
작성일: 2022.01.16
작성자: 이정관 (leejk526@gmail.com)
요약
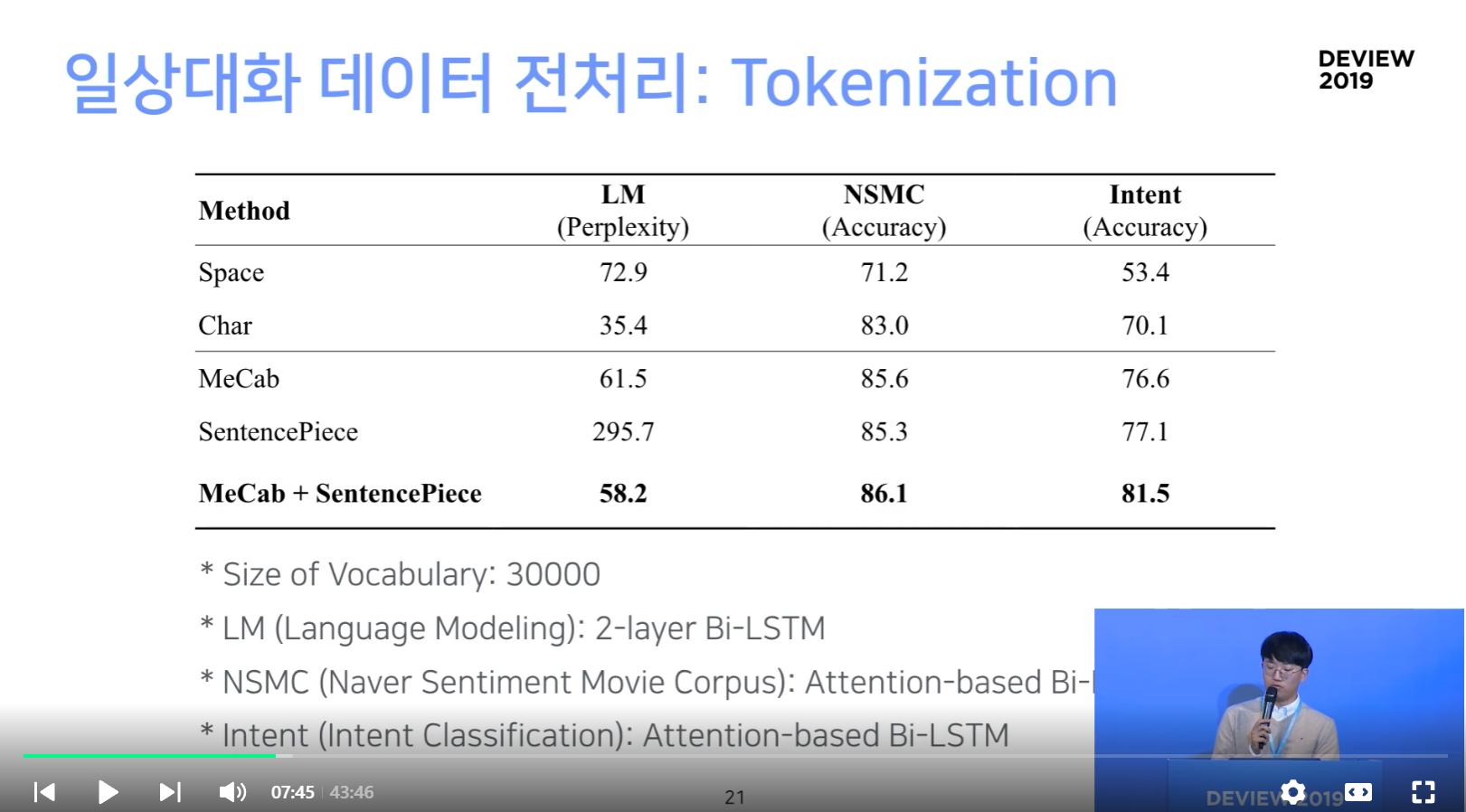
- 대화 데이터 특성을 반영할 수 있도록 Tokenizer는 형태소 기반 MeCab 과 Subword 기반 SentencePiece을 조합하여 tokenization하였다. (Perplexity, NSMC, Intent Classification에서 성능 개선)
- 문어기반 BERT 가 아닌 대화기반 BERT를 만들기 위해 Pre-training을 시켰으며 (Turn 구분 추가; max_len 48), 서로 다른 도메인(대화체와 문어체)에서 각 모델의 성능이 떨어짐을 확인하였다. (다르게 말해서, 대화기반 BERT가 필요하다)
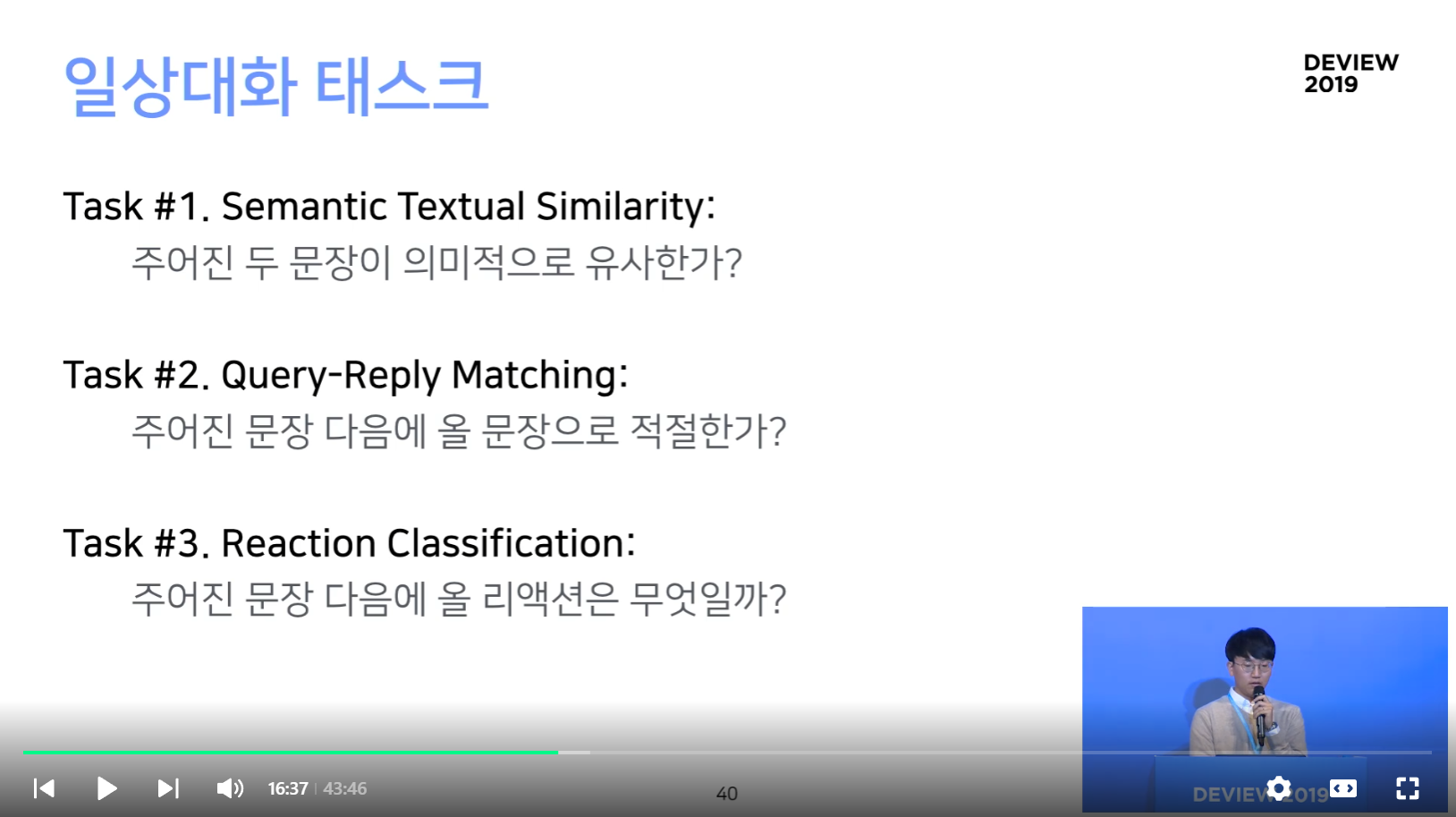
- Fine-tuning을 위해 세 가지 일상대화 태스크 (1. Semantic Textual Similarity (두 문장이 의미적으로 유사한지), 2. Query-Reply Matching (주어진 문장 다음에 올 문장으로 적절한지) 3. Reaction Classification (주어진 문장 다음에 올 리액션은 무엇인지) 를 정의하고, 성능을 측정하였다.
- 서비스를 위해 모델 경량화(Distillation) 을 도입하였으며, 여기서는 잘 학습된 Large model의 softmax output 를 small 모델이 라벨로서 학습함으로서, 보다 빠른 속도로 수렴 및 단순 학습 보다 더 나은 성능을 확보하였다.
목차

