다음 내용은 아주대학교 김상훈 교수님 운영체제 강의 및 강의 자료와 Operating Systems: Three Easy Pieces(https://pages.cs.wisc.edu/~remzi/OSTEP/)을 참고하여 작성한 글입니다.
Paging
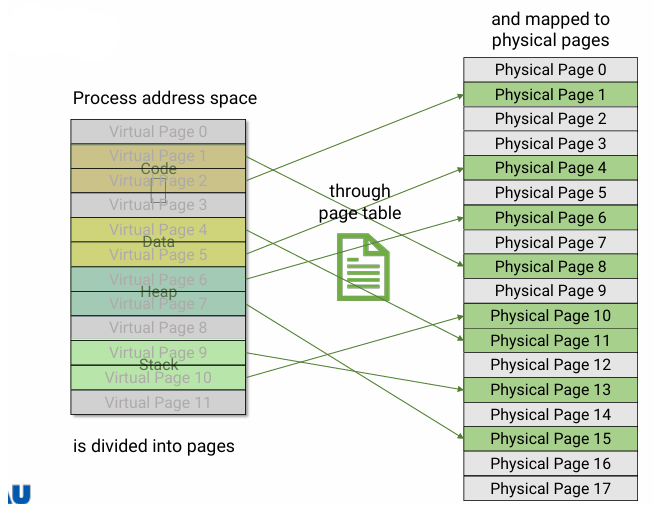
- Divide physical memory into fixed-sized blocks called "page frames" or "frames"
- PPN: Physical Page Number
- Divide logical address space into the same sized blocks called "pages"
- LPN: Logical Page Number or VPN: Virtual Page Number
- LPN: Logical Page Number or VPN: Virtual Page Number
- To run a program of size n, find n free frames and load the program
- Allow the physical address space of process to be noncontiguous
- Still, some internal fragmentation exists
- page를 fixed size로 나누어 주기 때문이다.
- 평균적으로 frame(page) size의 절반이 낭비된다고 한다.
- compare with previous concepts
- 1개의 process -> 1개의 partition: fixed partition
- 1개의 process -> 여러 개의 크기가 다른 partition: Segment
- 1개의 process -> 여러 개의 크기가 같은 partition: paging
Page Tables
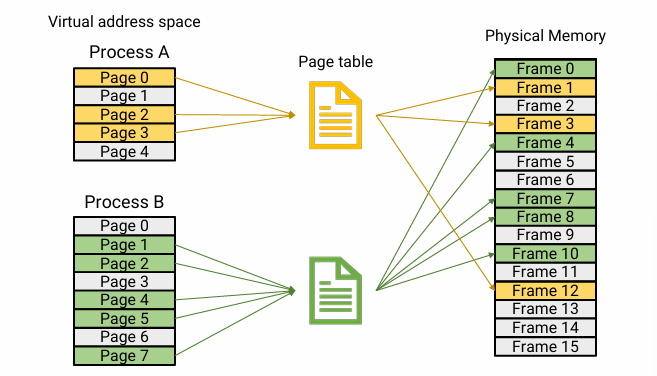
- Each process has its own page table
- Page-table base register (PTBR) points to the base address of the page table
- PTBR은 현재 실행 중인 process의 page table 주소를 가리킨다.
- page table은 memory에 위치해 있다.
- Comprised of page table entries (PTEs)
- Each PTE covers one page in virtual address space
- Managed by OS, accessed by MMU
- mapping 정보를 update 하는 건 OS가 하고, 접근은 HW인 MMU가 한다.
- mapping 정보를 update 하는 건 OS가 하고, 접근은 HW인 MMU가 한다.
