Retrieval-Enhanced TRansfOrmer
Introduction
- We use a chunked cross-attention module to incorporate the retrieved text.
- With model size and database size : RETRO provides a constant gain for models ranging from 150M to 7B parameters.
RETRO's Retrieval Database
database는 key-value 구조를 가지고 있다.
key : BERT의 sentence embedding
value : Neighbor 과 Completion으로 구성된 text
Neighbor : key를 구하기 위해 사용되는 text
Completion : original document의 text (continuation of text)

RETRO의 database : 2 trillion (20억 개) multi-lingual tokens로 구성 (MassiveText dataset)
그리고 각 neighbor와 completion chunk는 최대 64 토큰 길이
The Database Lookup
Input prompt (즉 context)는 BERT를 통과하여 mean-pool된 sentence embedding 이 되고, 이를 k-NN search를 통해 Nearest Neighbor 를 찾는다.
어떻게 Retrieve 하는지?
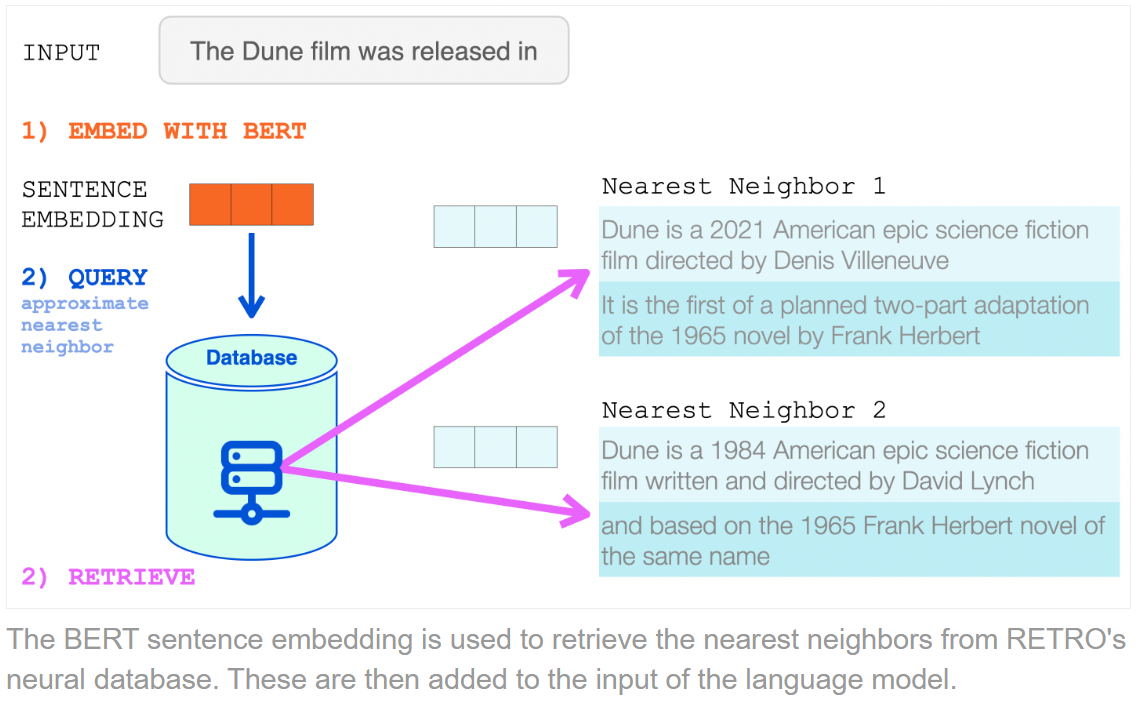
Retrieve 한 것을 통해 문장 생성을 어떻게 하는지?