1. BERT 이해하기
(잘 아시는 분들은 안 보셔도 됩니다.)
왜 일상대화를 잘 못하지?
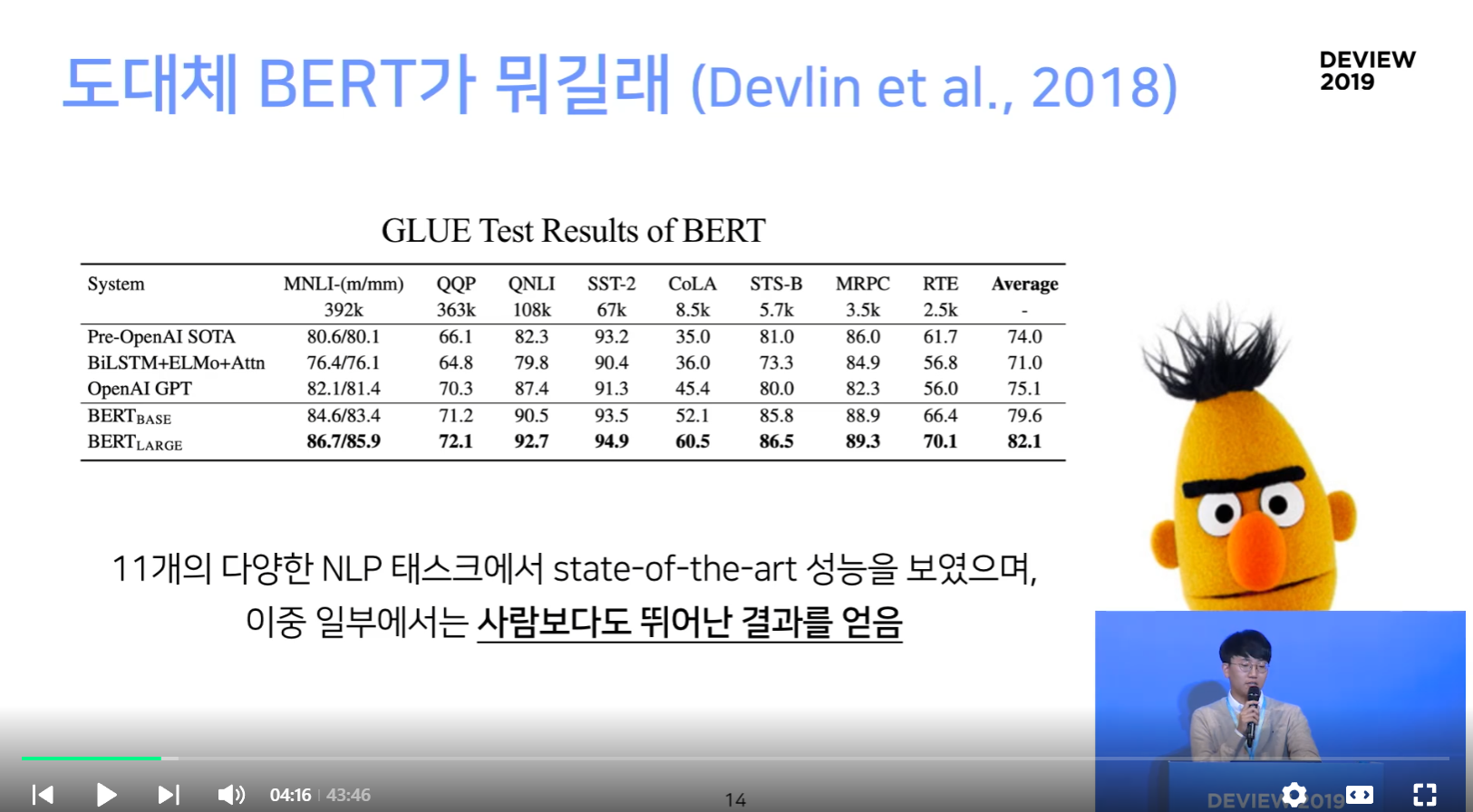
BERT 란?

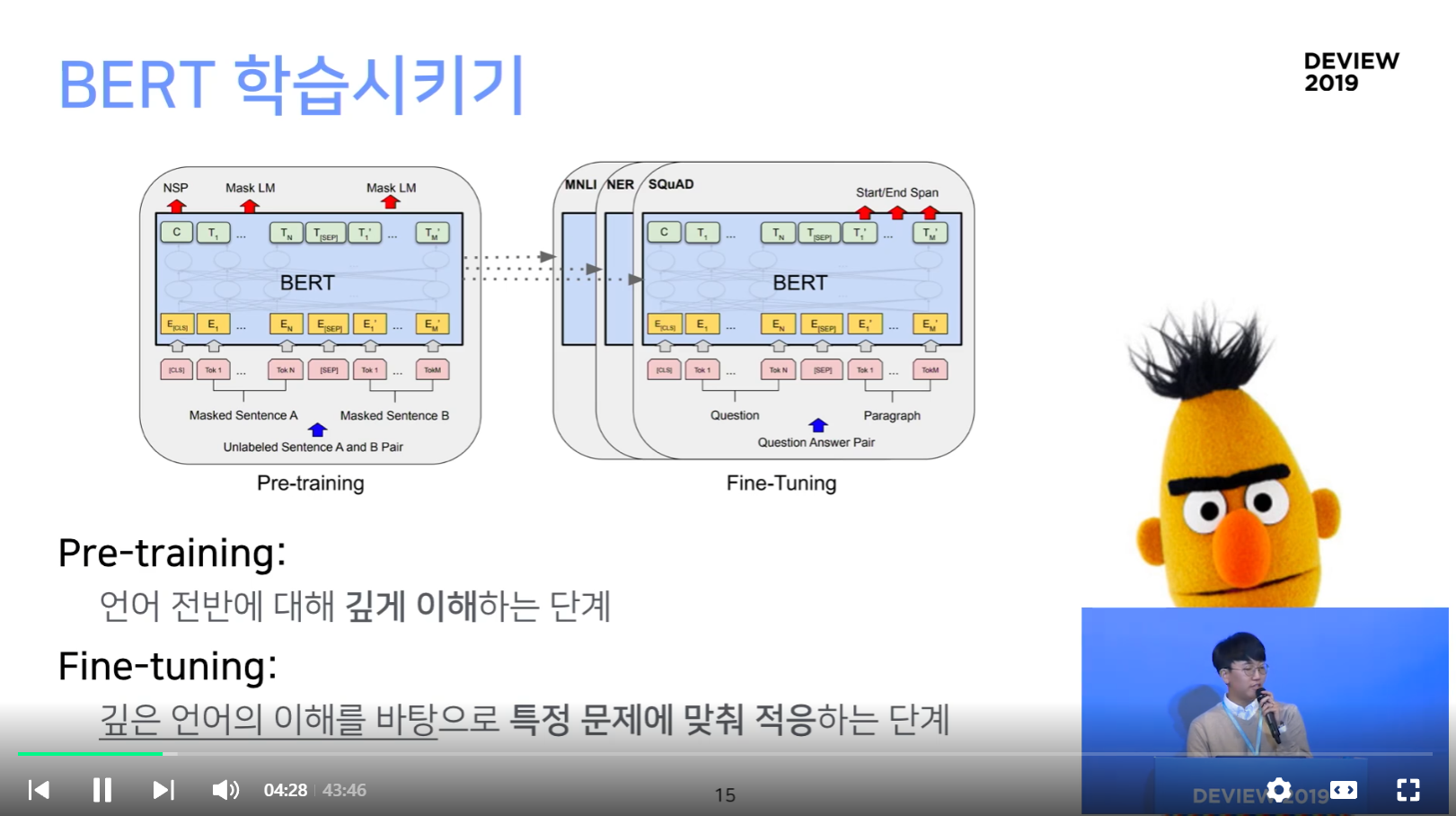
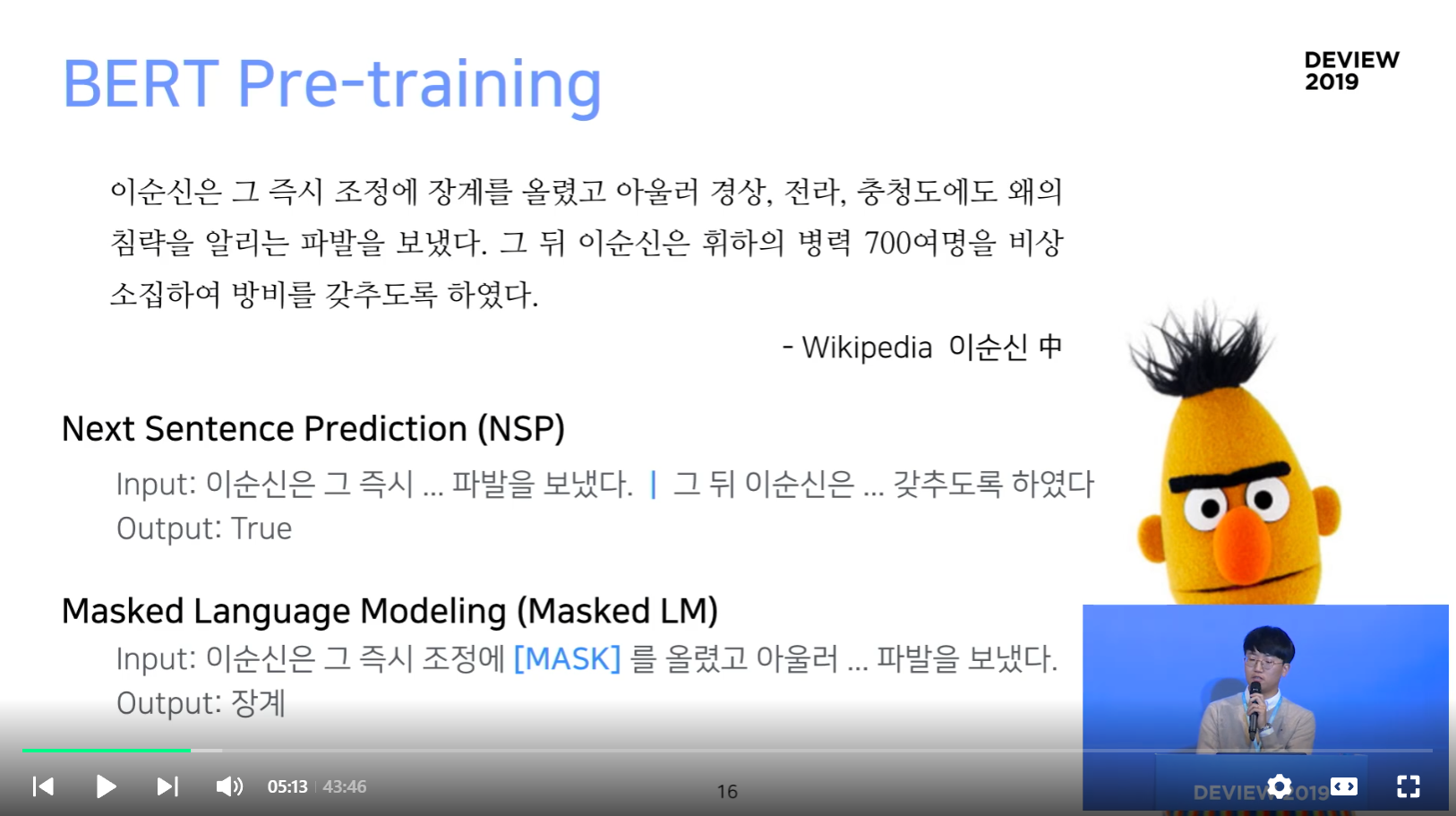
BERT Pre-Training
- ALBERT, RoBERTa 등 다양한 학습 방법 제시
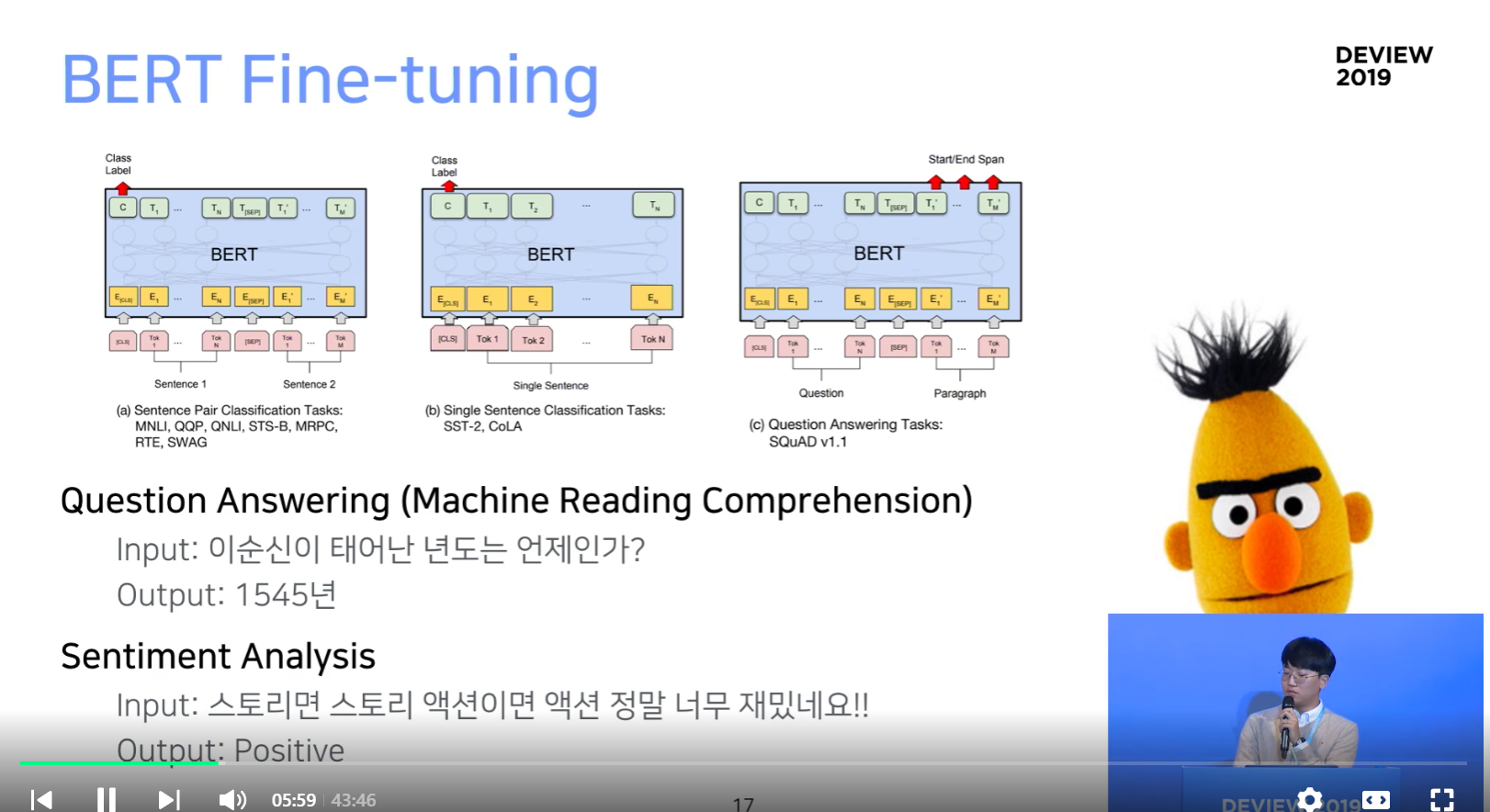
BERT Fine-tuning
2. 일상대화를 위한 Dialog-BERT 학습시키기 (Pre-trainig)
세 가지 문제에 대해 결과 분석
- LM (Perlexity)
- NSMC (Naver Sentiment Movie Corpus)
- Intent (Intent Classification) : 의도 분류
Mecab + SentencePiece 가 모든 태스크에서 좋은 성능을 보임
- Space (공백 기준)
- Char (자모 단위)
- 확실히 한국어에서는 Space에서 성능이 좋지 않음
- 반면 Char (자모 단위)에서는 어느정도 준수한 성능을 보임
- LM 에서 Mecab이 조금 더 성능이 좋은데, 그 이유는 조사(형태소 단위)를 분리해주기 때문


- Vocab size: 30,000 (OOD 비율이 1% 미만)
고민1. 대화체로 학습시켜도 괜찮을까?

