참고 글)
- Kafka 사용이유 ( vs RabbitMQ )
- Kafka vs RabbitMQ
- Redis,RabbitMQ의 차이점
- RabbitMQ와 Kafka의 차이? 메시지 브로커와 이벤트 스트리밍 플랫폼
0. 개요
포스팅 목적
이전 회사에서 rabbitmq와 celery를 이용해서 크롤프로세스를 개발한 경험이 있는데, rabbitmq와 kafka가 비슷한 역할을 한다고만 알고있었는데, 채용 기술 우대사항이나 이런 경험이 있으면 좋아요란에 kafka가 훨씬 많이 띄는 것 같다. 메세징 큐 방식들에 어떤 차이가 있고 내가 경험한것과 어떻게 관련이 있는지 정리해보려한다.
기본적인 메세지 큐 구조

일반적으로 Producer에서 메세지를 생성, 전송하고 큐를 사용하여 producer, consumer간 결합성을 약하게 해주면서 우선순위나, 라우팅, failover등 여러 기능을 제공해주고 consumer에서 메세지를 사용하는 구조이다.
메시지 큐의 장점
- 비동기 (Asynchronous) : Queue에 넣기 때문에 나중에 처리 가능
- 비동조 (Decoupling) : 애플리케이션과 분리
- 탄력성 (Resilience) : 일부가 실패 시 전체에 영향을 받지 않음
- 과잉 (Redundancy) : 실패할 경우 재실행 가능
- 보증 (Guarantees) : 작업이 처리된 걸 확인 가능
- 확장성 (Scalable) : 다수의 프로세스들이 큐에 메시지를 보낼 수 있음
1. rabbitMQ, celery
○ Celery
celery는 분산 메세지 전달을 기반으로 하는 비동기(호출되는 함수 작업 완료여부를 신경쓰지 않고 추후 완료 시 콜백함수를 실행시킨다)작업 작업 큐이다. (worker)
Celery를 쓰는 이유는, 무거운 실행내용을 메인 로직에서 빼내 별도로 워커에게 위임시키기 위함이고, Broker와 함께 쓴다.
작업을 Celery task로 정의, Broker(RabbitMQ)와 Consumer(Celery Worker)를 이용해 비동기(Async)하게 일반적으로 많이 사용한다.
○ RabbitMQ
: AMQP를 구현한 메세지 브로커 시스템,
이 때, AMQP(advanced message queing protocol)는 client가 메세지 미들웨어 브로커와 통신할 수 있게 해주는 메세징 프로토콜이다.
- AMQP프로토콜
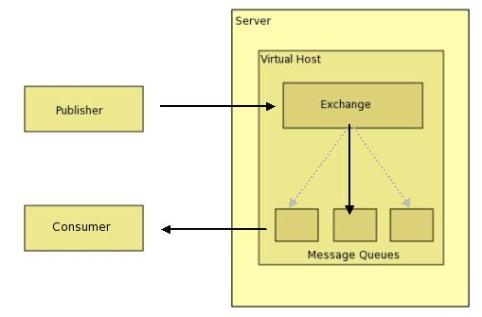
- AMQP의 구성요소
- Exchange : publisher로부터 수신한 메세지를 메세지 큐에 분배하는 라우터역할
- Queue : 메세지를 메모리나 디스크에 저장했다가 Consumer에게 전달하는 역할
- Binding : Exchange와 Queue의 관계를 정의.
RabbitMQ에서는 위 AMQP 구성요소를 이용해 메세지큐를 구현한다.
RabbitMQ에서는 응용 프로그램(applications)에게 메시지를 주고 받을 수 있으며, 메시지가 수신될 때까지 안전하게 있을 수 있도록 하는 공용 플랫폼(common platform)을 제공한다.
- AMQP의 구성요소
- 메시지를 다른 대기열로 보낼 수있는 라우팅 시스템을 갖추고 있다.
- 우선 순위가 높은 메시지를 먼저 사용하기 위해 작업자가 사용할 수있는 메시지의 우선 순위를 지원한다.
