고급컴퓨터구조
1.01intro / 02 Performance

Conferencefirm deadline, short process, quality 다양JournalNo deadline, long process, 퀄리티 높음vacuum tube → 트랜지스터 등장 전, 전자 회로 기본 소자ENIAC, EDVACVon Neumann
2.03 Power
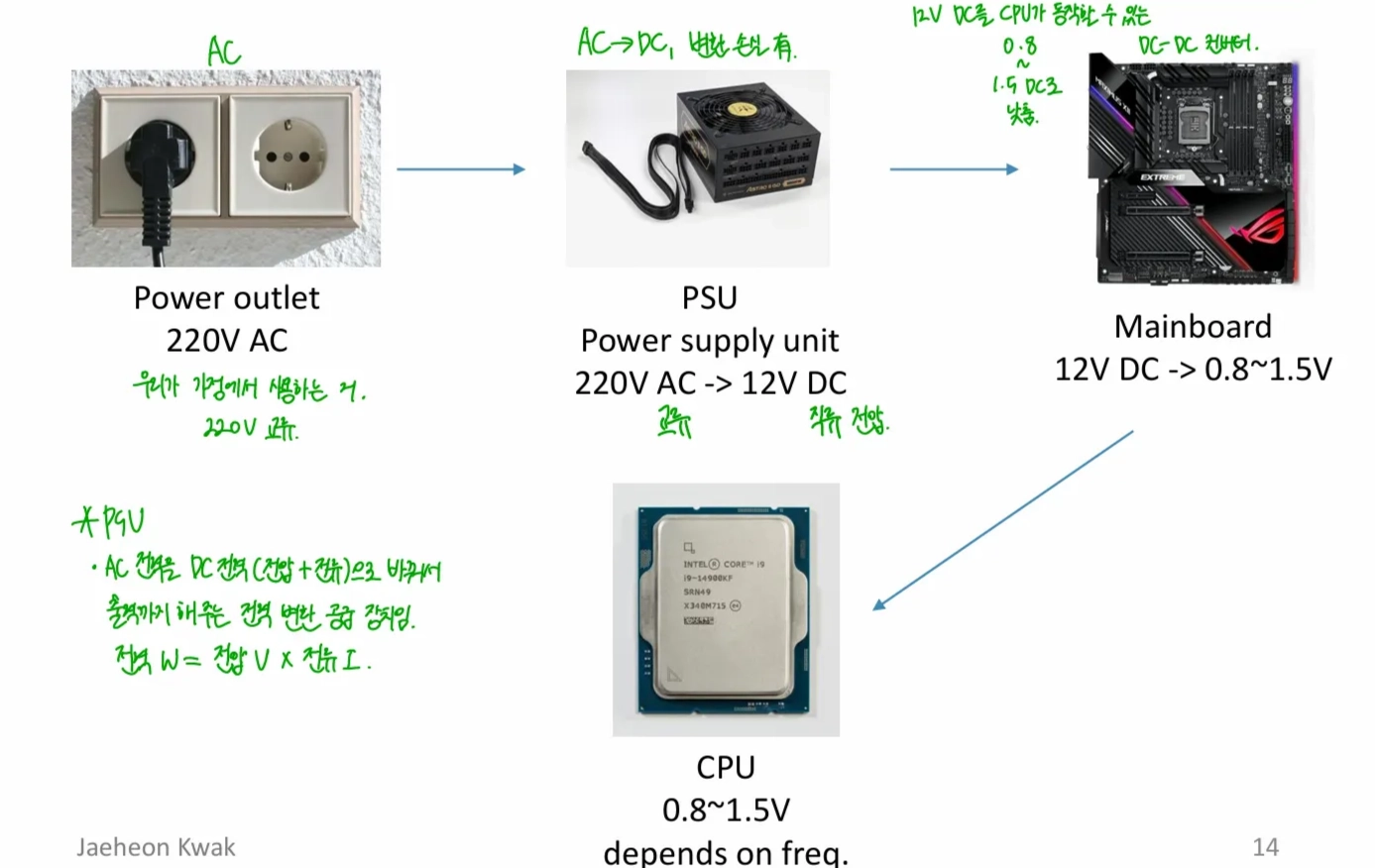
가정용 220V AC (교류) → 12V DC → 0.8~1.5V DC가정용 220V AC (교류) → PSU가 12V DC (직류)로 변환efficiency: 70-95%, 변환 과정에서 발열로 인해 5~30% 손실12V DC→ Mainboard가 CPU가 동작할 수
3.04 DVFS
