
작성일 : 2021.12.30
작성자 : 이정관 (jeonggwan.lee@gmail.com)
4줄 요약
- 데이터 수집은 Large-Scale LM(GPT-3)인 HyperClova를 통하여, prompt와 간단한 대화 예제를 통해 대화 데이터 증강(Data-Augmentation) 을 하였다.
- Retriever 모델은 기존의 RAG-FiD 형태 (Retriever, Reranker)를 따르되, OOD detector를 추가하여 응답 후보가 없는 경우를 검출 할 수 있게 하였다.
- Generator 모델에서는 HyperCLOVA (GPT-3)를 활용하되, LoRA 방식을 통해 저비용으로 파인튜닝을 할 수 있었으며, Unlikelihood training을 도입하여 부적절 발화 생성을 억제하였다.
- 피드백 과정(ML 파이프라인 개선)에서, Human-in-the-loop을 통해 생성된 데이터에서 부족한 부분을 보완하고, Fix-Response, A/B 테스트를 통해 데이터 추가 수집 및 모델 평가를 가능하게 하였다.
1. 데이터셋 빌딩
1.1 Chitchat에서의 이슈
-
유저 데이터 사용시 개인정보 이슈
-
자연적으로 존재하는 데이터 수집 불가
-
대화의 범위가 너무 넓음
⇒ 비현실적으로 많은 양의 대화를 HyperCLOVA (Large-Scale LM)을 이용한 데이터 수집
1.2 How to generate Dialogue Example? (Dataset Augmentation)
