Abstract
VSLAM은 다른 센서와의 융합성이 좋고 비용이 적다는 측면에서 매우 매력적인 기술이다.
본 논문에서는 traditional VSLAM과 발전과정, sementic VSLAM을 소개한다.
전통적인 SLAM의 방법인 direct&indirect 기법의 장단점을 소개하고 CNN, RNN을 소개한 후 이 딥러닝 기법이 첨가된 sementic VSLAM을 소개한다.
Introduction
SLAM은 로봇으로 하여금 낯선 환경에서 localization과 mapping을 동시에 할 수 있도록 하기에로보틱스에서 필수적인 기술이다. 1986년 제안되어 빠르게 발전해왔다. 초기에는 로봇의 localization과 네비게이션에 쓰이다가 기술이 발전됨에 따라 점점 자율주행의 핵심기술로 자리잡았다.
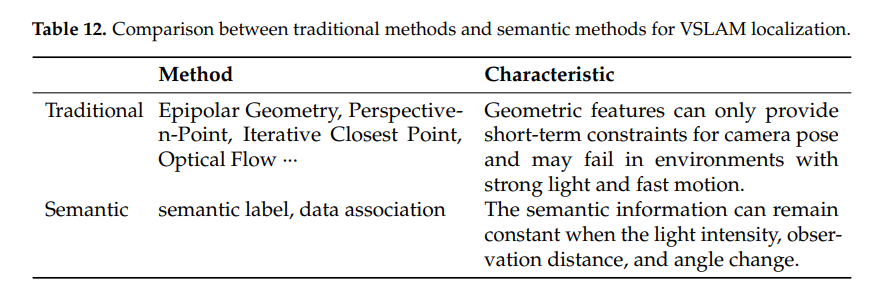
전통적인 VSLAM은 점,선 등의 환경의 기하학적 특징들만 사용하여 빛, 텍스트, 동적물체가 등장하면 포지션 예측과 강인함이 떨어지는 것이 약점이었다. 전통적인 SLAM에서 이용하는 정보들이 자율주행이나 장애물회피를 하기에는 불충분하다. 또한 기존 VSLAM 기술만으로는 복잡한 판단이 불가능하다.
이러한 기존 VSLAM에 sementic 기술이 융합되면 유의미한 정보들을 픽셀단위에서 객체단위로 확장가능하고 맵 생성과 장면의 인지도 고도화 시킬 수 있다.
2016년에 Cadena et al.은 SLAM의 발전을 Classic, Algorithm, Robust 3-stages로 나눴다. Yousif et al.은 VSLAM의 프레임워크를 소개하고 여러가지 수학적 문제들을 정리하였다. 그 외에도 다수의 논문들이 SLAM에 대한 분석과 고찰, 예상되는 문제점들을 기술하였다.
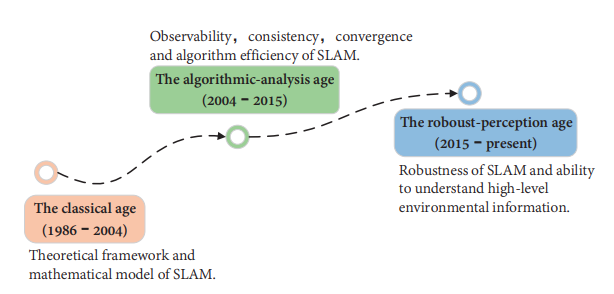
이러한 분석들은 모두 전통적인 VSLAM 알고리즘을 기반으로 진행되었다. 본 논문은 알고리즘 관점에서 보다 더 폭넓은 요약을 제공한다.
- 섹션1에서는 전통적인 VSLAM의 특징을 자세히 다루는데 direct, indirect 기법을 소개하고 depth-camera 기반 VSLAM과 IMU기반 VSLAM을 비교한다.
- 섹션2에서는 CNN & RNN과 결합된 VSLAM을 소개한다.결합 측면은 세가지로 나뉜다. localization, mapping, elimination of dynamic objects.
- 섹선3에서는 SLAM dataset의 메인스트림과 주요연구실을 소개한다.
- 섹션4에서는 앞으로의 VSLAM분야의 연구방향을 예측한다.
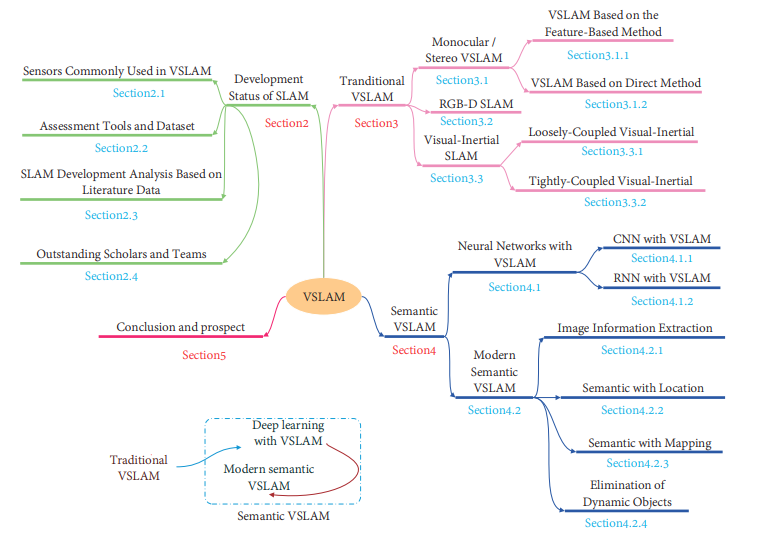
2. Development Status of SLAM
2.1 Sensor Commonly Used in VSLAM
VSLAM에 쓰이는 센서로는 monocular camera, stereo camera, RGB-D camera 등이 있다. RGB-D camera는 밝기변화를 이용하여 depth를 얻어낼 수 있지만 밝기에 민감하여 대부분 실내한정으로 사용된다. event camera는 픽셀들의 밝기변화를 보여주는 카메라로 event camera를 이용한 SLAM은 아직 연구중이다.
