면접을 위한 CS 전공지식 노트도서를 참고하여 정리하였습니다. ❗️
SECTION 3.2 메모리
3.2.1 메모리 계층
메모리 계층은 레지스터, 캐시, 메모리, 저장장치로 구성되어 있다.
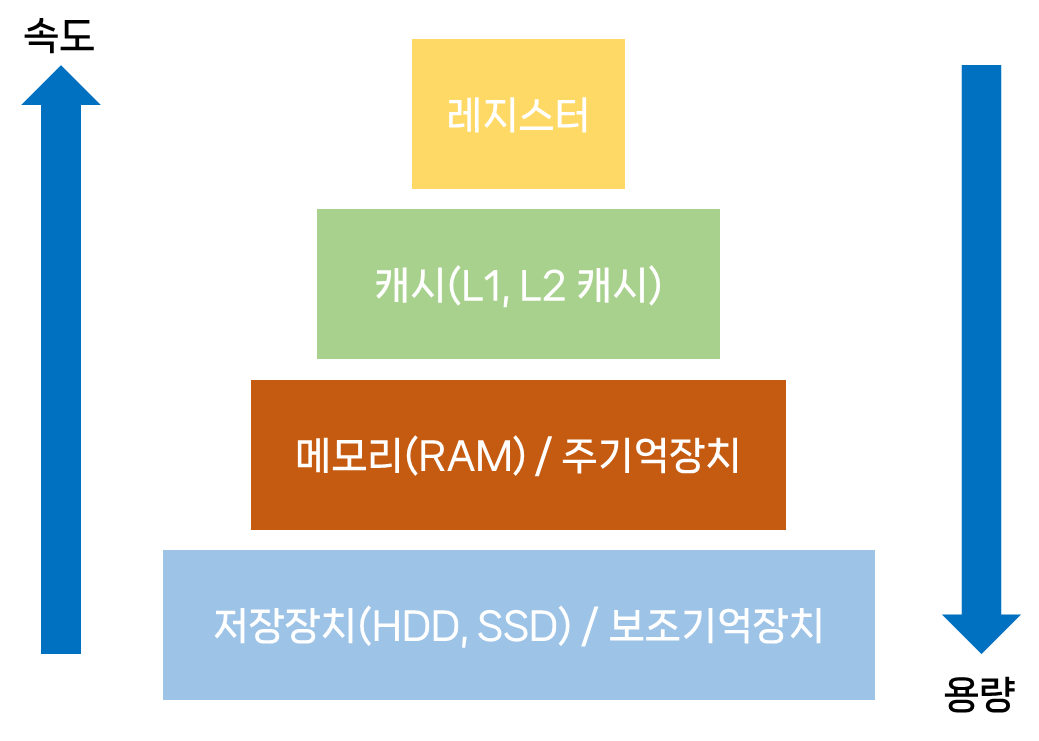
- 레지스터 : CPU안에 있는 작은 메모리, 휘발성, 속도 가장 빠름, 기억 용량이 가장 적음
- 캐시 : L1, L2 캐시를 지칭 | 휘발성, 속도 빠름, 기억 용량이 적음. (L3 캐시도 있음)
- 주기억장치 : RAM을 말함 | 휘발성, 속도 보통, 기억 용량 보통
- 보조기억장치 : HDD, SSD를 말함 | 비휘발성, 속도 낮음, 기억 용량 많음
이러한 계층이 있는 이유는 경제성과 캐시 때문
RAM은 하드디스크로부터 일정량의 데이터를 복사해서 임시 저장하고 필요 시에 CPU에 빠르게 전달하는 역할을 한다.
캐시
캐시(cache)는 데이터를 미리 복사해 놓는 임시 저장소이자 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리를 말한다.
[📌참고] CPU의 캐시 메모리
캐시 메모리가 많으면 CPU 성능적으로 유리하다고 말할 수 있다.
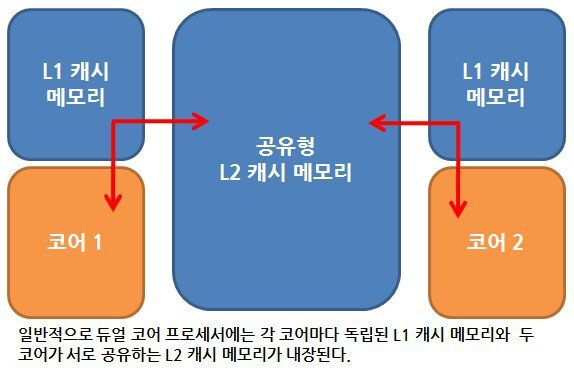
L1, L2, L3 캐시 메모리 : L은 Level을 의미한다. 이는 속도와 크기에 따라 분류한 것이다.
- L1 캐시는 일반적으로 CPU 칩안에 내장되어 데이터 사용/참조에 가장 먼저 사용된다.
-L1캐시는 보통8~64KB정도의 용량으로 CPU가 가장 빠르게 접근하게 되며, 여기서 데이터를 찾지 못하면 L2 캐시 메모리로 넘어 간다. - L2 캐시 메모리의 용도와 역할은
L1과 비슷하지만 속도는 그에 비해 느린편이다. 그렇지만, 일반 메모리(RAM) 보다 빠른 편이다. - L3 캐시 메모리의 용도와 역할은 동일한 원리로 작동하지만 거의 대부분
L3캐시 메모리를 달고 있지 않다. 충분히L2로 커버칠 수 있기 때문이다.
용어 정리 💡
캐싱 계층 : 메모리와 CPU의 속도 차이가 너무 크기 때문에 이를 해결하기 위해 계층과 계층 사이에 있는 계층을 말함. (캐시 메모리와 보조기억장치 사이에 있는 주기억장치 → 보조기억장치의 캐싱 계층)
지역성의 원리
캐시를 설정할 때는 지역성을 근거로 설정한다.
