What is Algorithm?
- '문제(Problem)'를 해결하는 단계별 절차를 체계적으로 기술한 것
- 하나의 문제에 대해 다양한 솔루션이 존재
- 솔루션에 따라 성능의 차이가 존재 (시간 성능, 공간 성능)
⠀⠀
- 문제의 요구 조건
- 입력(Input)과 출력(Output)으로 명시할 수 있다.
-> 알고리즘은 입력으로부터 출력을 만드는 과정
-> 알고리즘을 프로그래밍 언어로 표현한 것이 프로그램
예시
- 문제: 영어 사전에서 'Home'이라는 단어 찾기
- 입력: 영어 단어가 순서대로 나열되어 있는 영어 사전
- 출력: 'Home'이라는 단어의 뜻
- 알고리즘: 순차 검색, 이진 검색
알고리즘 학습의 목적
- 특정한 문제를 해결하기 위한 알고리즘 습득
- 체계적으로 생각하는 방법 훈련
- 알고리즘의 분석 및 시간,공간 복잡도와 같은 평가 방법 훈련
검색 알고리즘
- 순차 검색 (Sequential Search)
- 발견할 때 까지 리스트의 처음부터 순차적으로 비교
- 개의 리스트에 대해 최악의 경우 번 비교
- 이분 검색 (Binary Search)
- 정렬되어 있는 리스트에서 가운데 값과 찾고자 하는 값을 비교
- 비교 결과에 따라 검색 대상을 1/2씩 줄여가며 검색
- 개의 리스트에 대해 최악의 경우 번 비교
⠀⠀
| ⠀⠀배열의 크기⠀⠀ | 순차 검색 비교 횟수 | 이분 검색 비교 횟수 |
|---|---|---|
| 128 | 128 | 7 |
| 1,024 | 1,024 | 11 |
| 1,048,576 | 1,048,576 | 21 |