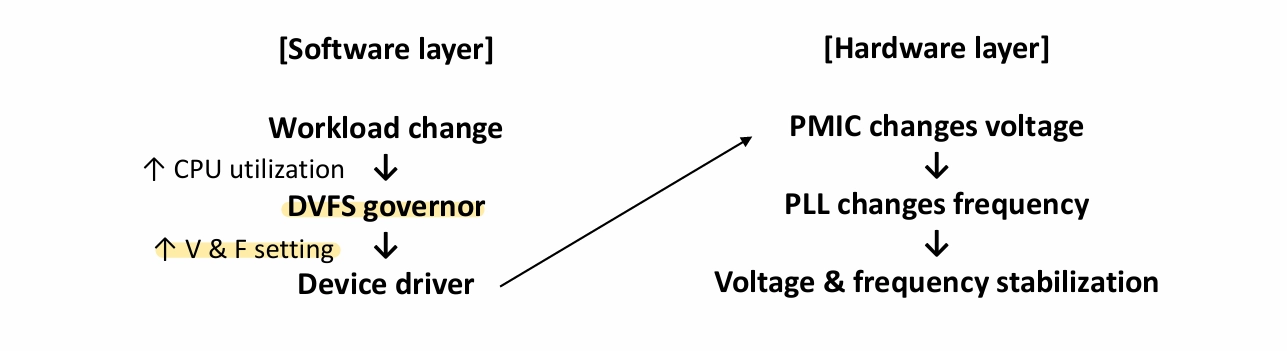
V와 F를 잘 조절하면, performance는 조금만 희생하고, power efficiency를 크게 개선할 수 있음CPU, GPU 같은 processor가 workload에 따라 voltage와 frequency를 조절하는 techniqueDVFS를 어떻게 수행할
4.05 ILP (1)
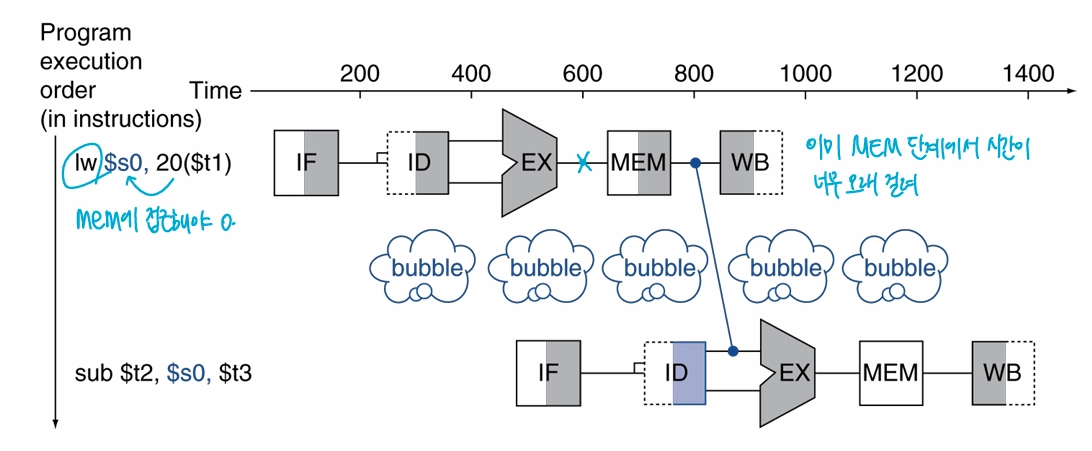
cpu 안에는 수많은 회로가 존재하고, 회로 간 sync를 맞추기 위해 clock이 존재clock period = time between clock ticks = clock rate(freqeuncy) = 초당 돌릴 수 있는 cycle 수single-cycle mach
5.06 ILP (2)
