What is OS?
사용자 애플리케이션과 컴퓨터 하드웨어 사이에 존재하는 소프트웨어 계층이다. 책에서는 프로그램을 쉽게 실행하고, 프로그램 간의 메모리 공유를 가능케 하고, 장치와 상호작용을 가능케 하고, 다양한 흥미로운 일을 할 수 있게 하는 소프트웨어라고 정의되어 있다.
운영체제는 앞에서 언급한 일을 하기 위하여 가상화(virtualization)라고 불리는 기법을 사용한다. 운영체제는 프로세서, 메모리, 또는 디스크와 같은 물리적인 자원을 이용하여 일반적이고, 강력하고, 사용이 편리한 가상 형태의 자원을 생성한다. 이 때문에 운영체제를 때로는 가상 머신(virtual machine)이라고 부른다.
Classification of OS
Accessibility
액세스 가능 인원이 한 명인 운영체제는 Single User System이다. 말 그대로 동시에 한 명의 유저만 컴퓨터 시스템에 접근 가능한 체제이다. 단순하지만 제한적인 수행 능력을 가진다. 예로는 MS-DOS, Windows, Mac OS 등이 있다. 반대로 두 명 이상 액세스 가능한 운영체제는 Multi User System이다. 복잡하지만 여러 작업을 수행할 수 있고 유저들 간에 권한과 보안을 관리해야 할 필요가 있다. 예로는 Unix, Windows NT, Linux 등이 있다.
Concurrency
동시에 수행 가능한 작업의 수로 분류되는 운영체제는 Single Tasking System과 Multi Tasking System이 있다. 이것도 말 그대로 동시에 하나의 프로그램만 실행 가능한 체제와 두 개 이상의 프로그램을 동시에 실행 가능한 체제를 뜻한다. 전자의 예로는 MS-DOS, Windows cmd가 있고, 후자는 Linux, Windows, Mac OS를 비롯한 대부분의 현대 운영체제가 있다.
Openness
