10 Cache
Sharing
- L1, L2 cache: core마다 존재
- L3 cache: shared
Private vs Shared Caches
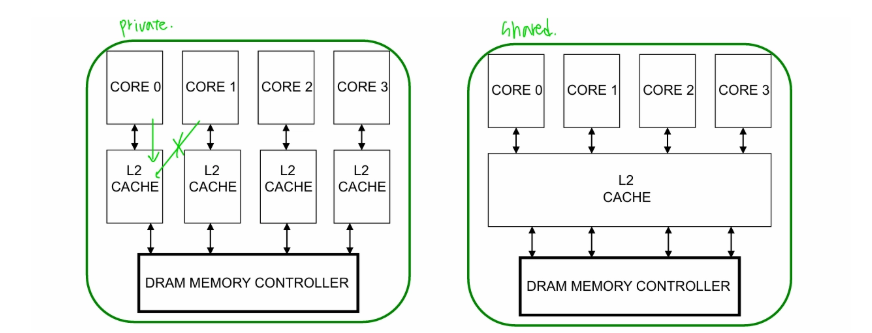
Resource Sharing advantage
- resource utilization/efficiency이 좋아지면서 throughput도 증가함
- 어떤 thread가 resource를 사용하지 않고 있으면 다른 thread가 사용할 수 있음
- communication latency가 줄어듦
- 같이 공유하는 cache에 data가 존재하므로
- thread들이 같은 주소 공간을 공유하는 모델과 자연스럽게 잘 호환됨
Resource Sharing disadvantage
- resource contention을 야기할 수 있음
- 어떤 thread가 이미 점유 중인데 다른 thread도 점유하려고 한다든지
- performance isolation을 제거하기 어려움 →다른 thread의 영향을 내가 받음
- QoS를 contol 하기 어려움
Shared Caches Between Cores advantage
- 캐시 전체 공간을 더 효율적으로 활용할 수 있음
- 정적으로 캐시를 나누지 않기 때문에 fragmentation을 줄일 수 있음
- 캐시 coherence를 유지하기 쉬움 (하나의 캐시 블록이 한 곳에만 존재하므로)
Shared Caches Between Cores disadvantage
- 캐시가 코어와 tightly coupled 되어 있지 않아 private cache에 비해 접근 속도가 느림
- 코어 간 간섭으로 인해 conflict miss 발생 (한 코어의 접근이 다른 코어의 캐시 라인을 밀어낼 수 있음)
- fairness 보장이 어려움
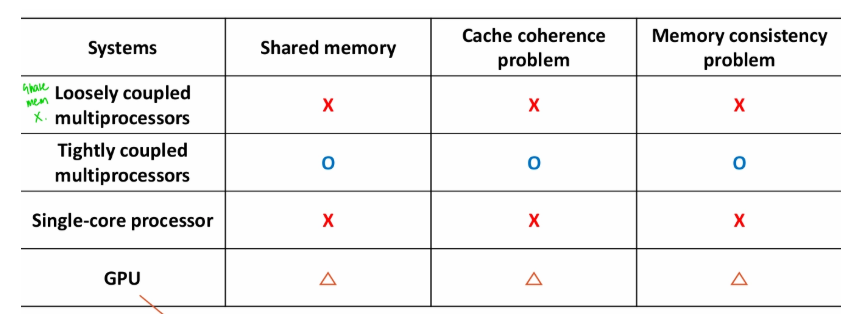
Cache Coherence vs Memory Consistency
cache coherence
- 여러 개의 cache들이 하나의 mem loc을 봤을 때 똑같은 값임을 보장
Memory consistency
- memory operation의 순서를 보장
Associative Cache
- Direct mapped: 반드시 modular 연산 값 그 자리에 write
- Set associative: modular 연산 값이 set # 임. set 안에 어디든 가능
- Fully associative: 어디든 가능
Write-Through
- 캐시에 있는 값을 update 할 때 메모리에 있는 값도 같이 update
- 메모리에 다 업데이트 될 때까지 기다리기 싫어서 write buffer을 사용하기도 함
Write-Back
- 캐시에서 evict 될 때 update 된 값을 메모리에 반영
Write Allocation
- 쓰고 싶은 게 캐시에 없다면 그 값을 메모리에서 찾아서 캐시에 올리고 수정 (write-back이 주로 사용)
Write around
- 캐시에 없으면, 메모리 가서 수정 (배열 초기화 같은 경우 당장 배열 전체를 캐시에 올릴 필요 없으니까)
MISS
- compulsory miss → first access miss to a block
- capacity miss → 유한한 캐시 사이즈로 인해 발생하는 미스
- conflict miss → non-fully associative cache에서 set 안에 유한한 entry 개수로 인해 발생하는 miss


Pitfalls
- shared L2/L3 캐시에 코어 수보다 associativity가 적으면 conflict miss가 발생하기 쉬움
- core가 많고, 캐시 접근이 많아질수록 associativity가 많아져야 함.
