혼잡제어의 원리
혼잡 제어가 일어나는 원인을 살펴보기 위해서 우리는 3가지 시나리오를 살펴볼 것입니다.
시나리오 1: 2개의 송신자와 무한 버퍼를 갖는 하나의 라우터
두 호스트 A와 B가 아래 그림처럼 각각 출발지와 목적지 사이에 단일 홉을 공유하는 연결을 가진다고 생각하자.
⚡ 홉(Hop) ⚡
홉이란 데이터통신망에서 각 패킷이 매 노드(또는 라우터를) 건너가는 양상을 비유적으로 표현
이러한 체계를 hop-by-hop 체제라고 합니다. (영어 뜻 자체로는 건너뛰는 모습을 의미)
현재 호스트 A에서 호스트 B로 데이터를 전송하고 있다고 하고, 호스트 A의 데이터 전송 속도가 호스트 B가 데이터를 처리하는 속도보다 빠르다고 가정해 보겠습니다.
쉽게 말하자면, 바이트/초의 전송률로 매우 많은 데이터를 보내고 있는 상태입니다.
호스트 A로부터 호스트 B로 전송되는 패킷은 라우터를 통해서 전달되고, 용량 R의 공유 출력 링크상으로 전달됩니다.
라우터에서는 패킷 도착률 > 출력 링크의 용량인 상황이라 패킷들이 버퍼에 축척되고 있는 상태입니다.
다음 아래 그림은 호스트 A의 연결 성능을 나타낸 것입니다.
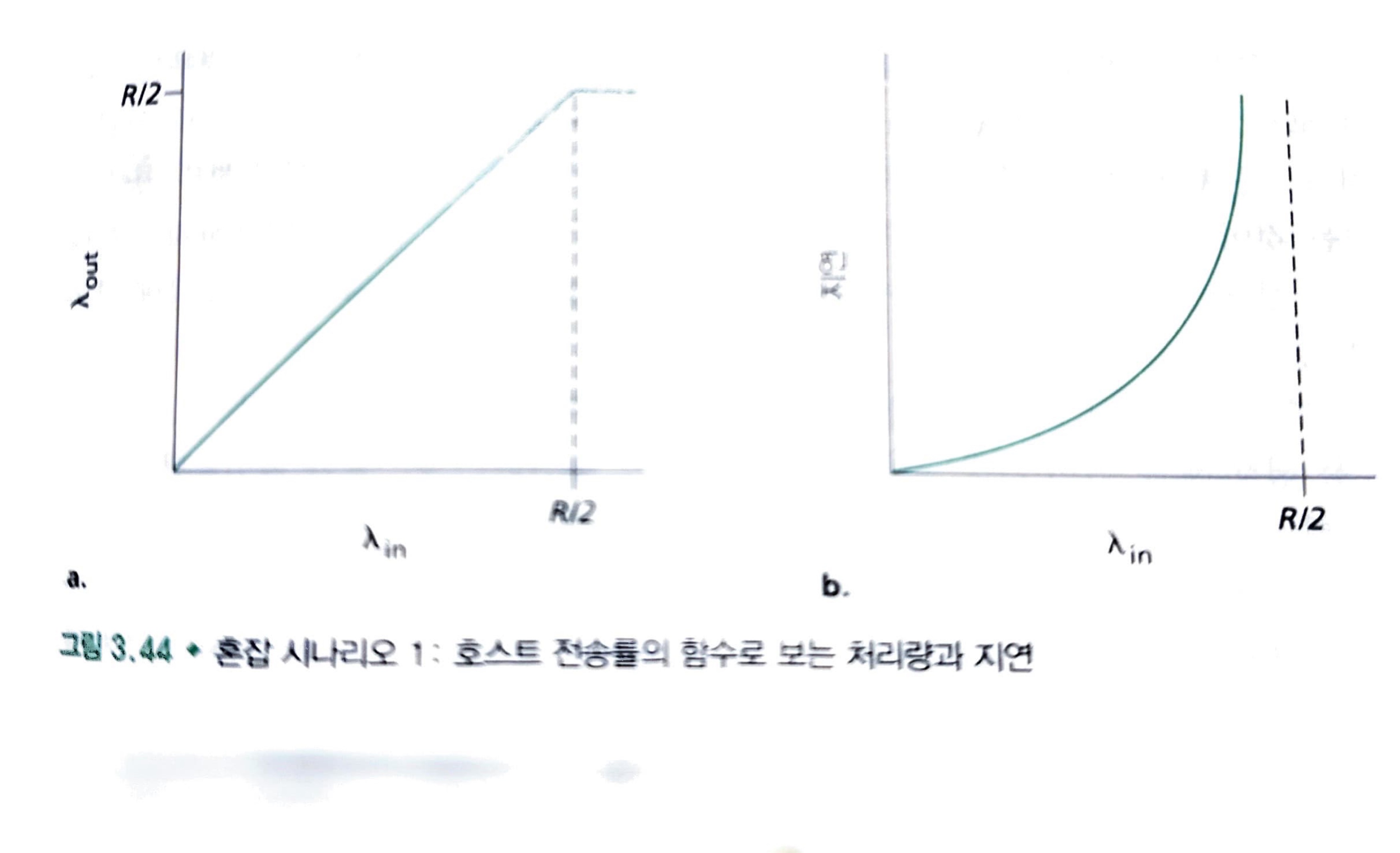
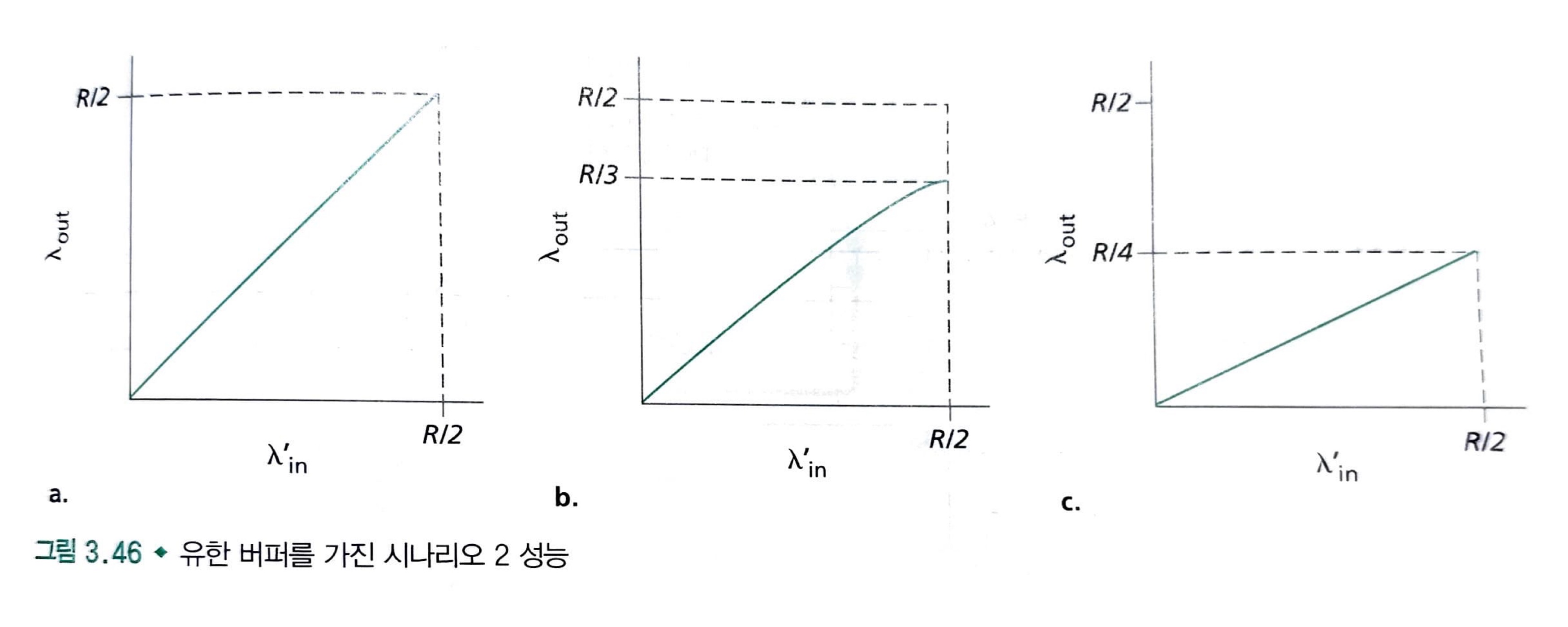