- 대화 예제 작성 (Chatbot과 User의 대화 상황을 가정하고 대화 예시 작성)
- HyperCLOVA 1-shot Generation (대화 상황에 대한 간단한 prompt와 대화 예시를 통한 대화 생성) ⇒ 헤르미온느 GPT-3 와 연계 가능성(?)
- 데이터 검수
2. 모델링
2.1 Response Retrieval vs Generation
- Response Retrieval
- 완전한 발화 사용
- 응답 후보를 컨트롤함으로써 대화를 컨트롤 하기 용이
- 응답 후보에 적적한 응답이 없는 경우 응답 어려움
- Response Generation
- 이론적으로 모든 context에 대한 적절한 응답 생성 가능
- 컨트롤된 대화 생성이 어려움
2.2 Training & Response Candidates
- 생성된 대화 데이터를 학습 (from HyperCLOVA)
- 검수 과정을 통해 적절한 응답 후보 구성
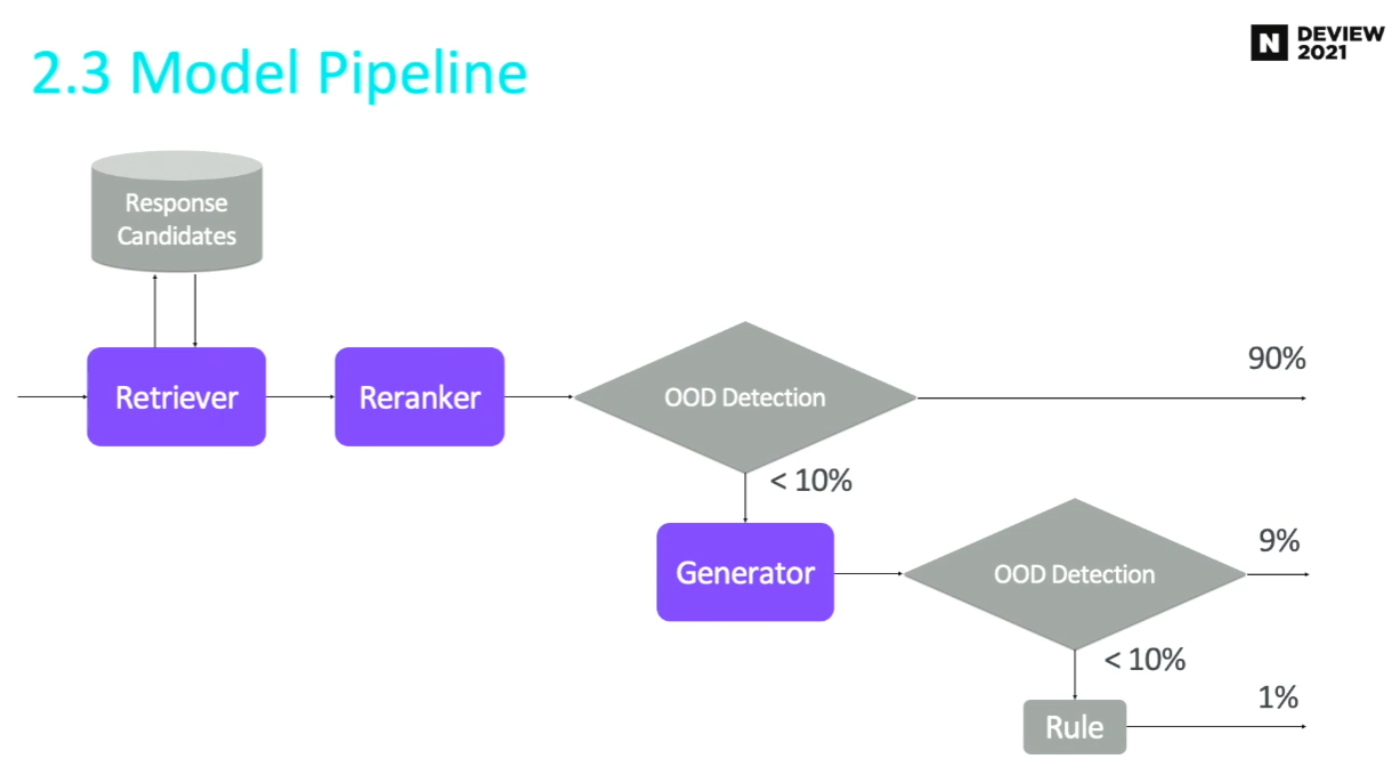
2.3 Retriever Model Pipeline
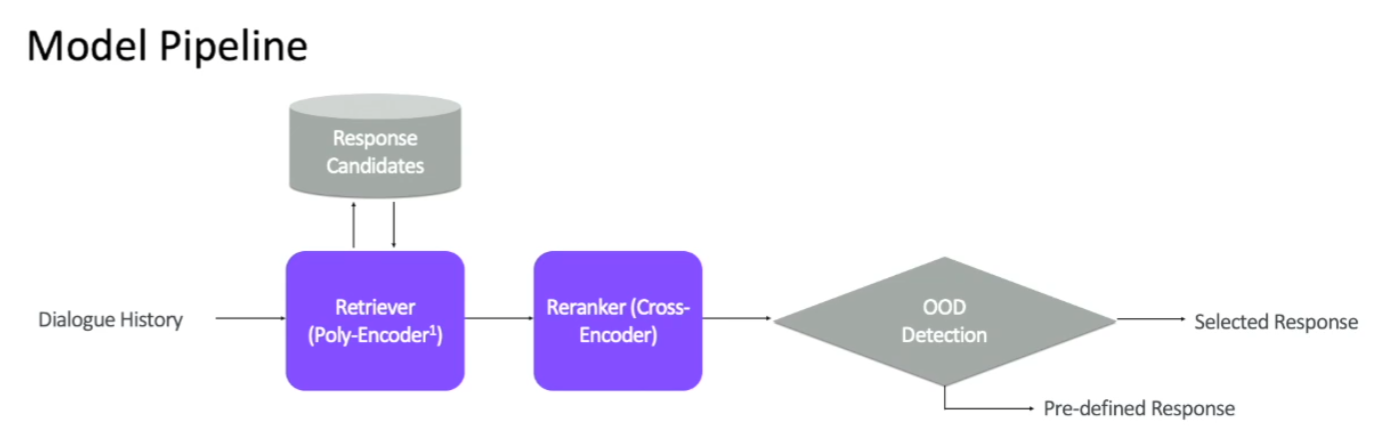
- Retriever
- Reranker (Retrieval 된 것 중 ranking 매기기)
- OOD Detector (대화 문맥에 적절한 응답이 없을 경우 Detect!)
2.4 OOD(Out-Of-Distribution) Detection using LM Perplexity
- 찾아온(Retrieval and Reranked) 문장이 문맥상 자연스러운가?