Coherence Protocol
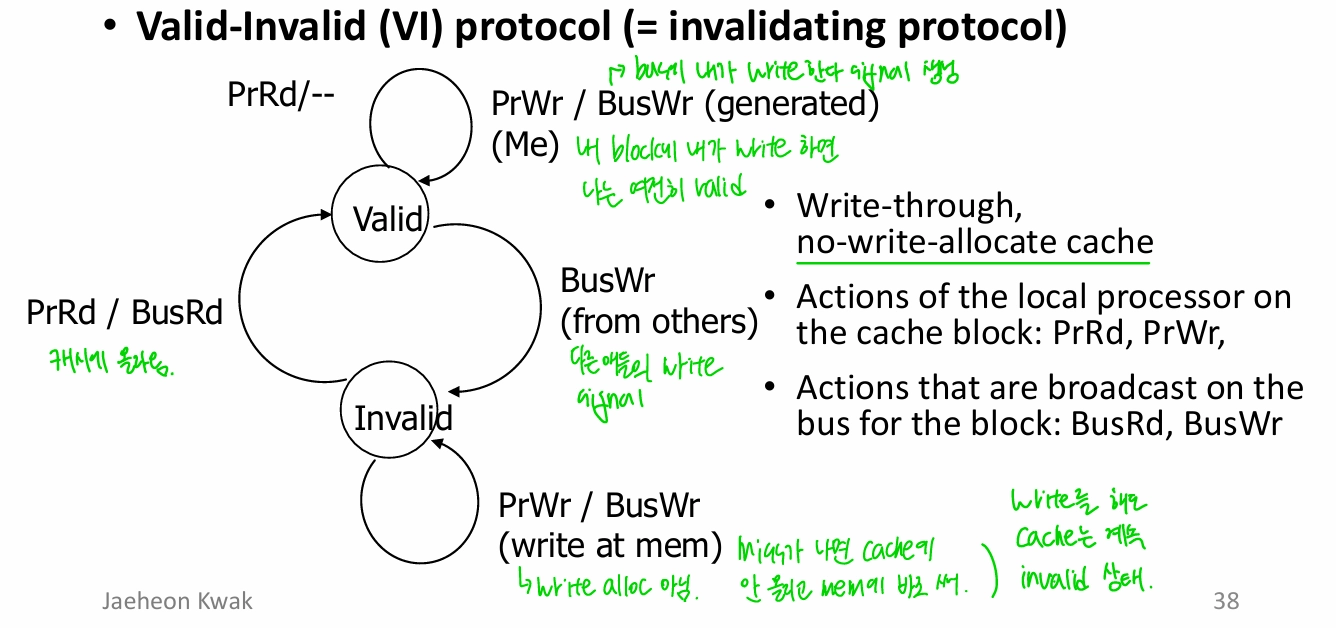
Simple Snoopy - Vaild-Invalid (VI) protocol
- valid/invalid state 관리를 HW가 다 하므로 HW cost가 큼
- scalability가 안 좋지만 latency는 괜찮음, 구현도 쉬움
Update protocol
- block에 write를 할 때 다른 write data를 broadcast → 다른 캐시에 존재하는 값들도 update 값으로
