모델 사이즈 증가에 따른 fine-tuning 방법론의 한계점
- Large scale 모델의 전체 파라미터를 튜닝하는 것은 많은 비용을 발생
- 새로운 방법론인 In-context Learning, P-tuning, LoRA을 알아보자
In-context Learning
- Few Shot
- 별도의 gradient update 가 없음 (즉, 학습이 없음)
- Prompt engineering
- 장점: 프롬프트의 수정(디자인) 만으로 다양한 태스크를 풀 수 있음
- 단점: 프롬프트 입력 방법, 예시 갯수 등 Engineering 적 요소가 들어감

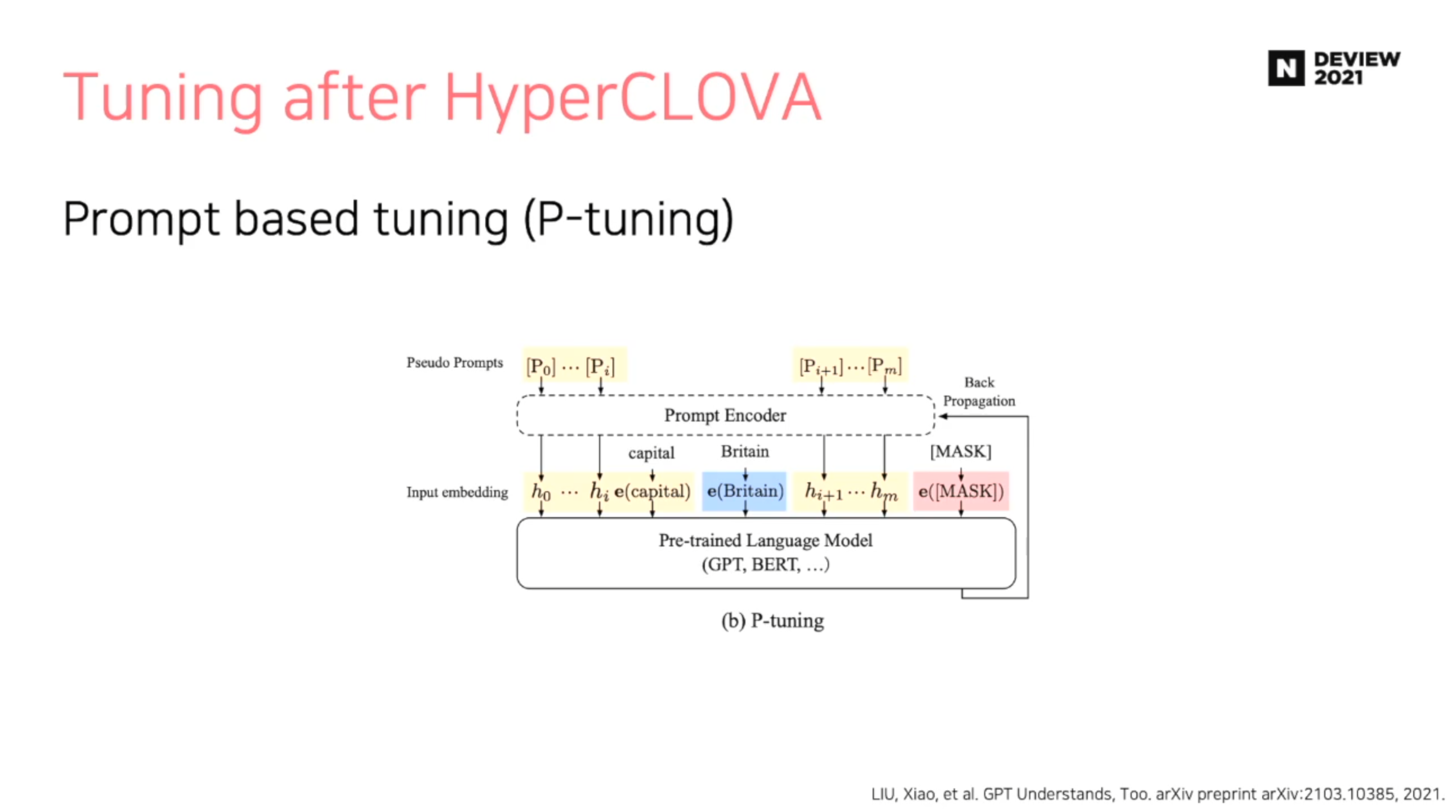
Prompt based tuning (P-tuning)
- 기존 Pre-trained Language Model을 Freeze 한 후, Prompt Encoder 만을 활용하여 학습 진행
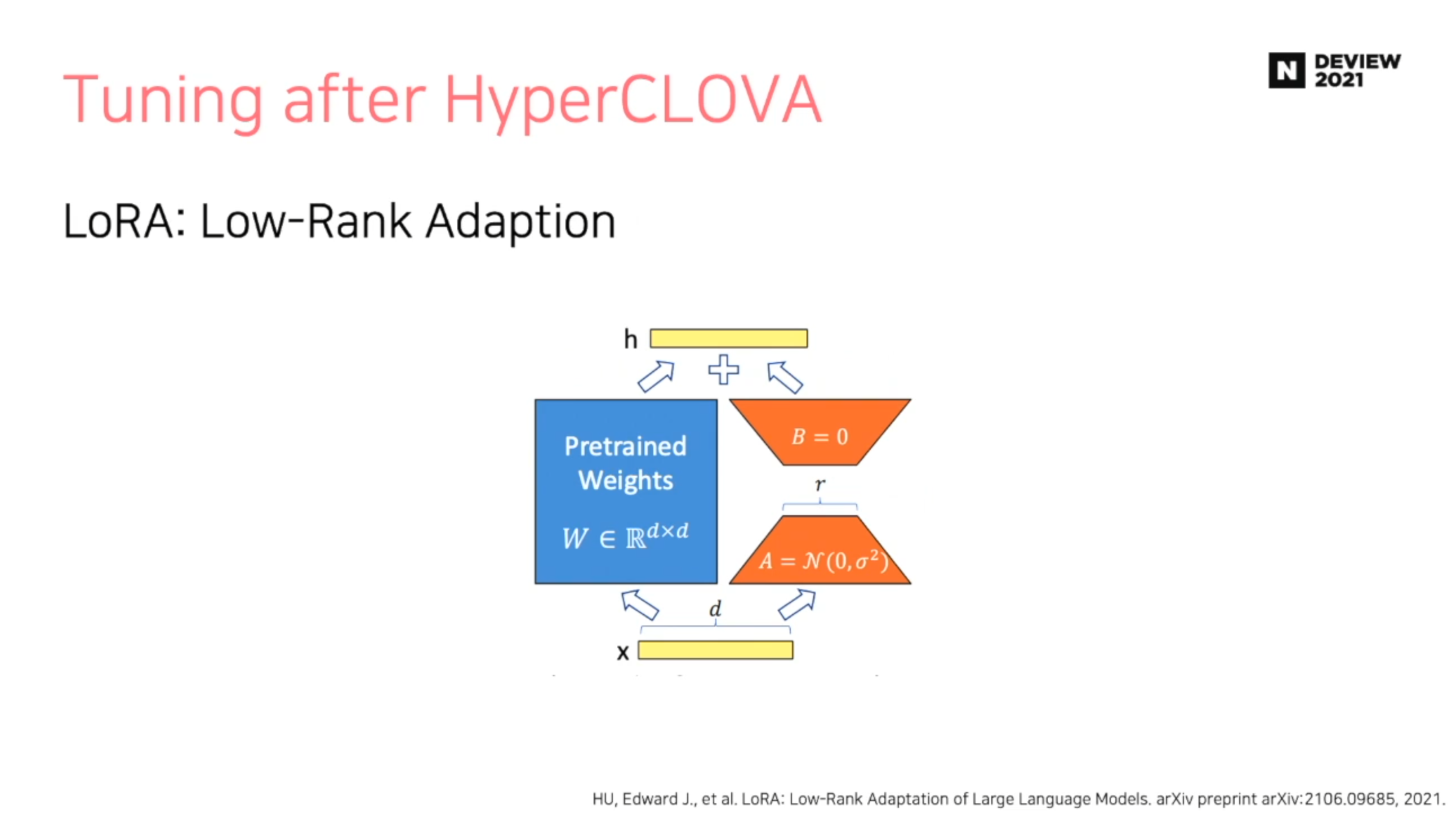
LoRA : Low-Rank Adaptation
- 파란색 영역 (Pretrained Weights)는 Freeze 한 후, 주황색 영역 (Low Rank Parameters)를 업데이트