- 크고 복잡한 메시지에 적합하다.
- 필요에 따라 비동기/동기식 처리가 가능하다.
rabbitmq는 exchange나 메시지 표식 등을 이용한 똑똑한 브로커에 초점을 가지고있다. event producer가 메세지를 생성하면, 메세지프로커 rabbitmq에서 메세지를 어떤 큐에 발송할지 결정하는 exchange를 하게되고 메세지는 event queue가 가져가게된다.
2. kafka
○ kafka란
분산 메시징 시스템. 분산 환경에 특화되었으며 rabbitmq와 동일역할을 하지만 클러스터링 구성이나 fail-over를 쉽게 할 수 있도록 설계되어있다. broker의 역할을 하지만 중앙집중화되어있고 소비자 중심의 rabbitmq와 다르게 생산자 중심의 설계로 구성되어있다. 구독 방식의 비동기식으로 구성되어있다(pub-sub모델).
카프카 사용 사례(아키텍처)
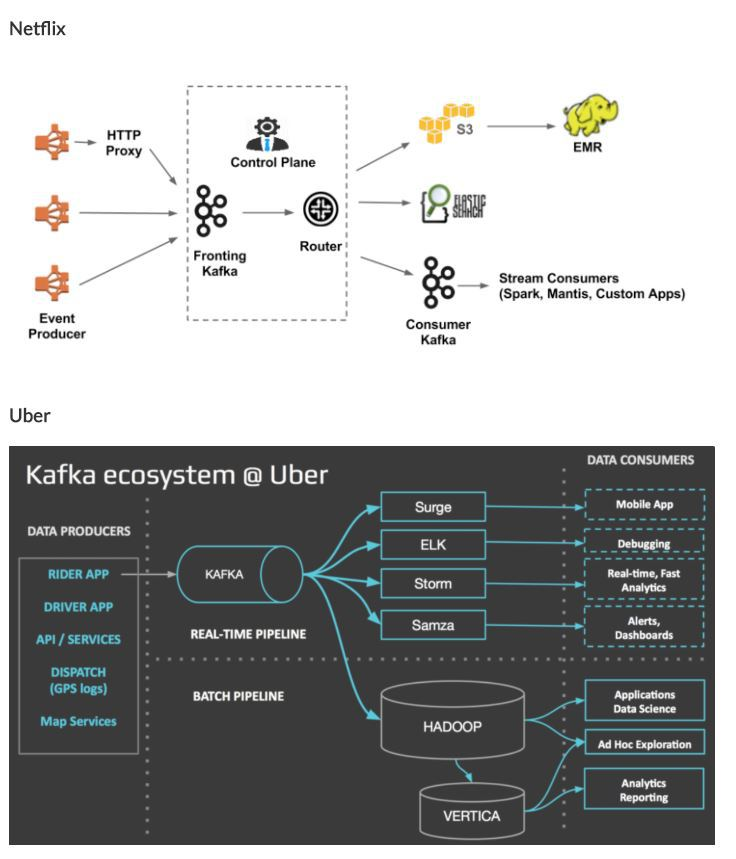
kafka를 통해 필요한 어플리케이션 elk, hadoop등에 메세지를 전달한다. 넷플릭스같은 경우에는 fronting kafka가 있고 consumer kafka로 2개로 구성되어서 왜인지 이유가 신경쓰여서 한번 살펴봤다.(위 링크에 evolution of data-pipeline이 설명되어있으며 위 이미지가 가장 최신(V2.0)이고 이전 아키텍처(1.5)는 front에 kafka가 아닌 chukwa라는 로그수집,분석,모니터링하는 하둡의 서브 툴같은 것이 있었다고하며, routing service에대한 이슈가 있었다고함.( +replication이 없음, 아키텍처 단순화라는 이유도 존재)
현재 넷플릭스 데이터 파이프라인은 Data Ingestion, Data Buffering, Data Routing의 세 가지 파트로 구성되어있으며
(1)Data Ingestion에서는 데이터를 ingestion하는 2가지 방법으로 Javalibrary를 사용해 kafka에 direct로 쓰는 방법, kafka에 데이터를 쓰는 http proxy를 보낸다. (kafka는 브로커의 역할을 할 때, 7일정도동안 filesystem에 데이터를 저장하기 때문에 바로 소비해버리는 rabbitmq와 다르게 더 안정적이라고 했다.) 두 가지 kafka가 있는데 우선 여기서 쓰인 fronting kafka가 메인이며, 후에 consumer kafka는 secondary이다.