왼쪽 그래프는 연결 전송률의 함수로 연결당 처리량(per-connection throughput: 수신자자 측에서의 초당 바이트 수)을 그린 것입니다. [0, R/2]에서의 전송률에 대해서 수신자측의 처리량과 수신자의 전송률과 같습니다. 송신자가 보내는 모든 데이터는 유한한 지연으로 수신자에게 수신됩니다.
그러나 전송률이 R/2 이상일 때, 처리량은 단지 R/2이다. 처리량에서 이러한 상위 제한은 두 연결사이에서 "링크 용량 공유"의 결과입니다.
링크는 "안정 상태(steady state)"에서는 R/2를 초과해서 패킷을 수신자에게 전달할 수 없습니다.
전송률을 아무리 높게 잡아도 각자 R/2보다 더 높은 처리량을 결코 얻을 수 없습니다.
R/2의 연결당 처리량을 얻는 것은 목적지에 패킷을 전달하는 데 링크를 최대로 활용하므로 좋은 현상입니다.
그러나 오른쪽 그래프는 링크 용량 근처에서 동작의 결과를 보여줍니다. 전송률이 R/2에 근접했을 때, 평균 지연은 점점 커진다.
해당 시나리오에서는 전송률이 R/2를 초과해도 라우터 안에 큐잉된 패킷의 평균 개수는 제한되지 않는다.
그리고 출발지와 목적지 사이의 평균 지연이 무제한이 됩니다.
따라서, R근처의 처리량에서 동작하는 것이 처리량 관점에서 이상적이지만, 지연 관점에서는 이상하지 않다.
심지어 이 이상적인 시나리오에서도 혼잡 네트워크의 한 비용을 발견했다. 즉, 패킷 도착률이 링크 용량에 근접함에 따라 큐잉 지연이 커진다.
시나리오 2: 2개의 송신자, 유한 버퍼를 가진 하나의 라우터
시나리오 1에서 약간의 변경이 있습니다.
- 라우터 버퍼의 양이 유한하다고 가정.