모두에게 소프트웨어가 공개된 것은 Open Source System 그렇지 않은 것은 Closed Source System이라고 한다. Open Source System는 무료로 배포되는 소프트웨어이다. 그렇기 때문에 제한 없이 누구나 소스 코드를 수정 가능하고, 이를 통해 더 나은 성능을 나타낼 수도 있다. 반면 Closed Source System는 사용자가 구입해야 하고 소스 코드를 확인하거나 임의로 수정할 수 없지만, 더 안전하고 믿을 수 있다는 장점이 있다. Linux가 대표적인 오픈 소스 체제, Windows가 대표적인 Closed Source System이다.
Types of Kernels
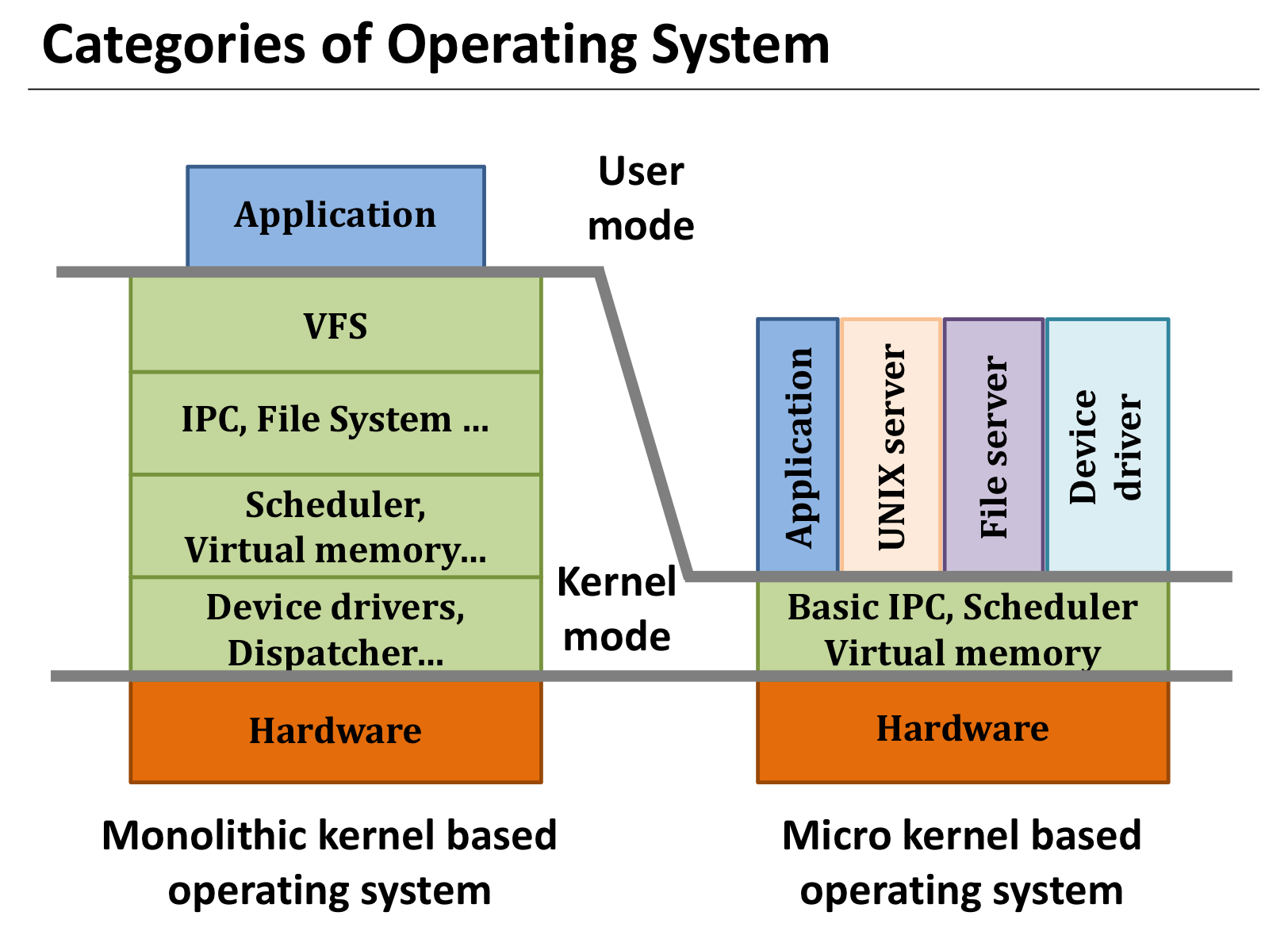
커널의 종류로 구분되는 운영체제는 위의 그림과 같이 Monolithic Kernel, Micro Kernel 그리고 Hybrid Kernel이 있다. 그림과 같이 Monolothic Kernel은 사용자가 따로 추가하지 않아도 운영체제에 대부분의 시스템이 구축되어 있고, Micro Kernel은 기본적인 모듈을 제외하고는 사용자가 직접 추가해야 하는 시스템이다. Monolothic Kernel은 각 모듈간의 커뮤니케이션이 효율적이지만 커널 하나가 죽으면 전체 시스템이 죽는다. 반면 Micro Kernel은 서버를 추가하는 방식이기 때문에 기능을 추가하기 쉽고, 시스템이 견고하며 리얼타임성이 높다. 하지만 모듈 사이의 커뮤니케이션이 불가해 성능이 비교적 낮다.
History of OS
Serial Processing (~ 1950s)
이 시기에는 컴퓨터가 비싸고 인건비는 비교적 저렴했기 때문에 컴퓨터를 최대한 효율적으로 사용해야 했다. 운영체제가 없었기 때문에 프로그램은 기계어로 이루어져 있었고, 컴퓨터를 사용하는데 필요한 모든 요소를 프로그램 내에 포함해야 했다. 멀티 태스킹은 당연히 불가했고, 천공 카드를 통한 코딩이 진행되었기 때문에 디버깅은 사람이 카드를 보며 직접 진행되었다. 아래 사진이 천공 카드를 운용하는 모습이다.