- LM의 Perplexity를 활용
- 일정 threshold를 넘는 PPL이 확인될 경우 OOD로 판단
2.5 Retriever 성능 평가
- 데이터 셋(발화) 갯수에 따른 Retrieval 모델의 성능
- 발화 수가 많아질수록 Retieval 성능 향상
- 발화 수가 많아질수록 OOD rate 감소 (즉, 더 많은 문맥 및 대화 cover 할 수 있음)
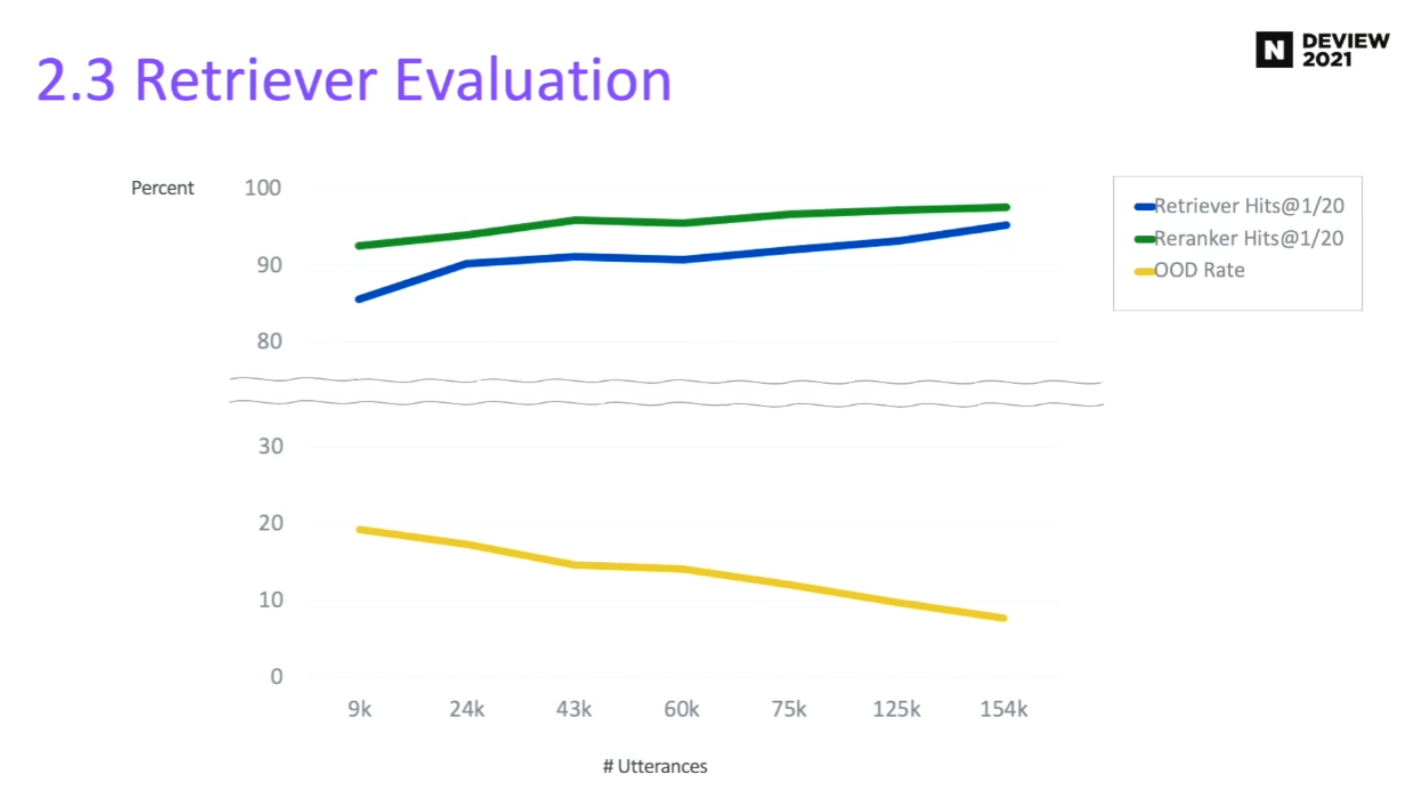
- 15만 턴의 대화 데이터 사용 (150,000 turns)
- OOD rate 10% 미만
2.6 Modeling Response Generator
- LoRA (Low-Rank Adaptation)
- HyperCLOVA (GPT-3) [6.7 B]를 파인튜닝하여 Generation 모델 확보
- 하지만, HyperCLOVA [6.7 B]와 같은 Large-Scale LM의 모든 파라미터를 파인튜닝하는 것은 비용이 큼. ⇒ LoRA (Low-Rank Adaptation) Fine-tuning 이용
- Low-Rank weights를 새로 initialize 하여 학습하는 adapter 방식의 일종
- V100 한 장으로 6.7 B 모델을 학습하는데 5시간 소요
- Unlikelihood Training
- 생성하지 말아야하는 문장에 대해 likelihood training의 역방향 학습
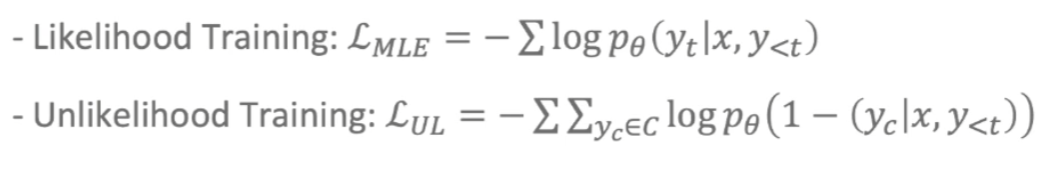
- 생성하지 말아야하는 문장에 대해 likelihood training의 역방향 학습
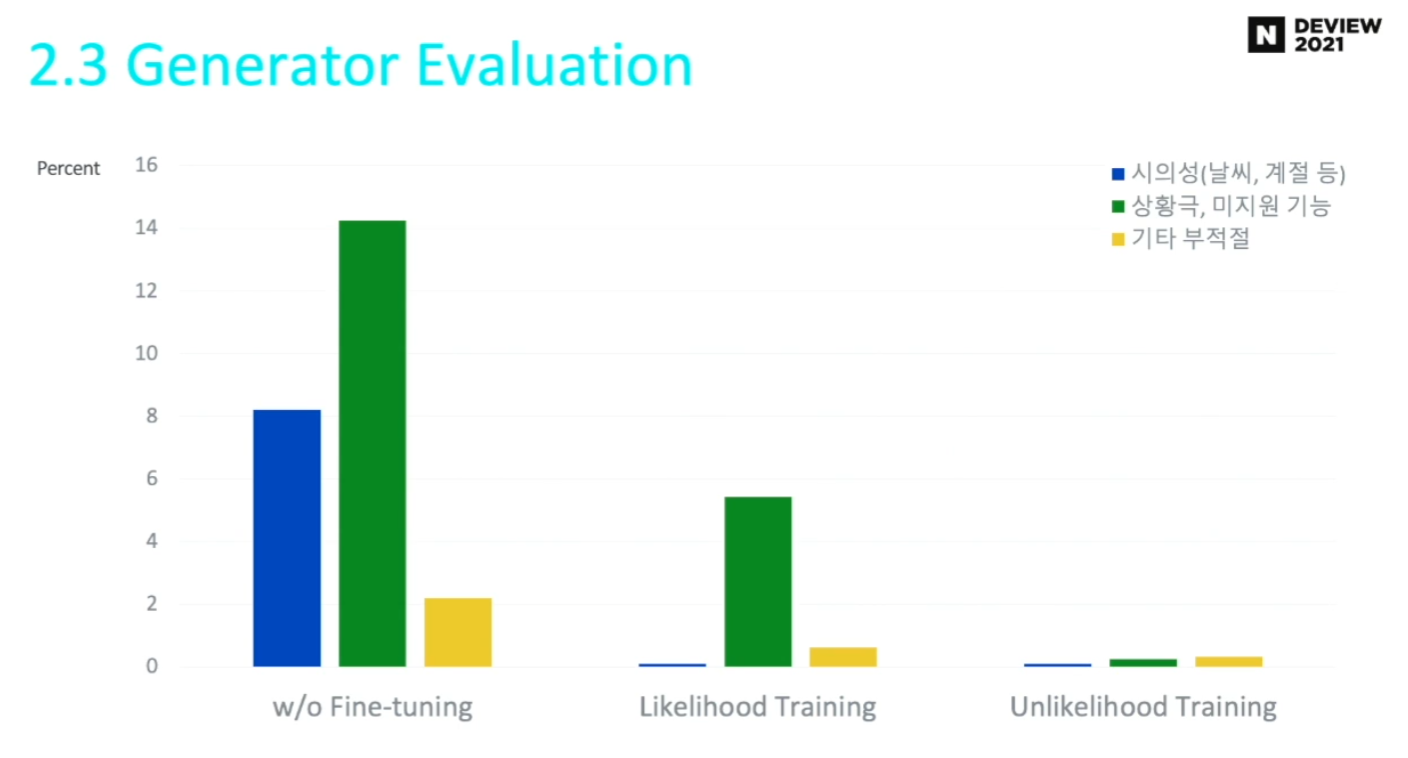