2.2 Assessment Tools and Dataset
SLAM을 평가하는 가장중요한 지표가 두가지가 있다. ATE(Absolute Trajectory Error)와 RPE(Relative Pose Error) 이다. ATE는 gt값과 estimated trajectory 값의 차이를 계산한 것이고 RPE는 두개의 동일한 timestamp에서 pose 차이를 나타낸 것이다. stereo와 RGB-D 카메라는 gt와 estimated trajectory가 스케일이 동일하기 때문에 least square method를 적용하면 되지만 Mono의 경우 scale uncertainties가 있어 변환행렬계산(Sim(3))이 필요하다. EVO라는 툴을 통해 ATE RPE 등을 계산할 수 있다. 평가 dataset은 KITTI, TUM 등이 있다.
2.3 SLAM Development Analysis Based on Literature Data
sementic SLAM의 관심도가 최근들어 급격히 증가되고있다는 지표들 소개.
2.4 Outstanding Scholars and Teams
많은 사람들이 SLAM을 연구하고 있다.
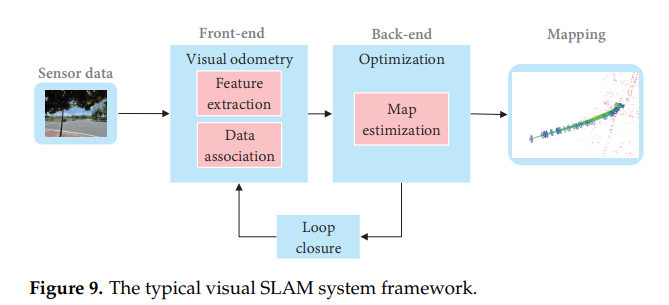
3. Traditional VSLAM
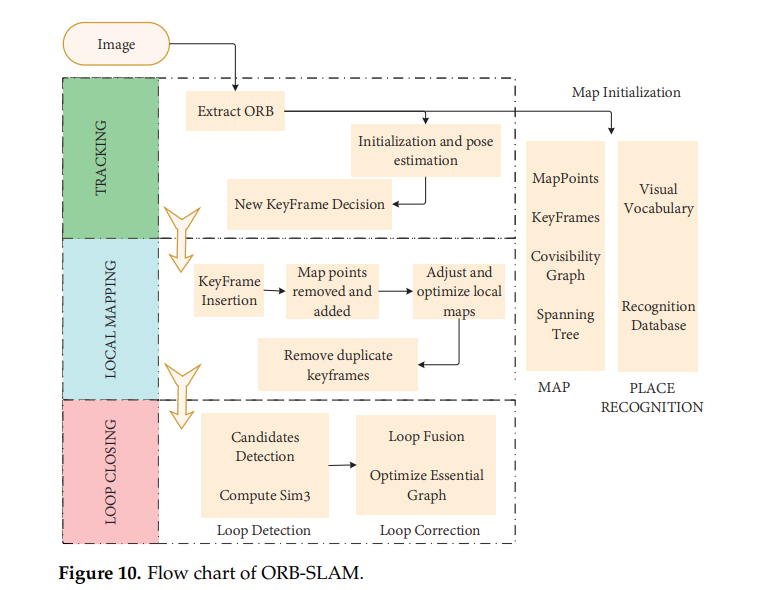
Cadena et al.이 설명한 classical VSLAM 프레임워크는 front-end & back-end로 이루어져있다.
- front-end: 실시간 pose추정.
- back-end: map 업데이트, 최적화.
또한 현재의 VSLAM은 sensor data collection, loop closing detection, map construction 모듈들을 포함한다.
3.1. Monocular/Stereo VSLAM
이 절에서는 Monocular/Stereo VSLAM의 알고리즘들을 자세히 리뷰한다. 이미지에서 정보를 얻어와 pose변화를 측정하는 visual odometry는 SLAM에서 필수적인 프로세스다. 이미지에서 정보를 얻어오는 방식은 direct와 indirect로 구분된다.
- indirect: 이미지에서 특징점(key-points)를 뽑아 다음 오는 프레임의 특징점들과 비교하는 방법. 계산량이 적다.
- direct: 이미지의 전체 정보를 저장하여 픽셀들의 밝기변화로 계산하는 법. 이미지에서의 전처리가 없고 feature 기반보다 robust하다.
3.1.1 VSLAM Based on the Feature-Based Method
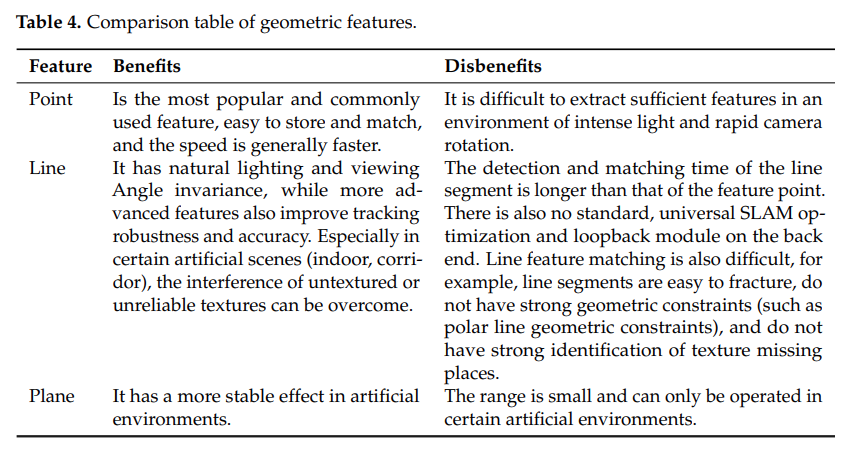
feature 기반 방식의 중점은 이미지에서 특징이 될만한 기하학적 요소(점, 선, 면)들을 추출해내고 추출된 정보들로 pose estimation을 진행 후 환경을 재구성하는 것이다. 초기에는 Harris, FAST, GFTT 등의 코너검출방법을 사용하여 특징점 추출을 하였지만 다양한 시나리오에서 높은 신뢰성을 제공하지 못해 더 좋은 특징점 추출을 위한 연구가 활발하다. 요즘 사용되는 특징점 추출방법은 SIFT, SURF, ORB등이 있다.