Case/switch statementswitch는 memory에 jump address table이 존재값에 따라 jump 할 곳을 jump address table에서 읽기만 하면 되니까 branch prediction이 도움 XPC 값을, branch 결과를 확실
6.07 Flash memory
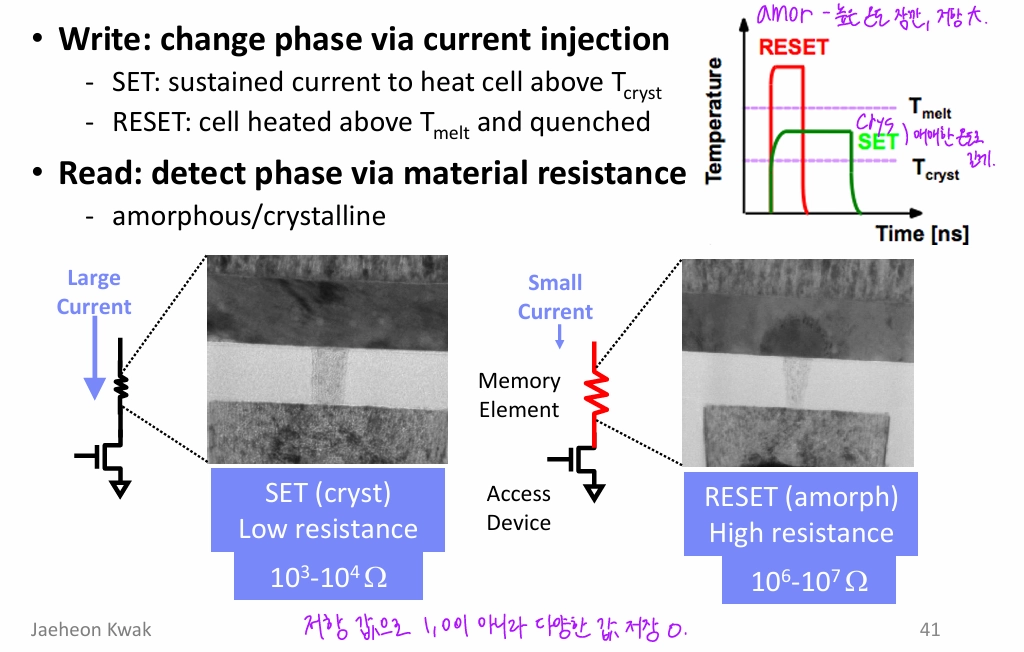
DRAM: RAM의 한 종류, volatileDRAM의 storage unit: cell (transistor 1개 + capacitor 1개)NAND Flash: non-volatile (GATE가 있어서 전하가 새어나가는 걸 막아주는 역할을 함)SSD: NAND F
7.08 DLP (1)
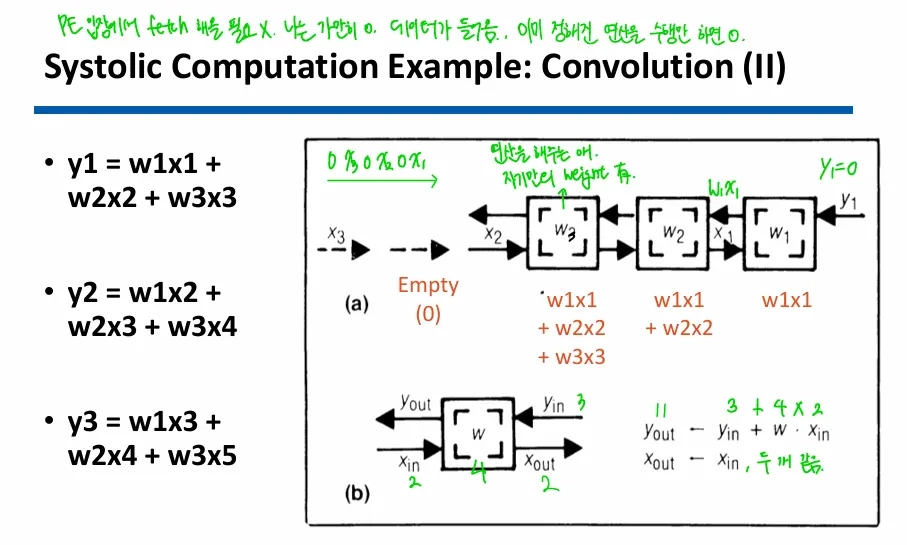