⠀⠀ ⠀⠀ <효율적인 알고리즘 사용의 중요성>
피보나치 알고리즘 비교
재귀 함수로 구현
long fibo_recursive(long n) {
if (n == 0)
return 0;
else if (n == 1)
return 1;
else
return fibo_recursive(n - 1) + fibo_recursive(n - 2);
}시간 복잡도:
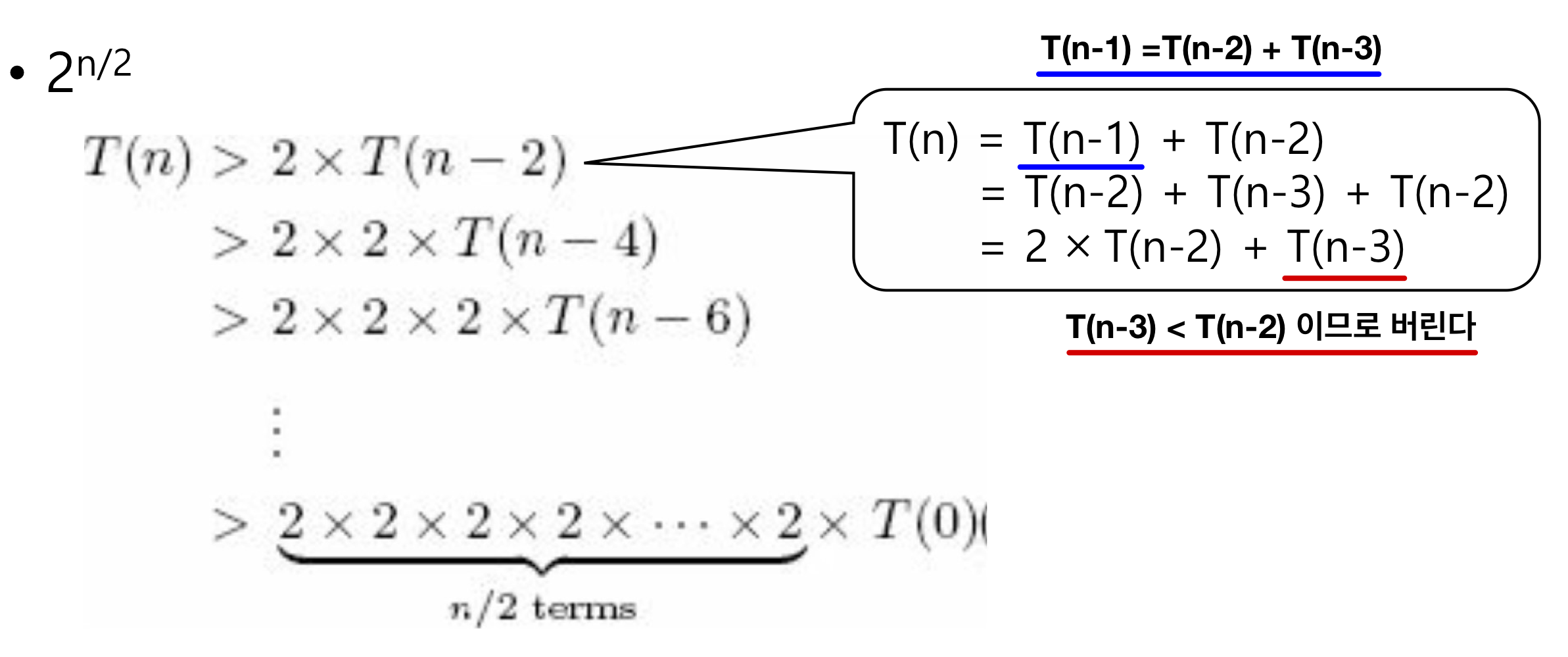
⠀⠀
반복 함수로 구현
long fibo_iterative(long n){
long* fibo = new long[n + 1];
fibo[0] = 0;
fibo[1] = 1;
for (long i = 2; i <= n; i++)
fibo[i] = fibo[i - 1] + fibo[i - 2];
return fibo[n];
}시간 복잡도:
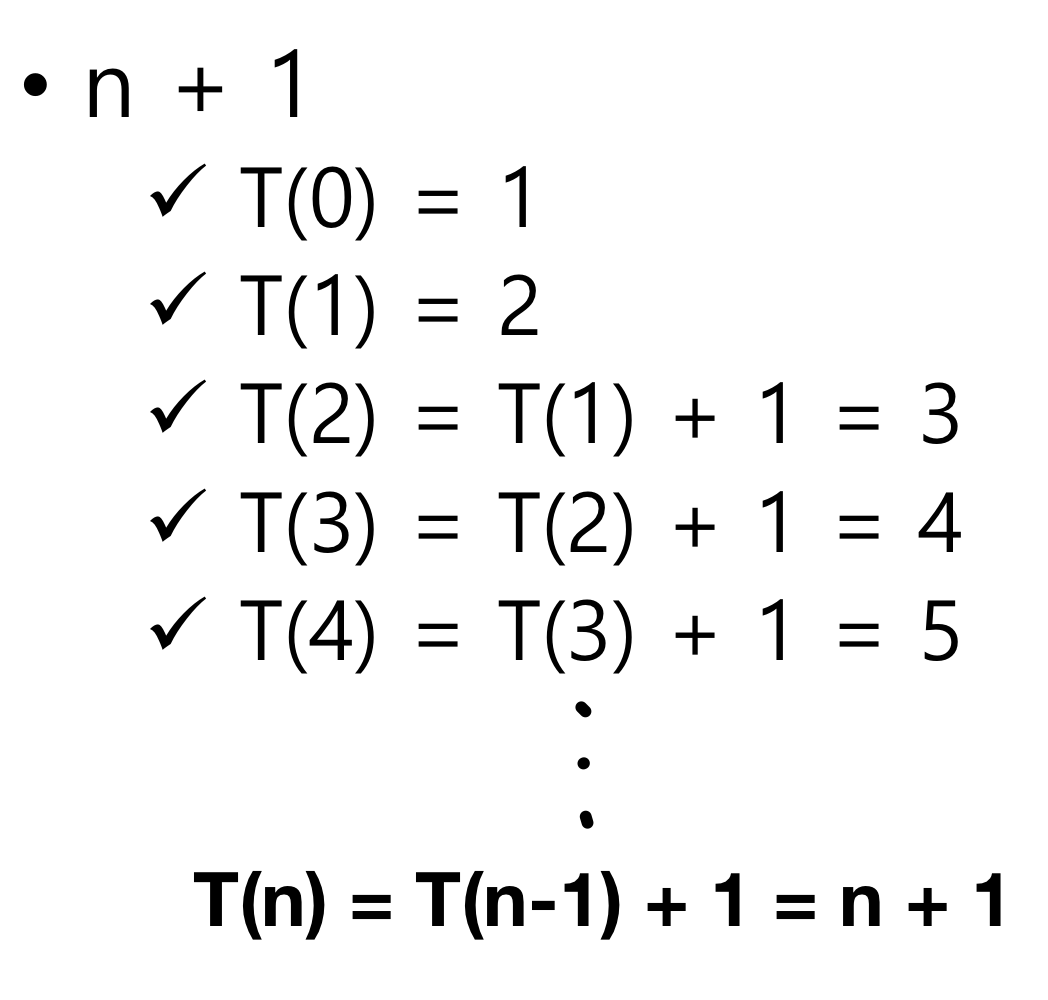
Complexity Analysis
알고리즘 분석
- 목적: 자원 사용의 효율성 파악
- 시간: 알고리즘 실행을 위해 사용되는 시간. CPU Cycle과 Instruction 개수는 고려하지 않음.
- 공간: 알고리즘 실행을 위해 추가로 사용하는 공간
⠀⠀ - 알고리즘의 효율성은 입력에 대해 특정 기본 연산의 수행 횟수를 계산하여 분석
⠀ - 알고리즘의 실행 시간에 영향을 주는 요소
- 입력의 크기
- 입력값
⠀ - 입력의 크기가 큰 경우 알고리즘의 효율성이 매우 중요. 이때의 분석을 '점근적 분석(Asymptotic)'이라고 표현.
알고리즘 분석 절차
1. 입력의 크기 결정