(2) Data Buffering에서는 복제본의 message queue역할을 한다.
(3)Data Routing에서는 fronting kafka에서 S3(AWS), ElasticSearch, Secondary Kafka로 데이터를 보내준다.
넷플릭스는 계속해서 QoS(서비스품질), scalability, availability, operability 등을 계속 포커싱하면서 발전시키고있다고 하며 kafka를 cloud scale에서 run하는 방법, 라우팅서비스를 docker container에 배포하는것을 어떻게 매니징하는지 등등.. production에서 넷플릭스정도의 규모를 운영하면서 생기는 문제들을 핸들링하다보니 위와같은 구조를 쓰게되었고 아마 kafka가 가용성이 있고, 분산처리에 특화되었으며, replication을 지원하기 때문에 chuckwa를 제거하지 않았을까 한다. 여기서 secondary kafka 가 있는 이유에 대해 나오는데, 카프카 스트림에 추가 필터링을 적용하는것이 하나의 kafka토픽에서 소비하고 다른 kafka토픽으로 생산할 라우터가 있는 이유였다라고 함.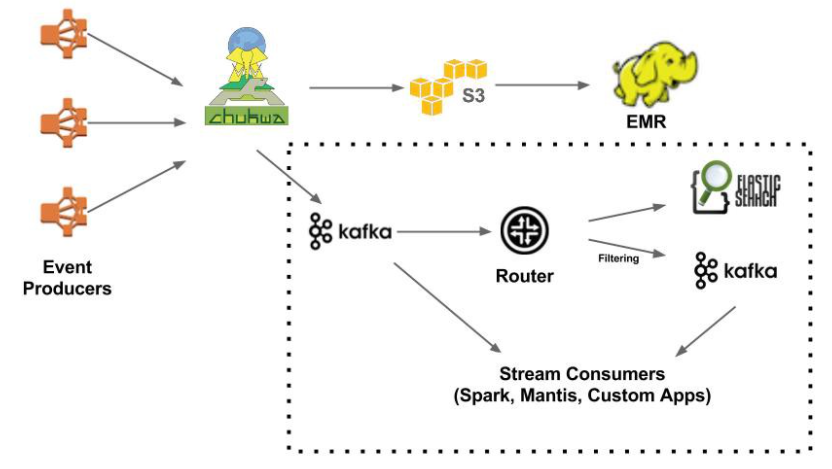
이유였다라고 말한 것은 이전에 도입 했을 때의 목적. kafka가 2개가 있는 것은 V1.5때 도입되었다. 위 이미지 처럼 라우터를통해 다른 어플리케이션에, 필터링을 통해 두번 째 카프카에 내려줬는데, 아키텍처를 좀 더 단순화하면서 frontkafka에서는 router로 바로 내려주고 router에서 kafka에 라우팅 해주면 아래와같이 stream consumer들에게 역할을 해주는 듯 하다.
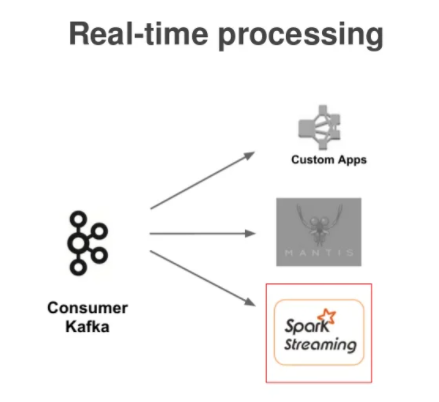
3. kafka vs rabbitMQ
rabbitMQ는 메세지 브로커 방식이고, kafka는 pub/sub 방식.