특정 연산을 빠르게 수행하도록 설계된 Specialized AcceleratorFPGAs, ASICs를 사용해서 구현됨명령어를 하나씩 읽고 실행하는 von Neumann과 달리, PE↔PE 사이 register-to-register로 data 전달simple, regu
8.08 DLP (2)
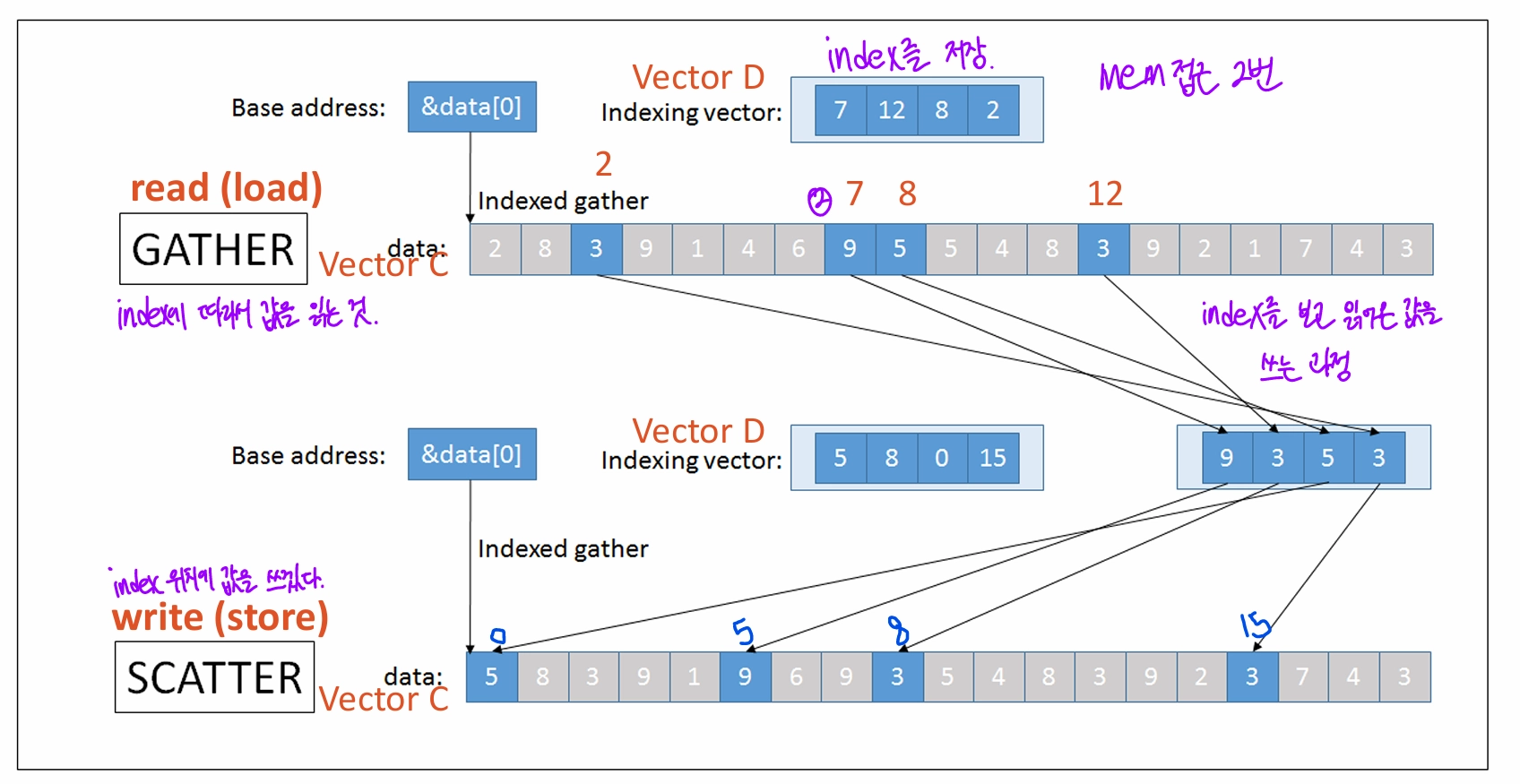
data elemetns 수 > vector register에 들어가는 수?Strip-mining읽어야 할 데이터 길이가 내가 가진 vector reg보다 클 경우, reg 크기만큼 쪼개서 여러 번 읽는 방법stride ≠ 1?bank가 너무 작거나 stride가 너무
9.09 TLP
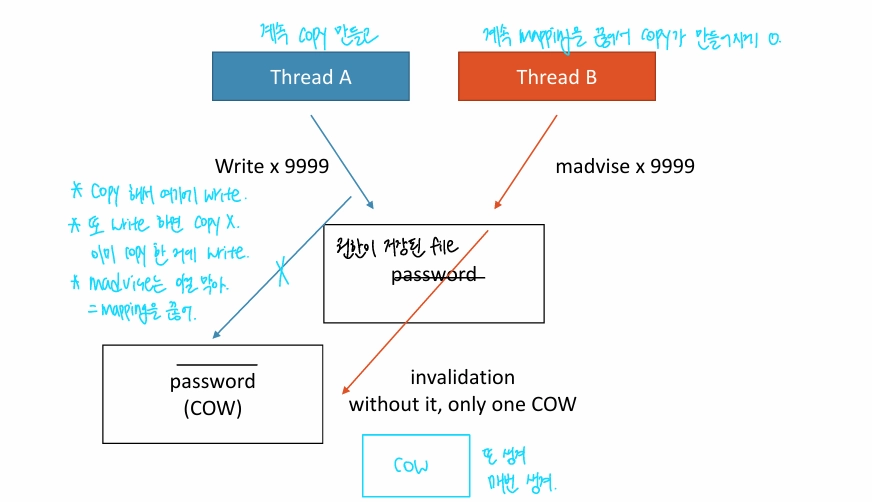