문어체와 구어체의 차이점
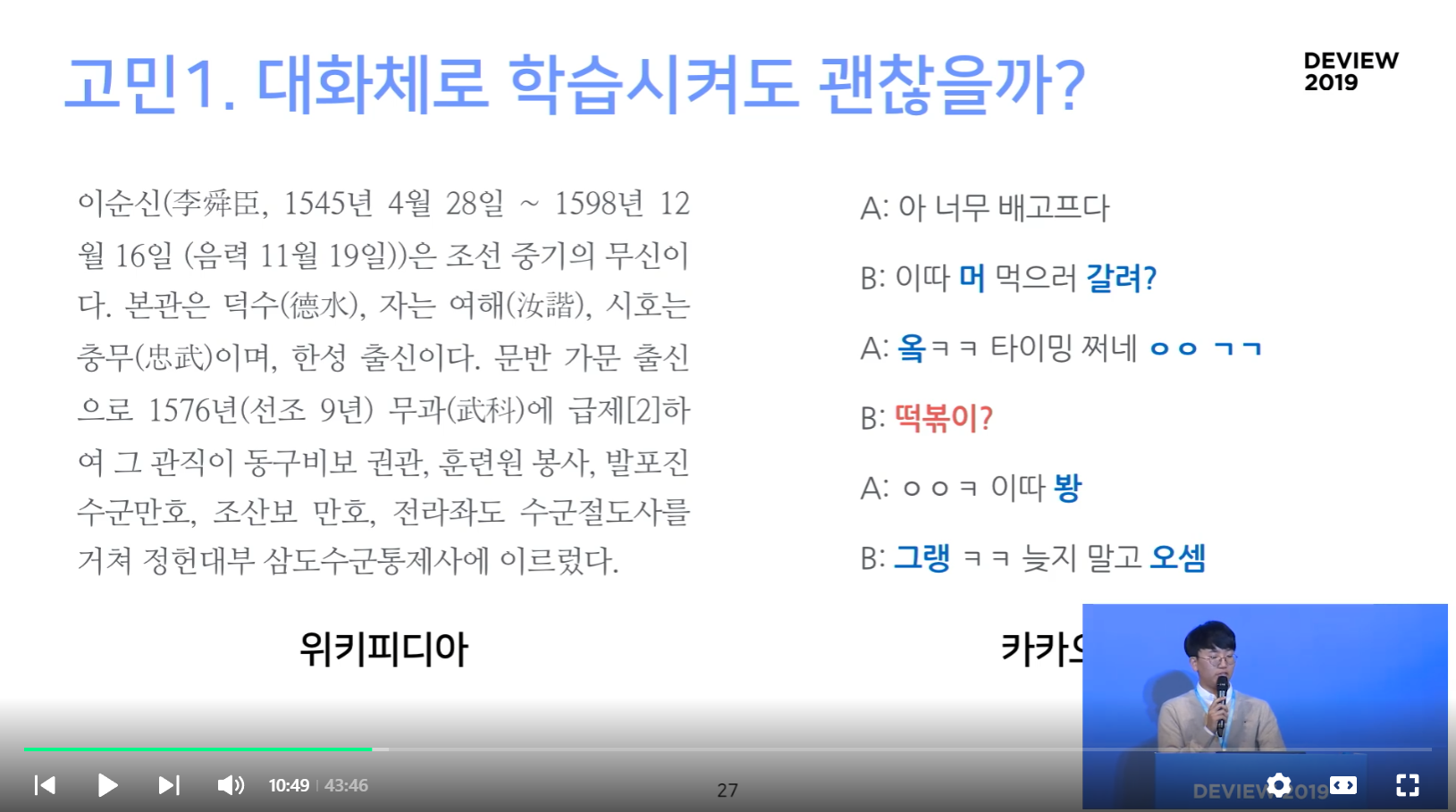
- 문장의 길이가 다름
- 문어체는 김 (위키피디아)
- 구어체는 짧음 (카카오)
- 구어체의 특성
- (파란색) 말의 변형이 심함 (ex. 봥, 그랭, 머, 갈려?)
- (빨간색) 생략된 의미가 많음 (ex. 우리 떢볶이 먹을까? -> 떢볶이?)
1. 대화체로도 충분히 학습이 잘 된다
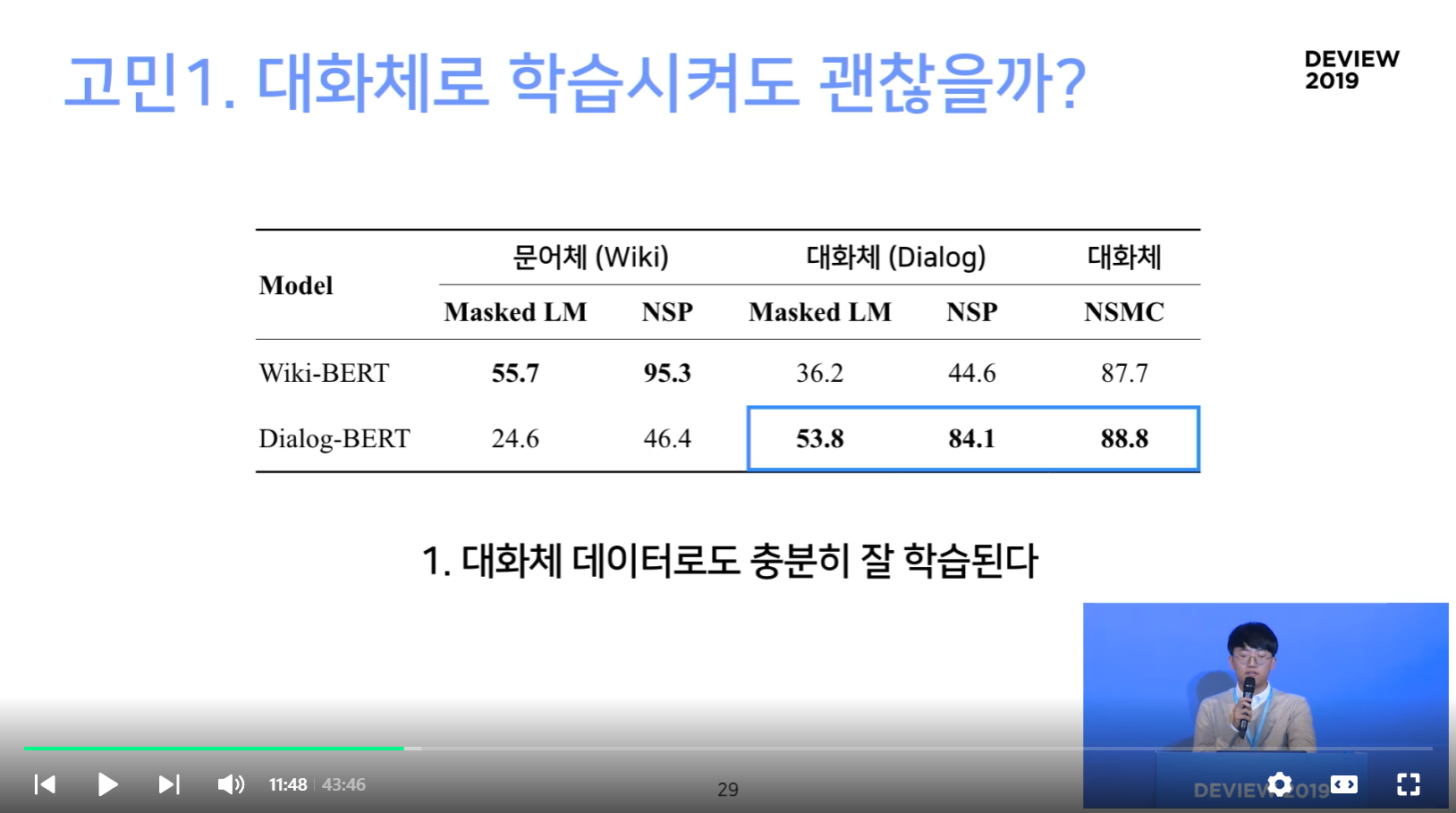
- 잘 수렴을 한다
- NSMC(대화체)에서도 좋은 성능을 보인다 (왜냐, 댓글이 보다 구어체적인 성격이 많기 때문)
2. 서로 다른 도메인에서는 성능이 매우 떨어진다
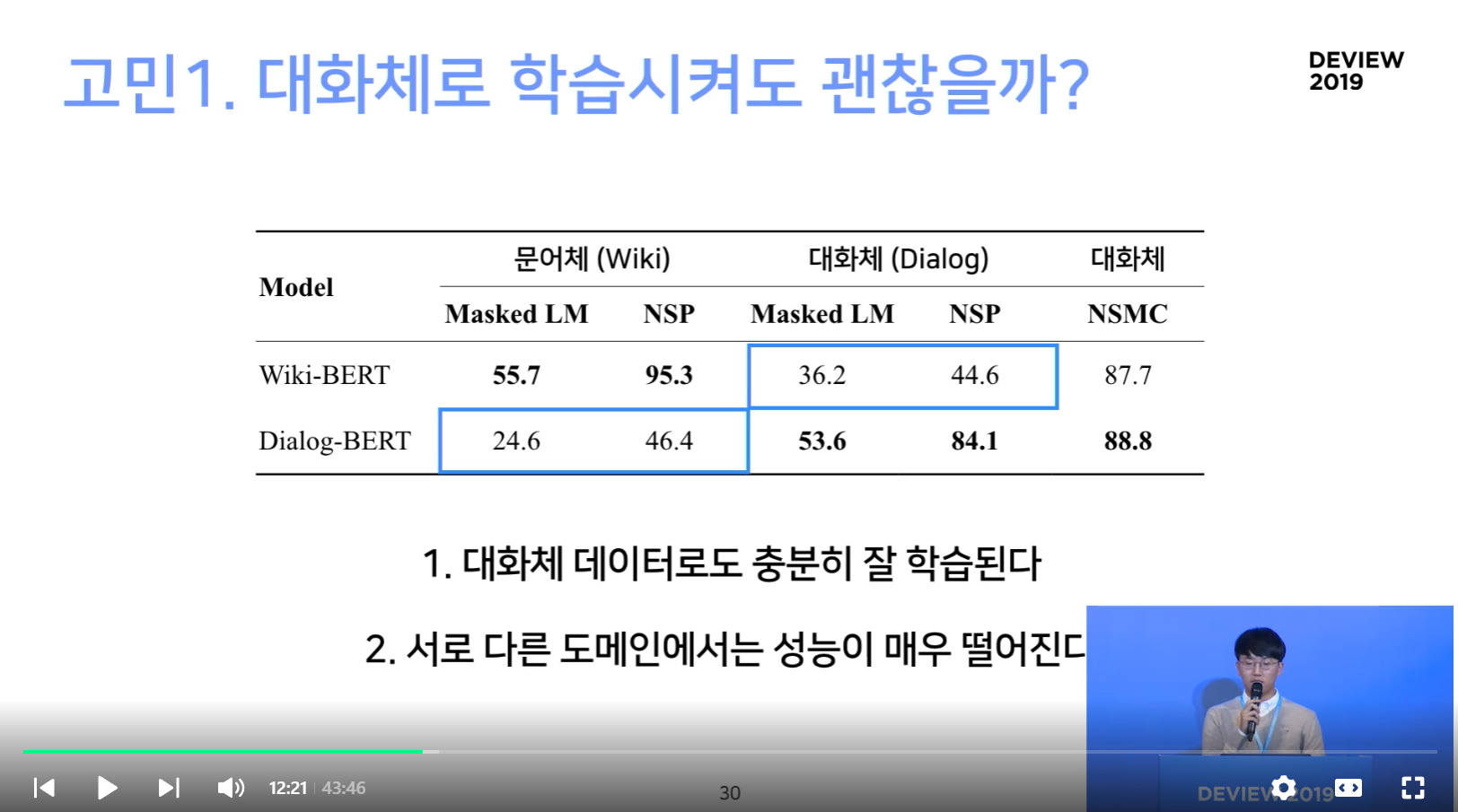
- 문장 형태가 달라졌기 때문
- 같은 한국어지만 구어체와 문어체는 다름
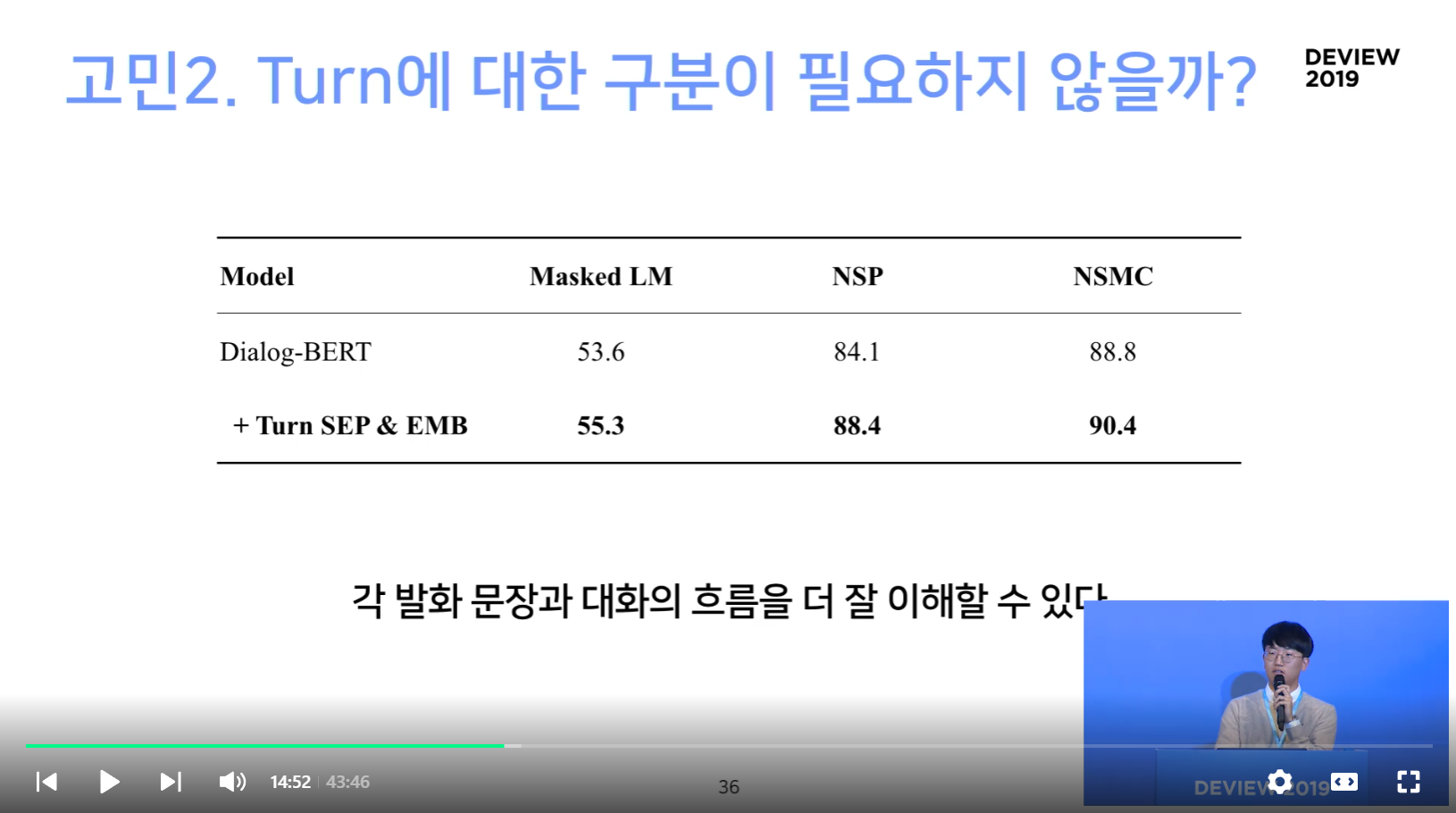
고민2. Turn에 대한 구분이 필요하지 않을까?
대화체의 특성을 고려하여, Turn을 구분하자

[JG] Segment(Session?) Embeddings의 역할이 무엇?
- 옼ㅋㅋ...ㅋㅋㅋ 는 다른 대화 세션을 의미?

SEPT 토큰 추가
- 각 Utterance 를 구분짓는 토근인 SEPT 토큰 추가
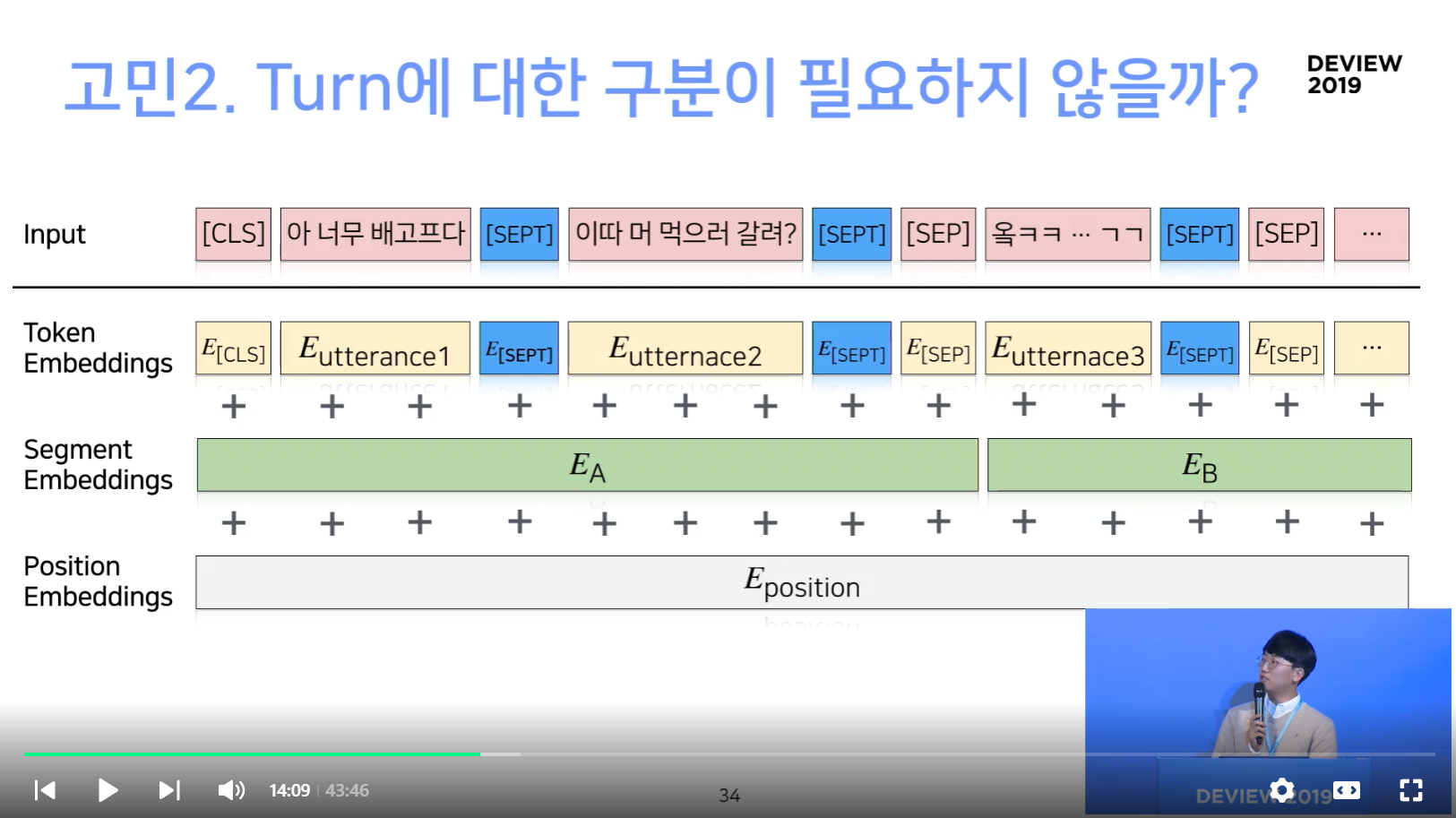
Turn Tokens 추가

[결론] Turn SEP & EMB를 통해 성능 향상
Dialog-BERT Configuration

- 특징
- 128 max_len -> 48 max_len
- 하루~이틀만 학습해도 어느 정도 성능 확보 가능
3. Dialog-BERT로 일상대화 태스크 해결하기 (Fine-tuning)

일상대화의 모호성

- 일련의 과정을 거치는데 그것에 대한 분류가 필요함
일상대화 태스크
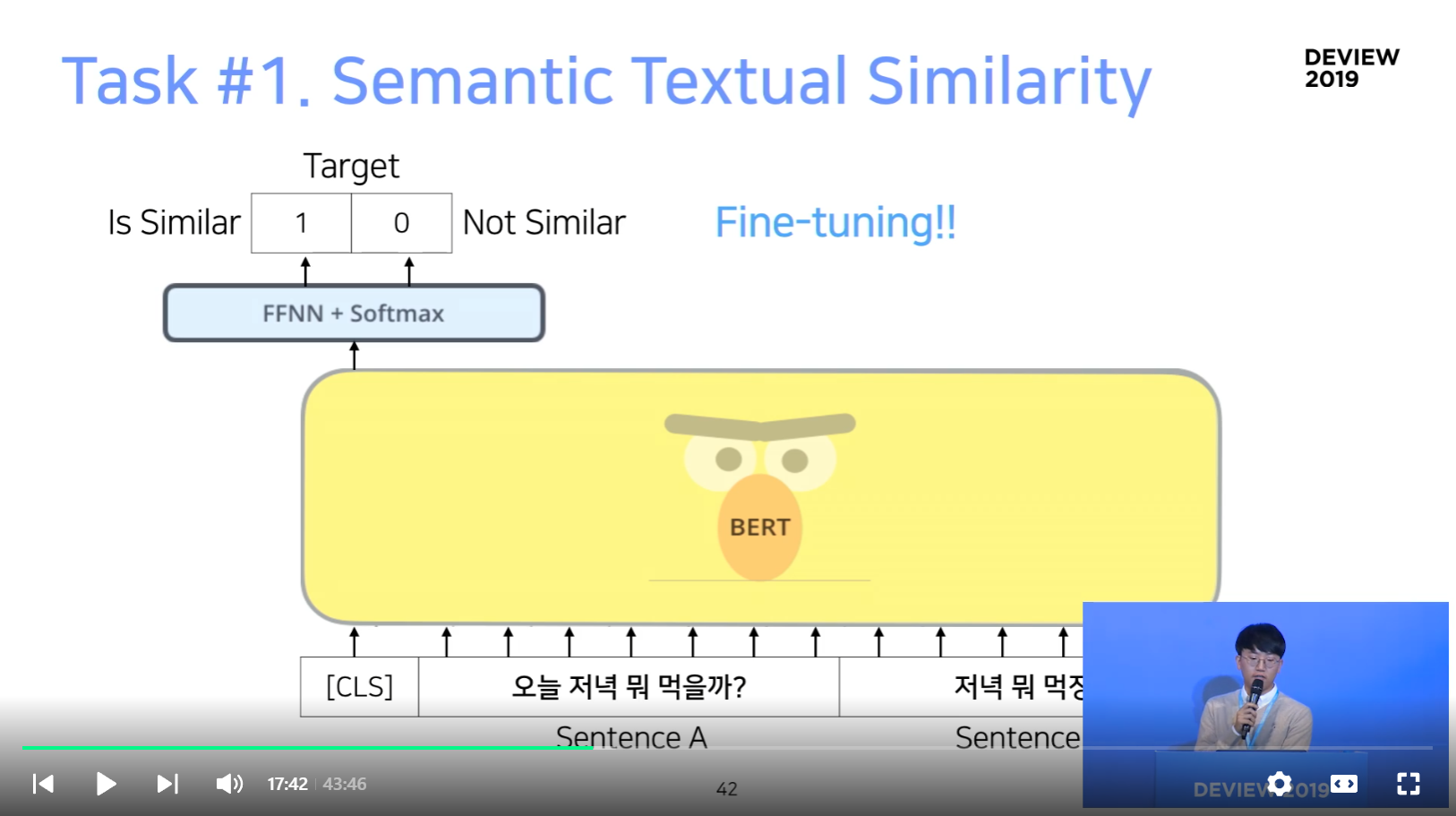
Task #1. Semantic Textual Similarity