- 자주 업데이트 되지 않는 data에 대해선 유용함 (+ 다시 캐시 접근 안 해도 되고)
- write-through cache policy와 함께 사용할 경우 bus가 bottleneck이 됨
- bus를 통해 메모리로 data도 전달해야 하고 다른 캐시에도 data를 전달해야 하므로
Invalidate Protocol
- block에 write를 할 때 invalidation을 broadcast → 다른 캐시에 있는 값들도 invalidate 처리
- modern CPUs에서 사용
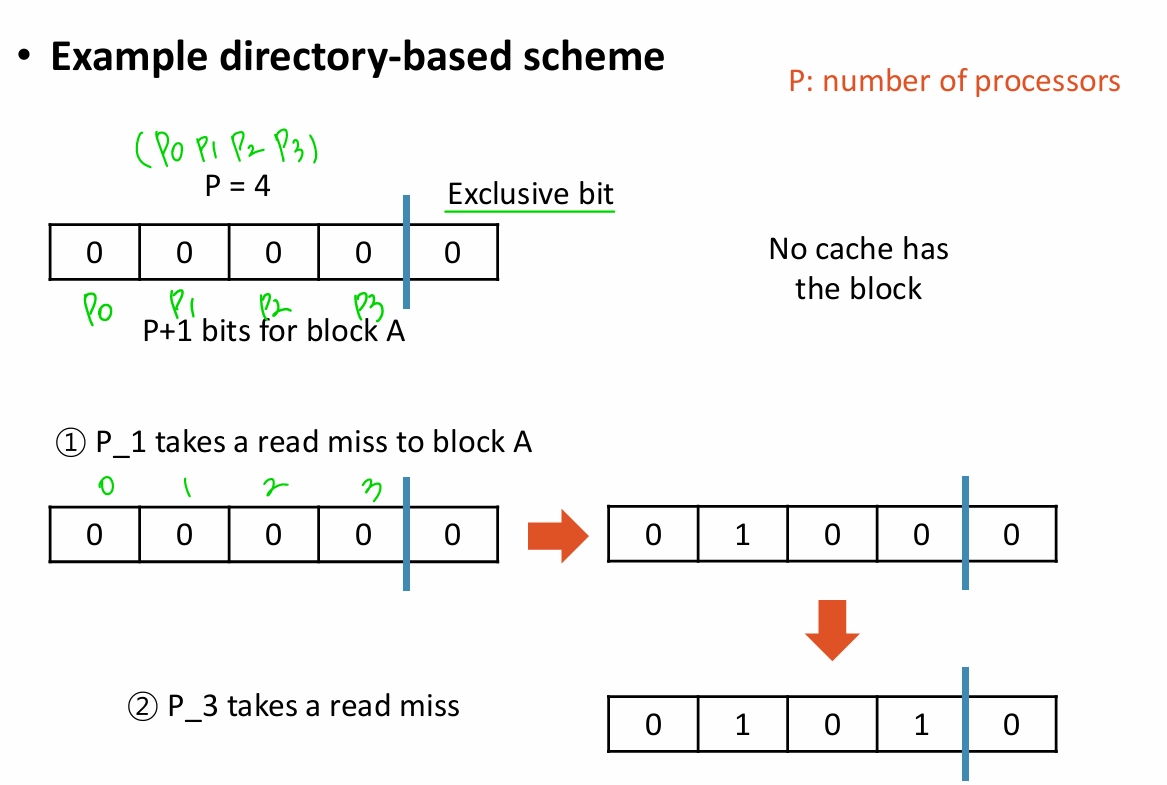
Directory Based Coherence
- 메모리에 있는 block마다 processor bits와 exclusive bit를 둠
- scalability는 좋지만 latency가 나쁨

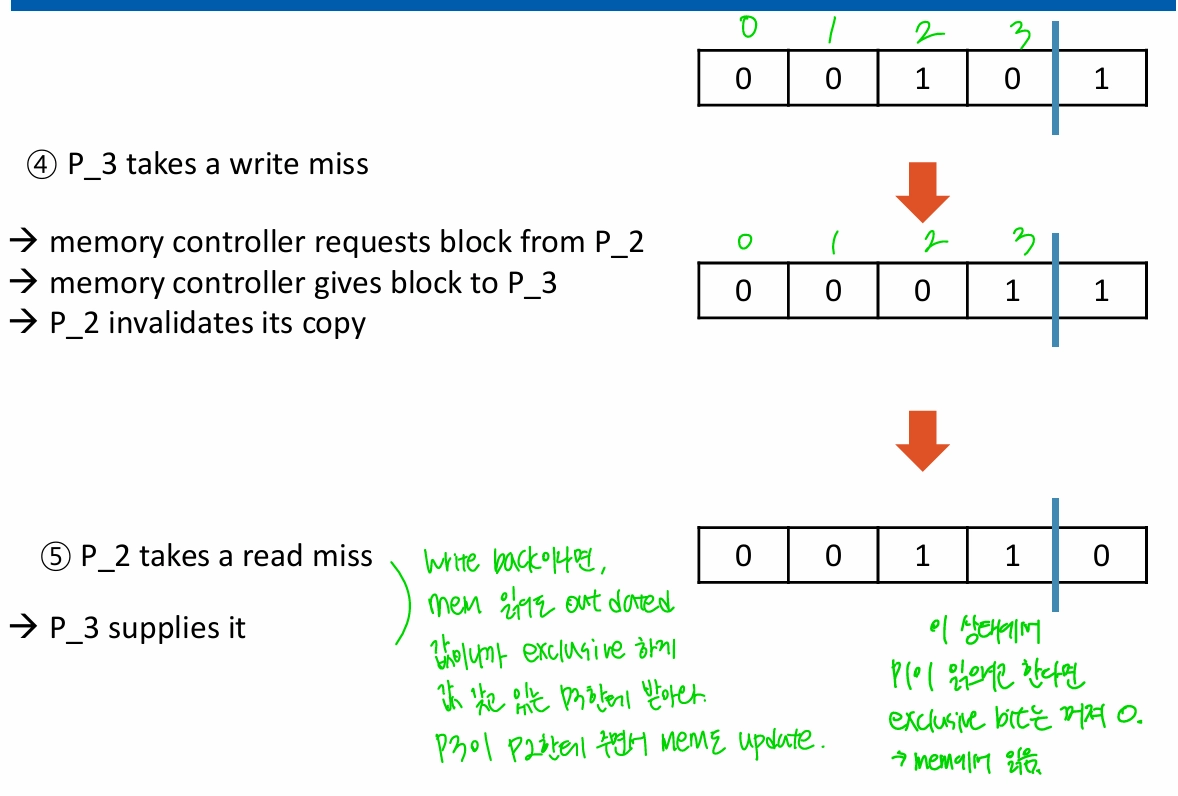
MSI Example