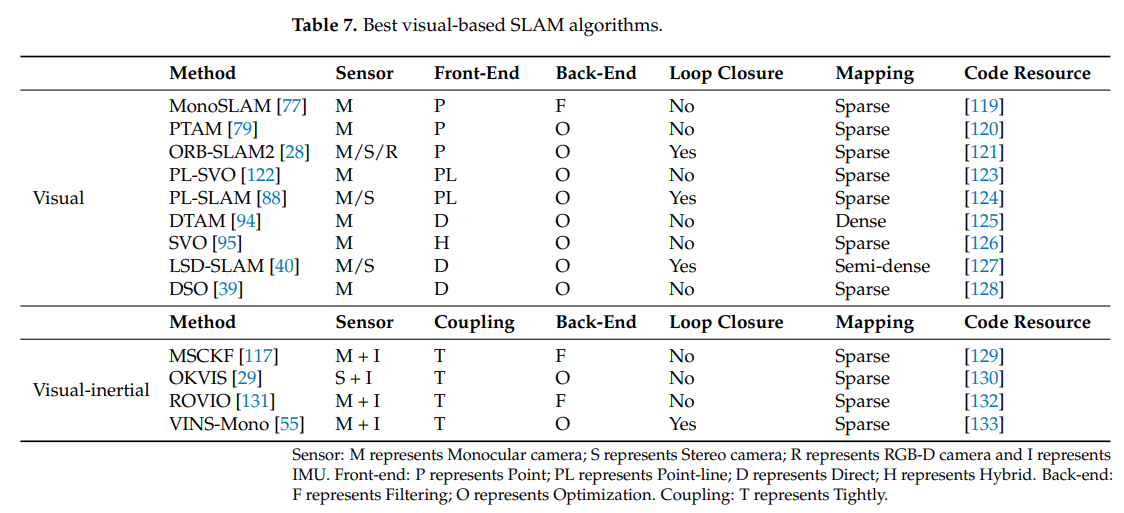
2007년에 Davidson et al. 에 의해 제안된 MonoSLAM 알고리즘은 front-end에 shi-Tomasi corner point를 사용하여 트래킹을 하고 back-end에 Extended Kalman Filter를 사용하여 최초로 드리프트 없이 실시간으로 동작하는 monoslam 알고리즘을 보였다. 그러나 EKF 방식은 storage와 state quantity 사이의 증가로 이어져 큰 규모의 시나리오에는 적합하지 않았다. 이를 해결한 것이 PTAM이다. PTAM은 backend에 비선형 최적화를 이용한 최초의 SLAM이다. 또한 PTAM은 tracking과 mapping을 두개의 쓰레드로 나눈 최초의 SLAM이기도 하다. 특징점 추출에는 FAST 코너검출을 사용하였다. 허나 아직 루프감지모듈이 없는 상태여서 장시간 동작시 오차가 발생하였다.
2015년에 ORB_SLAM이 발표되었다. PTAM에 루프감지모듈을 (별도의 쓰레드로) 추가하였고 루프감지시 DBoW를 사용하여 빠르게 루프를감지할 수 있다. 하지만 환경적인 특징점에 지나치게 의존하는 경향이 있어 texture feature가 없는 환경에서는 충분한 features를 추출해내지 못한다. robust하지않음. 이를 해결하기 위해 Line feature를 추출하는 기능을 탑재한 LineSLAM이 제안되었으나 이 기능에 루프감지기능이 없고 line segment 길이가 무한하여 사용되지 않음.
이 후 점과 선을 모두 추출하는 PL-SLAM이 제안되었고 빛변화에도 강인하며 좋은 성능을 보였으나 실시간성이 좋지 않았다. 이 후 점, 선, 면까지 골고루 추출하는 SLAM이 제안되었고 점들은 pose estimation에, 선과 면들은 환경구성에 쓰였지만 대부분의 면들은 인공적인 환경에서만 발견되고 자연환경에서는 적합한 면이 거의 발견되지 않아 적용범위가 제한적이었다.

3.1.2. VSLAM Based on Direct Method
feature-based와는 달리 direct에서는 pixel intensity를 사용하고 이미지의 모든 정보를 저장한다. 또한 feature를 추출하고 비교하는 과정이 생략되어 indirect 기법에 비해 계산량이 적은 강점이 있다. 또한 robust하다.

최초의 Direct SLAM은 DTAM으로 입력 이미지를 재구성된 맵들과 비교하며 트래킹하는 방식 -> 성능도 괜찮고 맵도 디테일하게 잘 만들었으나 연산량이 어마어마하여 CPU로 안돌아감.
LSD_SLAM은 연산량을 줄이고 CPU 상에서 실시간성을 확보하기 위해 textureless area를 무시하였다. 알고리즘은 tracking, depth estimation, map optimization으로 구성되고 첫번째는 photometric error를 최소화하면서 pose estimation을 한다. 둘째로 깊이를 추정할 key frame을 선정한다. 셋째로 새로운 key frame을 맵에 합치고 최적화를 진행한다.
2014년에는 SVO라는 semi-direct SLAM이 제안되었다. SVO 알고리즘은 두 파트로 구성되는데 feature point 매칭으로부터 오는 motion estimation과 direct method로부터 오는 mapping으로 나뉜다. SVO는 좋은 결과를 보였지만 시각적인 방법만을 사용하여 짧은 data association에서만 성능을 보였다.
2018년 이미지의 아무 픽셀들이나 사용가능하며 robust하고 SVO보다 성능이 뛰어난 DSO가 등장한다. DSO는 photometric 정보와 geometric 정보를 모두 사용하여 높은 정확도를 보인다. 하지만 DSO는 local geometric consistency만 고려하여 누적되는 애러가 존재한다. 또한 루프감지와 맵재사용이 없어 완전한 SLAM이라고 할 수 없다.

3.2. RGB-D SLAM
RGB-D 카메라는 이미지로부터 RGB정보와 depth정보를 추출한다. 공간의 3차원 정보를 쉽게 추출가능하므로 3차원 맵 재구성쪽으로 많이 발전해왔다.