Example 1
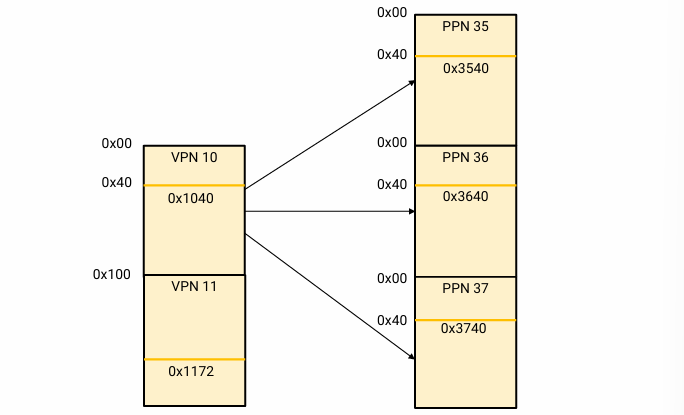
- logical address: 0x1040
- |page| = 0x100
- offset = 0x0040
- VPN 10번 page가 PPN 35번 page와 mapping 됨
위 조건에서 Physical address는 0x3540이다. VPN이 PPN으로 바뀔 뿐, offset 값은 바뀌지 않는 걸 관찰할 수 있다.
Address Translation
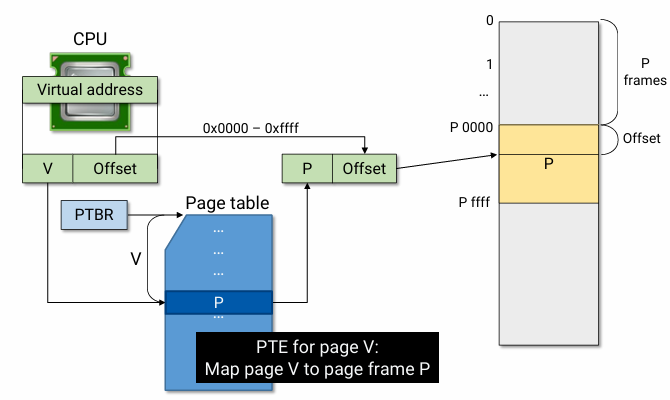
- Page size가 byte일 때, binary address의 하위 n bit는 offset으로 쓰인다.
- page size = =16 bytes일 때, 이 page는 이진수 4 bit로 나타낼 수 있다.
- MMU는 VPN을 index로서 사용해 Page table에 접근하며, mapping 된 PPN 값과 offset 값을 가지고 address translation을 한다.
Example 1
- Virtual address: 32 bits
- Physical address: 20 bits
- Page size: 4KB
- offset bit
위 조건에서, page size는 B이므로 virtual address와 physical address의 하위 12 bit가 offset으로 사용된다. - page table entry 개수
virtual address의 나머지 20 bits는 VPN으로 쓰이며, page table의 총 entry 개수는 개이다. - page table entry 크기
physical address의 나머지 8 bits는 PFN으로 쓰이며, 이 8 bits에는 특정 VPN과 mapping된 PFN이 저장된다. 따라서 page table entry 1개의 크기는 8 bits = 1 byte이다. - page table 크기
page table의 크기는 table entry 개수에 entry 크기를 곱해 주면 된다. 따라서 x byte = B이다.
PTE

- V (Valid bit) says whether the PTE can be used or not
- valid: the page is in use
- invalid: the page is not allocated
- R (Reference bit) says whether the page has been accessed or not
- it is set when a read or write to the page occurs
- M (Modify bit) says whether the page is dirty
- Prot (Protection bit) control which operations are allowed
- PFN (Page Frame Number) determines the physical frame
Linear Page Table
- Page table이 physical address에 flat(= physically contiguous) 하게 있는 걸 linear page table이라고 한다.
- High space overhead for page tables
- 32-bit address space with 4KB pages, 4 bytes/PTE:
- table size: x 4 = 4 MB per process
- 64-bit address space with 8KB pages, 8 bytes/PTE:
- table size: x 8 = 16 PB per process
- 32-bit address space with 4KB pages, 4 bytes/PTE:
- However, process address spaces tend to be sparse
- Only a small portion of address space is used (Code, Data, Stack, Heap)
- most of the address space is not used at all
즉, 기껏 frame 단위로 memory를 나누고 process의 pages를 physically discontiguous 하게 올렸더니 page table은 contiguous 하게 올리는 상황이다. 또 process마다 갖는 page table의 크기가 상당하고, 막상 까보니 낭비되는 공간이 상당히 많다는 게 문제점이다.