- simple snoopy protocol엔 state가 valid/invalid 두 개밖에 없어서 write-back에서 사용할 수 없음
- M(odified) / S(hared) / I(nvalid)
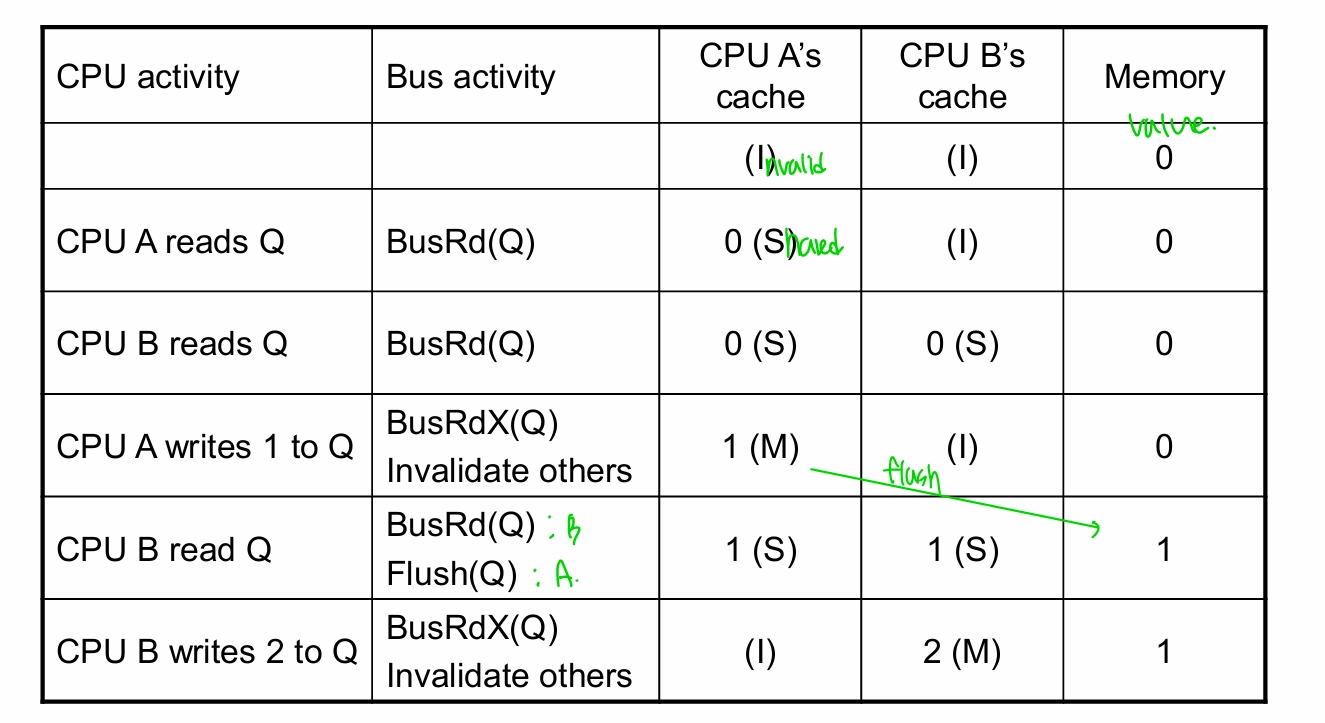
Coherence → cache miss rate
- True Sharing miss
- invalidation 때문에 발생
- False Sharing miss