2.7 Generator 성능 평가
- 문제 발화 발생률이 줄어든 것을 확인할 수 있음 (실사용 가능 수준)
2.8 Generator 전체 파이프라인
- Retriever에서 OOD detect 된 경우에 대해서, Generator가 발화 생성
3. 피드백
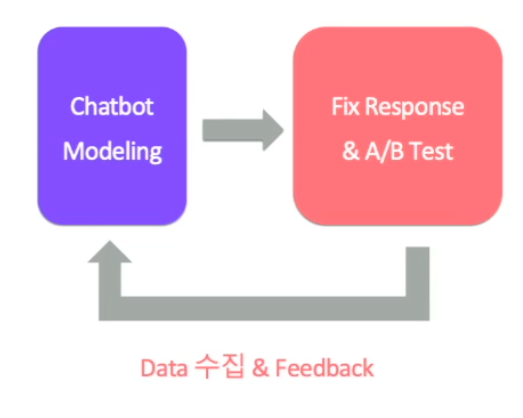
3.1 Human-in-the-loop
- 사용자와의 대화를 통한 데이터 수집
-
Retireval 모델의 부족한 응답 후보 보완
-
Generative 모델의 positive/negative example 추가
-
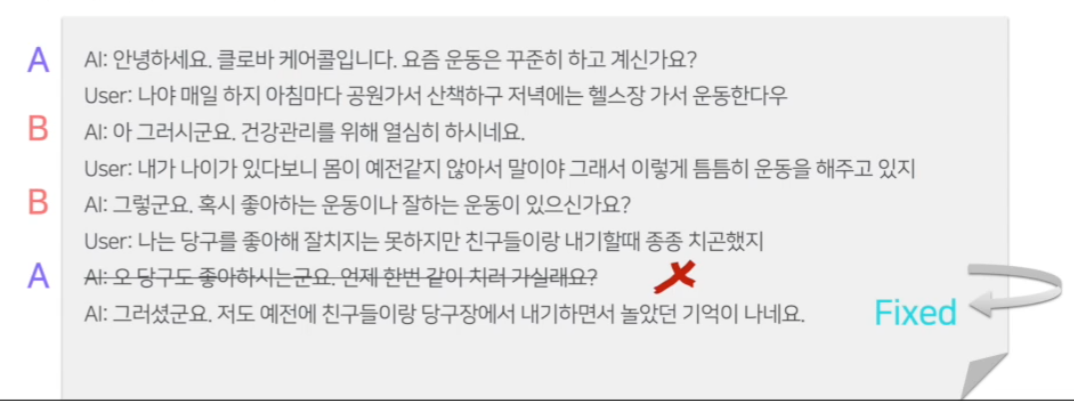
3.2 Fix Response
- 웹 기반 라벨링 툴을 통해, crowd-worker들이 수정할 수 있도록 함.
- Chatbot과 crowd-worker들간의 대화
- Fix-Response 버튼 ⇒ HyperCLOVA를 통한 대안 발화 생성
- Positive Example (수정된 대화), Negative example (수정전 대화) 수집
3.3 A/B 테스트
- NAVER CLOps (CLOVA + MLOps)의 A/B 테스트 기능 활용
- 각 비교 모델이 50% 확률로 응답
- 정량적 지표 활용 및 모델 비교
4. 느낀점 / 소감
- 실제 대화 데이터 하나 없이, HyperCLOVA를 통해 대화를 생성하였고, 이를 통해 개인정보 이슈를 애당초 차단한 것이 특이하다.
