학습 목표
- 데이터를 배열로 저장하는 것에 대해 이해하고 list, NumPy의 사용법을 학습합니다.
- 구조화된 데이터를 저장하는 것을 이해하고 dictionary와 Pandas 사용법을 학습합니다.
- 이미지 데이터를 NumPy 배열로 저장하는 것을 이해하고 그 사용법을 학습합니다.
- 학습한 자료 구조를 활용해서 통계 데이터를 어떻게 계산하는지 학습합니다.
후기
9. Data 어떻게 표현하면 좋을까? 배열(array)과 표(table)
9.1 배열은 가까이에~ 기본 통계 데이터를 계산해 볼까?
- 평균 계산
- 입력 받은 값을 리스트로 저장하지 않아도 됨
-> 숫자 들을 총합이 필요할 뿐!
-> 입력 받을 때 마다 카운트를 세고, 입력 받은 값을 계속 더하면 됨
- 배열
- 표준편차 및 중앙값을 계산하기 위해서는 입력 받은 값들을 모두 저장해야 함
- 리스트를 활용
-> 리스트는 엄밀히 말해 동적 배열(Dynamic Array)
-> array모듈의 배열(array)은 크기와 타입이 동일해야 함
-> 파이썬의 리스트는 자료구조인 list와 array의 장점을 모두 취한 형태
- 리스트를 활용
- 중앙값
- 숫자들의 집합을 크기 순서로 배치했을 때, 중앙에 위치하는 값
-> 숫자들의 수가 짝수이면, 가장 중앙의 값이 중앙값
-> 숫자들의 수가 홀수이면, 가장 중앙으 두 값의 평균이 중앙값
9.2 끝판왕 등장! NumPy로 이 모든 걸 한방에!
NumPy: Numerical Python
-> 과학 계산용 고성능 컴퓨팅과 데이터 분석에 필요한 파이썬 패키지
- numpy의 장점
- 빠르고 메모리를 효율적으로 사용하여 벡터의 산술 연산과 브로드캐스팅 연산을 지원하는 다차원 배열 ndarray 데이터 타입을 지원한다.
- 반복문을 작성할 필요 없이 전체 데이터 배열에 대해 빠른 연산을 제공하는 다양한 표준 수학 함수를 제공한다.
- 배열 데이터를 디스크에 쓰거나 읽을 수 있다. (즉 파일로 저장한다는 뜻입니다)
- 선형대수, 난수발생기, 푸리에 변환 가능, C/C++ 포트란으로 쓰여진 코드를 통합한다.
- numpy 사용
- import numpy as np
- np.array([변수 나열]), np.arange(개수)
- 숫자들 사이에 문자가 포함되면 모두 문자열로 변환됨
- numpy 주요 기능
- 크기
- 타입
- 특수 행렬
- 브로드캐스트
- 슬라이스와 인덱싱
- 랜덤
- 전치행렬
- 통계 데이터 계산
- 합, 평균, 표준편차, 중앙값 계산 가능
- 배열.sum(), 배열.mean(), 배열.std(), numpy.median(배열)
9.3 데이터의 행렬 변환
- 이미지
- 이미지의 왼쪽 위로 좌표 (0, 0) 으로 표시
- 관련 라이브러리
a. matplotlib
b. PIL - PIL
- from Pil import Image
- .open(이미지 주소), .size, .crop((x0, y0, xt, yt)), .resize((w, h)), .save(이미지 주소)
- 흑백 이미지로 열기: .open(이미지 주소).convert('L')
- 이미지를 행렬로 변환
- 이미지_행렬 = np.array(이미지)
9.4 구조화된 데이터란?