- block 단위로 update → invalidated block의 unmodified word를 읽으려 해도 miss가 발생
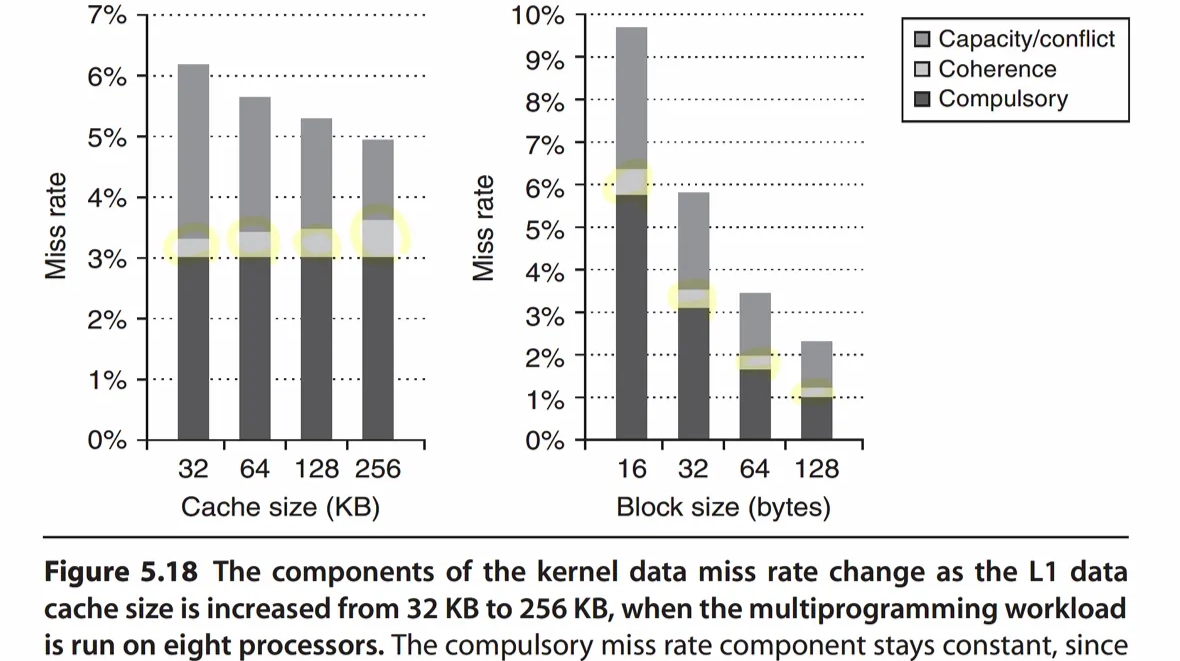
- block 단위로 update → invalidated block의 unmodified word를 읽으려 해도 miss가 발생
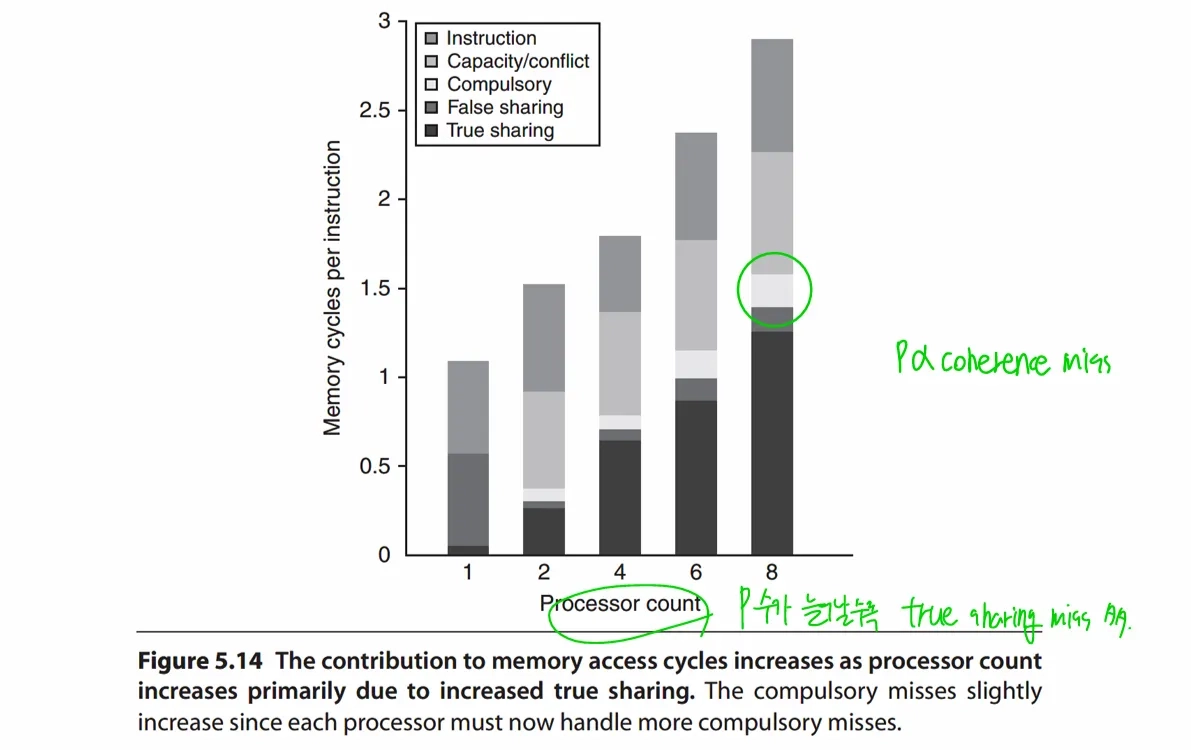
CA^3
How CPUs select cores?