Single Batch Processing (~ 1960s)
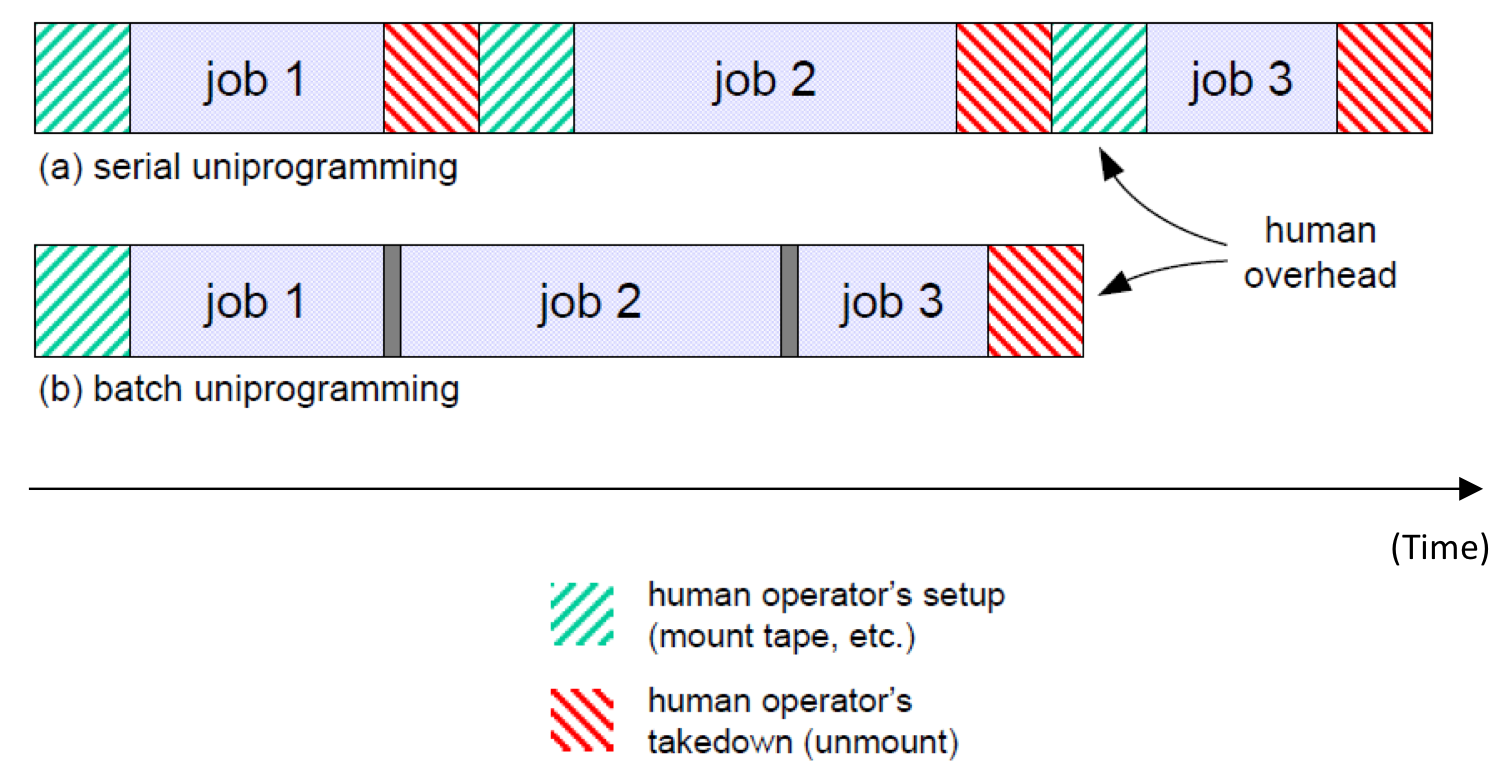
시기 설명에 앞서 위 그림을 보자. 민트색 빗금은 천공 카드를 넣는 작업, 빨간색 빗금은 빼는 작업이라고 생각하면 된다. Job은 이후에 배우게 되면 Task가 될 수도, Thread가 될 수도, Program이 될 수도 있다. 우선 여기서는 컴퓨터가 수행하는 작업이다. 그림으로 봐도 (a)는 컴퓨터가 작업하지 않는 시간이 (b)에 비해 훨씬 길다. 예를 들어 Job1이 덧셈 계산, Job2는 곱셈 계산, Job3는 덧셈 계산을 하는 작업일 때, Job1과 Job3를 한 번에 처리하고 Job2를 마지막에 처리한다면 천공카드를 넣고 빼는 작업을 줄일 수 있을 것이다. 이때 묶어준 Job1과 Job3를 우리는 Batch라고 부른다. 왼쪽 아래 그림을 보면 이해가 쉬울 것이다. 물론 여기서 Operating System은 이 시기에 없었기 때문에 이 작업을 사람이 대신했다고 생각하면 된다. 그렇다면 이 Batch들은 어떤 순서로 실행하는 게 좋을까?