- KinectFusion: RGB-D 카메라를 이용한 최초의 3차원 맵재구성 시스템. ICP(Iterate Closest Point)를 이용해 깊이로부터 생성되는 포인트클라우드로 pose estimation을 하고 TSDF(Truncated signed distance Function)으로 맵재구성을 한다. GPU에서 동작하며 loop-closer에서의 최적화는 없다. 또한 카메라로부터 생성되는 RGB정보를 온전히 사용하지 못했다.
- ElasticFusion: RGB 정보와 depth정보를 모두 사용하여 카메라 pose estimation의 정확도를 높였지만 작은 실내공간에서만 적용됨.
- Kinitinuous: KinectFusion에 loop-closure 모듈을 탑재.
- RGB-D_SLAMv2: feature detection과 최적화, 루프감지 등을 모두 포함한 SLAM.
RGB-D 카메라는 빛에 민감하고 좁고 노이지한 환경에서 문제가 많아 실내환경에서만 적용가능하다. 또한 현존하는 알고리즘들이 GPU를 필수로 요구하기에 SLAM의 주력 센서로 자리잡지는 못했지만 실내 3차원 맵 재구성 분야에서는 널리 쓰이고 있다.

3.3. Visual-Inertial SLAM
SLAM은 빠른 카메라 이동과 좋지않은 조명에서 항상 어려움을 겪어왔다. 이를 해결하기 위해 여러가지 센서들과 퓨전이 시도되어왔고 그중 IMU는 높은 주파수와 동적물체의 영향을 줄일 수 있다는 점에서 아주 좋은 피융합센서로 자리매김하고 있다.
visual-inertial fusion은 이미지의 feature정보가 state vector에 추가되는지 여부에 따라 loosely coupled와 tightly coupled로 나뉜다.
3.3.1. Loosely Coupled Visual-Inertial
시각센서와 관성센서로부터 얻어지는 포지션정보와 위치정보를 EKF를 통해 융합한다. 이 융합과정이 두 센서로부터 얻어지는 정보결과에 영향을 미치지 않는다. 구현이 상대적으로 쉽지만 애러가 존재하여 많은 연구가 이뤄지지않았다.
3.3.2. Tightly Coupled Visual-Inertial
최적화된 필터를 통해 시각센서와 관성센서의 상태를 합친다. motion 방정식과 pose 방정식을 구하기 위해 이미지의 features가 feature vector에 추가되어야한다. 구현이 어렵지만 좋은 성능을 보여 연구가 많이 이뤄졌다.
- MSCKF: IMU와 camera를 EKF로 융합했다. robustness와 높은 속도, 정확도를 보였지만 back-end에서 칼만필터를 사용하여 global information이 최적화에 쓰이지 않았고 루프감지를 못한다.