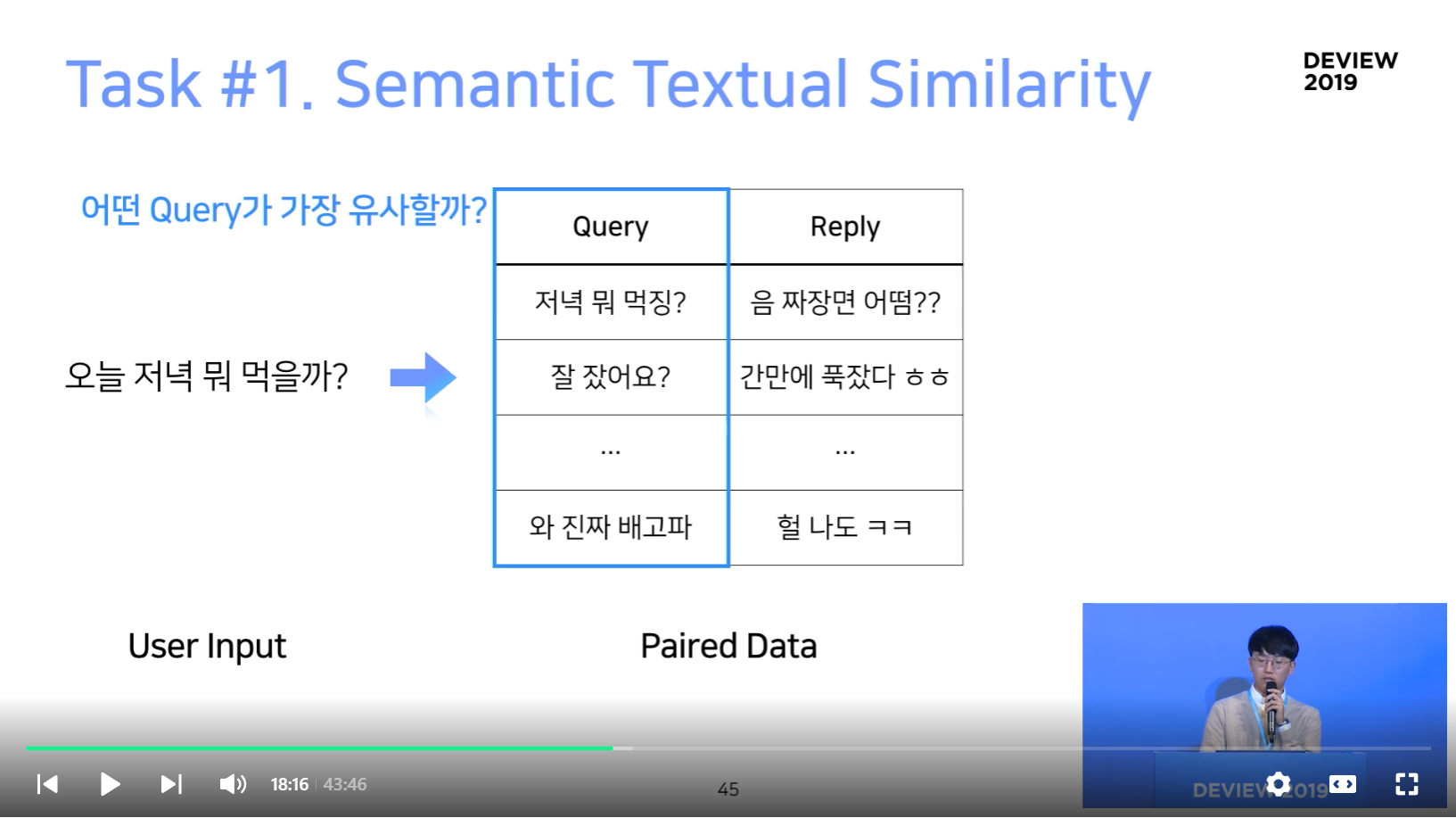
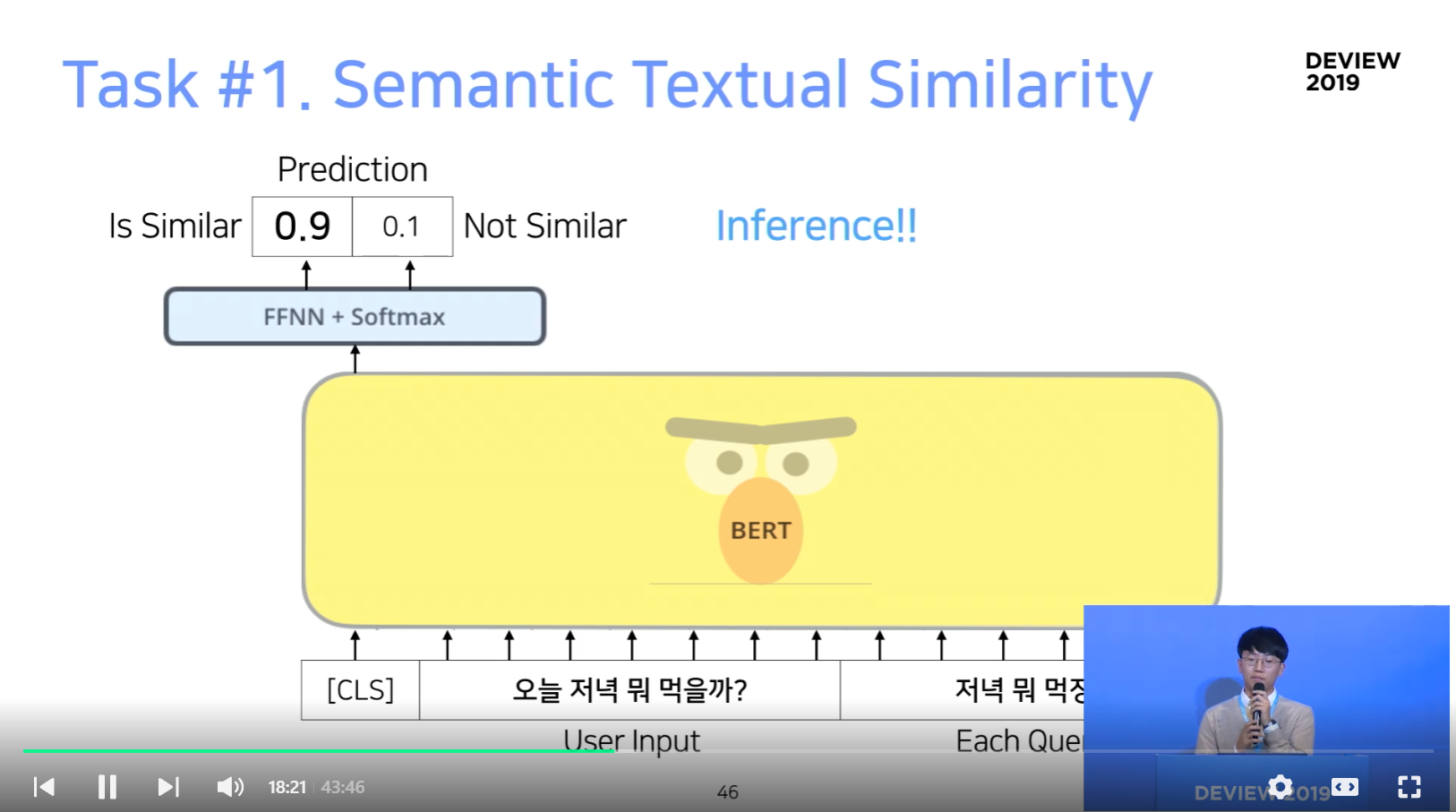
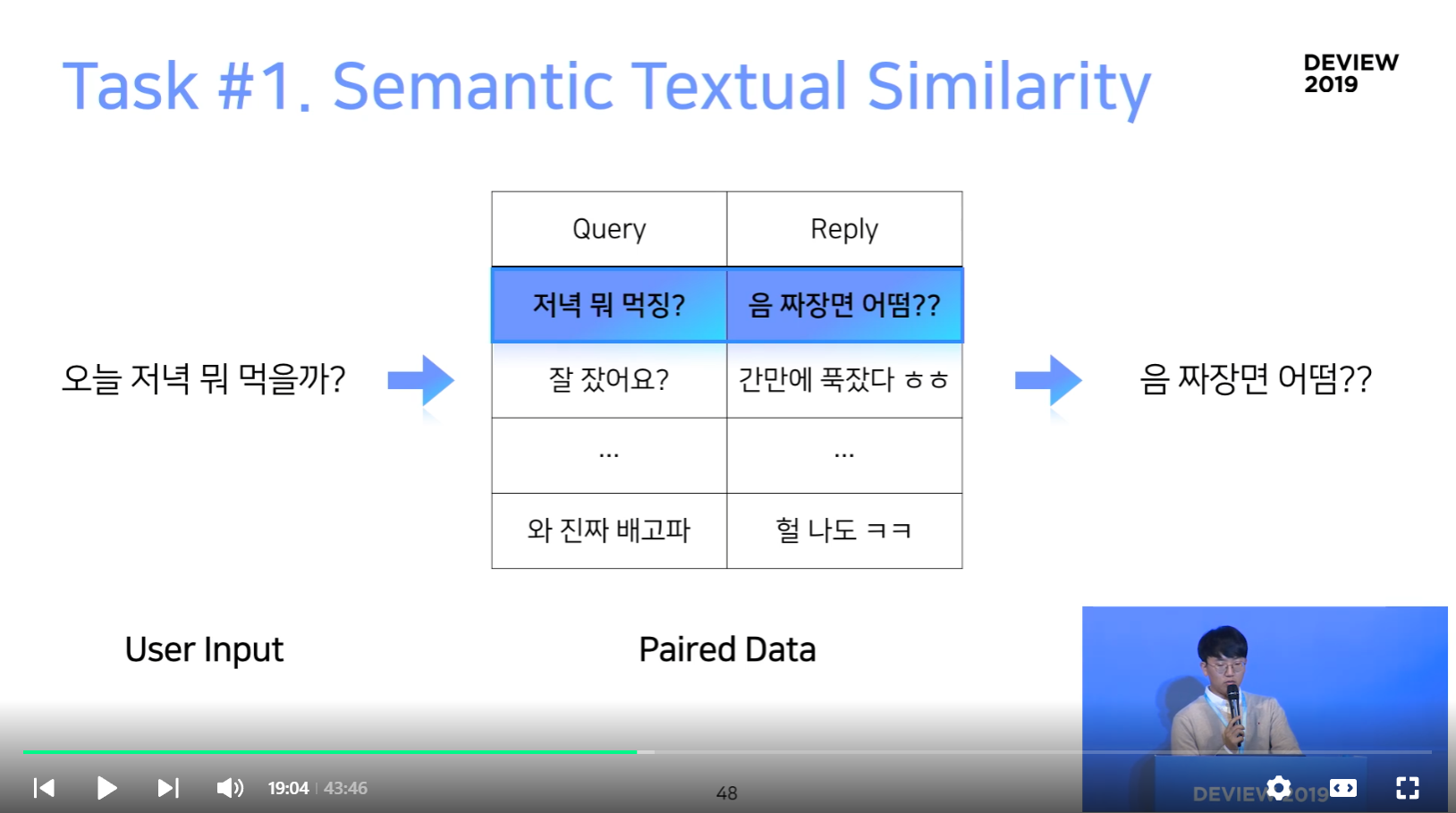
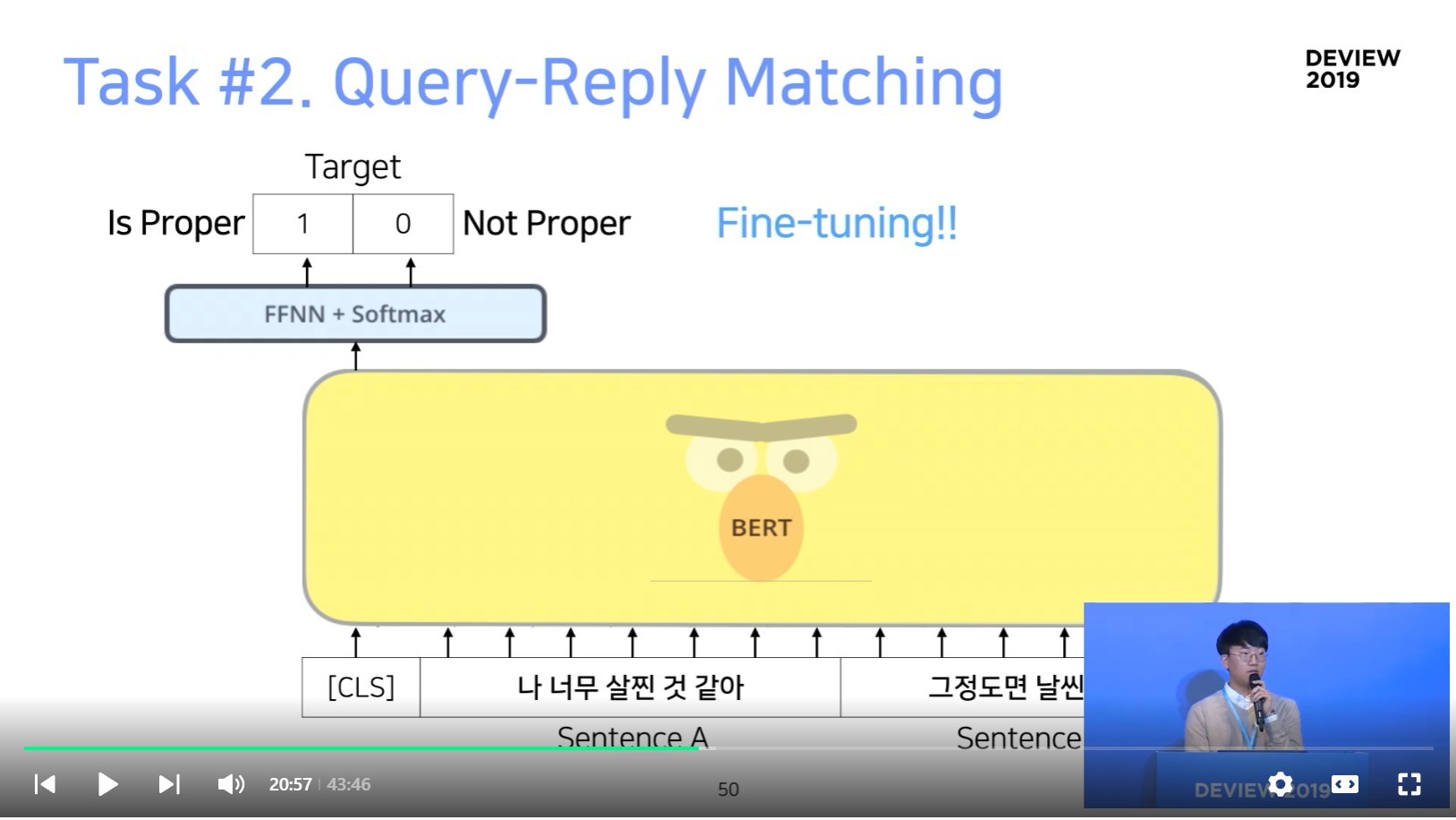
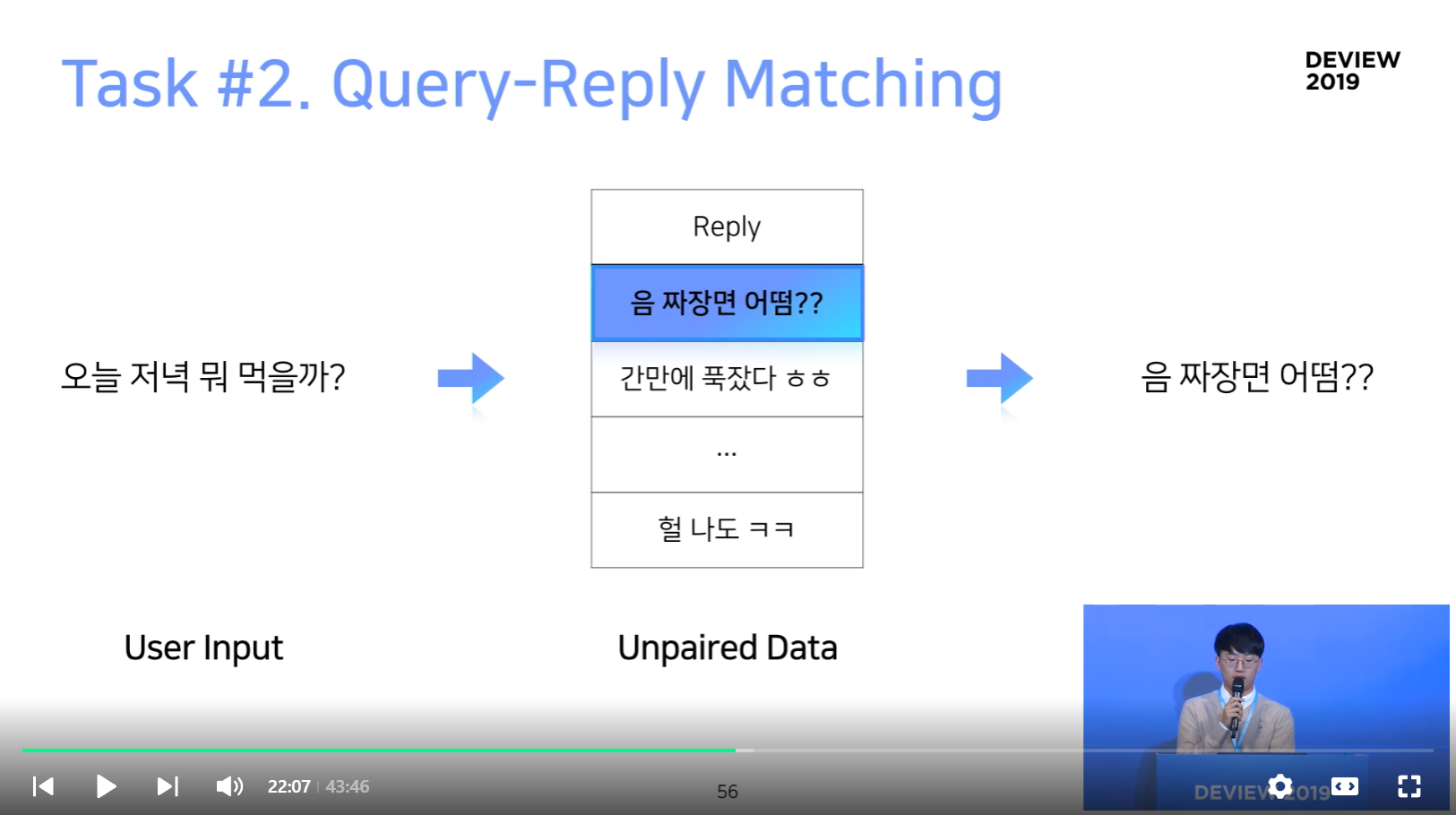
Task #2. Query-Reply Matching

