참고 링크 ) https://wikidocs.net/22654
참고 링크 ) https://han-py.tistory.com/361
1.Hadoop
what is Hadoop
Hadoop : High-Availability Distributed Object-Oriented Platform
빅데이터 분산 저장, 분산 컴퓨팅 솔루션. 클러스터링을 통해 데이터를 병렬로 동시에 처리하여 처리속도를 높이는 것을 목적으로함. 병렬처리, 분산처리하는 것이 핵심 목적.
: 메인 개념은 HDFS(하둡파일시스템), MapReduce(맵리듀스) 프레임워크였으나(코어 프로젝트),
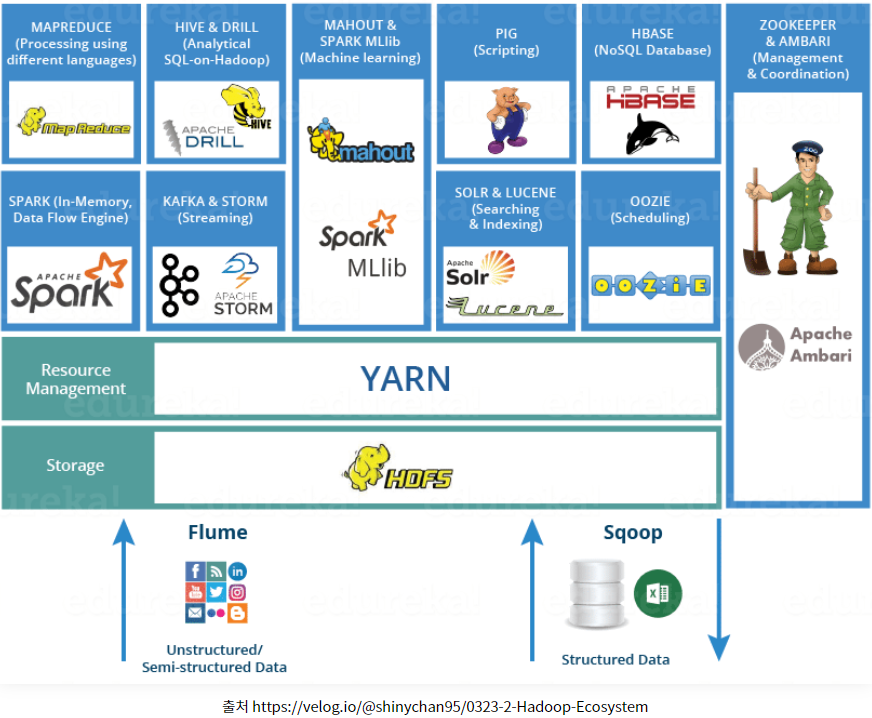
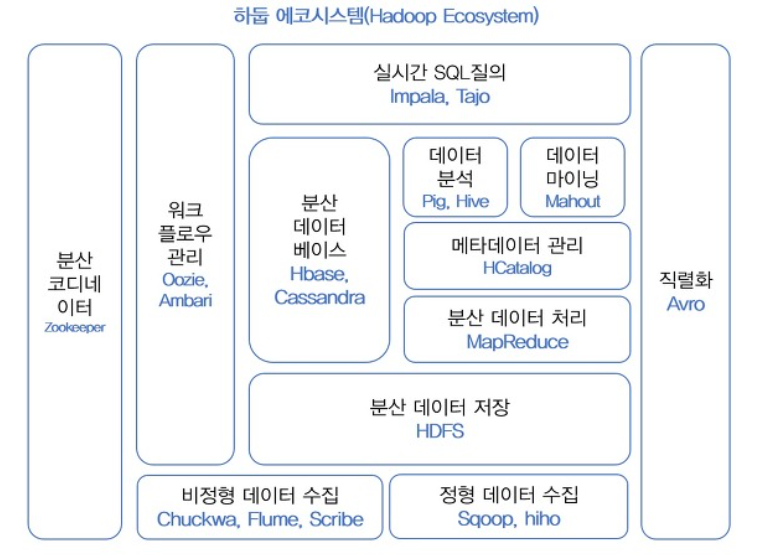
데이터저장,실행엔진,프로그래밍,데이터처리(서브 프로젝트) 등 Ecosystem을 의미하는 개념으로 현재는 발전되었다.
Hadoop의 철학
- 데이터를 프로그램이 있는 컴퓨터에 가져와 처리하는 것이 일반론. 그러나 데이터가 대용량일 경우, 데이터를 옮기는 것 보다 프로그램을 옮기는 것이 효율적이라는 개념으로 Hadoop은 데이터가 있는 컴퓨터에 프로그램을 전송하여 처리한다.