- Intel/AMD + Linux → CFS + Capacity-aware scheduling
- task의 PELT utilization 측정 → idle P 코어 → idle E 코어 → load balancing
- ARM + Linux → CFS + Energy-aware scheduling (EAS)
- 시스템의 load가 크지 않은 상황에서는 E 코어 먼저 사용
- EAS란? task가 무거우면 P-코어, 가벼우면 E-코어
Limitations of Current Approach
- core-to-core latency나 core끼리의 캐시 공유 여부 등을 자세히 고려하지 않음
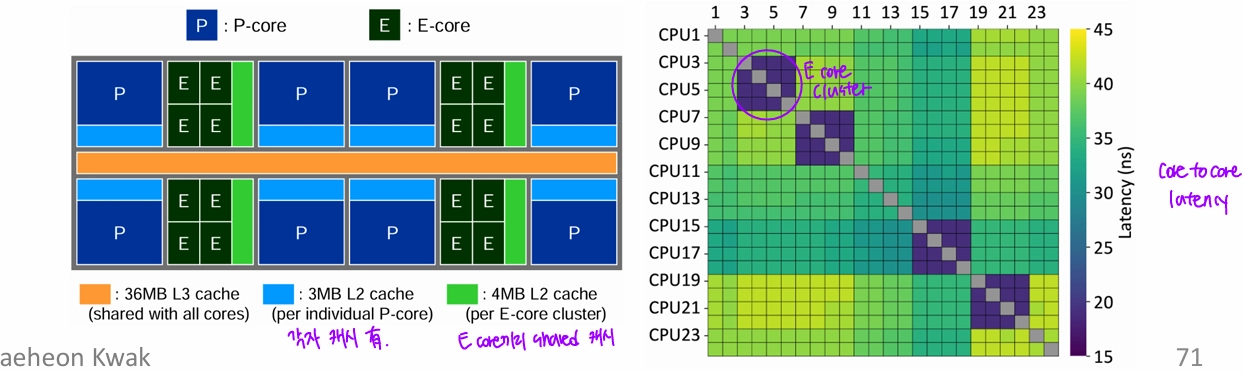
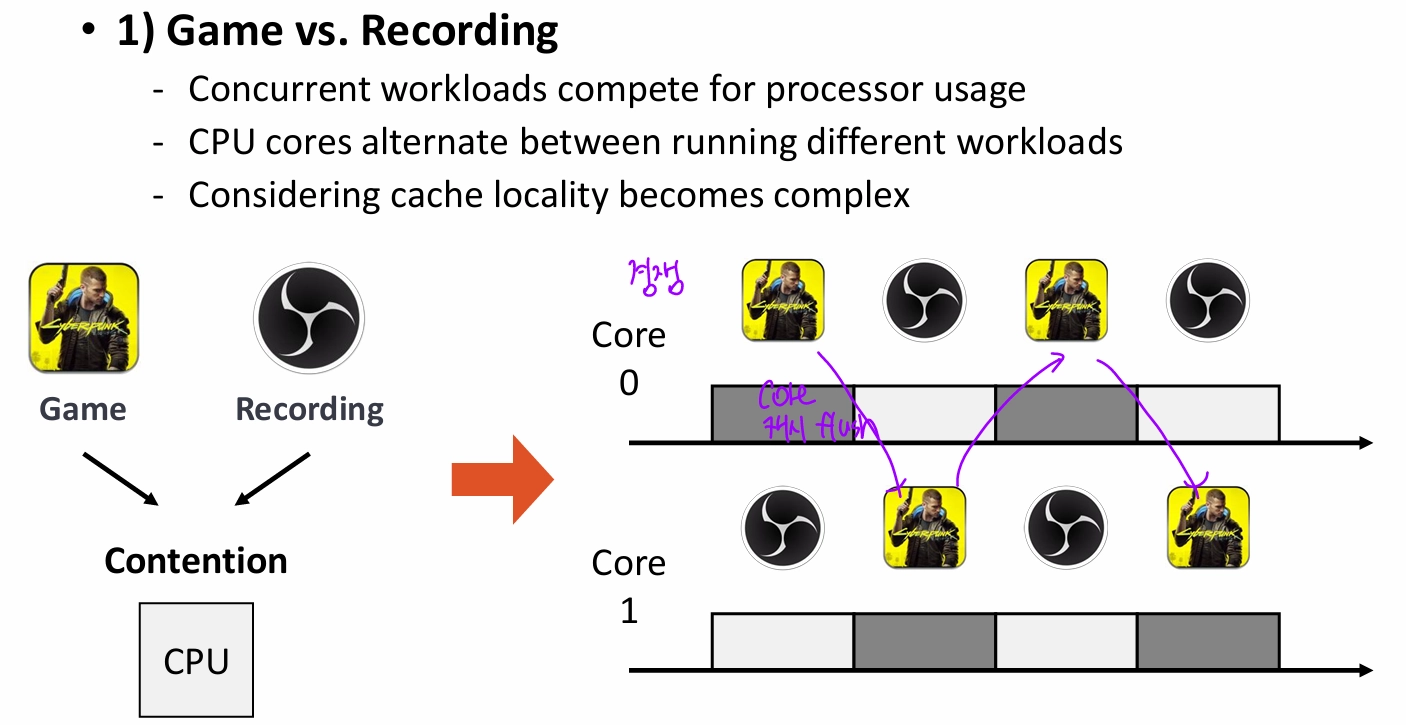
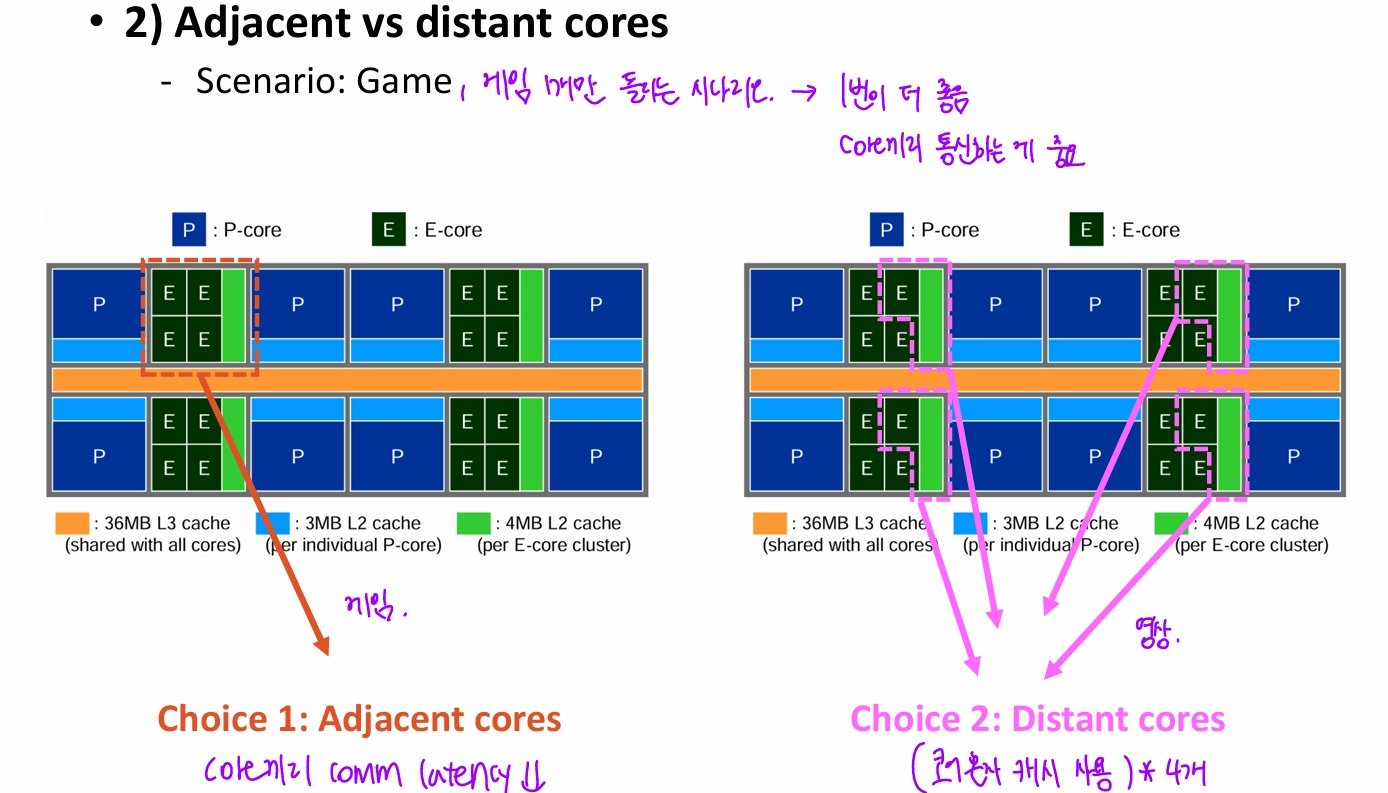
- CA^3
- thread의 characteristic에 따라 P-core 배정의 우선순위를 달리 하고, 캐시 크기나 inter-core communication을 고려해서 E-core를 배정하자.
