역할
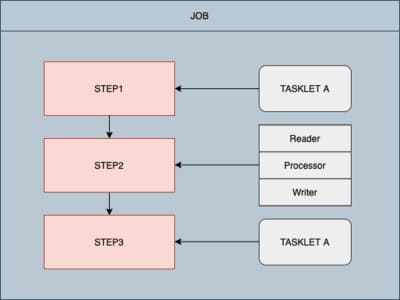
출처 : https://velog.io/@hyunho058/Spring-Batch-Spring-Batch%EC%8B%9C%EC%9E%91
Batch프로세스 과정은 크게 3가지로 나뉜다
Job -> Step -> Tasklet
위와같은 일련의과정을 하나의 Job하나의 배치처리단위라고 말한다
예를들어 옷을 한번에 모아 빨래를하는 세탁기를 보자
Jop : 빨래
- Step : 설정
- Tasklet : A사 세제를 넣는다
- Tasklet : A사 섬유유연제를 넣는다
- Tasklet : 세탁, 헹굼, 탈수 시간을 정한다
- Step : 세탁
- Tasklet : 일정시간동안 세탁을 진행한다
- Step : 헹굼
- Tasklet : 일정시간동안 헹굼을 진행한다
- Step : 탈수
- Takslet : 일정시간동안 탈수를 세탁기는 위처럼 쌓여있는 옷에대해 한번에 세탁(배치)를 진행한다
JobLauncher
위에서 설명했던 Job을 실행해주는 객체이다
public class SimpleJobLauncher implements JobLauncher, InitializingBean {
@Override
public JobExecution run(final Job job, final JobParameters jobParameters) ... {
...
//유효성 체크
job.getJobParametersValidator().validate(jobParameters);
jobExecution = jobRepository.createJobExecution(job.getName(), jobParameters);
try {
taskExecutor.execute(new Runnable() {
@Override
public void run() {
...
job.execute(jobExecution);
...
}
}
}catch(...) {
jobExecution.upgradeStatus(BatchStatus.FAILED);
...
jobRepository.update(jobExecution);
}
return jobExecution;
}
}위와같이 유효성 검사를 진행하고 jobExecution생성한 뒤 execute로 실행한다
만약 에러가 날시 FAILED로 상태를 설정한다
이 중 중요하게 봐야될 부분이 2가지있다
createJobExecution같은경우 (Job, JobParameter)이 하나의 키값으로 해당하는 내용이 없을경우 JobInstance를 생성하고 있을경우 작업을 다시 이어한다
이 때 트랜잭션 격리수준이 REPETABLE_READ이상인경우 해당 메서드 호출을 차단해야한다 첫번째 트랜잭션은 JobExecution을 얻지만 두번째 트랜잭션부터 JobExecutionAlreadyRunningException을 얻기때문이다(Phantom read)
두번째로 taskExecutor인데 이는 기본적으로 SyncTaskExecutor를 사용한다 즉 동기작업이다 따라서 비동기로 사용할꺼면 ASyncTaskExecutor로 설정해주어야 한다
Job
Job은 Name과 Parameter정보를 가지고있다
JobParameters.class
private final Map<String,JobParameter> parameters;AbstractJob.class
@Override
public String getName() {
return name;
}
@Override
public final void execute(JobExecution execution) {
...
// 파라미터 검증
jobParametersValidator.validate(execution.getJobParameters());
if (execution.getStatus() != BatchStatus.STOPPING) {
...
listener.beforeJob(execution);
doExecute(execution);
...
}
...
finally {
...
execution.setStatus(BatchStatus.STOPPED);
execution.setExitStatus(ExitStatus.COMPLETED);
}
...
listener.afterJob(execution);
...
}listener처리작업과 doExecute로 작업을 진행한뒤 각 Status, ExitStatus를 설정하고 after리스너로 처리한뒤 작업이 종료된다
doExecute는 Template Method패턴을 이용해 하위클래스들에게 처리를 위임시킨다
- SimpleJob : Step을 순서대로 실행한다
- FlowJob : 복잡한 순서를 처리할때 사용된다
Step
public interface Step {
...
// true : 완료된 Step도 다시실행
boolean isAllowStartIfComplete();
...
// 동일한 식별자로 작업을 시작할 수 있는 횟수
int getStartLimit();
void execute(StepExecution stepExecution) throws JobInterruptedException;
}Step또한 execute를 이용해 처리된다
JobStep
@Override
protected void doExecute(StepExecution stepExecution) throws Exception {
...