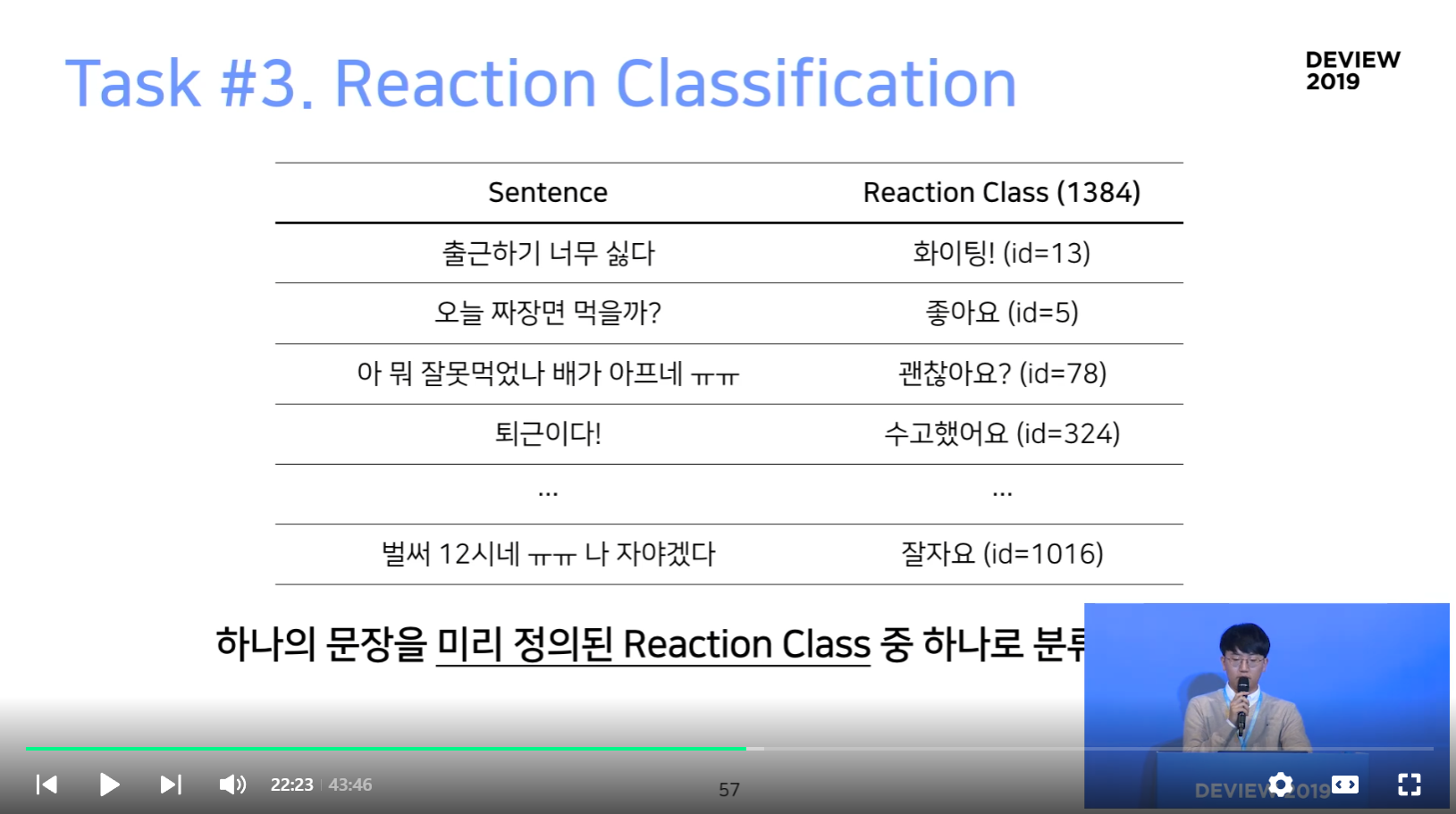
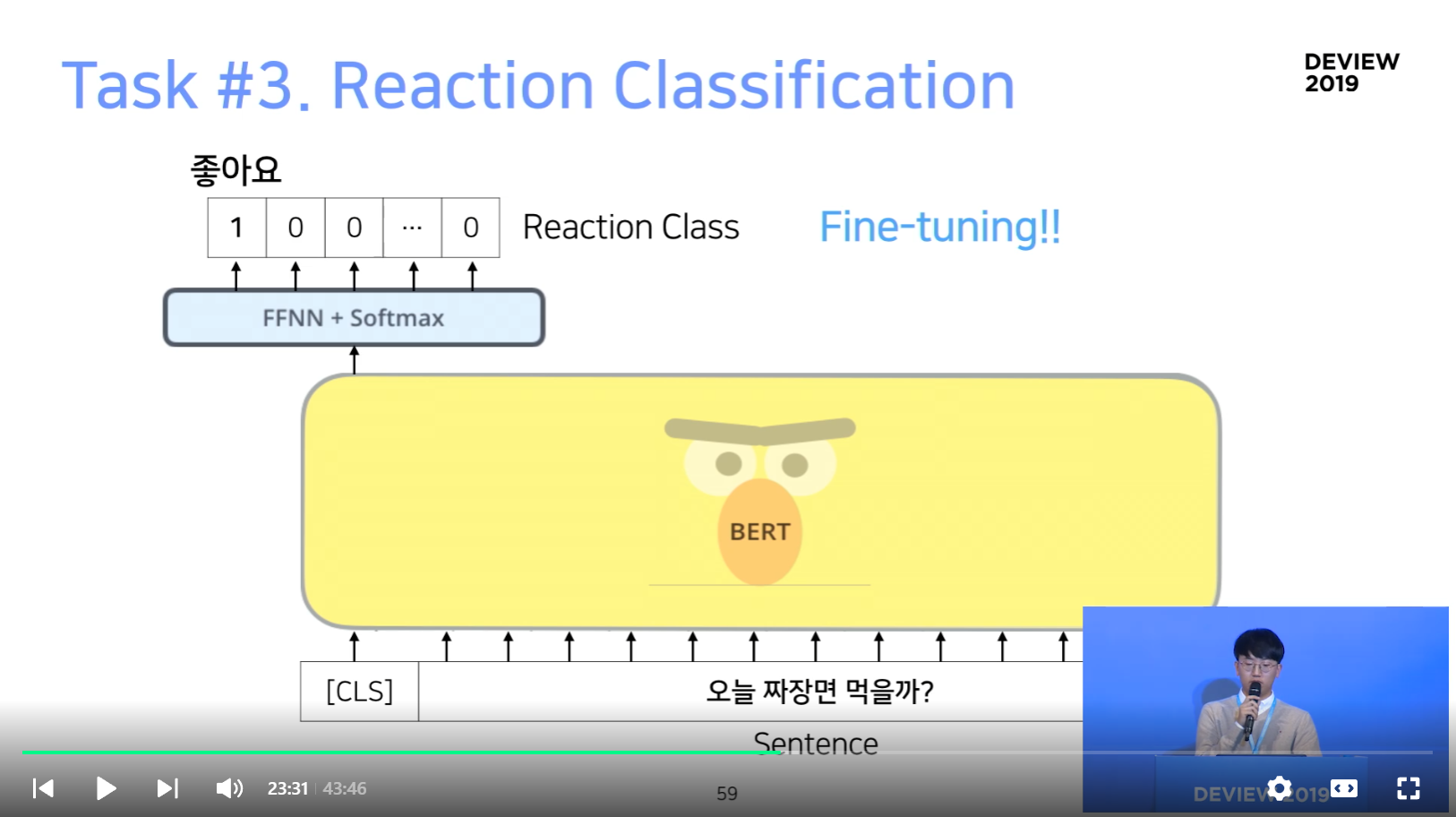
Task #3. Reaction Classification
Motivation
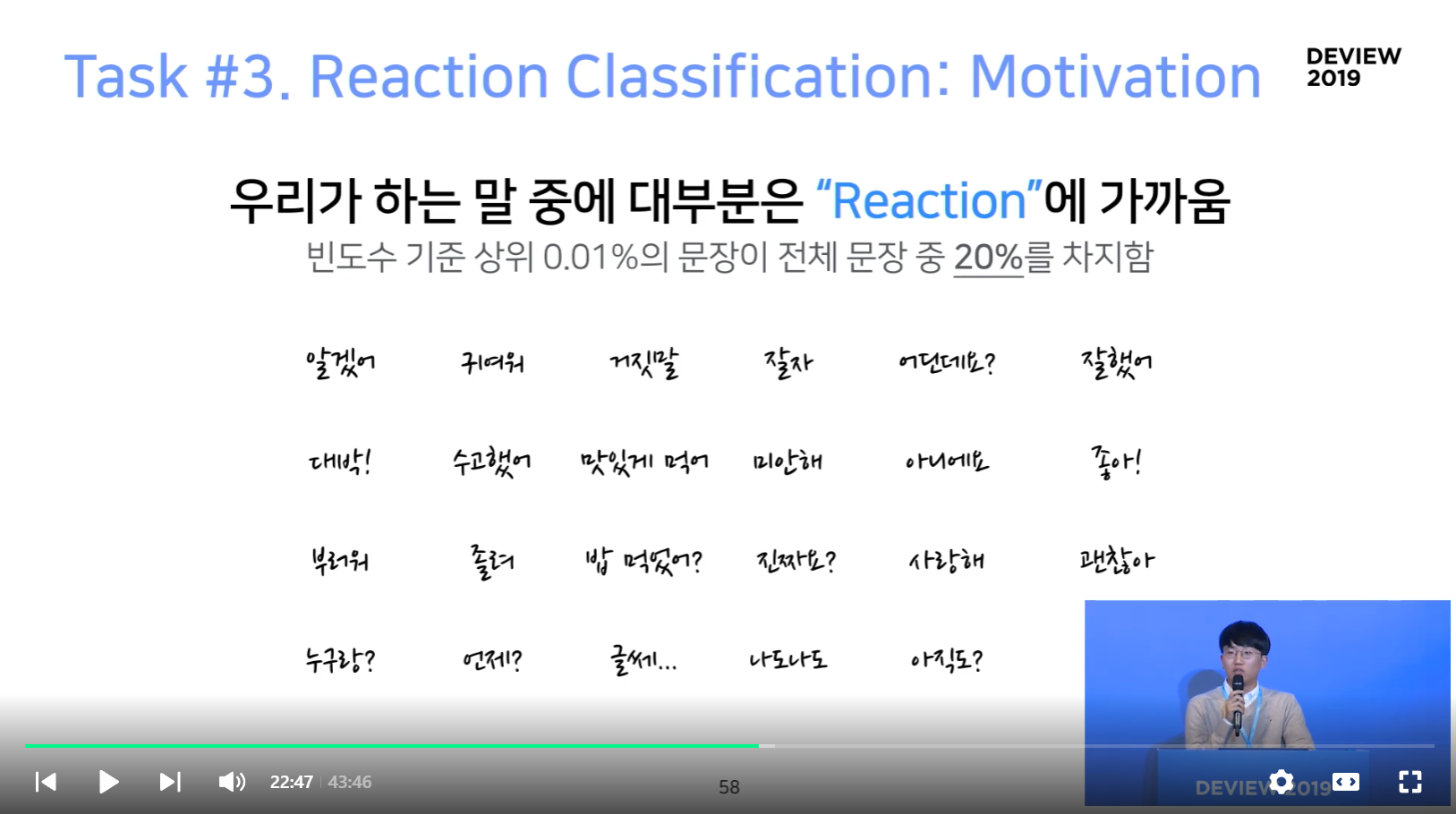
- 우리가 하는 말 중에 대부분은 "Reaction"에 가까움
- 빈도 수 기준 상위 0.01% 의 문장이 전체 문장 중 20%를 차지함