- 이미 버퍼가 가득 찼을 경우 도착하는 패킷들이 버려진다는 것을 의미
- 각 연결은 신뢰적이라고 가정한다.
패킷이 재전송 될 수 있으므로 송신율(sending rate)이라는 용어 사용에 좀 더 주의를 해야 합니다.
애플리케이션에서 원래의 데이터를 소켓으로 보내는 송신율을 바이트/초로 표기하고, 네트워크 안으로 세그먼트(원래 데이터와 재전송 데이터를 포함)를 송신하는 트랜스포트 계층에서의 송신율은 바이트/초로 표시하고, 은 때때로 네트워크에 제공된 부하(offered load)라고 부릅니다.
여기서도 3가지 상황으로 나눌 수 있습니다.
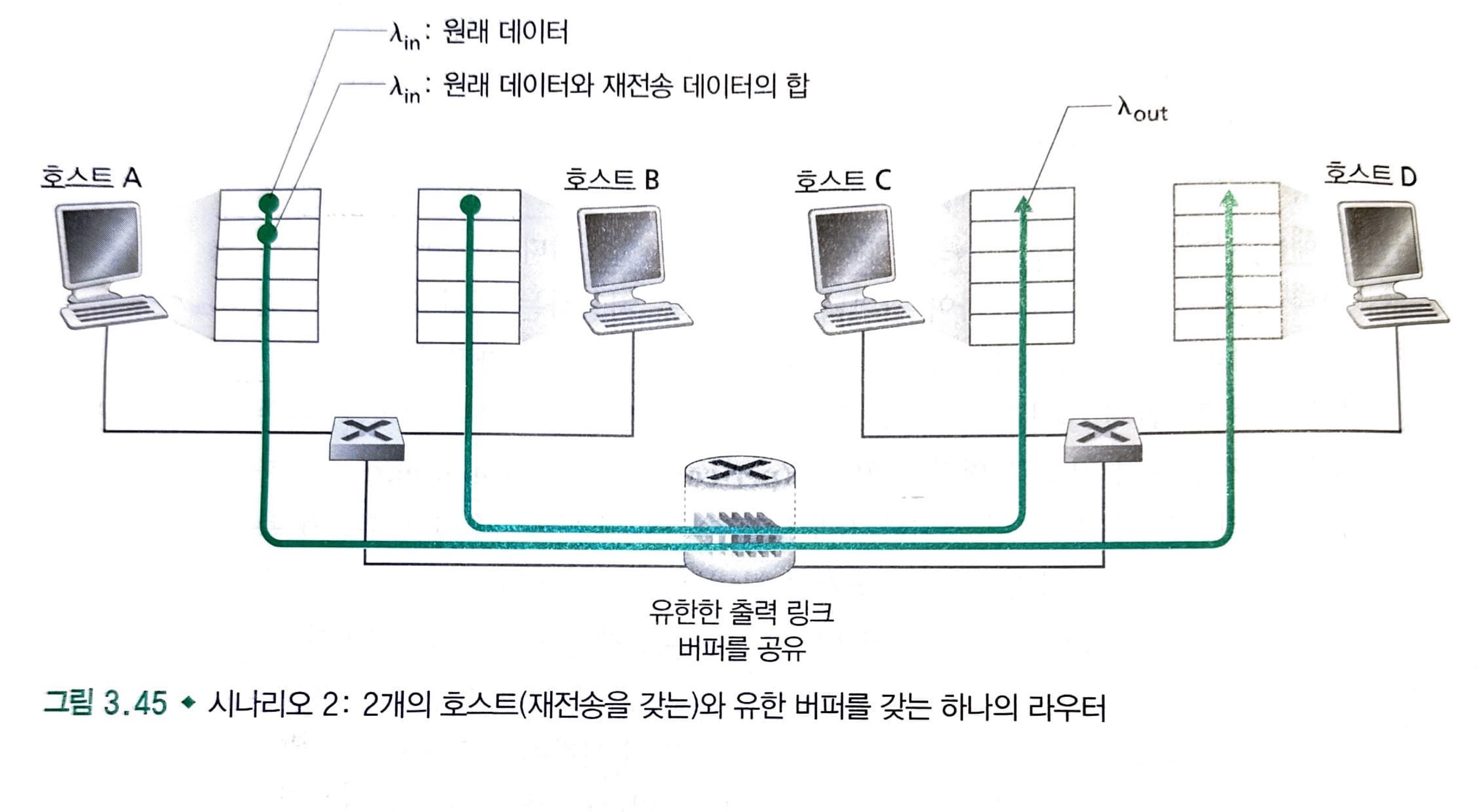
- == : 패킷 손실이 전혀 일어나지 않는 상황
- < : 패킷이 확실히 손실된 것을 알았을 때만, 송신자가 재전송 하는 상황
- << : 송신자에서 너무 일찍 타임아웃되는 바람에 패킷이 손실되지 않았지만 큐에서 지연되고 있는 패킷을 재전송하는 경우
먼저, 1번의 경우 송신된 모든 것이 수신되기 때문에 성능은 이상적이다.
2번의 경우, 혼잡 네트워크의 또 다른 비용을 알 수 있습니다. 즉, 송신자는 버퍼 오버플로 때문에 버려진 패킷을 보상하기 위해 재전송을 수행해야 합니다.
