학습 목표
- 중복된 데이터를 찾아 제거할 수 있고, 결측치(missing data)를 제거하거나 채워 넣을 수 있다.
- 데이터를 정규화시킬 수 있다.
- 이상치(outlier)를 찾고, 이를 처리할 수 있다.
- 범주형 데이터를 원-핫 인코딩할 수 있다.
연속적인 데이터를 구간으로 나눠 범주형 데이터로 변환할 수 있다.
“데이터 분석의 8할은 데이터 전처리이다.”
후기
학습 내용
Fundamental 10. 다양한 데이터 전처리 기법
1. 결측치(Missing Data)
- 결측치를 처리하는 방법
- 결측치가 있는 데이터를 제거
- 결측치를 다른 데이터로 대체
- len(데이터) - 데이터.count()
- 전체 데이터 수에서 칼럼별 값이 있는 데이터 수를 빼면 결측치의 개수를 알 수 있음
- 아무 정보다 없는 칼럼이라면 제거할 수 있음
- 데이터 = 데이터.drop('칼럼', axis = 1)
- 결측치 확인
- 데이터.isnull(): 데이터 마다 결측치가 있는지 확인
- 데이터.any(axis = 1): 행마다 하나라도 값이 있는지 확인
-> isnull로 데이터 마다 True 또는 False를 반환하고 any를 통해 각 행에 결측치가 하나라도 있는지 확인
(False면 해당 행이 결측치로만 이뤄져 있다는 뜻)
데이터.isnull().any(axis = 1)
- 데이터에 위 값을 넣어주어 True인 데이터들만 추출
-> 데이터[isnull().any(axis = 1)]
- 결측치를 삭제 해주는 방법
- 데이터.dropna(how='all', subset=['수출건수', '수입건수', '수입금액', '무역수지'], inplace=True)
- subset 옵션으로 특정 칼럼을 선택하고, how 옵션으로 선택한 칼럼 전부가 결측치인 행을 삭제하기 위해 all을 입력(any는 하나라도 결측치인 경우 삭제)
- inplace 옵션으로 데이터 내부에 바로 적용
2. 중복된 데이터
- 중복된 데이터 확인
- 데이터.duplicated()
- 데이터[데이터.duplicated()]: 중복된 데이터만 출력
- 중복된 데이터 삭제
- 데이터.drop_duplicates()
- 옵션을 통해 여러가지 조절 가능
3. 이상치(Outlier)
- 이상치
- 대부분의 값에서 벗어나 극단적으로 크거 작은 값
- 이상치를 찾은 후에는?
- 원래 데이터에서 삭제 후 이상치끼리 따로 분석
- 다른 값으로 대체
- 예측 모델을 만들어 예측치로 대체
- binning을 통해 수치형 데이터를 범주형 데이터로 바꿈
- z-score method
- 데이터[abs(데이터[칼럼] - np.mean(데이터[칼럼]))/np.std(데이터[칼럼])>z].index
- 데이터에서 평균을 빼준 것에 절대값을 취하고, 표준편차로 나눠준 후, 값이 z보다 큰 데이터의 인덱스를 추출
- z보다 작거나 같은 값을 추출하여 이상치가 포함된 데이터를 제외할 수 있음
- IQR(Interquartile range) method
- 사분위 범위수: 제3사분위수(Q3)에서 제1사부위수(Q1)를 뺀 값
-> 데이터의 중간 50% 범위로 보면 됨
- Q1 − 1.5∗IQR보다 왼쪽에 있거나, Q3 + 1.5*IQR보다 오른쪽에 있는 경우를 이상치라고 판단