- Split the entire page table into smaller page table pieces
- split so that each page table fits in a page
- Only map the the used portion
- Thus, the split page tables can be allocated non-contiguously
따라서 이 page table 자체를 좀 작게 나눠서 사용되는 부분만 mapping 정보를 기록하고, non-contiguous 하게 memory 올려보자는 게 해결 방안이다.
Hierarchical Page Tables
-
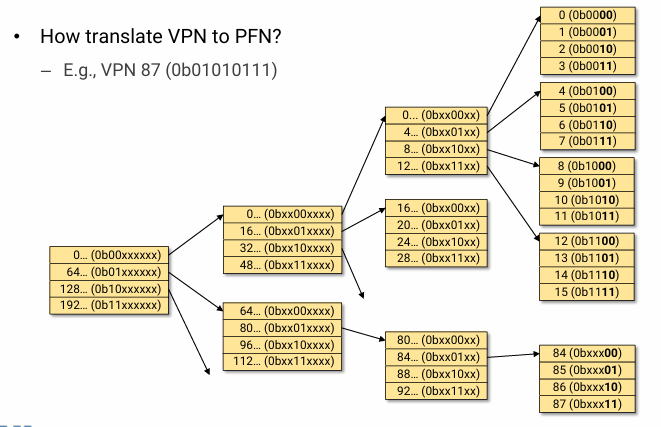
Page table을 여러 page 단위로 쪼개서 sparse 하게 두고, 그 위치를 summary 하는 다른 outer page table page를 두는 방식이 hierarchical page tables이다.
-
VPN to PFN translation을 위해서는, 1 page에 PTE가 개 있다면, 1 level 당 bit를 n 개씩만 봐 주면 된다. (table 당 entry 수가 같으므로 level과 무관하게 n개만 봐 주면 되는 것이다.)

-
아래 사진은 1 level에서 4개의 PTE를 cover 하므로 2bit씩 끊어 보면 된다.
- 0b010111 -> 0b01 / 01 / 01 / 11
- 가장 outer에서 0b01이 가리키는 page table page로 가서 01번째가 가리키는 page table page로 가서 01번째 ... 이렇게 해석하면 된다.
-
Pros
- Compact while supporting sparse-address space
- Easier to manage physical memory
- Each page table usually fits within a page
- 예전에는 frame 하나로는 어림도 없던 table이 이제는 frame 하나로 cover가 가능하다.
- No external fragmentation
-
Cons
- More complex than a simple linear page-table look up
- n level의 hierarchical page table 구조라면, address translation을 위해 MMU가 n번만큼 memory를 다녀와야 한다. 즉 additional memory access가 level 수만큼 발생한다.
- More complex than a simple linear page-table look up
Example 1
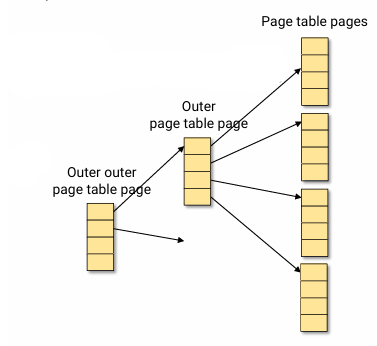
- 4 leaf page table pages + 1 outer page table page
- the address space can be up to 16 pages
- 4 PTE in outer page table page x 4 pages in a leaf page table page
-
Three levels?
4 PTE in outer outer x 4 PTE in outer x 4 pages in a leaf page table page = 64 pages
-
1 table에 4개의 page를 indexing 할 수 있다. 128개의 page를 hierarchical하게 indexing 하려면 몇 level로 만들어야 할까?
= 256 > 128이므로 4 level로 만들어야 한다.