마지막으로 이러한 경우는 수신자가 이미 패킷의 원래 복사본을 수신 했을 때, 복사본을 포워딩하는 작업은 낭비입니다. 이것 대신에 라우터는 다른 패킷을 송신하기 위해 링크 전송 용량을 사용하는 것이 좋습니다.
따라서 여기에 혼잡 네트워크의 또 다른 비용이 있습니다. 즉, 커다란 지연으로 인한 송신자의 불필요한 재전송은 라우터가 패킷의 불필요한 복사본을 전송하는데 링크 대역폭을 사용하는 원인이 됩니다.
시나리오 3: 4개의 손신자와 유한 버퍼를 가지는 라우터, 그리고 멀티홉 경로
여기서 모든 호스트는 의 동일한 값을 가지고, 모든 라우터 링크는 R 바이트/초 용량을 가진다고 가정합니다.
여기서 그림을 먼저 확인해 봅시다.
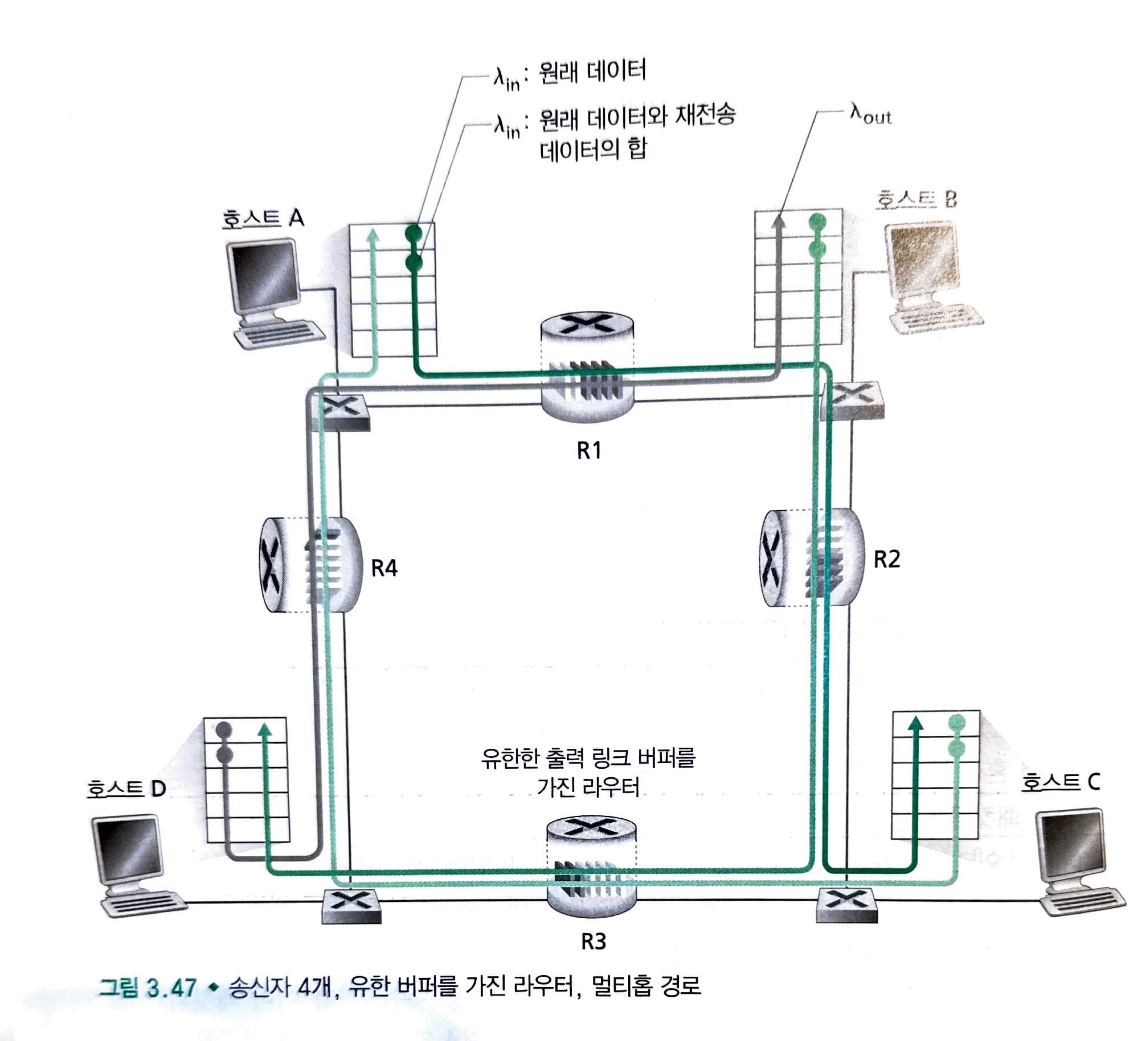
현재 호스트 A ~ C 연결은 D ~ B 연결과 라우터 R1을 공유합니다. 그리고 B ~ D 연결과 라우터 R2를 공유합니다.
이러한 시나리오에서 가 작을 경우에는 크게 문제가 되지 않지만, 값이 커지기 시작하면 문제가 발생합니다.