- 입력의 개수
- 을 표현하기 위해 필요한 비트 수
ex) 13 = 1101₂ => 필요 비트 수 : 4
2. 기본 작업 선정
- 알고리즘 동작 시 전체 동작과 비례하여 수행되는 명령어 또는 명령어 집합
ex) 정렬 알고리즘에서는 두 수를 비교하는 것이 기본 작업
3. 시간 복잡도 분석
- 입력값에 대해 기본 작업이 몇 번 수행되는지 분석
여러가지 시간 복잡도
Every-Case Time Complexity ( )
- 입력 크기 이 주어졌을 때, 알고리즘이 연산을 수행하는 횟수
- 실행 시간은 의 크기에 비례하며 값과 무관
Worst-Case Time Complexity ()
- 입력 크기 이 주어졌을 때, 알고리즘이 연산을 수행하는 최대 횟수
- 입력값에 영향을 받음
- 배열에 존재하지 않는 값을 찾으려고 할 때 :
- 배열의 제일 마지막에 있는 값을 찾으려고 할 때 :
Average-Case Time Complexity ()
- 입력 크기 이 주어졌을 때, 알고리즘이 연산을 수행하는 평균 횟수
- 표준편차가 큰 경우는 평균값이 의미 없을 수 있음
- (Worst-Case)의 영향이 매우 클 경우 은 의미 없음
Best-Case Time Complexity ()
- 입력 크기 이 주어졌을 때, 알고리즘이 연산을 수행하는 최소 횟수
- 입력값이 특정 조건을 만족하면 매우 빠르게 동작
- 대부분의 알고리즘 분석에서 은 고려 대상이 아님
Order
Order라고 표현되어 있어 약간 낯설었는데, 쉽게 말해 차수라는 의미이다. 차수는 알고리즘의 실행 시간을 결정하는 가장 중요한 요소이다.