메세지 브로커는 어플리케이션들이 통신,정보교환할 수 있도록 하는 sw모듈. broker는 어플리케이션간 중개자로 작동한다.
그러나 pub/sub은 생산자가 메세지를 게시할 수 있도록 하는 메세지 배포 패턴이며, kafka는 이벤트 스트리밍 플랫폼.
전통적 메세지 브로커 형태(rabbitmq)는 소비자와 브로커의 결합력이 높아 앱 트래픽이 높아져도 수평적으로 확장하는데 어려움이 존재. 이벤트 메세지가 성공적으로 전달되었다 판단되었을 경우 메세지가 큐에서 삭제되어 이벤트 재 재생이 어렵다.
이벤트 스트리밍 플랫폼(kafka)은 메세지 전달이라는 큰 틀에서 같은 기능을 하지만, 작동방식에 차이가 존재. sub-pub방식에 의해 토픽이라고 불리는 이벤트의 레코드 로그를 streamer에 순서대로 기록하게되고(offset) , consumer의 메시지 소비 이후에도 유지되는 토픽에 접근이 가능하다.(이벤트 재생 가능) : 좀 더 유연하고 느슨한 결합, 격리와 확장이 쉽다.
○ rabbitmq, kafka 각 장점
- Kafka의 차별점/장점
- 기존 메시징 시스템과는 달리 메시지를 파일 시스템에 저장함으로 영속성(durability)이 보장
- consumer가 broker로 부터 직접 메시지를 가지고 가는 pull 방식으로 동작
- producer 중심적, 많은 양의 데이터를 파티셔닝하는데에 기반을 둔다
- consumer가 전달 상태를 기억함
- 대용량의 데이터를 처리해야 할 때 사용
- RabbitMQ의 차별점/장점
- 유연한 라우팅이 가능
- 제품 성숙도가 높은편
- 개방형 프로토콜을 위한 AMQP(Advanced Message Queuing Protocol)를 구현위해 개발
- AMQP : Client어플리케이션과 middleware broker와의 메시지를 주고받기 위한 프로토콜
- broker 중심적, producer/consumer간의 보장되는 메세지 전달에 초점
- 클러스터 구성이 쉽고, Manage UI가 제공되며 플러그인도 제공되어 확장성이 뛰어남
- broker상에서 전달 상태를 확인하기 위한 메세지 표식을 사용
데이터 처리보단 관리적 측면이나 다양한 기능 구현을 위한 서비스를 구축할 때 사용
○ rabbitmq, kafka 적절한 사용
- kafka가 적절한 곳
kafka 키워드 요약 : 실시간 처리Kafka는 복잡한 라우팅에 의존하지 않고 최대 처리량으로 스트리밍하는 데 가장 적합. 또한 이벤트 소싱, 스트림 처리 및 일련의 이벤트로 시스템에 대한 모델링 변경을 수행하는 데 이상적. Kafka는 다단계 파이프라인에서 데이터를 처리하는 데도 적합. 결론적으로 스트리밍 데이터를 저장, 읽기, 다시 읽기 및 분석하는 프레임워크가 필요한 경우 Kafka. 정기적으로 감사하는 시스템이나 메시지를 영구적으로 저장하는 데 이상적.
- RabbitMQ가 적절한 곳
RabbitMQ 키워드 요약 : 장시간 실행되는 태스크, 안정적인 백그라운드 작업 실행, 애플리케이션 간/내부 통신/통합복잡한 라우팅. 이 경우에는 RabbitMQ를 사용. RabbitMQ는 신속한 요청-응답이 필요한 웹 서버에 적합. 또한 부하가 높은 작업자(20K 이상 메시지/초) 간에 부하를 공유. RabbitMQ는 백그라운드 작업이나 PDF 변환, 파일 검색 또는 이미지 확장과 같은 장기 실행 작업도 처리할 수 있다.