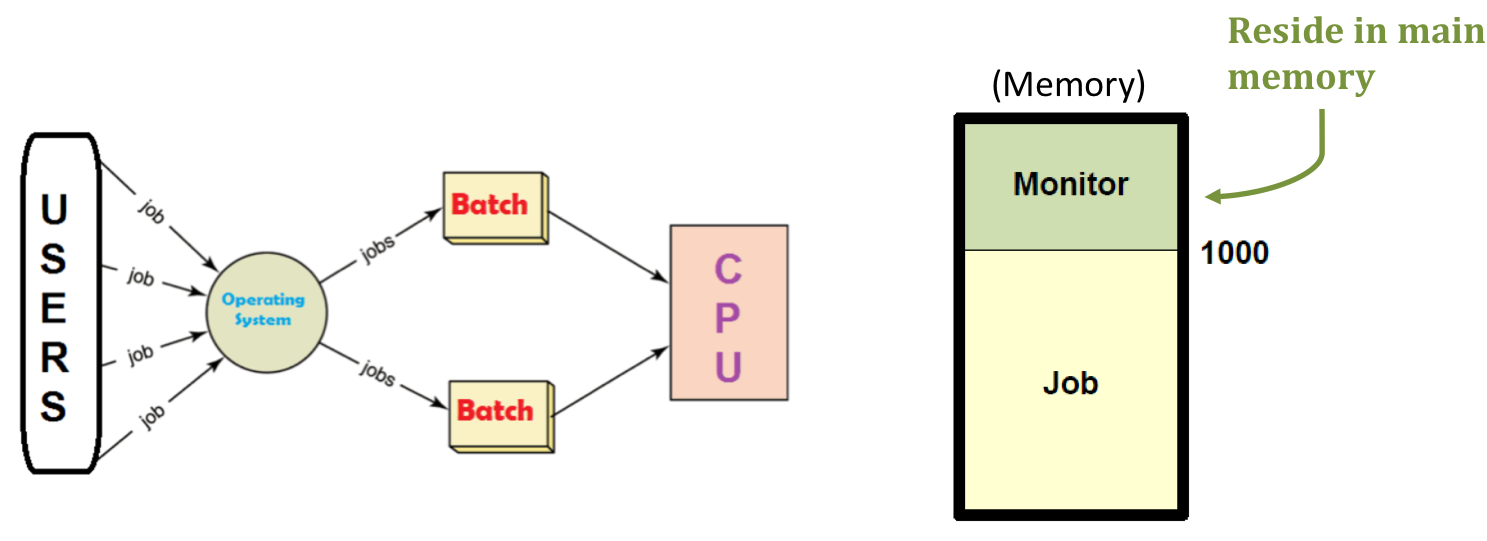
그것을 결정하기 위해 위 그림의 우측과 같이 메모리 내부에 Monitor를 상주시키게 되었다. 이것이 운영체제의 전신이다. 결론적으로 이 시기에는 모든 유형의 프로그램과 데이터를 일괄 처리 방식으로 수집한 후 한꺼번에 처리할 수 있게 되었다. 그로 인해 설정 및 종료 시간이 단축되었고, CPU 활용도 역시 향상되었다. Monitor가 메모리 보호, 타이머, 관리 명령어 그리고 Interrupt 역할이 추가된 단순한 Scheduler가 되었다. 하지만 여전히 운영체제가 없고, 단일 작업 체계였기 때문에 활용도가 높지 않았다. 이번에는 수행 시간을 통해 CPU 활용도를 계산해보자.
Read one record from file : 15μs
Execute 100 instructions in processor : 1μs
Write one record to file : 15μs
위와 같은 결과가 나왔다. 그렇다면 이때 CPU 활용도는 어떻게 될까? 답은 간단하다. 작업이 처리되는 전체 시간 중에 CPU가 작업하는 시간을 구하면 된다. 여기서는 1/31 ≒ 0.032 = 3.2%의 CPU 활용도가 나타난다. 분명히 Batch로 묶어 시간을 단축시켰는데도 낮은 활용도가 나온다. 그럼 어떻게 하면 활용도를 높일 수 있을까?