- Linear-Time Algorithm : 등
- Quadratic-Time Algorithm
- Pure Quadratic (Linear Term이 없을 때) : 등
- Complete Quadratic (Linear Term이 있을 때) : 등
- Polynomial Algorithm :
- Exponential Algorithm :
점근적 표기법
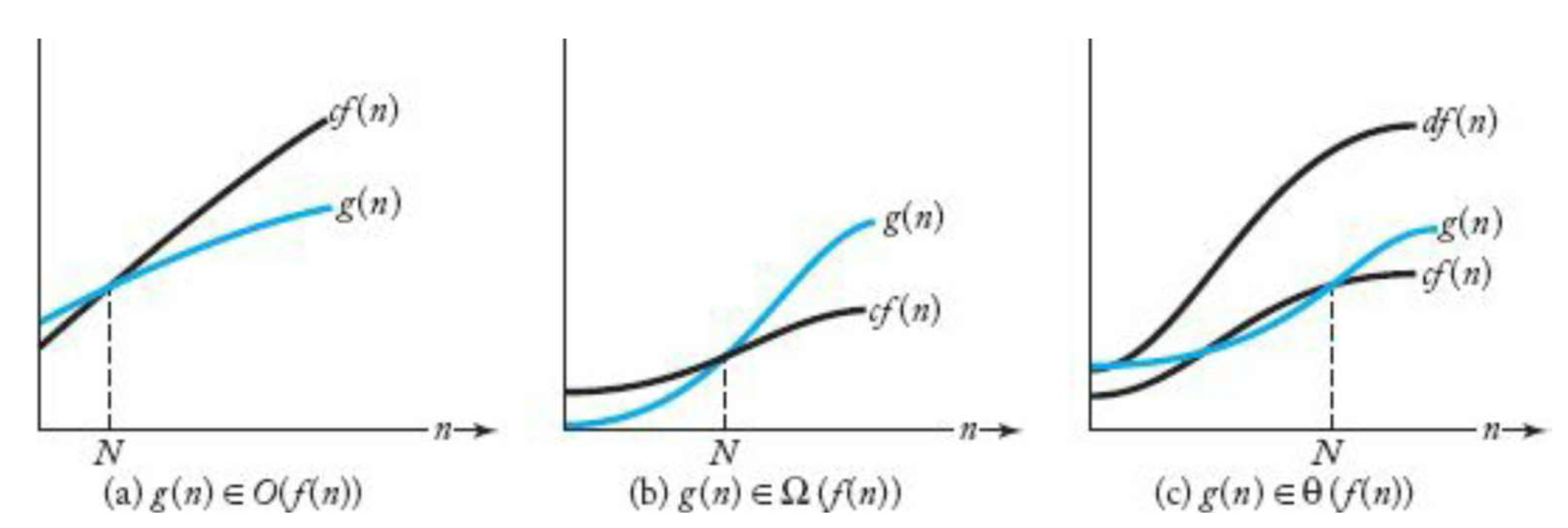
- 기껏해야 의 비율로 증가하는 함수
- 등
- : 최악의 경우 이다.
⠀⠀
- 적어도 의 비율로 증가하는 함수
- 등
- : 최선의 경우 이다.
⠀⠀
- 의 비율로 증가하는 함수
- : 등
- : 항상 을 유지한다.
⠀⠀
⠀⠀
아무래도 첫 시간이라서 그런지 이전에 자료 구조 수업에서 배운 내용을 복습하는 느낌?
⠀⠀
