ArrayList와 LinkedList의 차이가 무엇인가요?
1. 공간적 제약
-
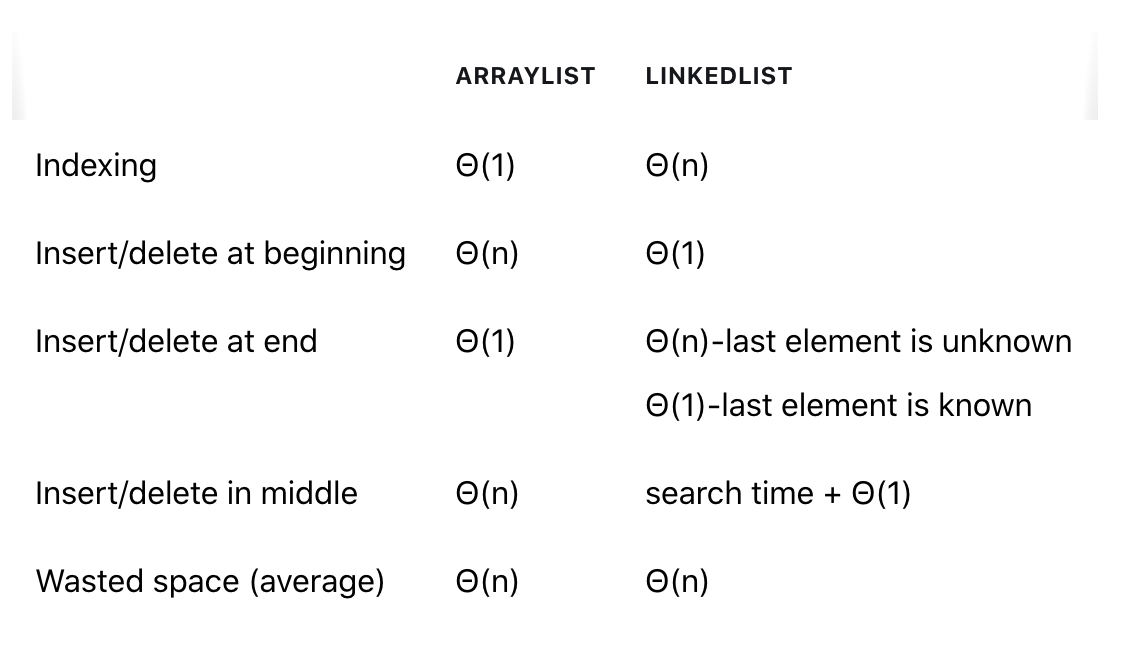
ArrayList : 결국 배열이므로 길이가 고정되어 있습니다. 때문에, 새로 배열에 새로운 요소를 추가하려고 할 때, 배열의 용량이 이미 가득 차있다면 새로운 배열을 생성해주어야 합니다. 이 때, 새로 생성된 배열이 메모리 상에 연속해서 생길 수도 있지만, 이미 다른 값이 메모리를 사용하고 있는 경우, 새로운 위치에 배열이 생성되어야 하고 이는 모든 요소를 옮긴다는 얘기가 됩니다. 또 메모리에 여유공간이 없는 경우 에러가 발생할 수도 있습니다.
-
LinkedList: 한 개의 Node는 다른 Node에 대한 참조만 가지고 있습니다. 따라서 공간적 제약을 ArrayList에 비해 받지 않습니다.
2. 새로운 요소 추가
-
ArrayList : 새로운 요소를 추가할 때, 여유 공간이 있는 경우엔 O(1)이지만, 여유공간이 없는 경우엔 O(n)이므로 O(n)입니다.
-
LinkedList : 새로운 요소를 추가할 때, 항상 O(1)입니다. 왜냐하면, 그냥 마지막 요소에서 다음 참조값을 가지게만 하면 되기 때문입니다.
3. 임의 접근과 순차 접근
- 임의 접근(Random Access) : 어떤 요소에 바로 접근하는 것.
- 순차 접근(Sequential Access) : 어떤 요소에 접근할 때, 차례차례 접근하는 것.
- ArrayList :임의 접근, 바로 접근이 가능하다는 것은 곧 O(1)을 의미한다.
- nkedList : 순차 접근만 가능, O(n)이 걸리게 됩니다.
4. 새로운 요소 삽입(중간에)
- ArrayList는 해당 요소뒤의 요소들도 전부 옮겨야 합니다.
- LinkedList는 앞 뒤 요소의 값만 바꾸어주면 됩니다.
5. 요소 삭제(중간에)
- ArrayList는 뒤의 요소들을 전부 앞으로 이동시켜야합니다.
- LinkedList의 경우에는 앞 뒤 요소의 값만 바꾸어주면 됩니다.
Stack과 Queue의 차이점은 무엇인가요?
Stack
세로로 된 바구니와 같은 구조로 먼저 넣게 되는 자료가 마지막으로 나오게 되는 First-In Last-Out(FILO) 구조이다. List로 구현하면 객체를 제거하는 작업이 필요하다. 하지만 Array로 구현하면 삭제할 필요 없이 index를 줄이고 초기화만 하면 되므로, Array로 구현하는 것이 좋다.
top을 통해서 push, pop을 하면서 삽입과 삭제가 일어난다. DFS나 재귀에서 사용된다.
Queue
큐는 원소의 줄을 세우는 자료구조이다. 가로로 된 통과 같은 구조로 먼저 넣게 되는 자료가 가장 먼저 나오는 First-In First-Out(FIFO) 구조이다. Array로 구현하면 poll 연산 이후 객체를 앞당기는 작업이 필요하다. 하지만 List로 구현하면 객체 1개만 제거하면 되므로 삽입 및 삭제가 용이한 LinkedList로 구현하는 것이 좋다.큐는 한 쪽 끝에서 삽입 작업을, 다른 쪽 끝에서 삭제 작업을 진행한다. 선입선출 구조이다. 주로 데이터가 입력된 시간 순서대로 처리되어야 하는 경우 사용한다. BFS나 캐시를 구현할 때 사용한다.
[참고링크]