JobExecution jobExecution = jobLauncher.run(job, jobParameters);
...
} Step내에서 Job을 재귀적으로 사용할 수 있습니다
TaskletStep
@Override
protected void doExecute(StepExecution stepExecution) throws Exception {
...
stream.update(stepExecution.getExecutionContext());
...
stepOperations.iterate(new StepContextRepeatCallback(stepExecution) {
@Override
public RepeatStatus doInChunkContext(RepeatContext repeatContext, ChunkContext chunkContext)
throws Exception {
StepExecution stepExecution = chunkContext.getStepContext().getStepExecution();
result = new TransactionTemplate(transactionManager, transactionAttribute)
.execute(new ChunkTransactionCallback(chunkContext, semaphore));
...
}
}
...
}Tasklet을 호출한다 이때 각 호출은 트랜잭션으로 감싸져 있다
트랜잭션을 담당하는 ChunkTransacationCallback에 대해서 조금더 살펴보자
ChunkTransacationCallback.class
private final Semaphore semaphore;
@Override
public RepeatStatus doInTransaction(TransactionStatus status) {
...
StepContribution contribution = stepExecution.createStepContribution();
...
try {
result = tasklet.execute(contribution, chunkContext);
if (result == null) {
result = RepeatStatus.FINISHED;
}
} catch(..) {
rollback(..);
}
finally {
semaphore.acquire();
locked = true;
}
...
try {
stream.update(stepExecution.getExecutionContext());
getJobRepository().updateExecutionContext(stepExecution);
stepExecution.incrementCommitCount();
getJobRepository().update(stepExecution);
catch(..) {
rollback(..);
}
}
@Override
public void afterCompletion(int status) {
try {
...
}catch(..) {
rollback(stepExecution);
}finllay {
if (locked) {
semaphore.release();
}
locked = false;
}
}Transaction을 진행할때는 정상처리되면 CommitCount를 올리며 정보를 저장하고 Exception발생시 Rollback을 진행한다 또한 정상처리가 됐다면 세마포어를 이용해 락을건다 요청이 완료됐을경우 semaphore를 해지하며 lock을푼다 에러시 rollback
세마포어락 : 특정 개수에 Context가 있는데 전부다 차기전까지는 계속 받아들이다 횟수를 넘을경우 대기 ( 뮤텍스락이 여러개인느낌 )
Tasklet
CallableTeskletAdapter
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
return callable.call();
}Callable을 통해 비동기로 함수를 처리하고 결과값을 await한다
ChunkOrientedTasklet
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) {
Chunk<I> inputs = (Chunk<I>) chunkContext.getAttribute(INPUTS_KEY);
if (inputs == null) {
inputs = chunkProvider.provide(contribution);
...
chunkProcessor.process(contribution, inputs);
chunkProvider.postProcess(contribution, inputs);
}
SimpleChunkProcessor.class
@Override
public final void process(StepContribution contribution, Chunk<I> inputs) {
...
Chunk<O> outputs = transform(contribution, inputs);
...
write(contribution, inputs, getAdjustedOutputs(inputs, outputs));
}
protected Chunk<O> transform(StepContribution contribution, Chunk<I> inputs) {
...
for (Chunk<I>.ChunkIterator iterator = inputs.iterator(); iterator.hasNext();) {
final I item = iterator.next();
...
output = doProcess(item);
}
...
}
protected final O doProcess(I item) throws Exception {
...
listener.beforeProcess(item);
O result = itemProcessor.process(item);
listener.afterProcess(item, result);
return result;
...
}input(read) -> process(brefore -> process -> after) -> write의 순서대로 Tasklet을 진행한다
이렇게 청크를 나누어서 처리할경우 모든 배치작업을 한번에 커밋 or 롤백이아닌 일정 구간별로(청크)를 나누어서 커밋 or 롤백을 시킬 수 있어 리스크가 많이 줄어든다
정리
- JobInstance같은경우 Phantom read방지를 위해 Repetable Read 이상의 격리수준에서 create메서드를 동시호출하면 안된다
- Job을 통해 Job, Parameter정보를 받고 Step을 통해 수행순서를 지정하며 Tasklet을 통해 작업단위를 규정할 수 있다
- Chunk를 사용해 메모리에 한번에 올리지않고 일정구간을 나누어 커밋을 진행할 수 있다