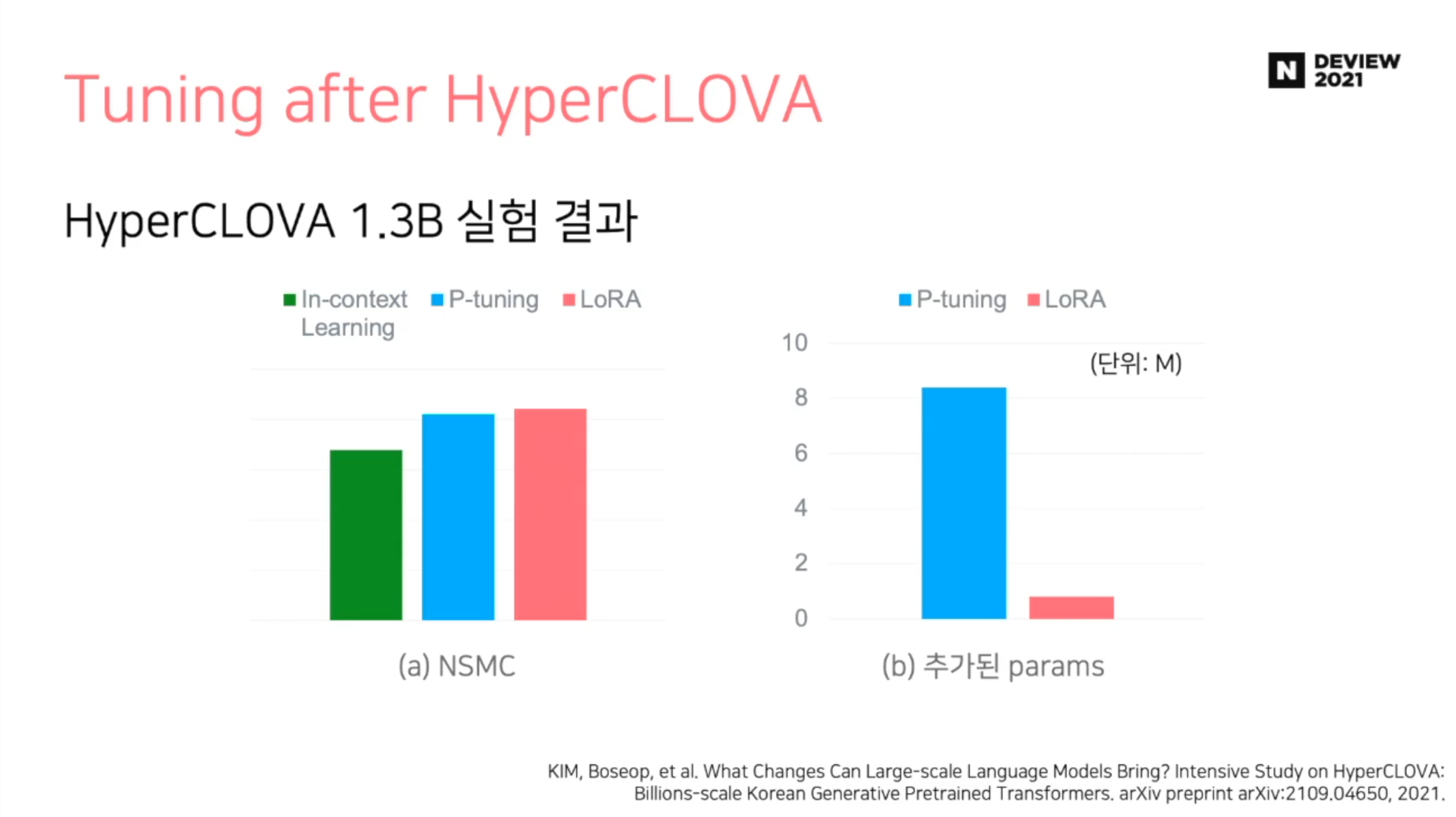
비교 실험
- 네이버 댓글 데이터 (NSMC) 를 활용한 실험 결과
- LoRA 가 더 적은 파라미터를 가지면서 더 좋은 성능을 냄
결론
P-tuning, LoRA 모두 적은 Trainable Parameters 만을 사용해 Large-Scale Model을 fine-tuning 할 수 있음
참고자료

Deep Learning Research Engineer@KRAFTON Inc.