하둡의 구성 요소
- Hadoop Common : 하둡의 다른 모듈들을 지원하기 위한 공통 컴포넌트 모듈
- Hadoop HDFS : 분산저장을 처리하기 위한 모듈(여러 서버를 하나처럼 묶어 데이터 저장)
- Hadoop Yarn : 병렬처리를 위한 클러스터 자원관리 및 스케줄링.
- Hadoop MapReduce : 분산되어 저장된 데이터를 병렬처리할 수 있게 해주는 분산처리 모듈.
- Hadoop Ozone : 하둡 오브젝트 저장소
기능이 점차 추가되어 위와같이 Haddop Ecosystem으로 구성요소 확장됨.
하둡 장점 & 단점
장점
- 오픈소스로 라이선스 비용부담 적고, 비용대비 빠른 데이터처리
- 가용성, 무중단 장비추가 용이(Scale Out)
- 일부 장비 장애 발생해도 전체 시스템 영향 적음(Fault Tolerance)
- 오프라인 배치 프로세싱에 최적화
단점
- HDFS에 저장된 데이터 변경 불가
- 실시간 데이터 분석처럼 신속한 작업에 부적합
- 버전별 연동 어려움 / 설치 세팅 어려움.
2.HDFS (Hadoop Distributed FileSystem)
HDFS특징 : 분산저장
Hadoop component중 storage HDFS는 file system중에서도 여러 컴퓨터로 클러스터링되어진 저장소에 파일을 분산저장할 수 있는 파일시스템이며, 특징으로는
- 블록 단위 저장 : HDFS는 데이터를 블록 단위로 나누어 저장한다.
- 블록 복제를 이용한 장애 복구(Fault tolerance) :블록에 문제가 생기면 다른 블록을 이용해 데이터 복구.
- 읽기중심 : 데이터를 여러 번 읽는 것이 목적이고, 파일 수정을 지원하지 않는다.
- 데이터 지역성 : 맵리듀스는 처리 알고리즘이 있는 곳에서 데이터를 이동시키지 않고 데이터가 있는 곳에서 알고리즘을 처리하여 네트워크를 통해 대용량데이터를 이동시키는 비용을 줄일 수 있다.
HDFS 아키텍처
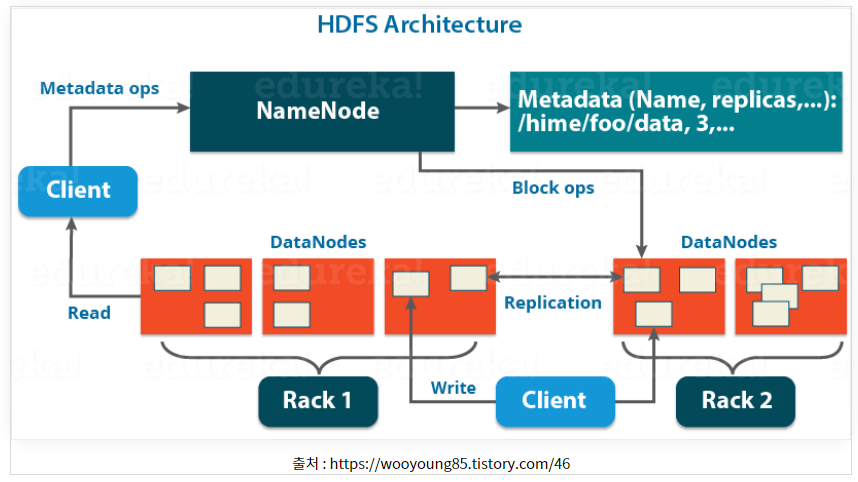
HDFS는 NameNode, DataNode, Client 모듈로 구성되어있음.
- Name Node : HDFS 전반 구성정보와 블록 정보를 포함하는 메타데이터를 관리.
- 메타데이터 - 파일이름,크기,생성시간,접근권한,소유,파일이 위치한 블록정보 등으로 구성. 파일로 보관되며 Namenode가 실행될 때 파일을 읽어 메모리에 보관.
메타데이터 Fsimage - 네임스페이스와 블록정보
메타데이터 Edits - 파일 생성,삭제에대한 트랜잭션 로그. 메모리 저장하다 주기적으로 생성. - 데이터 노드 관리 - NameNode는 데이터 노드가 주기적으로 전달하는 heartBeat와 blockreport를 이용하여 데이터 노드의 동작상태, 블록상태를 관리.
- 메타데이터 - 파일이름,크기,생성시간,접근권한,소유,파일이 위치한 블록정보 등으로 구성. 파일로 보관되며 Namenode가 실행될 때 파일을 읽어 메모리에 보관.
- Data Node : 실제 파일을 저장.
- 블록단위로 파일 저장.