- 리액션만 잘 해도 웬만한 대화는 커버 가능
- 1384 개의 리액션 predefined class set 정의


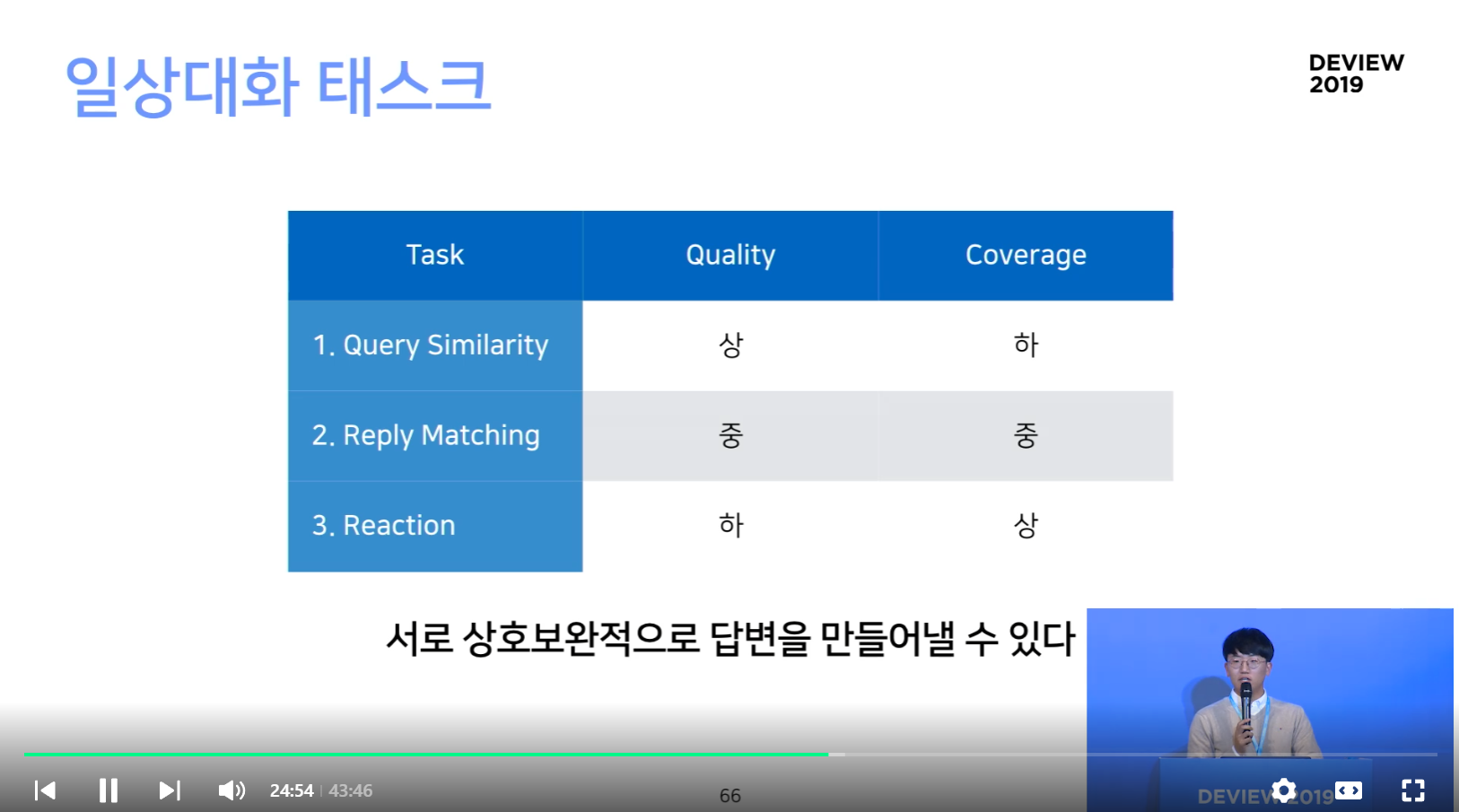
상호 보완적 관계에 있는 세가지 태스크
-
Query Similarity는 유사한 Query를 찾으면 되지만, 동일한 Query가 없을 경우가 많으므로 Coverage가 낮다.
-
반대로 Reaction은 대답의 적절성은 떨어지지만, Coverage 는 높다.
일상대화 태스크 성능
1. Scatter Lab의 태스크
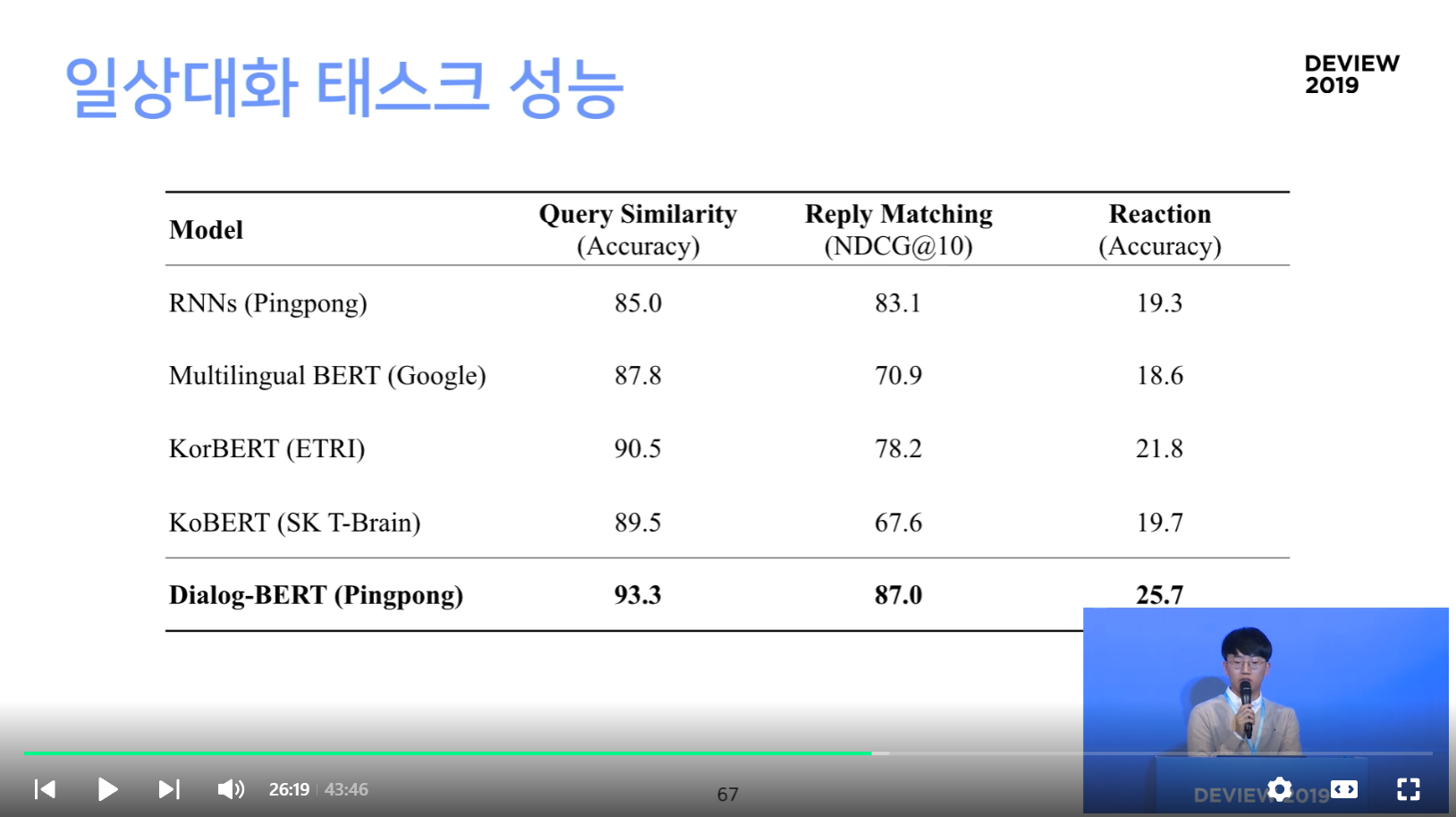
- 문어체와 대화체의 차이가 여기에서도 두드러짐
2. 기존 벤치마크 태스크
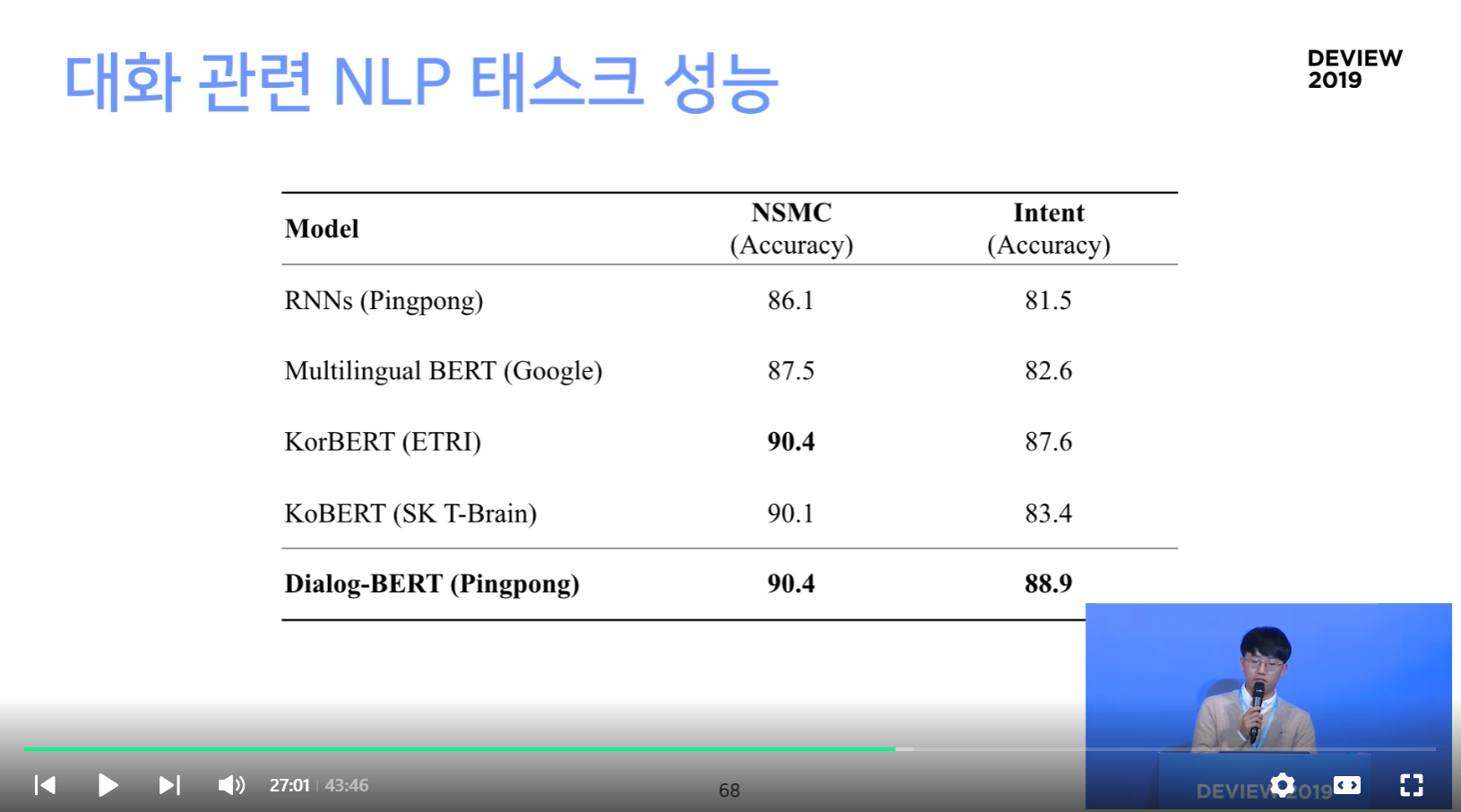
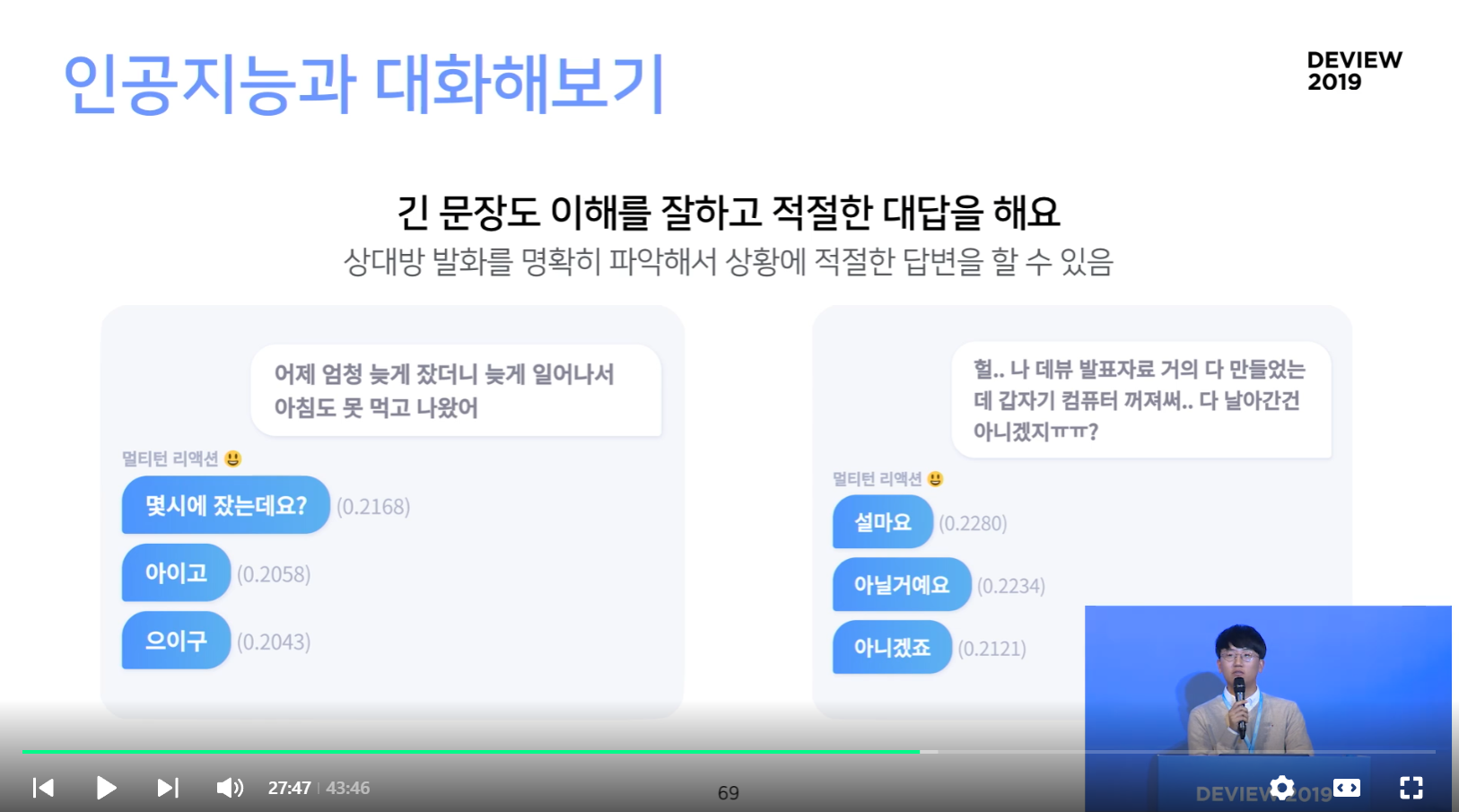
인공지능과 대화해보기
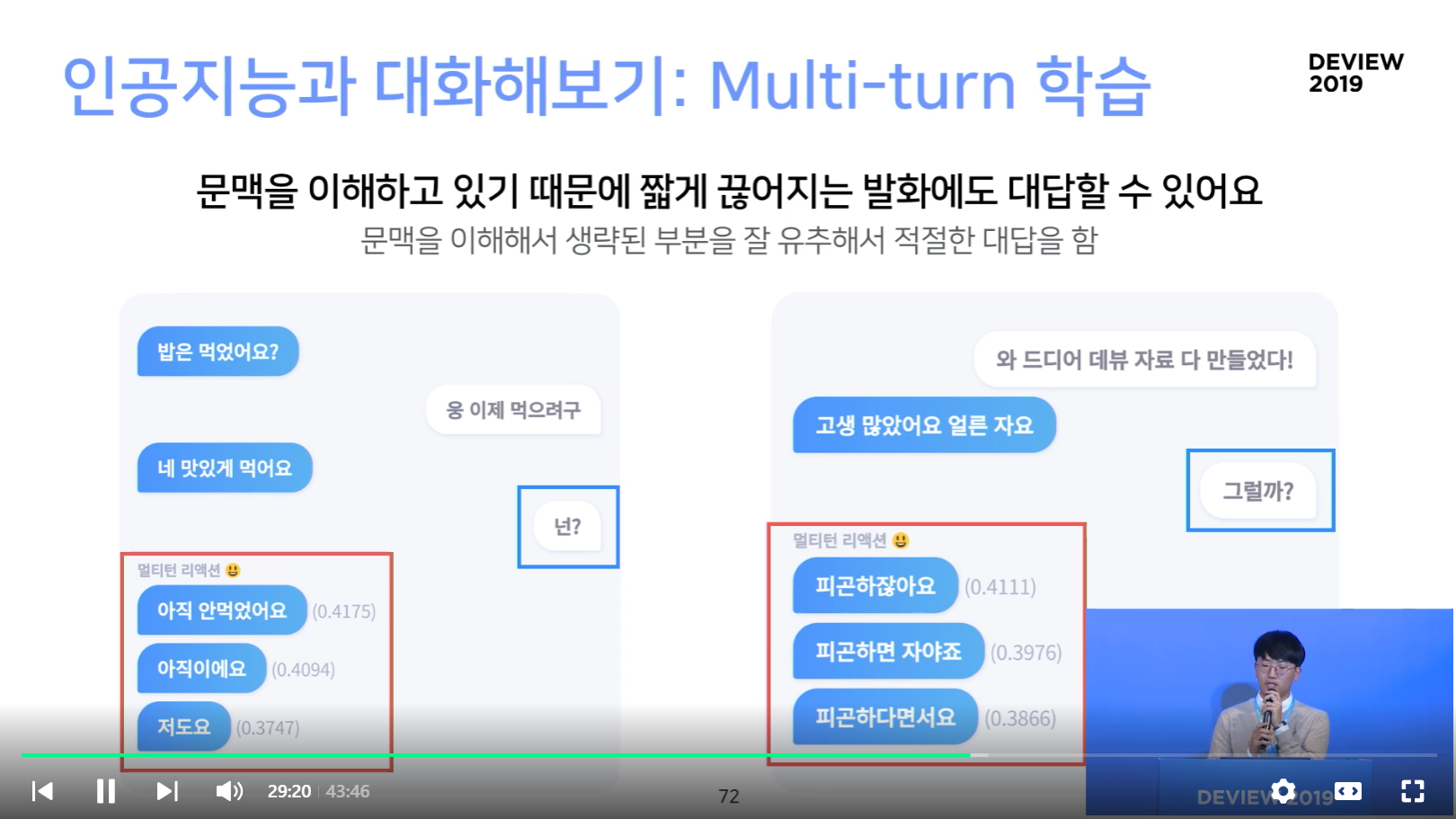
긴 문장도 이해하고 적절한 대답을 해요
- 상대방 발화를 명확히 파악해서 상황에 적절한 답변을 할 수 있음
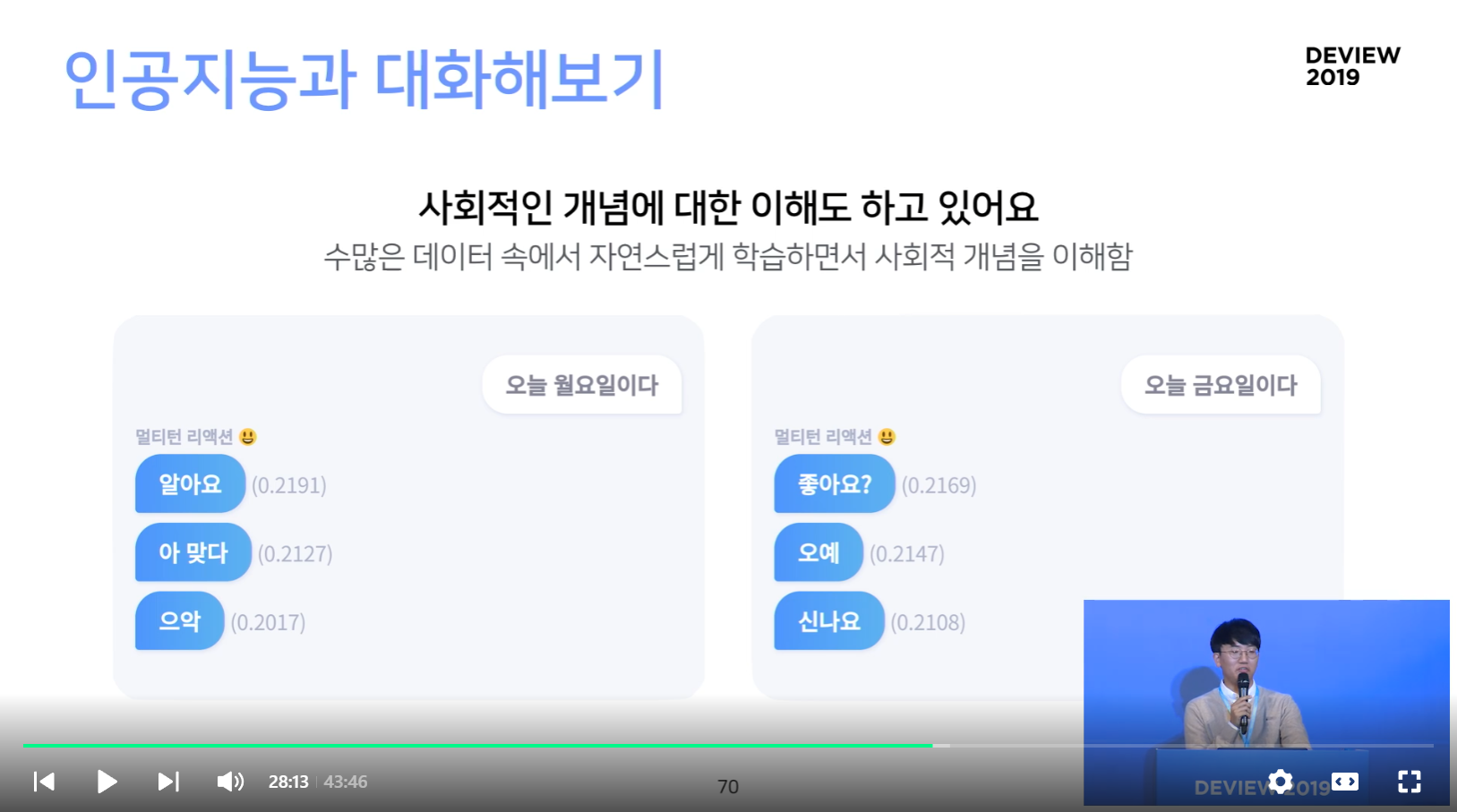
사회적인 개념애 대한 이해도 하고 있어요
- 수많은 데이터 속에서 자연스럽게 학습하면서 사회적 개념을 이해함
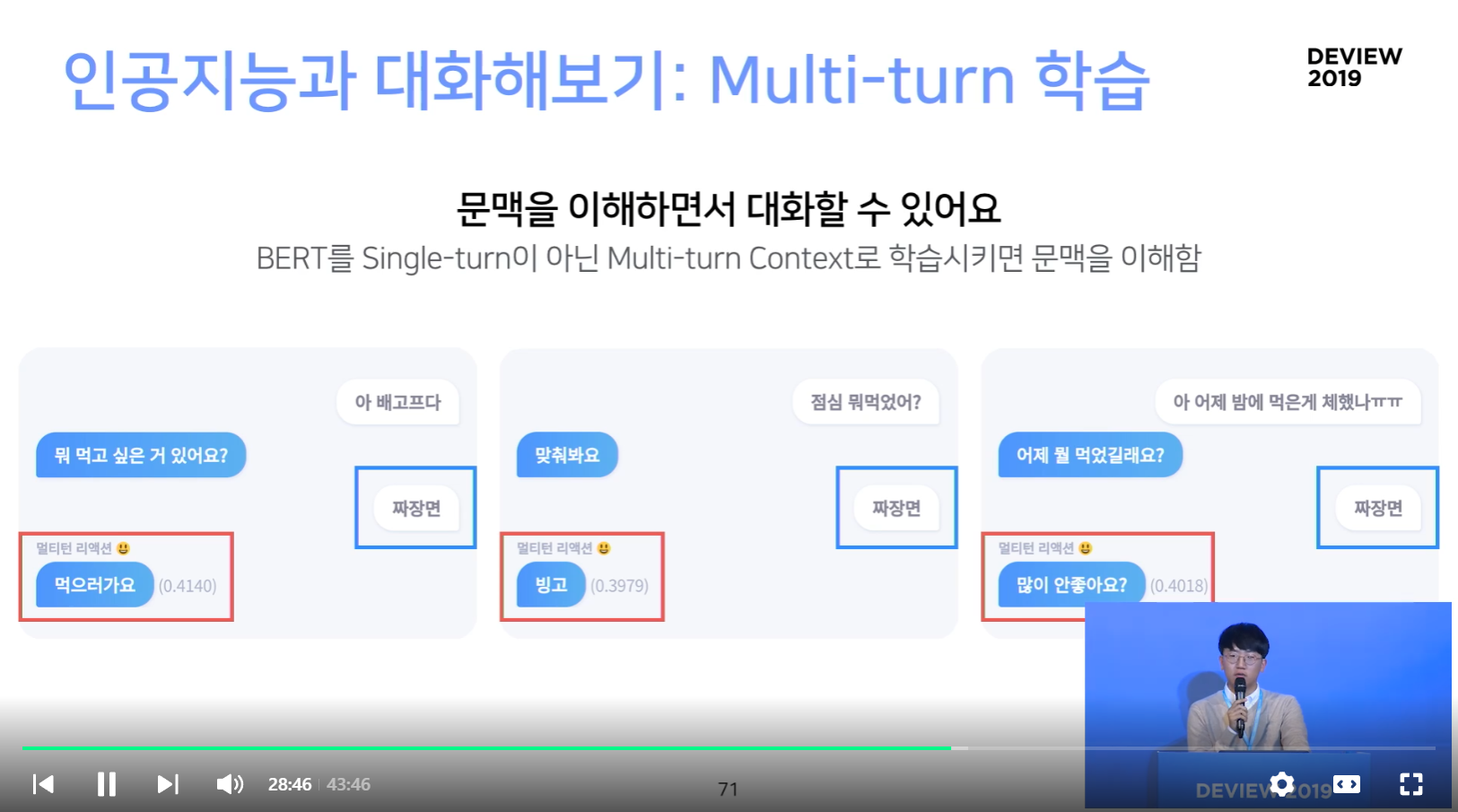
Multi-turn 학습
- BERT를 Single-turn 이 아닌 Multi-turn Context로 학습시키면 문맥을 이해함
4. 서비스를 위한 BERT 경량화