- OKVIS: binocular+IMU. 루프감지와 맵생성이 없어 엄밀히 말하면 SLAM이라고 할 수 없다.
- VINS-Mono: Mono+IMU, Stereo+IMU, Stereo only, with GPS를 제공한다. 루프감지가 존재하며 높은 정확도와 속도를 자랑한다. 실내외에 모두 적용되며 조명변화에도 강인하다. visual information+IMU의 교과서적인 융합을 제시한 SLAM이다.
센서를 융합하며 추출되는 데이터량이 많아짐에따라 많은양의 데이터를 효율적으로 처리하는 것이 다음 과제로 제시되고 있다.
4.Semantic VSLAM
semantic VSLAM은 단순히 기하학적 정보만 얻어내는 것이 아닌 객체검출과 장면의 이해까지 하는 것을 의미한다. 딥러닝이 발전하면서 연구자들은 딥러닝이 SLAM으로 하여금 맵에대한 이해와 feature point 의존성을 개선하고 robustness를 향상시킬 수 있을 것이라 예측하였다.
딥러닝 기반 SLAM 소개와 기존 SLAM에 존재하는 문제들 정리한 논문.
- Li, R.; Wang, S.; Gu, D. DeepSLAM: A Robust Monocular SLAM System With Unsupervised Deep Learning. IEEE Trans. Ind. Electron. 2021, 68, 3577–3587.
기존 SLAM 내 모듈중 일부는 딥러닝으로 대체되어야한다는 논문.
- Garg, R.; Bg, V.K.; Carneiro, G.; Reid, I. Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 740–756.
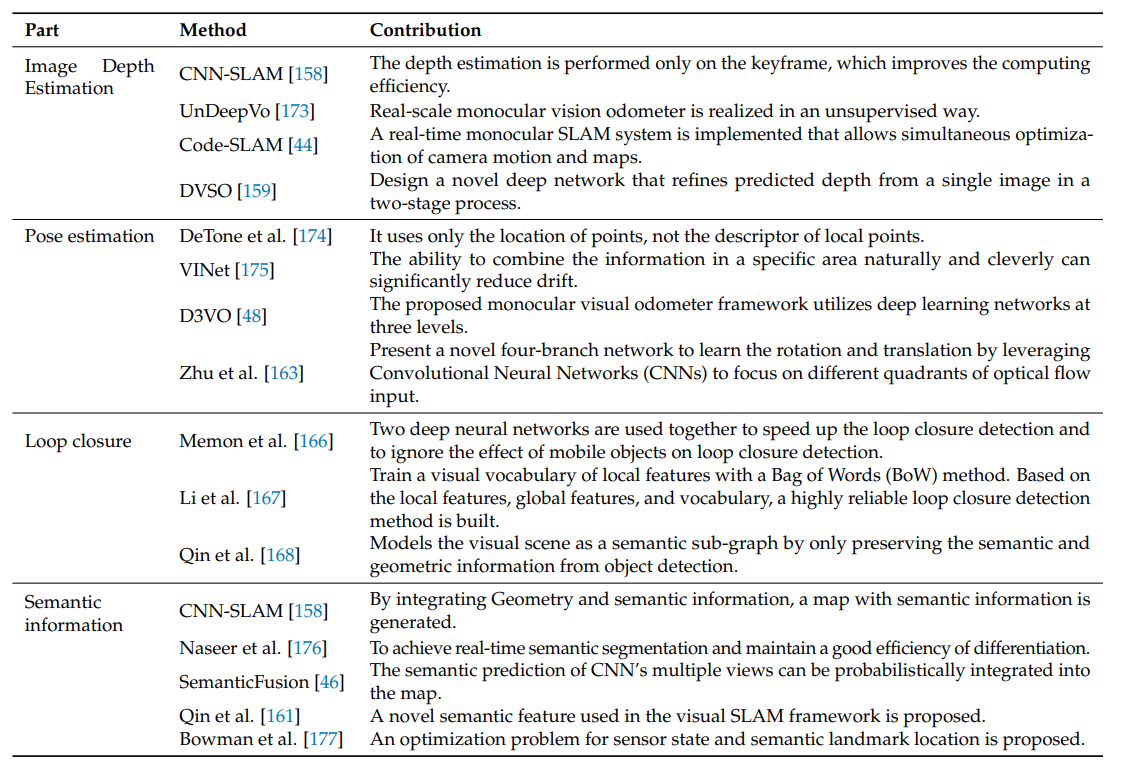
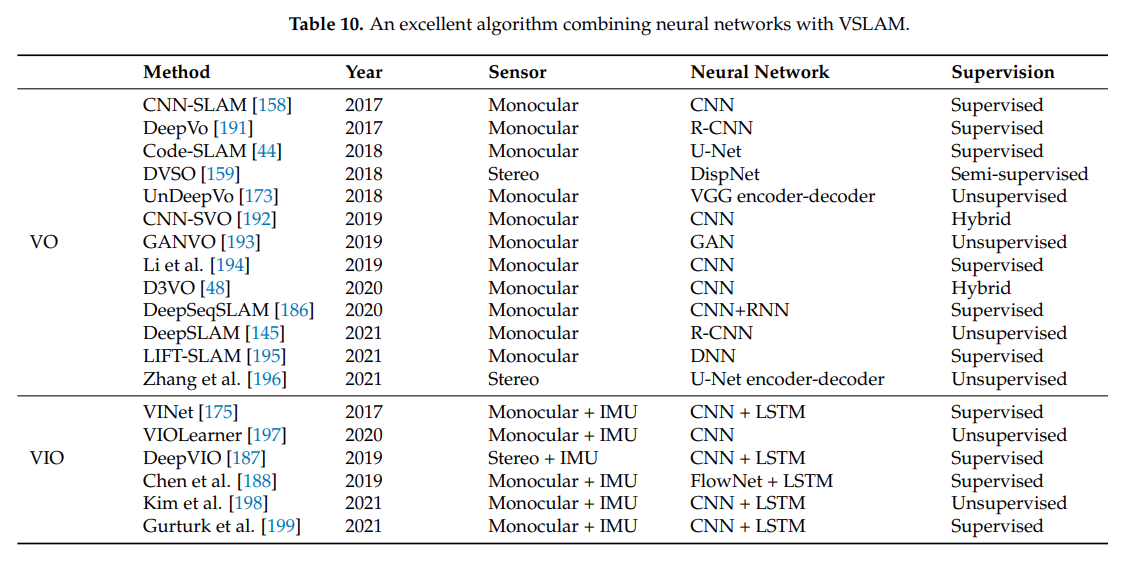
4.1. Neural Networks With VSLAM
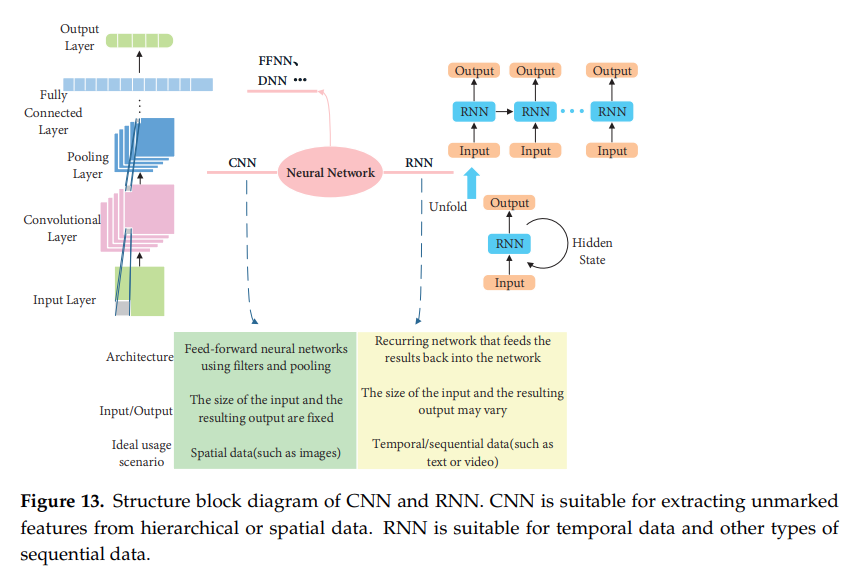
CNN은 이미지의 패턴을 찾아 특징을 뽑아내고 RNN은 네트워크 내 자체 기억능력이 있어 문맥상 흐름을 파악할 수 있다. CNN은 SLAM에서 feature extraction과 matching 부분에 적용이 가능하며 RNN은 프레임들간 관계와 경향을 파악하는데 기여할 수 있다.
4.1.1. CNN with VSLAM
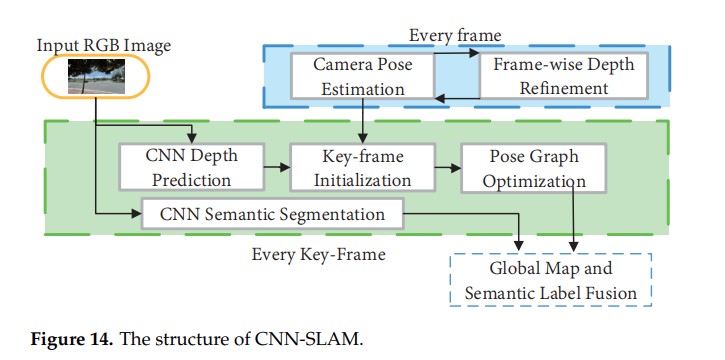
- CNN-SLAM: LSD-SLAM의 Depth estimation 부분에서 CNN을 사용하였다. 또한 더 좋은 시각정보를 얻기위해 CNN ssg가 모듈에 탑재되었다.