Multi-Programming Batch processing (1960s ~ 1970s)
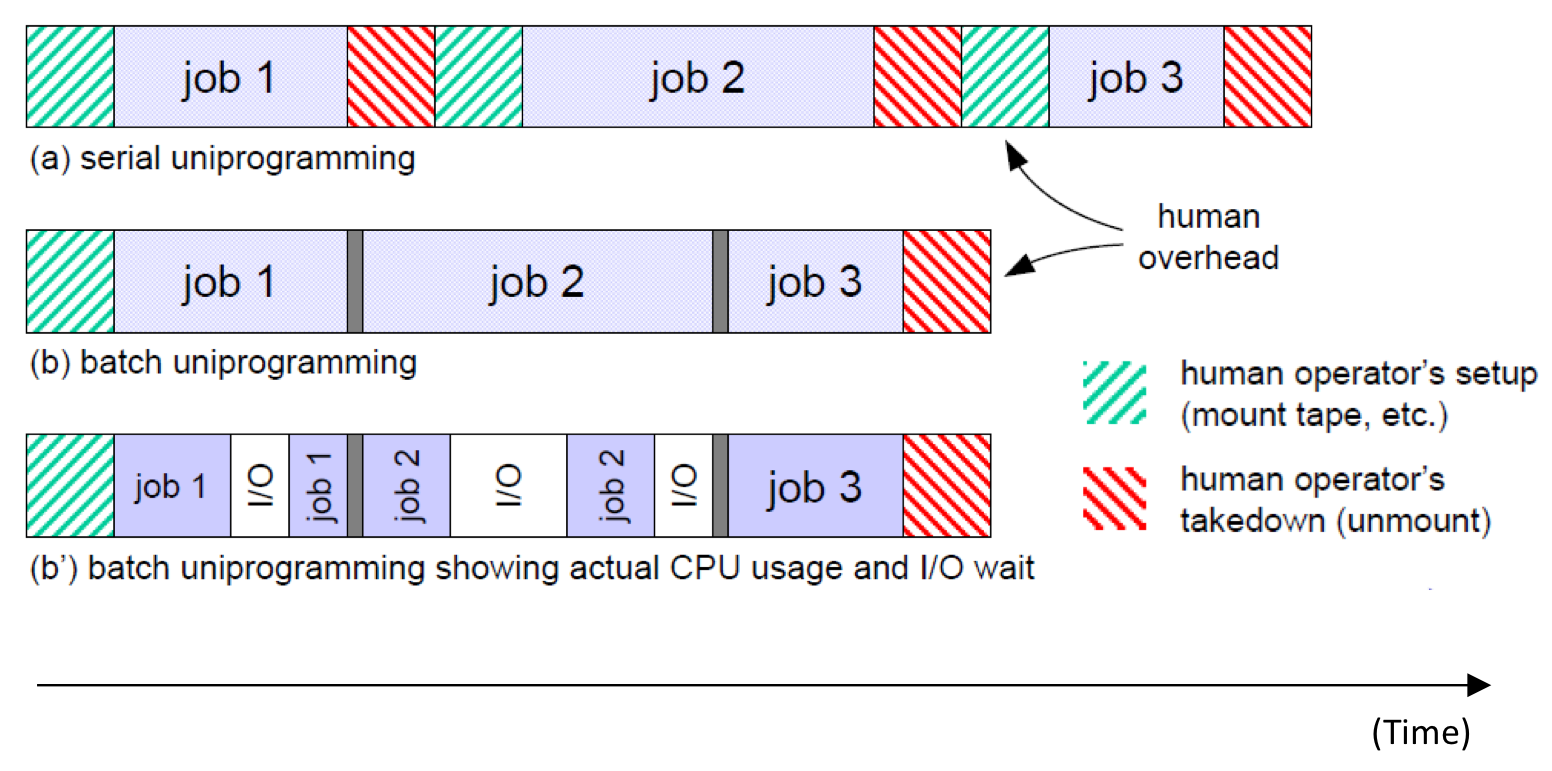
위 그림의 (b)와 (b')를 비교해보면 일부 Job 안에는 Input, Output이 존재한다는 것을 알 수 있다. 그렇다. 이 Input, Output이 진행되는 동안 CPU는 작업을 하지 않아 활용도가 낮게 나온 것이다. 컴퓨터 구조에서 Pipeline 개념을 배웠다면 어떻게 해야할지 감이 올지도 모른다. 다음 그림을 참고하자.