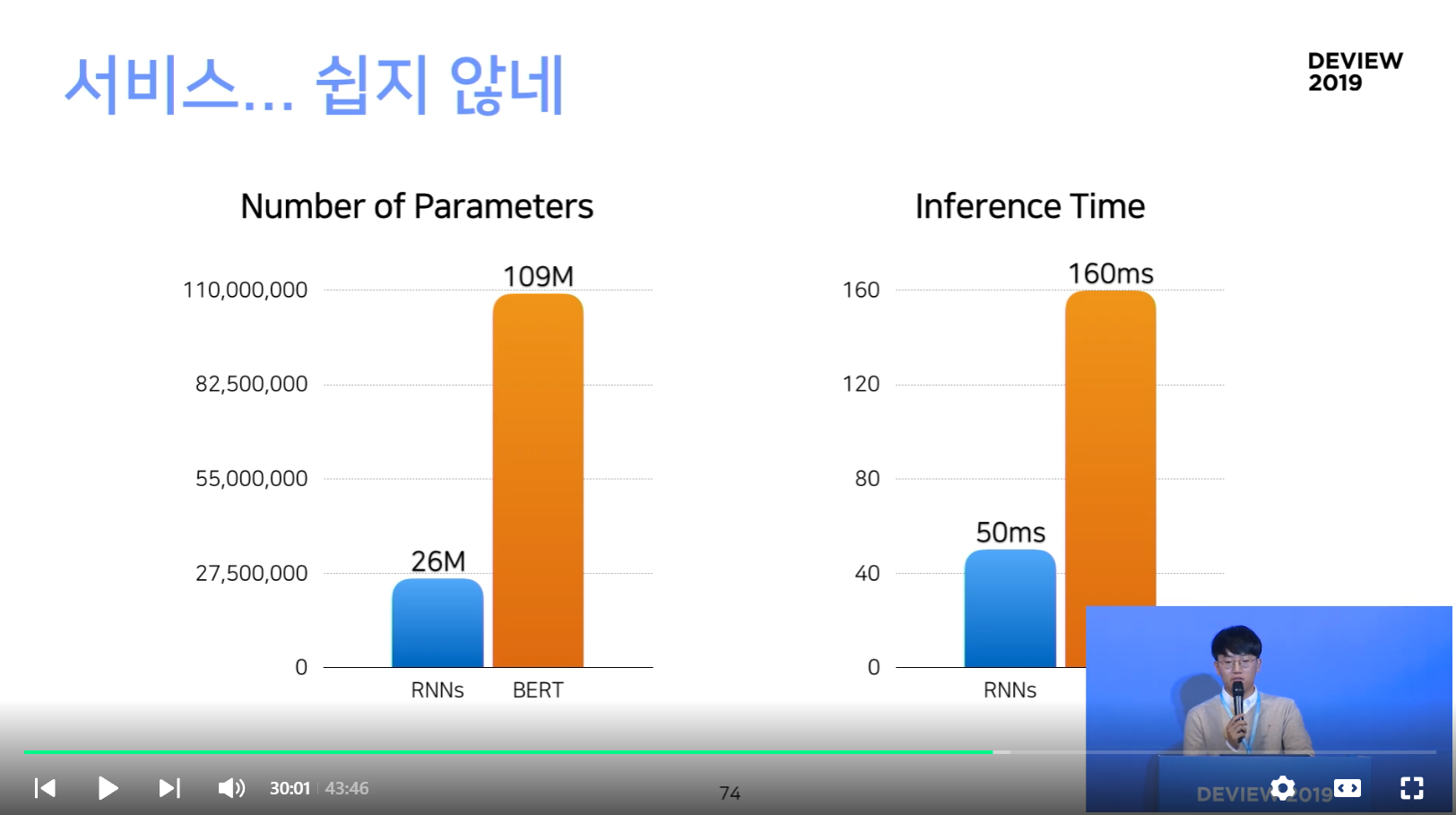
서비스를 하기 위해 필연적으로 겪는 이슈..
모델 경량화!

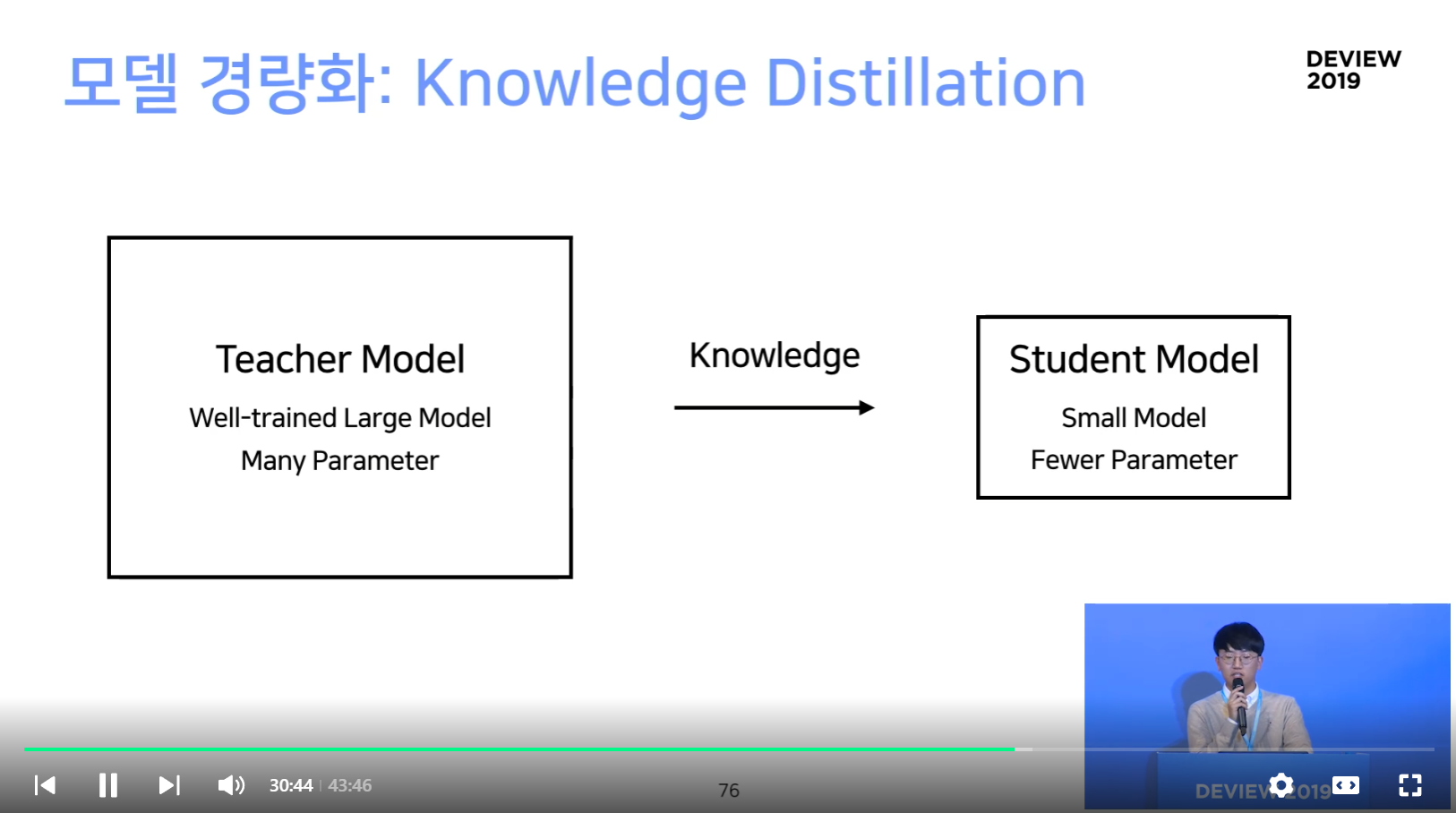
- 티처 모델의 softmax output을 학습 레이블로 활용
- 하드 레이블 (특정 라벨만 1) 보다, 오히려 기존 모델의 knowledge를 잘 전수받으면서 빠르게 학습할 수 있음.