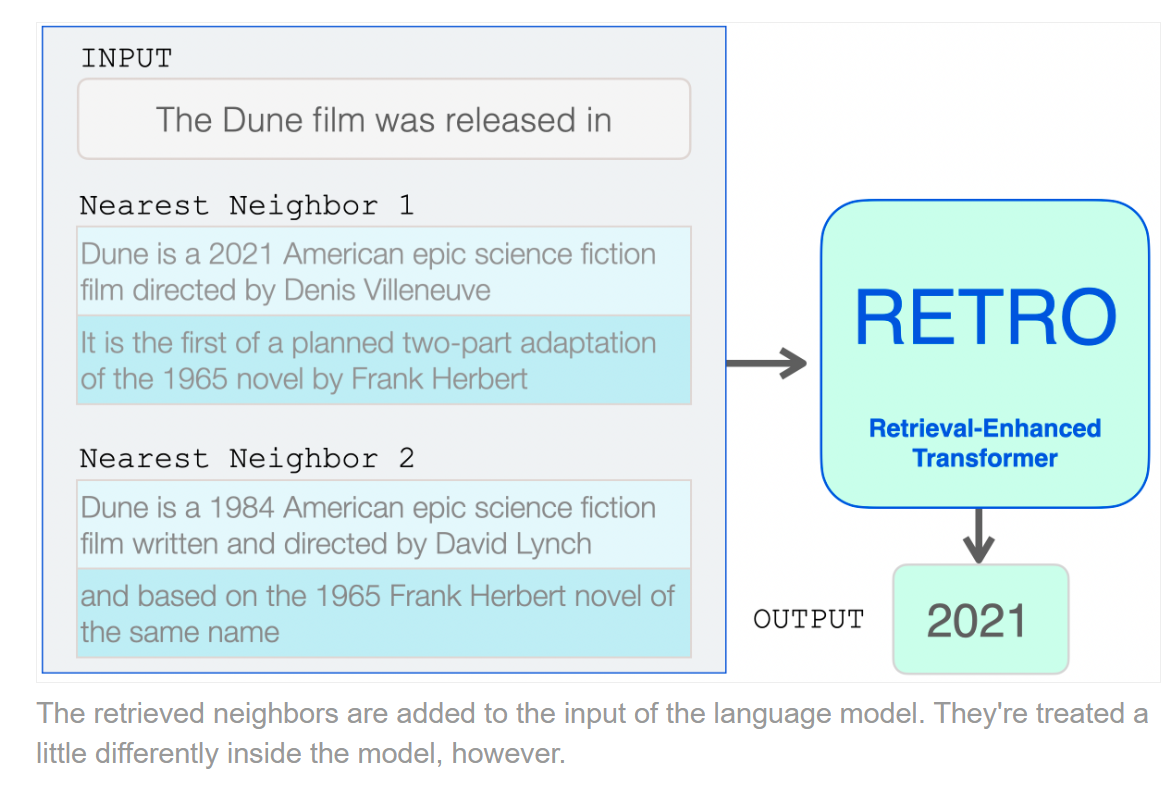
RETRO Transformer
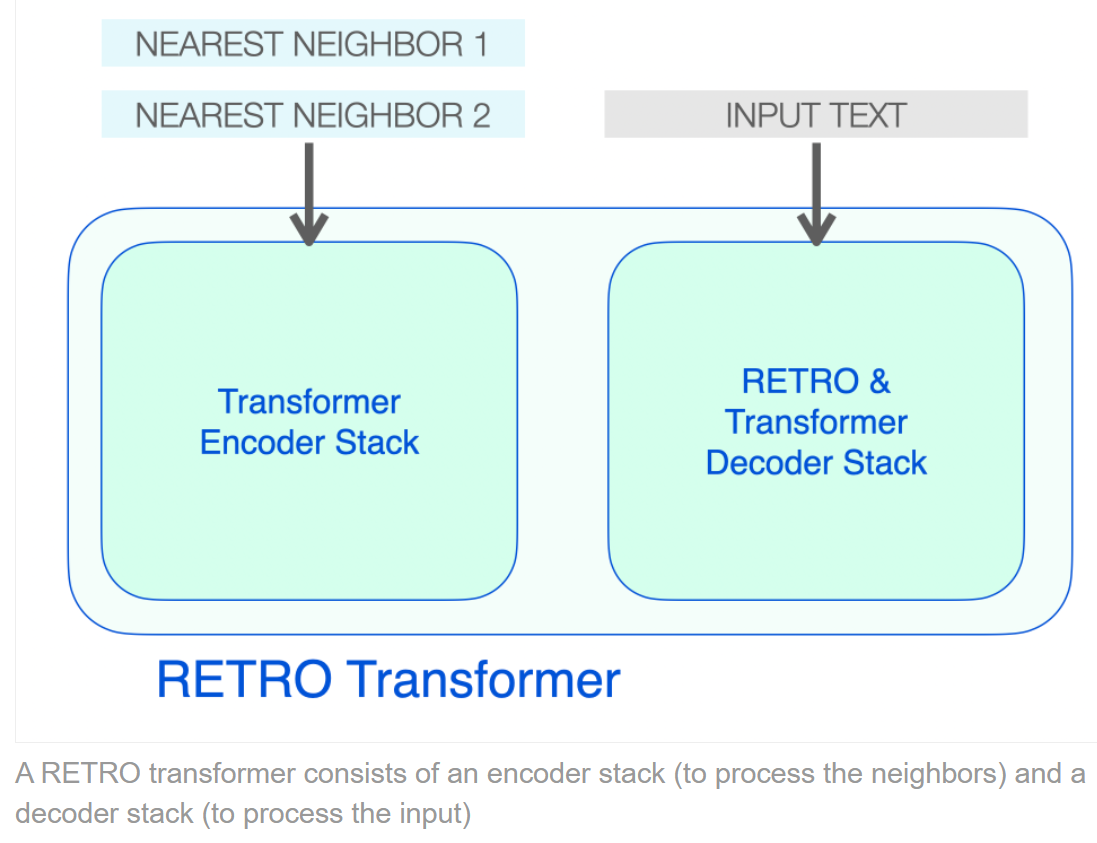
RETRO의 Encoder : 2 stacked Transformer Encoder Block
RETRO의 Decoder 는 두 종류의 Decocoder Block으로 이루어 진다.
- Standard Transformer Decoder Block (ATTN + FFNN)
- RETRO Decoder Block (ATTN + Chunked Cross Attention (CCA) + FFNN)

Deep Learning Research Engineer@KRAFTON Inc.