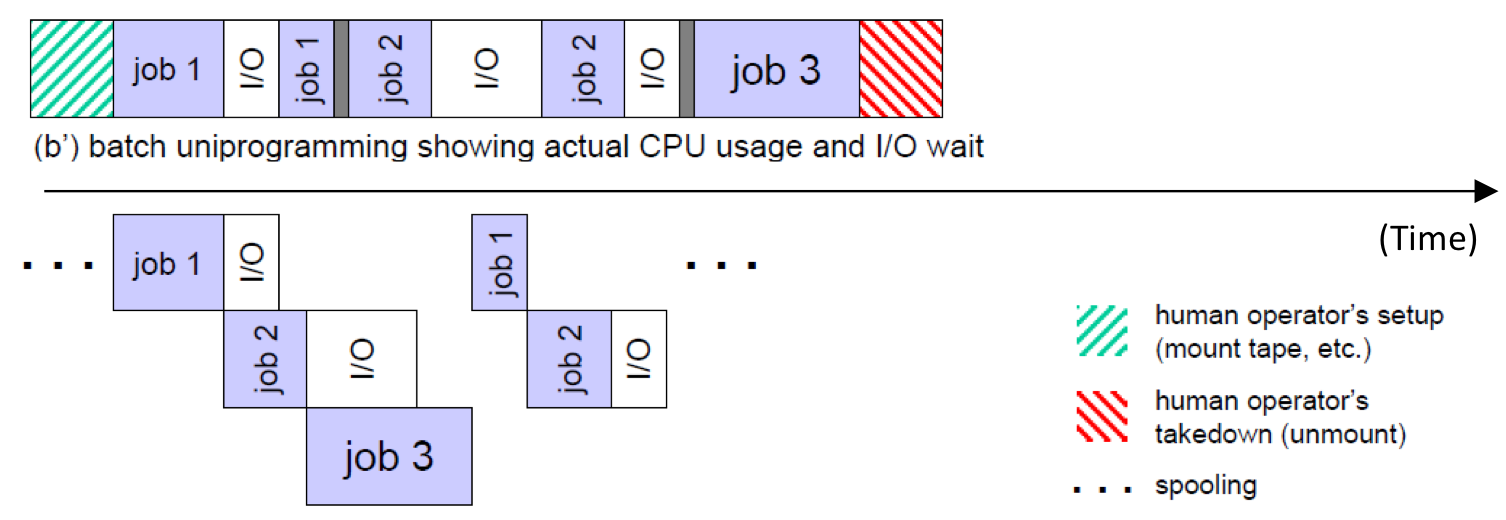
위와 같이 I/O가 진행되는 동안 CPU가 쉬지 않고, 다른 프로그램을 실행하게 만들 수 있다. 이렇게 하면 CPU 활용도를 높일 수 있다. 이것이 바로 Multi Programming이다.
이 시기에 드디어 운영체제가 등장한다. 이로 인해 여러 사용자의 시스템 공유가 가능해졌고, 위에서 설명했듯 Multi Programming 역시 가능해졌다. 이렇게 단일 프로세서에서 여러 배치 프로그램이 동시에 실행되기 위해 동시 프로그래밍이 필요해진 것이다. 이전까지 메모리 안에서 Monitor라는 이름으로 존재했던 것이 버퍼링과 인터럽트 처리의 역할까지 수행하면서 운영체제라는 이름으로 바뀌었다. 이 시기의 메모리를 형상화하면 다음 그림과 같다.
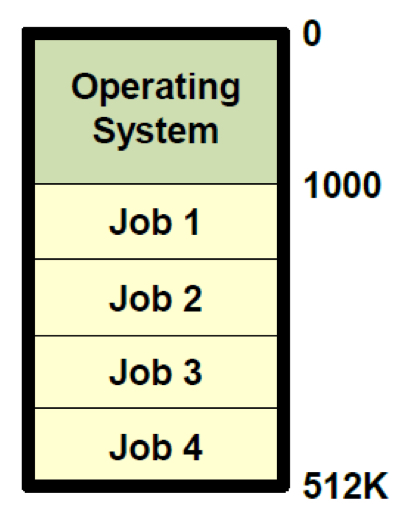
이제 다른 문제를 고려해보자. 만약 위 그림과 같이 네 가지 작업이 진행되고 있는 메모리 상황에서 Job5를 수행해야 하는 상황이 되었다고 고려하자. 어떤 Job을 빼고 어떻게 Job5를 넣어야 하는 것일까?