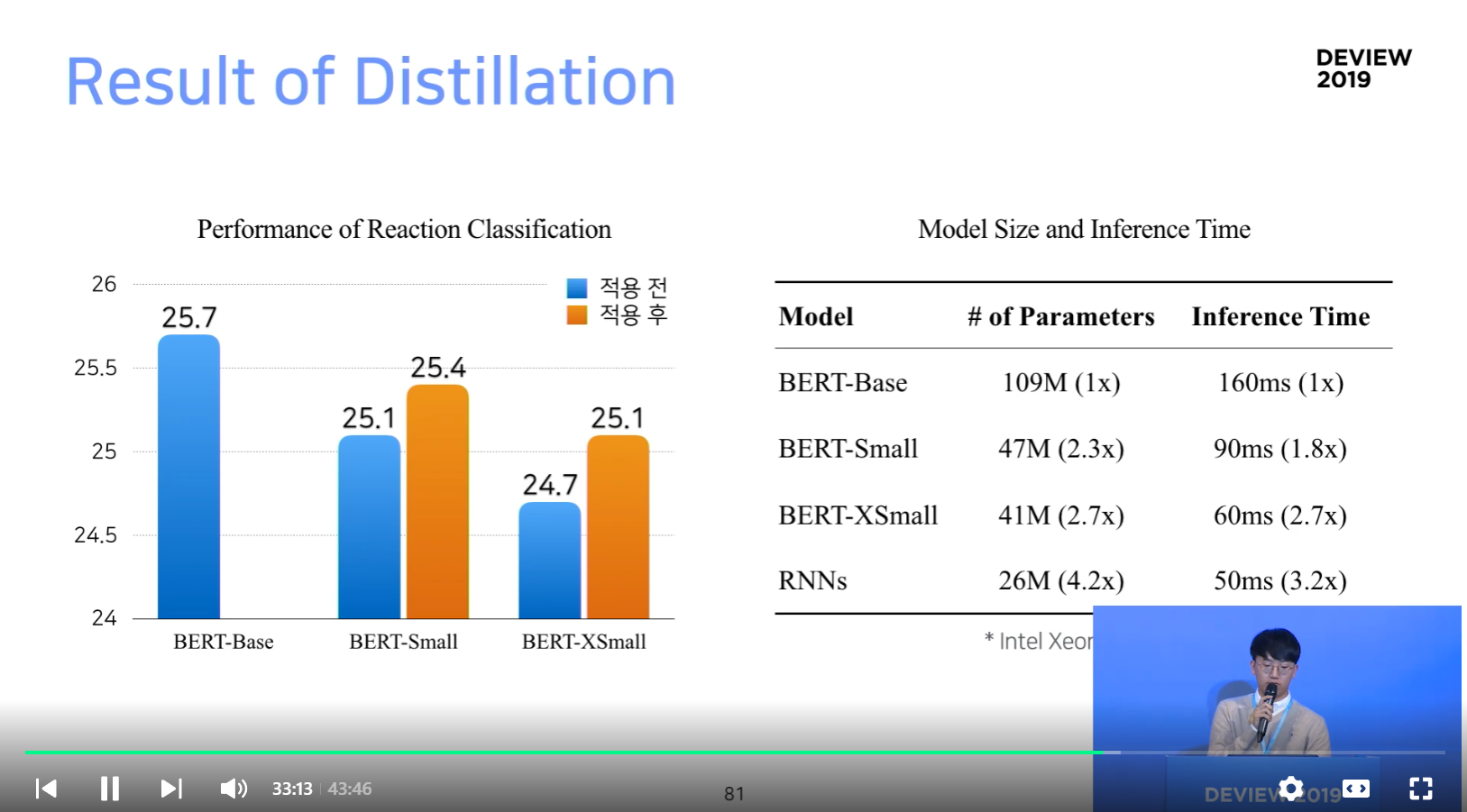
Distillation
- 경량화는 fine-tune 방식으로 적용됨 (즉, pre-train 된 것 사용)

- Reaction Classification에 적용
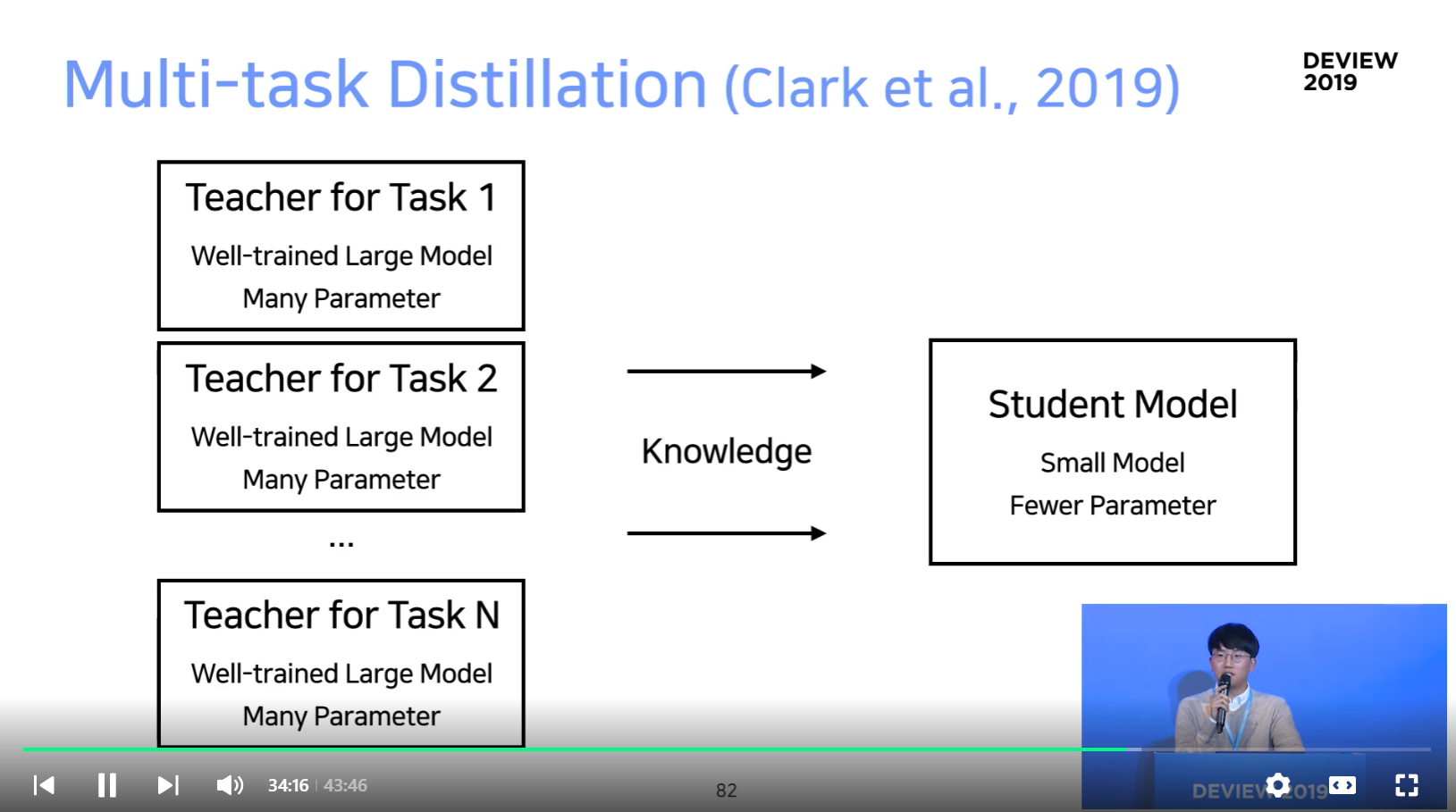
Multi-task Distillation
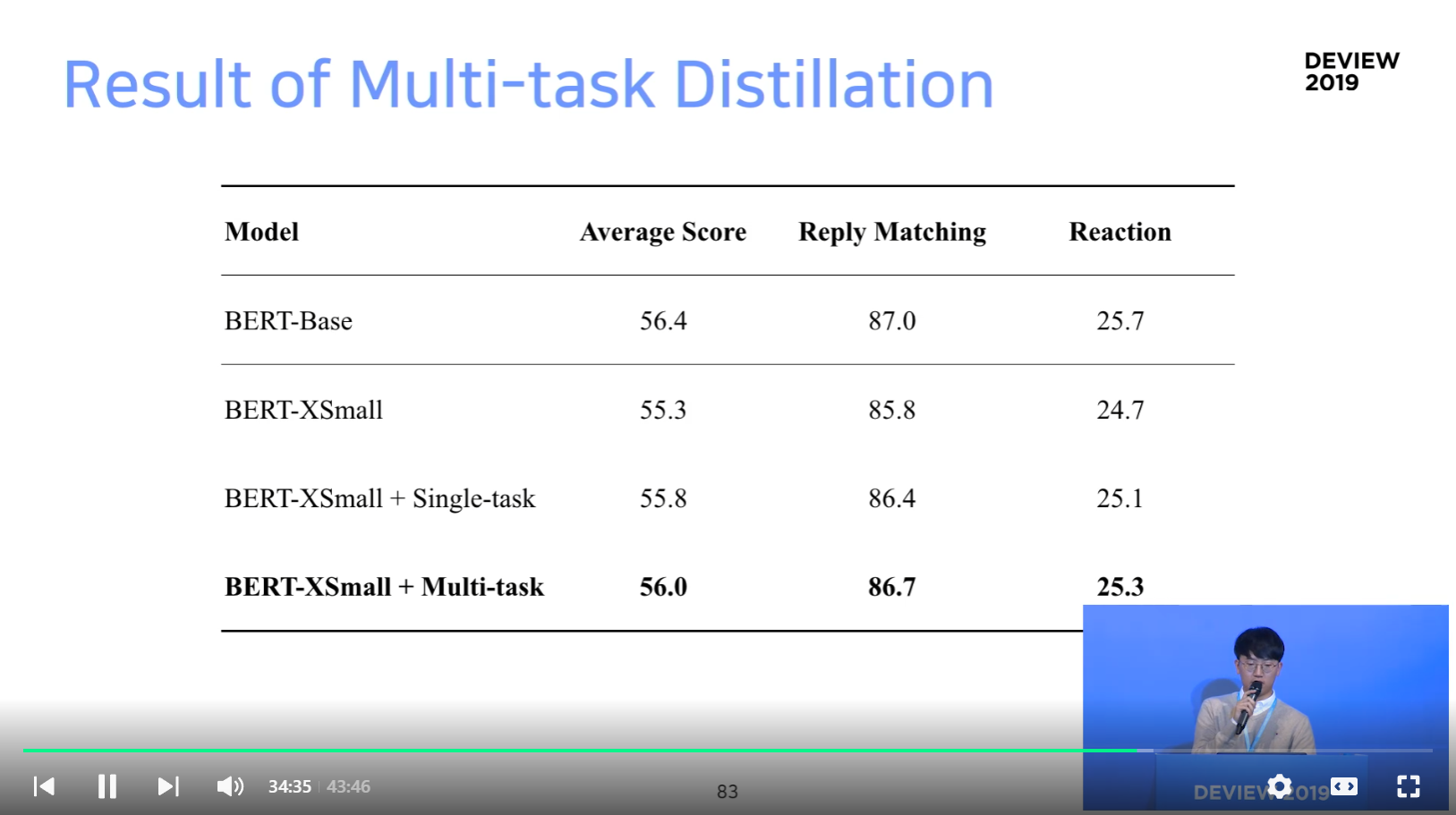
Conclusion
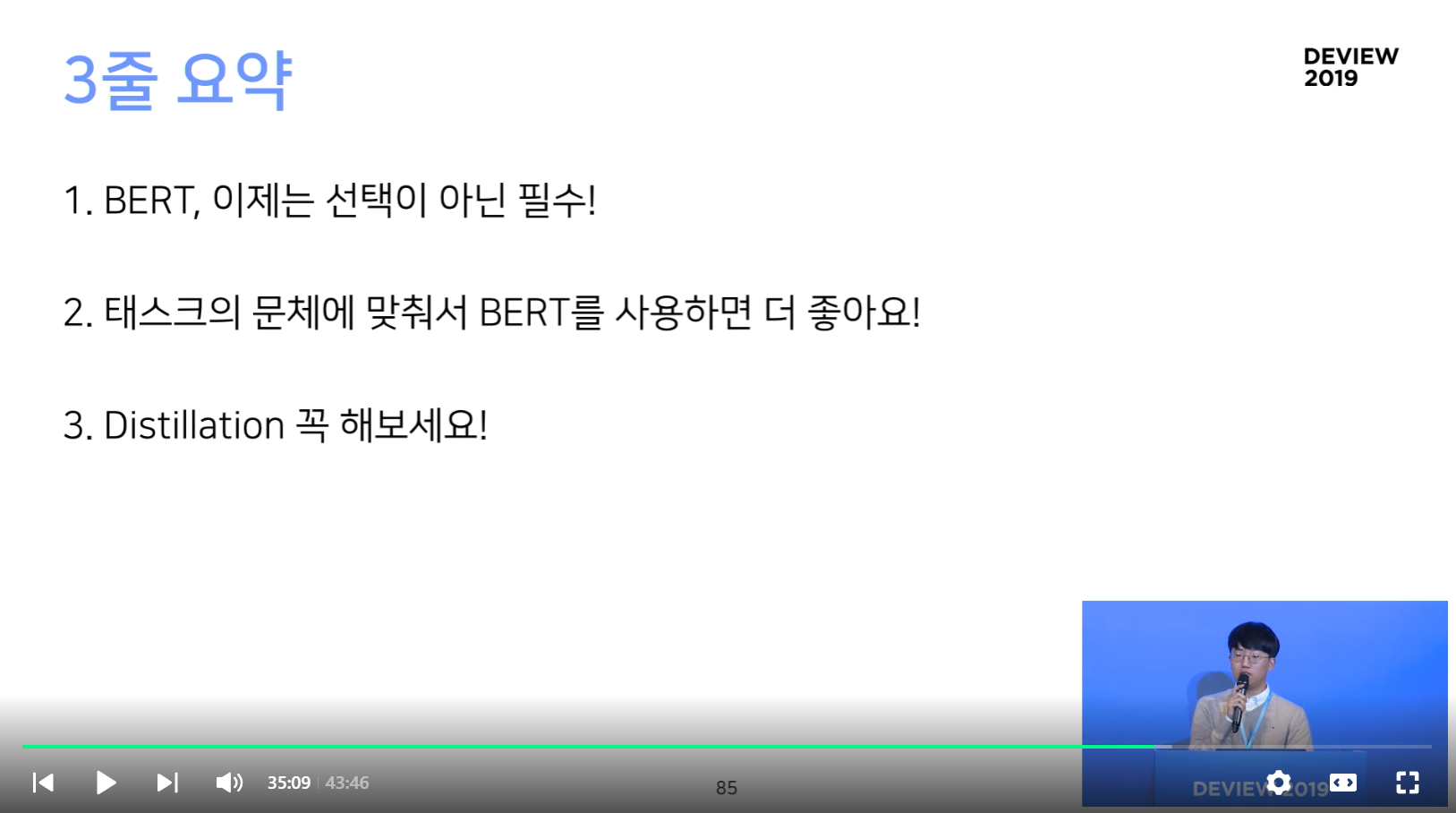
- ETRI, SKT bert를 그대로 사용하지 말고, 태스크 특성에 맞게 학습시키는게 더 좋다!
- 특히 대화 체의 경우 더더욱!
- 경량화
- Quantization, Pruning
Future Work
해당 내용에서 잘못된 부분이나, 의문인 부분에 대해 연락 주시는 것은 언제든 환영입니다!
작성일: 2022.01.16
작성자: 이정관 (leejk526@gmail.com)

Deep Learning Research Engineer@KRAFTON Inc.