라우터 R2를 고려해 봅시다. 라우터 R2에 도착하는 A ~ C 트래픽은 R2에 값에 관계없이, R1에서 R2까지의 링크용량, R인 도착률을 가질 수 있습니다. 만약 이 모든 연결(B ~ D 연결을 포함하는)에 대해 매우 크다면, R2의 B ~ D트래픽 도착률은 A ~ C 트래픽 도착률보다 클 수 있습니다.
버퍼 공간 R2 라우터에서 경쟁해야 하는 상황인데, R2를 성공적으로 통과하는 A ~ C 트래픽의 양은 B ~ D에서 제공된 부하가 크면 클수록 더 작아집니다.
극한적인 경우에 제공된 부하가 무한대에 가까워짐에 따라 A ~ C 종단관 처리율은 0이 될 수 있습니다.
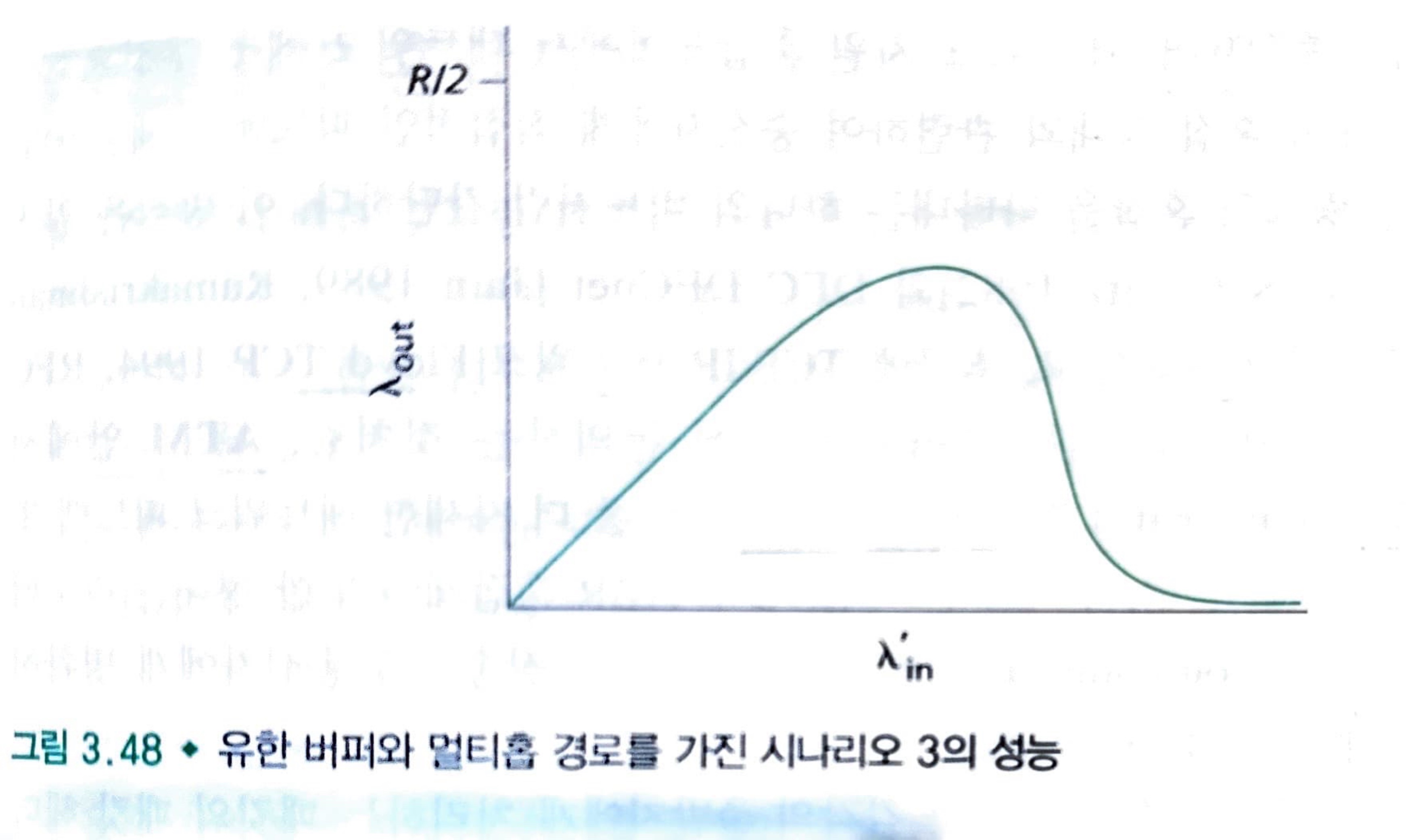
제공된 부하를 증가하면 처리량이 궁극적으로 감소하는 원인은 네트워크가 수행한 헛된 "작업"의 양을 고려해보면 확실해진다. 앞에서 설명된 과도한 트래픽 시나리오에서 패킷이 두 번째 홉 라우터에서 버려질 때마다, 두 번째 홉 라우터에서 패킷을 전달하는 첫 번째 홉 라우터에서 수행된 작업은 "헛된" 것이 됩니다.
여기서 혼잡 때문에 패킷을 버려야 하는 또 다른 비용을 확인할 수 있습니다. 패킷이 경로상에서 버려질 때 마다, 버려지는 지점까지 패킷을 전송하는데 사용된 상위 라우터에서 사용된 전송 용량은 헛된 것이다.