- D3VO: depth estimation, pose estimation, uncertainty estimation 세가지에 딥러닝을 적용하여 front-end에서의 트래킹 성능과 back-end에서 비선형최적화 성능을 높였다. 하지만 적용 환경이 제한적이다.
- Qin et al.: semantic feature를 이용한 localization 방법을 제안. 트래킹 로스가 발생하던 기존SLAM의 문제를 해결. 구체적인 알고리즘은 좁거나 붐비는 특정 환경에서 semantic feature를 추출하고 U-net을 통해 ssg를 진행하여 주차선, 속도범퍼 등을 분류한 후 odometer 정보를 이용한다.
- Memon et al.: 딕셔너리 기반 딥러닝 기법을 제시. vocabulary를 생성하지 않는 방법. 메모리 효율이 좋고 빠르게 동작하지만 검출주기의 유사성 점수에만 초점을 맞춰 널리 상용화되지는 않았다.
- Li et al.: 각 프레임마다 CNN을 사용하여 local feature와 global feature를 모두 추출. BoW based 방법보다 높은 효율과 적은 연산량을 보임.
- Qin et al: semantic 정보를 추출하는데 CNN을 사용. 추출한 정보로 loop-back 효율을 증진시킴.
더 복잡하고 좋은 모델들의 등장으로 실시간성을 확보하기위한 연산 효율성 증진과 모델 경량화가 다음 과제이다.
4.1.2. RNN with VSLAM

4.2. Modern Semantic VSLAM
semantic 기술은 SLAM과 자율주행에 있어 아주 큰 발전을 가져올 수 있는 기술이다. 이 절에서는 semantic VSLAM을 localization & mapping 과 dynamic object removal, 두가지 관점에서 바라볼 것이다.
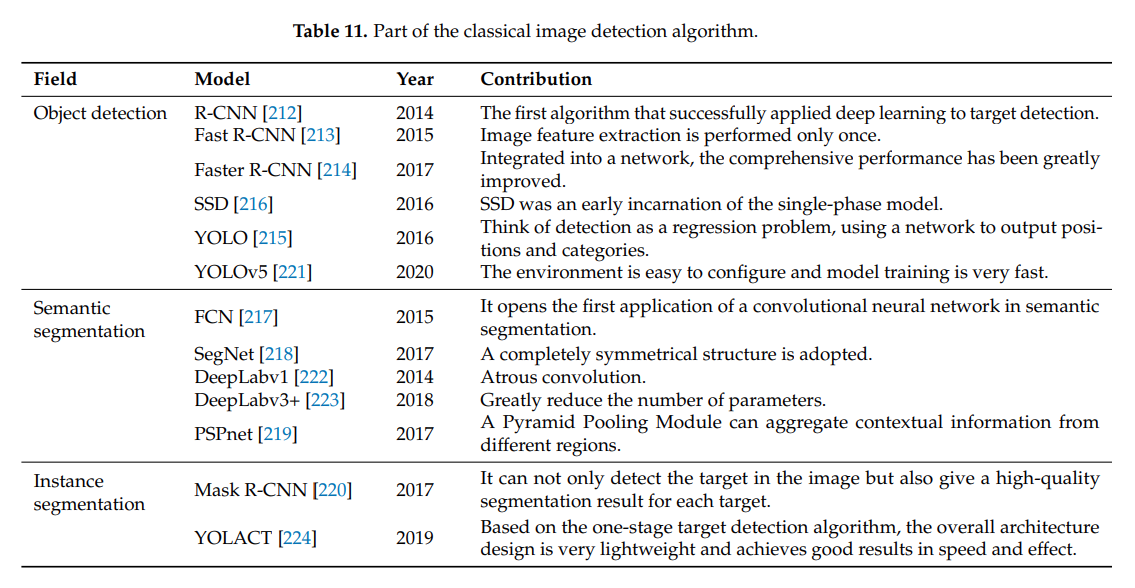
4.2.1. Image Information Extraction
이 절에서는 이미지정보를 추출하는 기술의 변천사를 설명하고 있다.
4.2.2. semantic with Location
-
Bowman et al.: sensor state estimation and semantic landmark location optimization 제안. 목표검출로부터 semantic 정보를 추출하고 EM(Expectation-Maximization)을 진행 후 semantic 분류에 따른 데이터 연관확률을 계산한다. localization의 성능을 증진시켰지만 사영되는 3차원 객체의 중심이 detection network의 중심에 가까워야한다는 한계점이 있었다.
-
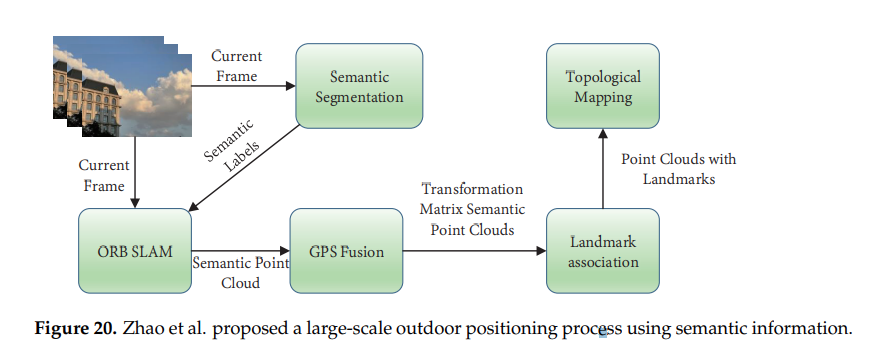
Zhao et al.(2020): 큰 규모의 실외 환경을 위한 semantic SLAM을 제안. ORB_SLAM의 포인트클라우드와 ssg 정보를 컨볼루젼 신경망에에서 합친다. 인공적인 랜드마크와 emantic 포인트클라우드를 연관짓고 구글맵으로부터 얻어진 랜드마크와 semantic 3D map을 연관짓는다. semantic point cloud의 도움으로 규모가 큰 실외 환경에서도 랜드마크를 찾아 GPS 없이 relocalization을 수행할 수 있다.
-
VSO: semantic information이 각도변화, 스케일변화, 조명변화의 영향을 받지 않는다는것을 이용하여 기존 SLAM이 실외환경에서 조명변화에 취약했던 문제를 해결하였다.