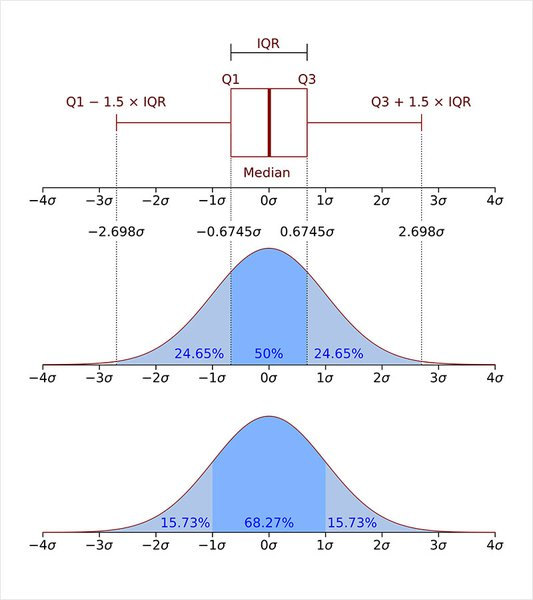
- Q3, Q1 = np.percentile(데이터, [75, 25])
- z-score method의 단점
- 평균과 표준편차가 이상치에 영향을 많이 받으므로 robust하지 않음
- 작은 데이터셋에서 결과 이상함(특히, 12개 이하의 데이터를 가지는 데이터셋에서는 결과 나타낼 수 없음)
4. 정규화(Normalization)
- 일반적으로 칼럼 간에 범위의 차가 큰 경우 전처리 과정으로 정규화를 해줌
-> 어떤 한 칼럼에만 큰 영향을 받지 않기 위해
- 정규화 방법
- 표준화(Standardization)
- (평균: 0, 분산: 1) 으로 변환
- (데이터 - 평균) / 분산
- Min-Max scaling
- (최솟값: 0, 최댓값: 1) 으로 변환
- (데이터 - 최소값) / (최대값 - 최소값)
- Standardization
- 원하는 칼럼들을 리스트 변수로 지정하고, 데이터[리스트]에 .mean()과 .std()를 이용한다.
- Min-Max Scaling
- 원하는 칼럼들을 리스트 변수로 지정하고, 데이터[리스트]에 .min()과 .max()를 이용한다.
- train 데이터와 test 데이터가 나뉘어져 있는 경우, 두 데이터를 모두 같은 방법으로 정규화 해야함
- scikit-learn의 StandardScaler, MinMaxScaler를 이용하는 방법도 있다.
5. 원-핫 인코딩(One-Hot Encoding)
- 카테고리별 이진 특성을 만들어 해당하는 특성만 1, 나머지는 0으로 만드는 방법
- pands의 get_dummies 함수로 쉽게 구현 가능
- 새 데이터 = pd.get_dummies(데이터[칼럼])
- 두 데이터 합쳐주기
- 새 데이터 = pd.concat([데이터1, 데이터2], axis=1)
6. 구간화(Binning)
- 데이터를 구간별로 나누는 기능
- 히스토그램과 같이 연속적인 데이터를 구간을 나눠 분석할 때 사용하는 방법
- 수치형 데이터를 범주형 데이터로 변형
- cut
bins = [0, 2000, 4000, 6000, 8000, 10000]
ctg = pd.cut(데이터, bins=bins)
출력)
0 (4000, 6000]
1 (8000, 10000]
2 (0, 2000]
3 (2000, 4000]
4 (0, 2000]
...
95 (2000, 4000]
96 (8000, 10000]
97 (6000, 8000]
98 (4000, 6000]
99 (2000, 4000]
Length: 100, dtype: category
Categories (5, interval[int64, right]): [(0, 2000] < (2000, 4000] < (4000, 6000] < (6000, 8000] < (8000, 10000]]
ctg[0]: 데이터[0]가 속한 카테고리
ctg.value_counts().sort_index(): 구간별로 값이 몇 개 속해 있는지 확인
bis 옵션에 정수 입력: 데이터의 최대, 최소를 균등하게 정수입력 개수만큼 나눠줌
- qcut
* 데이터 분포를 비슷한 크기의 그룹으로 나눠줌
* 새 데이터 = pd.qcut(데이터, q=정수)