혼잡 제어에 대한 접근법
혼잡제어에 대한 TCP의 두 가지 접근법이 있습니다.
- 종단간의 혼잡제어
- TimeOut & 3 Duplicated ACK 발생
- Congestion이 일어난 것으로 간주
- Window Size를 줄여준다.
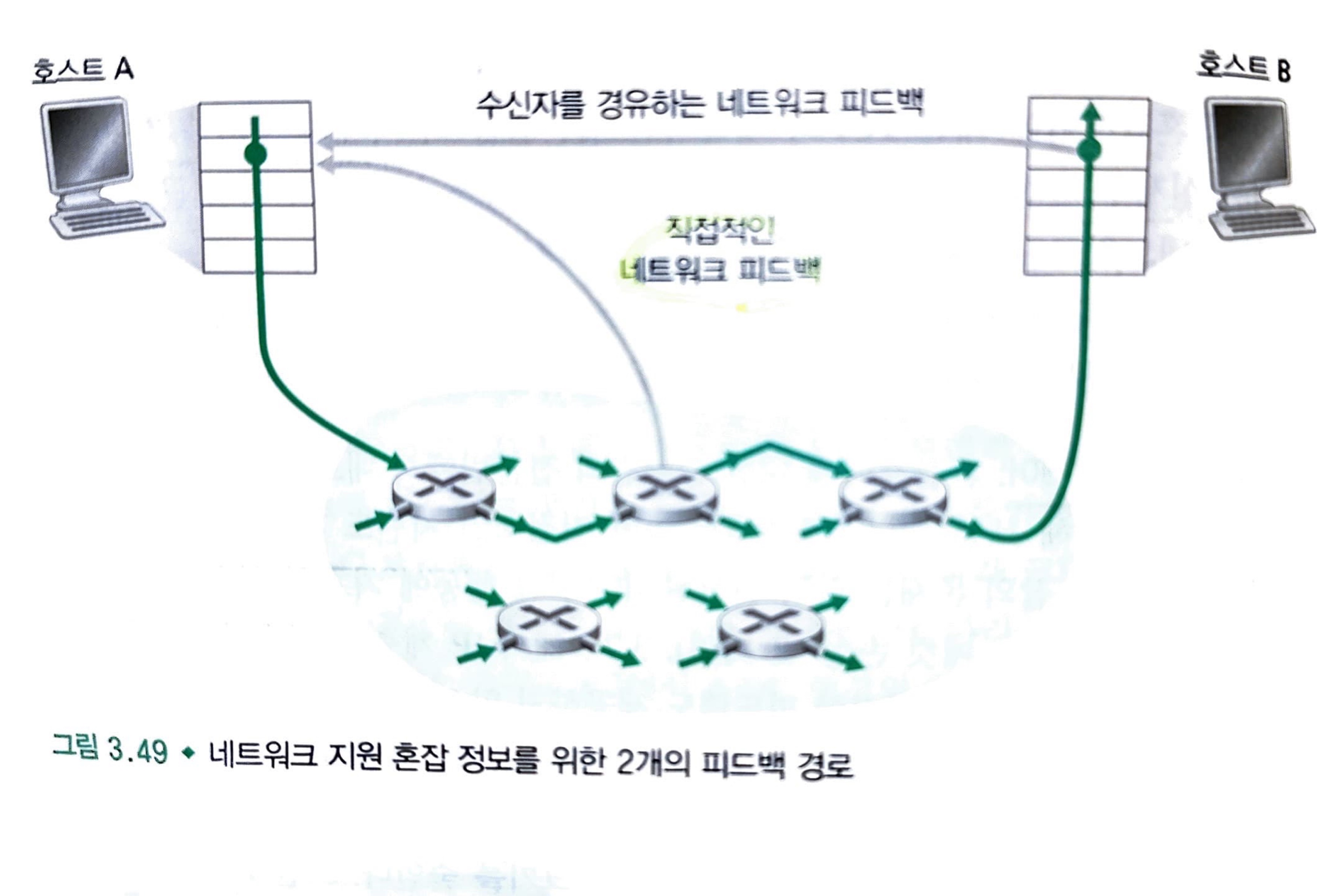
- 네트워크 지원 혼잡제어
- 직접적인 피드백: 라우터가 송신자에게 전달 (초크 패킷)
- 라우터가 패킷의 특정필드 수정: 수신자가 송신자에게 전달 (RTT 시간 소모)
혼잡제어
혼잡제어의 목적은 다음과 같습니다.
❗ 혼잡제어 목적
데이터의 양이 라우터가 처리할 수 있는 양을 초과하면 라우터는 더 이상 데이터를 처리할 수 없습니다. 이런 상황에서 송신 측은 라우터에서 처리하지 못한 데이터를 손실 데이터로 간주하고 계속해서 데이터를 전송하게 됩니다. 이는 네트워크를 혼잡하게 만듭니다. 혼잡 제어는 이런 네트워크의 혼잡성 문제를 해결하기 위한 기법입니다.
여기서 TCP가 취한 혼잡제어 방법은 네트워크 혼잡에 따라 연결에 트래픽을 보내는 전송률을 각 송신자가 제한하도록 하는 것입니다.
여기서 세 가지 정도 의문이 생깁니다.
- 트래픽 전송률을 어떻게 제한하지?
- 혼잡을 어떻게 감지하지?