4.2.3. Semantic with Mapping
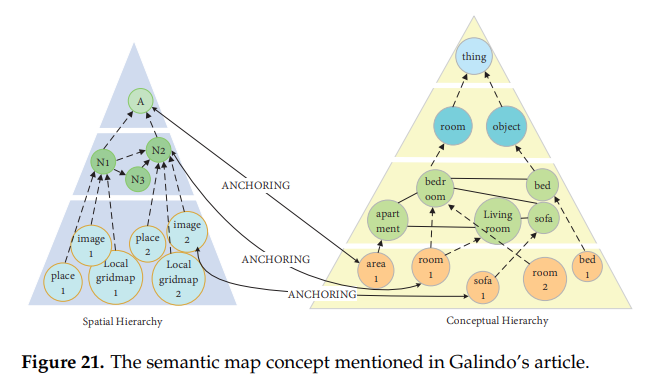
2005년 Galindo et al.은 로봇이 인지하고 추론할 수 있는 semantic map을 제안하였다.
- Kimera: 2020년 MIT에서 제안한 SLAM 알고리즘으로 YOLO를 통해 객체검출을 한 후 canny operation을 수행하여 윤곽선을 따서 semantic 표현을 한다. 기존 ssg 알고리즘에 비해 연산량이 현저히 적어 실시간으로 동작 가능하다.
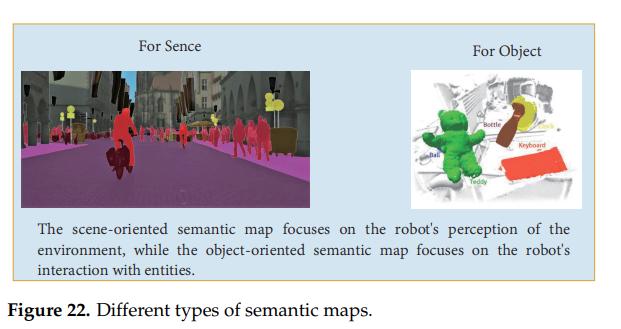
하지만 Kimera의 방식은 로봇과 환경의 소통과 로봇의 지능을 제한한다. 이를 해결하기 위해 Object Oriented semantic map이 제안되었다. 이는 맵에서 필요한 부분의 semantic 정보만 추출해내는 방법이다. 이 후 mask-RCNN과 KinectFusion을 베이스로 한 voxel 기반 semantic VSLAM이 제안되었고 이것도 실시간성을 확보하기에는 역부족이었다.
이 후 ORB2와 YOLOv3를 이용해 경량화된 Object Oriented semantic SLAM이 나왔다.(DSP-SLAM) Semantic map construction은 Instance sg와 Semantic sg를 모두 다뤄야한다. 때문에 실시간성이 안좋을 수 밖에 없다. 그리고 많은 알고리즘들이 동적 물체를 없애면서 robustness를 확보하였다. 동적물체를 없애는 것은 SLAM 시스템에서 유용한 정보의 손실로 이어졌다. 따라서 동적환경에서의 SLAM이 다음 과제로 제기되었다.
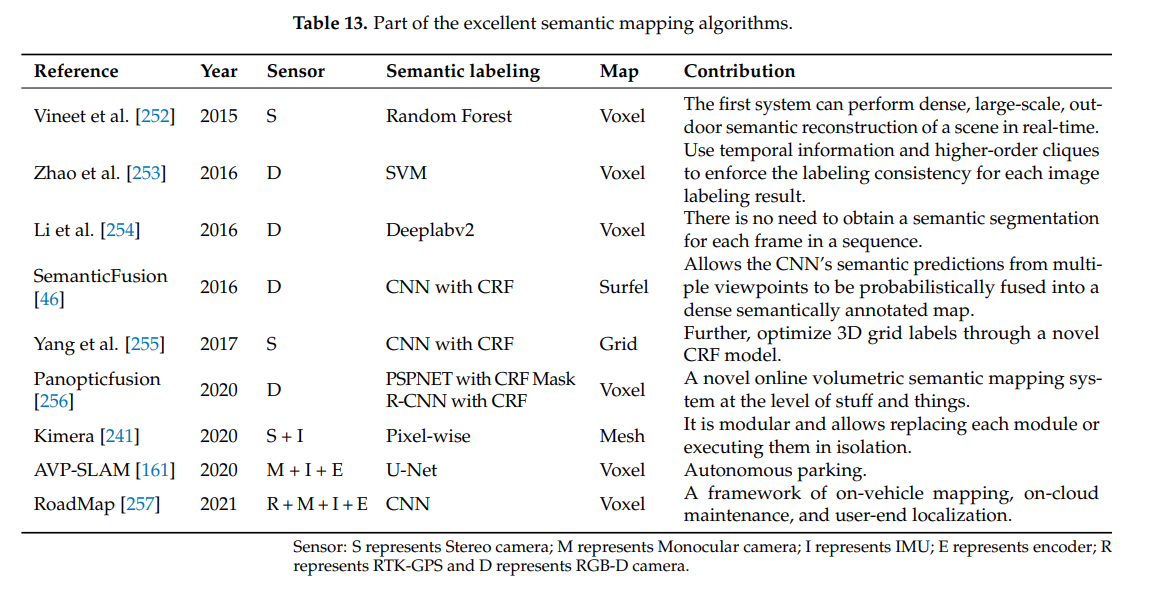
4.2.4 Elimination of Dynamic Object
동적물체는 SLAM의 정확도와 강인함에 영향을 미친다. 전통적인 SLAM은 RANSAC 알고리즘을 이용해 동적물체의 영향을 줄여왔다. 하지만 동적물체가 대부분인 상황과 움직이는 물체의 속도가 아주 빠르면 신뢰성 높은 정보들을 얻기 힘들다.