데이터 내부에 자체적인 서브 구조를 가지는 데이터
9.5 구조화된 데이터와 Pandas
Pandas
- NumPy기반에서 개발되어 NumPy를 사용하는 애플리케이션에서 쉽게 사용 가능
- 축의 이름에 따라 데이터를 정렬할 수 있는 자료 구조
- 다양한 방식으로 인덱싱(indexing)하여 데이터를 다룰 수 있는 기능
- 통합된 시계열 기능과 시계열 데이터와 비시계열 데이터를 함께 다룰 수 있는 통합 자료 구조
- 누락된 데이터 처리 기능
- 데이터베이스처럼 데이터를 합치고 관계 연산을 수행하는 기능
- pip를 이용해 설치
- Series
일련의 객체를 담을 수 있는, 1차원 배열과 비슷한 자료 구조
- pandas.series(배열형태)
- index와 value로 구성
- index는 기본적을 정수 형태이나, 원한다면 다른 값을 넣어 줄 수 있음
-> pands.series(배열형태, index = 배열형태)
-> 시리즈.index = 배열형태 - 딕셔너리를 시리즈로 쉽게 변환할 수 있음
-> 시리즈 = pandas.series(딕셔너리) - 이름 설정 가능
-> 시리즈.name = 시리즈 객체 이름
-> 시리즈.index.name = 시리즈 객체의 인덱스 이름
- DataFrame
표와 같은 자료 구조, 여러개의 칼럼 가능
-
시리즈를 데이터프레임으로
-> 데이터프레임 = pandas.DataFrame(시리즈) -
시리즈와 데이터프레임 비교
- 시리즈
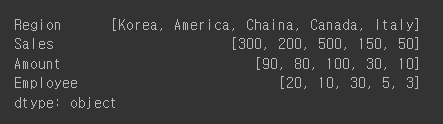
- 데이터프레임
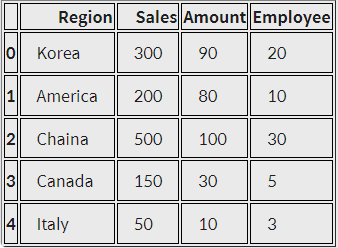
- 시리즈
-
데이터프레임.index = 배열형태
-
데이터프레임.columns = 배열형태 (-> 시리즈의 name과 같음)
구조화된 데이터 표현법 정리
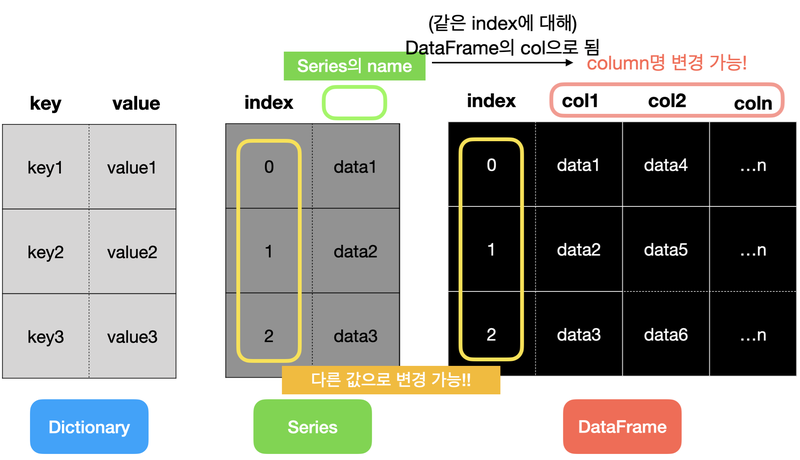
9.6 Pandas와 함께 EDA 시작하기
EDA(Exploratory Data Analysis)
-> 데이터 탐색, 즉, 데이터를 쭉 훑어보는 것
- EDA
- CSV 파일 읽기
- 데이터프레임 = pandas.read_csv(파일주소)
- .head(), .tail()
- 데이터셋의 처음 5행과 끝 5행을 보여줌
- 정수를 인자로 입력가능 -> 입력한 정수만큼만 보여줌
- .info()
- 칼럼별로 Null값과 자료형의 메서드를 보여줌
- .descrie()
- 칼럼별 기본적 통계 데이터를 보여줌
- 개수(Count), 평균(mean), 표준편차(std), 최솟값(min), 4분위수(25%, 50%, 75%), 최댓값(max)
- .isnull().sum()
- 칼럼별 결측값 총합을 보여줌
- EDA 통계
- .value_counts()
- 각 범주별 값의 개수
- .sum()
- 데이터셋[칼럼이름].sum() -> 해당 칼럼의 총합
- 데이터셋.sum() -> 칼럼별 총합
- .corr()
- 데이터셋[칼럼이름].corr(데이터셋[칼럼이름])
- 데이터셋.corr() -> 모든 칼럼들의 상관관계를 나타냄
- .drop()
- 데이터셋.drop(칼럼이름) -> 칼럼 버리기
- 몇가지 명령어
count(): NA를 제외한 수를 반환합니다. describe(): 요약 통계를 계산합니다. min(), max(): 최소, 최댓값을 계산합니다. sum(): 합을 계산합니다. mean(): 평균을 계산합니다. median(): 중앙값을 계산합니다. var(): 분산을 계산합니다. std(): 표준편차를 계산합니다. argmin(), argmax(): 최소, 최댓값을 가지고 있는 값을 반환합니다. idxmin(), idxmax(): 최소, 최댓값을 가지고 있는 인덱스를 반환합니다. cumsum(): 누적 합을 계산합니다. pct_change(): 퍼센트 변화율을 계산합니다.