- 어떤 알고리즘을 사용하는 것인가?
이 3가지 내용을 여기서 다뤄볼 것이며 마지막으론 현재 사용하고 있는 혼잡 제어 방식까지 알아볼 것입니다.
여기서 혼잡 윈도우(congestion window, cwnd)라는 개념이 등장합니다.
cwnd로 표시되는 혼잡 윈도우는 TCP 송신자가 네트워크로 트래픽을 전송할 수 있는 비율을 제한하도록 합니다.
이제부터는 흐름제어와 대조적으로 혼잡제어에 집중하기 위해서, 수신 윈도우의 제약 조건을 무시할 수 있을 정도로 TCP 수신 버퍼가 매우 크다고 해보자.
이렇게 하면 송신자의 확인응답이 안 된 데이터의 양은 오로지 cwnd에 의해 한정되게 됩니다.
송신자의 송신율은 대략 cwnd/RTT 바이트/초입니다. cwnd의 값을 조절하여, 송신자는 링크에 데이터를 전송하는 비율을 조절할 수 있습니다.
이제 가정을 해봅시다.
만약 송신한 세그먼트의 확인 응답이 TCP 송신자에게 수신되었다고 가정해 봅시다.
그렇다는 것은 결국 loss event가 발생하지 않고 잘 도착했음을 의미합니다.
그리고 해당 트래픽에 문제가 없다고 판단하여서 TCP는 혼잡 윈도우 크기를 증가시킬 것입니다.
하지만 만약 loss event가 발생했다고 생각해 봅시다. loss event를 송신자 측에서 감지를 하면
TCP는 트래픽을 조절하기 위해서 혼잡 윈도우의 크기를 줄일 것입니다.
TCP는 확인응답을 혼잡 윈도우 크기의 증가를 유발하는데 트리거(trigger) 또는 클록(clock)으로 사용하므로, TCP는 자체 클로킹(self-clocking)이라고 합니다.
이제 TCP가 혼잡 상태를 확인하는 것은 loss event의 발생으로 알 수 있다는 것을 알게 되었습니다.
그리고 혼잡 상태를 확인하면 혼잡 윈도우의 크기를 줄이는 것을 확인했습니다.
그렇다면 얼마나 줄여야 할까요?
이것 말고도 고려할 것이 더 있습니다.
- TCP 송신자들은 가용한 밴드폭을 모두 사용하는 동시에 반면 네트워크를 혼잡시키지 않는 전송률을 어떻게 결정할 수 있을까?
- TCP 송신자들은 명시적으로 조정되는 것일까?
- 아니면 TCP 송신자들이 로컬 정보에만 근거하여 자신들의 전송률을 정하는 분산 방식이 있는 것인가?
TCP는 다음의 처리 원칙에 따라 이 질문들에 답을 하게 됩니다.
- 손실된 세그먼트는 혼잡을 의미하며, 이에 따라 TCP 전송률은 한 세그먼트를 손실했을 때 줄여져야 합니다.
- 확인응답된 세그먼트는 네트워크가 송신자의 세그먼트를 수신자에게 전송된다는 것이고, 이에 따라 이전에 확인응답되지 않은 세그먼트에 대해 ACK가 도착하면, 송신자의 전송률을 증가할 수 있다.
- 밴드폭 탐색
- 네트워크가 혼잡하다 == "Lose Event"
- 네트워크가 혼잡하지 않다 == "ACK 수신"
- 이 두 특성을 이용하여 다음과 같이 동작합니다.
- 확인응답되지 않은 세그먼트로 부터 ACK를 수신 -> 전송률 ↑
- 진행 하다가 "Loss Event"발생 -> 전송률 ↓
이제 TCP 혼잡제어에 대한 개념을 가지고, TCP 혼잡제어 알고리즘(TCP congestion control algorithm)을 알아보자.
이 알고리즘은 다음의 중요한 세 가지 구성요소들을 갖습니다.
- 슬로 스타트(slow start)
- 혼잡 회피(congestion avoidance)
- 빠른 회복(fast recovery)
여기서 슬로 스타트와 혼잡 회피는 TCP의 필수 요소입니다.
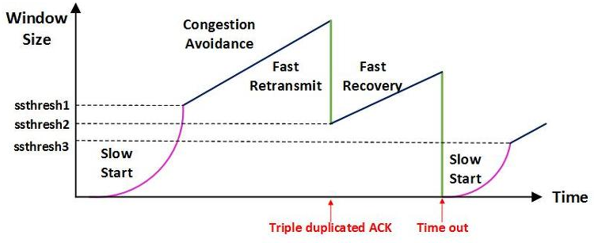
슬로 스타트(Slow Start)
TCP 연결이 시작될 때, cwnd의 값은 일반적으로 1 MSS로 초기화 되고, 그 결과 초기 전송률은 대략적으로 MSS/RTT가 됩니다.
예를 들어, 만약 MSS = 500바이트이고 RTT = 200msec이면, 그 결과 초기 전송률은 단지 약 20kbps정도가 됩니다.
TCP 송신자에게 가용 밴드폭은 MSS/RTT보다 훨씬 클 것이므로, TCP 송신자는 가용 밴드폭 양을 조속히 찾고자 합니다.
여기서 AIMD라는 방식이 비효율적이기 때문에, TCP는 슬로 스타트 방식을 사용합니다.
