학습 목표
- 레이어의 개념을 이해한다.
- 딥러닝 모델 속 각 레이어(Embedding, RNN, LSTM)의 동작 방식을 이해한다.
- 데이터의 특성을 고려한 레이어를 설계하고, 이를 Tensorflow로 정의하는 법을 배운다.
후기
학습 내용
24. 딥러닝 레이어의 이해(2) Embedding, Recurrent
Embedding 레이어와 RNN 레이어에 대해 알아보는 노드!
24.1. 분포 가설과 분산 표현
- 희소 표현(Sparse Representation)
- 벡터의 특정 차원에 단어 혹은 의미를 직접 매핑하는 방식
- 단어의 분산 표현(Distributed Representation)
분포 가설(distribution hypothesis)
-> 유사한 맥락에서 나타나는 단어는 그 의미도 비슷하다.
분산 표현(Distributed Representation)
유사한 맥락에 나타난 단어들끼리는 두 단어 벡터 사이의 거리를 가깝게 하고,
그렇지 않은 단어들끼리는 멀어지도록 조금씩 조정해 주어 얻어지는 단어 벡터장점: 희소 표현과는 다르게 단어 간의 유사도를 계산으로 구할 수 있다
24.2. 단어를 부탁해! Embedding 레이어
# Embedding 레이어
-> 단어의 분산 표현을 구현하기 위한 레이어
-> 간단히 말하면, 컴퓨터용 단어 사전
- 단어의 개수, Embedding 사이즈로 정의됨
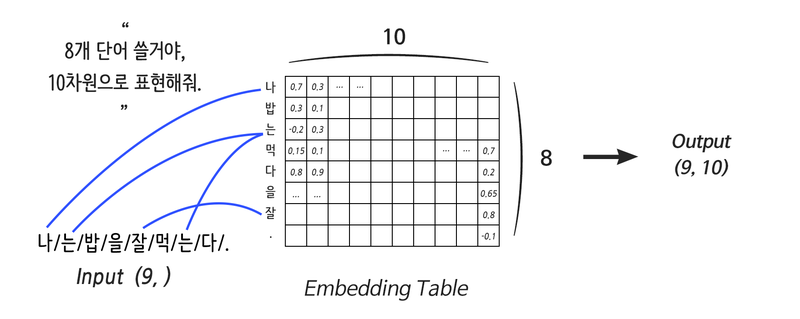
- 어떤 연산 결과를 Embedding 레이어에 연결시키는 것은 불가능
- 입력에 직접 연결되게 사용
# 원-핫 인코딩(One-hot Encoding)
N개의 단어를 각각 N차원의 벡터로 표현하는 방식
24.3. 순차적인 데이터! Recurrent 레이어 (1) RNN
문장이나 영상, 음성은 순차적인(Sequential) 특성을 가짐
-> 딥러닝에서 말하는 시퀀스 데이터는 순차적인 특성을 필수로 갖는다!
# Recurrent Neural Network(RNN)
-
RNN의 입력으로 들어가는 모든 단어만큼 Weight를 만드는 게 아님
-
(입력의 차원, 출력의 차원)에 해당하는 단 하나의 Weight를 순차적으로 업데이트하는 것
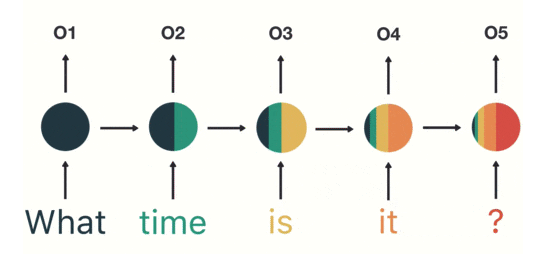
첫 입력인What의 정보가 마지막 입력인?에 다다라서는 거의 희석된 모습
입력의 앞부분이 뒤로 갈수록 옅어져 손실이 발생 -> 기울기 손실(Vanishing Gradient) -
어떤 문장이 긍정인지 부정인지 나누기 위해서라면 문장을 모두 읽은 후, 최종 Step의 Output만 확인해도 판단이 가능
-
하지만 문장을 생성하는 경우라면 이전 단어를 입력으로 받아 생성된 모든 다음 단어, 즉 모든 Step에 대한 Output이 필요
24.4. 순차적인 데이터! Recurrent 레이어 (2) LSTM
# LSTM(Long Short-Term Memory)
- 기울기 소실 문제를 해결하기 위해 고안된 RNN 레이어
- 4종류의 서로 다른 Weight를 가진 RNN
- Cell state 라는 새로운 개념이 추가
- 긴 문장이 들어와도 이 Cell state 를 통해 오래된 기억 또한 큰 손실 없이 저장
# Gated Recurrent Unit(GRU)
- LSTM의 변형 모델
- LSTM에 비해 GRU가 학습할 가중치(Weight)가 더 적다. (LSTM의 1/4)
# 양방향(Bidirectional) RNN
- 진행 방향에 변화를 준 RNN
- 순방향, 역방향을 모두 고려
- 방향이 반대인 RNN을 2개 겹쳐놓은 형태
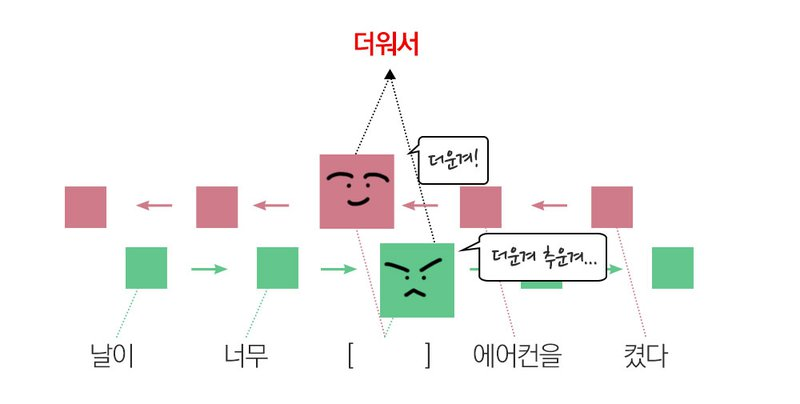
- 문장 분석이나 생성보다는 주로 기계번역 같은 테스크에 유리
- RNN의 2배 크기 Weight가 정의