- 네임노드에 하트비트와 블록리포트 주기적 전달. Heartbeat를 전달하여 Live/Dead 상태 알림.
- Client : 사용자가 작성한 프로그램으로 HDFS에 파일을 쓰거나 읽는 작업을 요청.
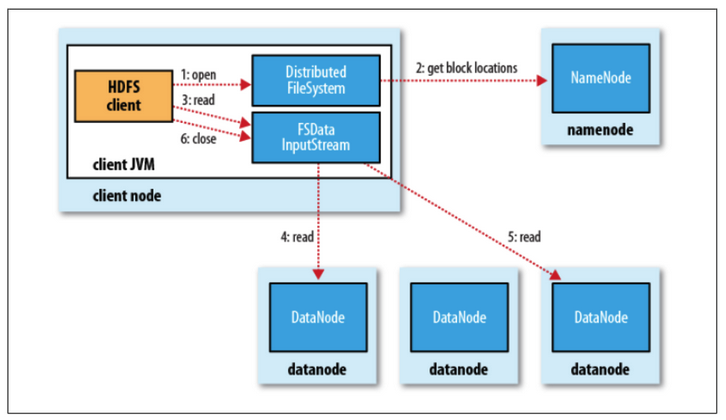
- 파일읽기
1.네임노드에 파일이 보관된 블록 위치 요청
2.네임노드가 블록 위치 반환
3.각 데이터 노드에 파일 블록을 요청
4.노드의 블록이 깨져 있으면 네임노드에 이를 통지하고 다른 블록 확인
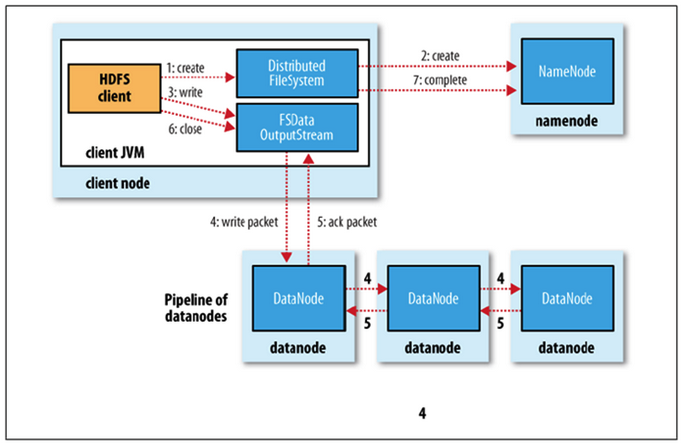
- 파일쓰기
1.네임노드에 파일 정보를 전송하고, 파일의 블록을 써야할 노드 목록 요청
2.네임노드가 파일을 저장할 목록 반환
3.데이터 노드에 파일 쓰기 요청
4.데이터 노드간 복제가 진행
- 파일읽기
3. Map Reduce
MapReduce 핵심 개념
HDFS는 데이터를 분산 저장하는 방식이었다면, 분산 처리하는 방법이 MapReduce.(최근엔 Spark가 많이 대체하고있다)
핵심 과정은 큰 덩어리를 작게 나누어서(Split) 여러 곳에서 각각 처리(Map)한 후 처리된 것을 모아서 결과물을 내는(Reduce) 방식.
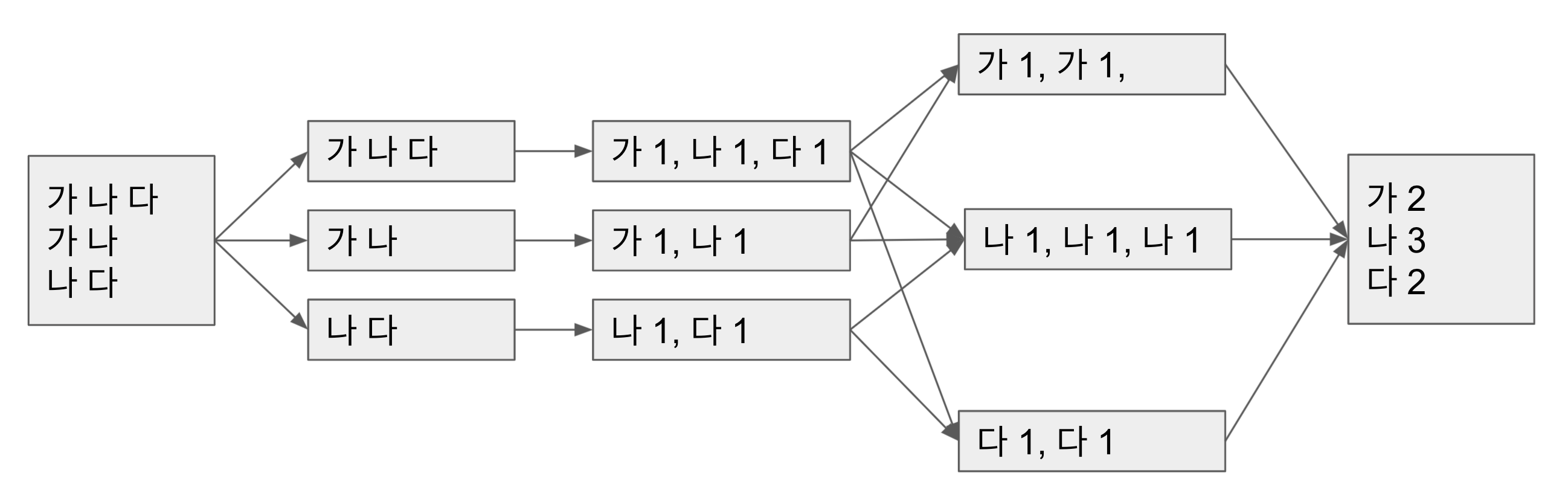
split은 큰 파일들을 작은 단위의 chunk들로 나누어 분산파일시스템에 저장
Map은 전체 데이터를 작은 단위로 나눈 chunk에 대해 수행할 로직이고(ex- 텍스트를 파싱해서 단어의 개수를 counting)