⚡ AIMD 방식(Additive Increase / Multiplicative Decrease) ⚡
- 처음에 패킷을 하나씩 보내고 이것이 문제없이 도착하면 window 크기를 1씩 증가시켜 가며 전송하는 방법
- 패킷 전송에 실패하거나 일정 시간을 넘으면 패킷의 보내는 속도를 절반으로 줄인다.
- 공평한 방식으로, 여러 호스트가 한 네트워크를 공유하고 있으면 나중에 진입하는 쪽이 처음에는 불리하지만, 시간이 흐르면 평형상태로 수렴하게 되는 특징이 있다.
문제점은 초기에 네트워크의 높은 대역폭을 사용하지 못하여 오랜 시간이 걸리게 되고, 네트워크가 혼잡해지는 상황을 미리 감지하지 못한다. 즉, 네트워크가 혼잡해지고 나서야 대역폭을 줄이는 방식이다.
TCP는 TCP 전송률을 작은 값으로 시작하지만 슬로 스타트 단계 동안에 "지수적"으로 증가시킵니다.
그렇다면 언제까지 슬로 스타트를 유지할까?
- 만약에 타임아웃에 의한 손실 이벤트가 있을 경우, TCP 송신자는 cwnd = 1로 하고 새로운 슬로 스타트를 시작. 그리고 두 번째 상태 변수인 ssthresh("slow start threshold", 슬로 스타트 임계치의 약자) 값을 cwnd/2(혼잡이 검출 되었을 시점에서의 혼잡 윈도우 값의 반)으로 정합니다.
- cwnd의 값이 ssthresh와 같아지면, 슬로 스타트는 종료되고 TCP는 혼잡 회피 모드로 전환한다.
- 3 Duplicated ACK가 발생시, TCP는 빠른 재전송을 수행하여 빠른 회복 상태로 들어갑니다.
혼잡 회피(Congestion Avoidance)
혼잡 회피 상태로 들어가는 시점에서 cwnd의 값은 대략 혼잡이 마지막 발견된 시점에서의 값의 반으로 됩니다.
그리고 RTT당 1MSS만큼씩 혼잡 윈도우를 증가시킬 것입니다.
언제 혼잡 회피의 선형증가가 끝날 것인가?
여기서는 타임아웃과 3개의 중복 ACK를 나눠서 처리합니다.
- 타임아웃
a. cwnd = 1
b. ssthresh = cwnd / 2 - 3 duplicated ack
a. cwnd = cwnd(발생 당시의 값) / 2
b. ssthresh = cwnd(발생 당시의 값) / 2
빠른 회복(Fast Recovery)
이것은 TCP에서 필수는 아니지만 권고 사항입니다.
빠른 회복에서 cwnd값은 잃었던 세그먼트에 대한 매 중복된 ACK를 수신할 때마다 1 MSS만큼씩 증가 됩니다.
타임아웃 이벤트가 발생한다면 빠른 회복은 슬로 스타트와 혼잡 회피에서와 같은 동작을 수행한 후 슬로 스타트로 전이합니다.
- 타임아웃
- Slow Start로 전환
- 3 duplicated ack
- 중복된 ack까지는 받으면서 1MSS씩 증가 시키고, 새로운 ACK 수신하면 혼잡 회피 모드로 전환
TCP 혼잡제어의 3가지 버전
TCP의 혼잡제어에서 3가지를 알아볼 것입니다.
- TCP Tahoe
- TCP Reno
- TCP newReno
3가지의 동작 방식에 대해서 적어 놓고 차이점에 대해서는 본인의 판단에 맡기겠습니다.
TCP Tahoe
- TCP 연결
- cwnd = 1에서 시작
- Slow Start하다가 ssthresh 값에 도달시 CA 모드
- Loss Event 발생시, ssthresh = cwnd / 2, cwnd = 1
- 3번과 동일하게 동작
TCP Reno
- TCP 연결
- cwnd = 1에서 시작
- Slow Start하다가 ssthresh 값에 도달시 CA 모드
- Loss Event 발생시, 두가지 case로 구분
a. Timeout: ssthresh = cwnd / 2, cwnd = 1 이후 3번 동작
b. 3 duplicated ack:- cwnd = ssthresh + 3으로 설정, ssthresh = cwnd / 2
- 중복된 ACK를 수신할 때 마다 1 MSS씩 증가
- 새로운 ACK 수신시 cwnd = cwnd / 2으로 설정
TCP newReno
TCP Reno의 문제점은 어떤 에러가 발생했을 때 개별적으로 발생하기 보다 한꺼번에 발생하는 경우가 많이 있습니다.

예를 들어, 위의 그림에서 X 표시가 에러인데, 현재 연속적으로 에러가 발생했습니다.
Reno방식을 사용하고 있다고 하면, 연속적인 에러로 인해서 cwnd는 1/8로 줄어들게 됩니다.
- 패킷 loss(3 Duplicated ACK)를 감지
- Fast Recovery 상태로 들어감
- 지금까지 보냈던 패킷들에 대한 ACK가 모두 도착할 때까지 fast recovery 상태를 종료 X
- 마지막에 보냈던 패킷에 대한 ACK가 오기 전에 패킷 loss가 한번 더 감지되었다고 가정
- cwnd는 절반이 되지 않고 현재의 fast recovery 상태 유지
Reference