Example 2
- 32-bit address space
- PTE size: 4B
- Page size: B
- 1개의 page에 entry가 몇 개
page 크기를 PTE 개수로 나누면 되므로 / = 개이다. - cover 해야 하는 addr space의 page 수
개 - 몇 level로 cover 가능한지
x = 이므로 2 level
이렇게 생각하면 더 쉽다.
page table을 여러 page로 쪼개서 discontiguous 하게 memory에 놓을 것이다. 여기서는 cover 해야 하는 총 page table entry 개수가 개이다. 그렇다면 이 1개의 page에 entry 몇 개가 들어갈까? page 크기를 entry 크기로 나누면 된다. 따라서 / = 개이다. 1개의 page (table)가 개의 entry를 cover 한다면 2 level에서는 각 entry가 또 개의 entry를 cover 하게 되니 x = 개가 된다. (예를 들어, 3명이 각각 3명의 연락처를 가지고 있다고 할 때, 총 연락처의 수는 3 x 3 = 9개 되는 계산 방식과 같다.) 여기서 cover 하려고 하는 entry 수와 같으니 2 level이면 모든 page를 cover 할 수 있다.
Example 3
- 1 page에 PTE가 8개씩 들어간다면 VPN to PFN translation을 위해 주소를 몇 개씩 잘라 보면 될까?
entry가 8개이므로 , 3bit씩 잘라서 보면 된다.
Example 4
- 53-bit address space
- 8KB pages
- 8B/PTE
- offset bit
8K = 이므로 13bit만 있으면 된다. - page당 cover 가능한 entry 수
8KB / 8B = 개 - need () bits per translation
10 - the system requires ()-level page table
4
Example 5
- 48-bit address space
- 4KB pages
- 한 page당 PTE 개 cover
- offset bit
12bit - cover 해야 하는 PTE 개수
개 - PTE 크기
page 크기를 pte 크기로 나누었을 때 개 cover 가능하므로,
가 된다.
PTE의 크기가 이었다는 걸 알 수 있다.
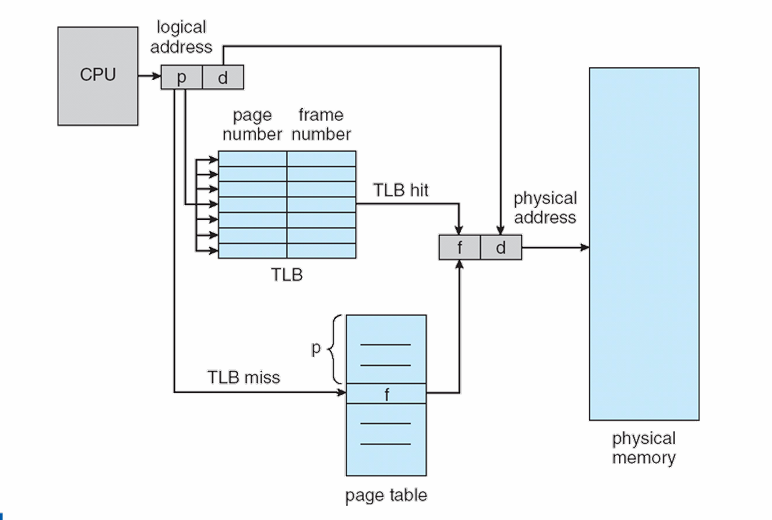
TLB (Translation Lookaside Buffer)
- Address translation time이 additional memory access 때문에 길어지니, 최근에 translation 한 결과를 caching 하기 위해 사용한다.
- TLB is part of the chip's MMU, and is simply a hardware cache of popular virtual-to-physical address translations.
- 'hardware' cache는 software 캐시와는 달리 물리적으로 CPU 내부에 통합되어 있어서 더 빠르고 효율적인 데이터 처리가 가능하다.
-
Exploit the locality of reference by caching recent V to P mapping results
- Temporal Locality
- locations referenced recently tend to be referenced again soon
- Spatial Locality
- Locations near recently referenced locations are likely to be referenced soon
- Temporal Locality
-
address translation을 위해 MMU는 우선적으로 TLB를 확인한다. TLB에서 miss가 나면, MMU는 page table로 가서 translation을 진행하고, translation result를 TLB에 저장한다.
-
On context switch, TLB should be flushed
- Each process has its own VA to PA mapping
- Thus, cannot share TLB entries between processes
- 그래서 address-space Identifiers (ASIDs) 같은 경우는, mapping 결과 옆에 process의 id를 함께 기록함으로써 여러 process의 TLB entries를 coexist 하도록 한다.