Reduce는 분산되어 처리된 결과값들을 하나로 합쳐주는 과정(Merge)이며, 분산된 환경에서 병렬적으로 수행됨.
Map Reduce 처리단계
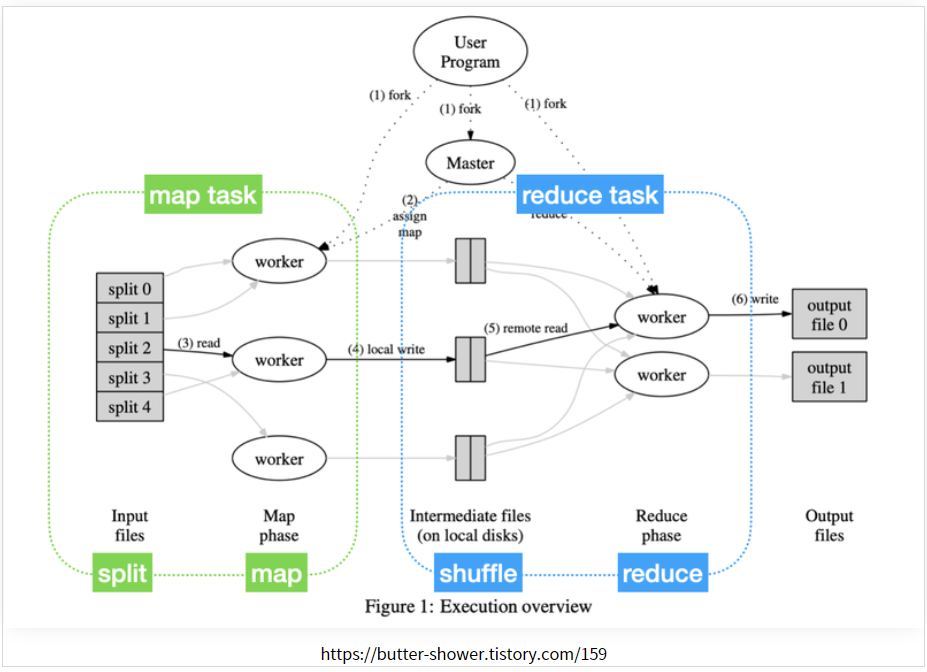
- (1) Fork
사용자가 map과 Reduce 함수를 정의한 프로그램을 실행하면 이는 (1)Master노드, (2)Map을 실행할 Worker노드(mapper), (3)Reduce를 실행할 Worker노드(Reducer)에 복사. - (2) Assign map and reduce
master노드는 mapper노드들에게 mapping역할(사용자정의)을, Reducer 노드들에게 reducing역할(사용자정의)을 수행하라고 지정해줌. - (3) Read Map, Local Write
Mapper(worker) node들은 데이터 chunk를 HDFS로부터 읽어오고, 데이터에 Map함수를 실행하여key-value형태의 Intermediate 데이터를 생성하고 local 저장소에 저장. 이후 Mapper노드는 Master Node에게 mapping작업 완료 알림. - (4) Reduce, Write
master노드는 Reducer Node들에게 reduce실행 명령을 내리고 Reducer 노드들은 디스크에 저장되어있는 Intermediate데이터를 읽어오고, reduce함수를 실행하여 최종 결과물을 설정한 파일형태로 출력(RecordWriter).