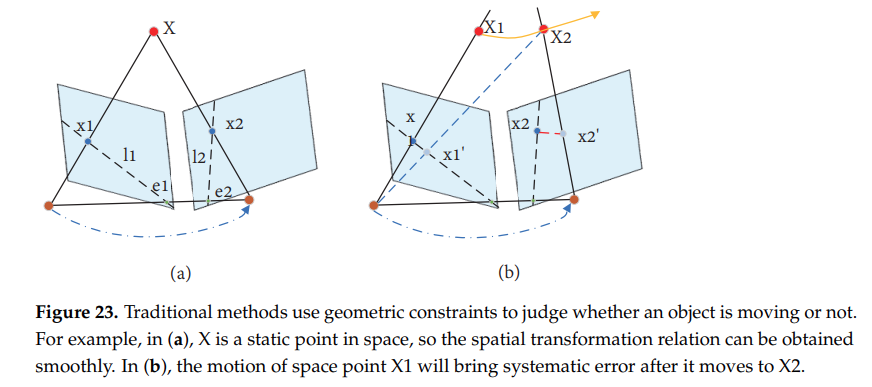
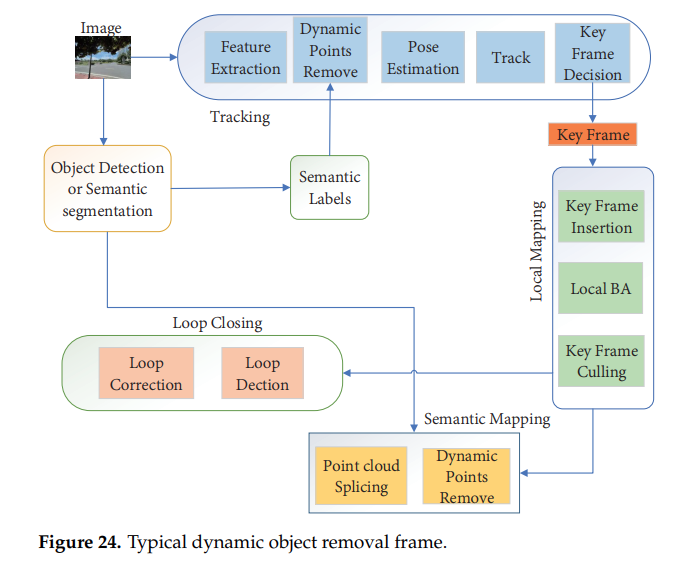
- DynaSLAM: ORB2를 기반으로 만들어졌고 front-end단에서 mask-RCNN을 사용하여 동적물체의 ssg를 잡아 동적물체 feature 추출을 피했다. 하지만 주차장에 정지해 있는 자동차도 동적물체로 구분해 유용한 정보의 손실이 발생하였다.
- DS-SLAM: ORB2 기반으로 만들어졌고 실시간 thread로 ssg를 돌린다.
어떤 논문은 모션벡터를 이용해 ssg 물체중에서도 정지해있는 물체들을 구분하는 알고리즘을 구현하였다. 또한 RGB-D 카메라로부터 얻은 depth정보와 mask-RCNN으로부터 얻은 semantic 정보를 이용하여 움직이는 feature들을 없애므로써 좋은 성능을 보인 논문도 있다.
semantic 정보들은 SLAM이 동적물체를 관리하는데 큰 도움을 주었지만 실제 로봇에 상용화 되기에는 실시간성 확보가 충분히 되지 못했다. 현재 optical flow를 통한 동적물체 감지등을 통해 여러 해결책들이 제안되고 있다.
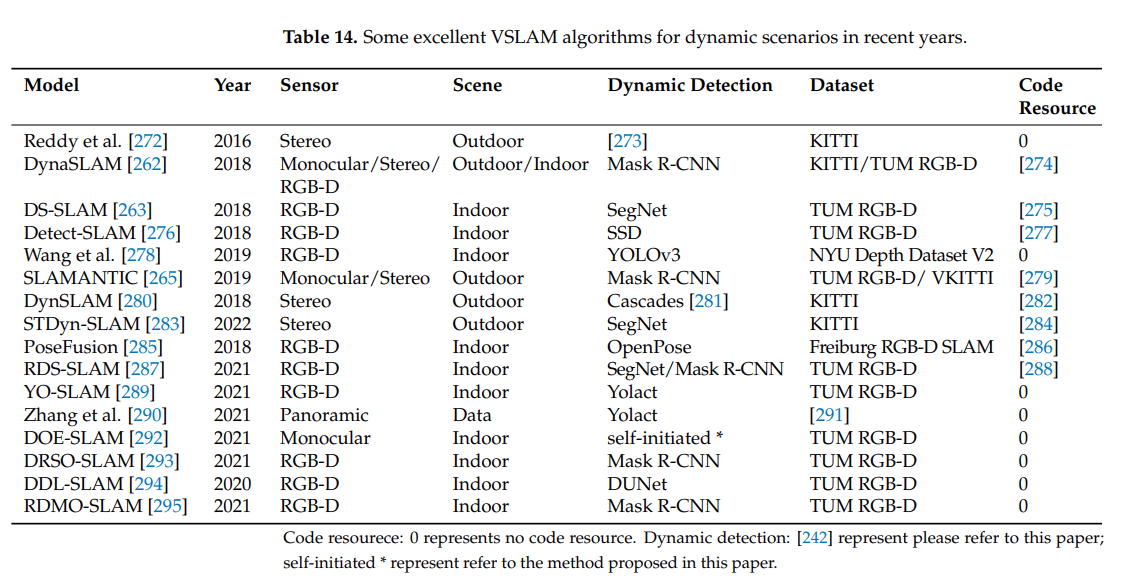
5. Conclusion
VSLAM에 딥러닝을 적용하고 Semantic 기술을 적용하는 연구가 활발히 이루어지고 있다.
앞으로의 SLAM연구의 방향성을 다음과 같이 정리하였다.
- 휴대폰이나 드론에 탑재될 만큼의 경량화. 빠른 동적물체와 다양한 조명환경에서의 강인함 증진.
- SLAM의 부분적 모듈을 딥러닝으로 대체하는 것이 아닌 SLAM의 전체적인 이론적 구조에 딥러닝 적용.
- 높은 수준의 인지와 사람간 상호작용 구현.(복잡한 명령어를 수행할 수 있을 정도)
- Semantic SLAM을 평가할 수 있는 다양한 지표생성.