네 가지 Job 모두 약 128K 사이즈이고 Job5는 200K 사이즈이다. Job5를 넣기 위해 Job1을 뺀다고 하더라도 바로 아래에 있는 Job2와 겹치는 부분이 생기면서 데이터 손실이 발생한다. 여기서 동시 프로그래밍이 중요하다. 바로 비동기(Asynchronous) I/O와 새로 들어오는 Job 5 계산을 겹치게 만드는 것이다. 이게 가능하기 위해서는 메모리 안의 작업들이 겹치지 않고 각자의 자리가 관리되어야 한다. 이게 바로 이 시기에 등장한 Multi Programming의 메모리 보호, 재배치 역할이다.
Time-Sharing processing (1970s ~ 1980s)
이 시기에는 컴퓨터의 가격이 인간의 노동력보다 저렴해졌다. 따라서 사람의 시간을 효율적으로 사용하는 것이 중요해졌다. 즉, 이 시기부터 CPU Utilization보다 User Experience(성능)가 더 중요해진 것이다. 그리고 Multi Programming System의 논리적 확장으로 대화형 컴퓨팅(Interactive Computing)이 개발 되었다. 이것은 CPU가 작업을 매우 짧은 단위 시간마다 전환하여 작업이 실행되는 동안 여러 사용자가 각 작업과 상호 작용할 수 있게 만든 것이다. 이 기술을 Time Sharing Processing이라고 부른다.
User Experience(성능)를 좌우하는 지표는 크게 Throughput, Response Time, TAT(Turnaround Time) 이렇게 세 가지가 있다. 교수님께서는 이것들을 중국집으로 설명해주셨는데, 나도 따라해봐야지.
우선 TAT이다. 중국집에 가서 군만두, 짜장면, 짬뽕, 탕수육을 시켰다. 주문을 받은 주방장은 열심히 요리를 한 후, 주문 받은 순서대로 음식을 갖다주었다. 군만두부터 시작해서 탕수육이 오는 순간 모든 주문이 완료된다. 여기서, 군만두가 테이블 위에 서빙되는 시점부터 탕수육이 서빙되는 시점 사이의 시간이 프로세스가 처음 도착해서 끝나기까지 걸린 시간을 의미하는 Turnaround Time이다.
Response Time은 무엇일까. 이번에는 중국집에 손님이 많다. 주문을 했는데도 오랜 시간 음식이 나오지 않아 잘못된 것은 아닌가 궁금해졌다. 그러던 와중에 처음 주문한 군만두가 나왔고 이를 통해 주문이 제대로 들어갔다는 것을 알 수 있었다. 이것이 내가 명령을 했을 때, 첫 번째 응답이 오기까지 걸리는 시간을 뜻하는 Response Time이다.
이번에는 바꿔서 중국집 사장님 입장에서 Throughput을 설명해보겠다. 사실 사장님 입장에서 가장 중요한 것은 매출, 즉 주문량이다. 사장님 입장에서는 회전율을 높여 같은 시간에 최대한 많이 파는 것이 중요하다. 이것을 수치화 하면 단위 시간당 테이블 수로 생각할 수 있다. 이것이 단위 시간당 처리하는 작업의 수를 나타내는 Throughput이다.
OS With Internet (~ 1990s)
이 시기에는 OS가 사용자에게 연결된 멀티미디어 서비스를 제공한다. 인터넷 접근과 멀티미디어 지원이 내포되어 있다는 것이 가장 큰 특징이다. PC와 OS에 인터넷 프로토콜이 추가되었다. 그리고 다양한 기능 모듈이 포함되어 컴퓨팅 시스템과 OS 자체가 훨씬 복잡하게 바뀌기도 했다.
New Era (~ 2010s)
우리에게 가장 익숙한 현 시점의 OS를 의미한다. 상품화된 OS라고도 부른다. 데스크탑, 핸드폰, 클라우드 시스템에 사용되는 대부분의 OS이다. 뿐만 아니라 OS 자체가 안드로이드, IOS, webOS 등에 사용되는 하나의 소프트웨어 플랫폼으로 사용되기도 한다.