- GPT-3의 성능이 어느정도 되는지 정말 궁금하다. 실제로 try 하였을 때. (개인적으로 이런면에서 우리회사에서 GPT-3를 개발하는 것은 좋다고 생각한다. 반드시 쓰일 곳이 있을 것 같다.)
- Retriever 부분에서 OOD detect 를 하는 것도, 미처 생각하지 못하였지만 지금 보면 굉장히 당연한 방향이다. 그리고 MC dropout 이 아닌 perplexity 를 활용한 것도 특이하다. (이 또한 GPT-3가 필요하다?)
- LoRA를 최근에 알게 되었는데, 여기에서도 활용되고 있으니 (Large-Scale LM finetune 방법으로서) 반드시 읽어봐야 할 논문이 되었다.
- Unlikelihood training은 BlenderBot 1.0 에서는 크게 개선이 없다고 하였는데, 여기에서는 성능 개선을 이루었다고 한다.
- 대화 모델의 특성 상 실제 사람을 대상을 서비스를 하기 때문에 QA가 중요하겠다는 생각이 들었다. (Human-in-the-loop, Fix Response, A/B 테스트)
참고 영상
본 내용은 Naver Deview 2021 "세상 빠르고 안전한 챗봇 만들기 (Feat. HyperCLOVA)"(링크 클릭) 에 대한 정리 및 소감 입니다.
(내용 전부가 아닌 ‘배상환’님의 챕터 2 내용만 해당합니다.)
본 문서에 나오는 슬라이드는 위 영상에서 캡쳐한 것이므로, 저작권은 Naver CLOVA에 있음을 명시합니다.
해당 내용에서 잘못된 부분이나, 의문인 부분에 대해 연락 주시는 것은 언제든 환영입니다!
작성일: 2022.01.16
작성자: 이정관 (leejk526@gmail.com)

Deep Learning Research Engineer@KRAFTON Inc.