시간 지역성(temporal locality)
- 시간 지역성은 최근 사용한 데이터에 다시 접근하려는 특성을 말한다.
공간 지역성(spatial locality)
- 공간 지역성은 최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성을 말한다.
arr = [0 for _ in range(10)]
print(arr)
>>> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
for i in range(10):
arr[i] = i
print(arr)
>>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]for반복문으로 이루어진 코드 안의 변수i에 계속해서 접근한다.- 최근에 사용한 변수
i를 계속 접근해서+1을 연이어 연산하는 것이 시간 지역성 특성이다. - 배열
arr의 각 요소들에i가 할당되며 해당 배열에 연속적으로 접근하는 것이 공간 지역성 특성이다.
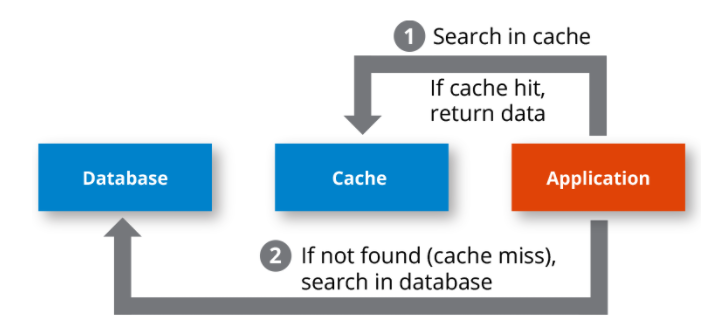
캐시히트와 캐시미스
캐시히트는 CPU가 참조하고자 하는 메모리가 캐시에 존재하고 있을 경우를 말한다.
- CPU 내부 버스를 기반으로 작동하기 때문에 빠르다. (제어장치를 거쳐 가져오기 때문에)
캐시미스는 CPU가 참조하고자 하는 메모리가 캐시에 존재하지 않을 때를 말한다.
- 시스템 버스를 기반으로 작동하기 때문에 느리다. (메모리에서 가져오기 때문에)
캐시 매핑
캐시매핑 : 캐시가 히트되기 위해 매핑하는 방법
| 이름 | 설명 |
|---|---|
| 직접매핑 (directed mapping) | 메모리가 1~100이 있고 캐시가 1~10이 있다면 1:1~10, 2:1~20 ... 이런 식으로 매핑하는 것을 말함. 처리가 빠르지만 충돌 발생이 잦음. |
| 연관 매핑 (associative mapping) | 순서를 일치시키지 않고 관련 있는 캐시와 메모리를 매핑함. 충돌이 적지만 모든 블록을 탐색해야 해서 속도가 느림. |
| 집합 연관 매핑 (set associative mapping) | 직접 매핑과 연관 매핑을 합쳐 놓은 것. 순서는 일치시키지만 집합을 둬서 저장하며 블록화되어 있기 때문에 검색은 좀 더 효율적임. |
웹 브라우저의 캐시
소프트웨어적인 대표적인 캐시로는 웹 브라우저의 작은 저장소 쿠키, 로컬 스토리지, 세션 스토리지가 있다.
- 보통 사용자의 커스텀한 정보나 인증 모듈 관련사항들을 웹 브라우저에 저장해서 추후 서버에 요청할 때 자신을 나타내는 아이덴티티나 중복 요청 방지를 위해 쓰인다.
쿠키
- 쿠키는 만료기한이 있는
키-값 저장소이다. - 쿠키를 설정할 때는
document.cookie로 쿠키를 볼 수 없게 httponly 옵션을 거는 것이 중요하며, 보통 서버에서 만료 기한을 정한다.
로컬 스토리지
- 로컬 스토리지는 만료기한이 없는
키-값 저장소이다. - 웹 브라우저를 닫아도 유지되고 도메인 단위로 저장, 생성된다.
HTML5를 지원하지 않는 웹 브라우저에서는 사용할 수 없으며, 클라이언트에서만 수정 가능하다.
세션 스토리지
- 세선 스토리지는 만료기한이 없는
키-값 저장소이다. - 탭 단위로 세션 스토리지를 생성하며, 탭을 닫을 때 해당 데이터가 삭제된다.
HTML5를 지원하지 않는 웹 브라우저에서는 사용할 수 없으며, 클라이언트에서만 수정 가능하다.
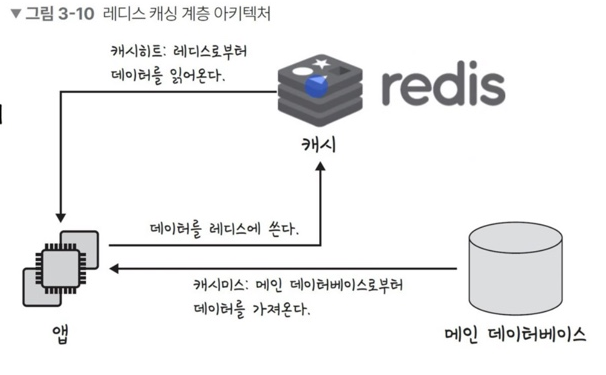
[📌참고] 데이터베이스의 캐싱 계층
데이터베이스 시스템을 구축할 때도 데이터베이스 위에 레디스(redis) 데이터 베이스 계층을 캐싱 계층으로 둬서 성능을 향상시키기도 한다.
[References]
인프런 강의 - 면접을 위한 CS 전공지식 노트
캐시히트, 캐시미스 사진
CPU와 캐시 (L1/L2/L3 캐시..)