Parallelism같은 시간에 많은 일을 하는 것여러 HW resource (cores, pipeline, SIMD)가 필요Instruction-level parallelism / Data-level parallelism / Task-level parallelismC
10.10 Cache
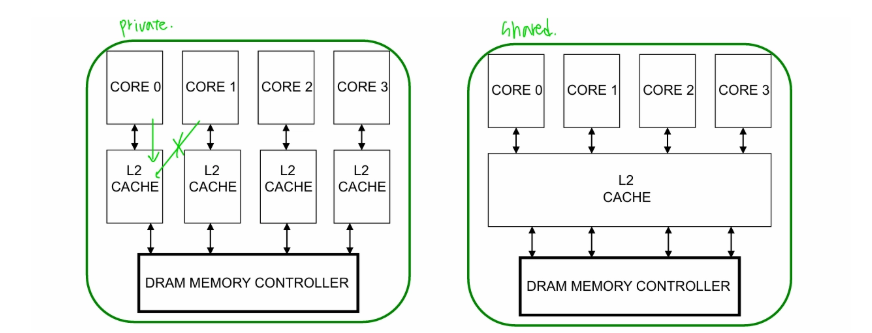
L1, L2 cache: core마다 존재L3 cache: sharedPrivate vs Shared CachesResource Sharing advantageresource utilization/efficiency이 좋아지면서 throughput도 증가함어떤 thre
11.11 Memory-Centric Computing
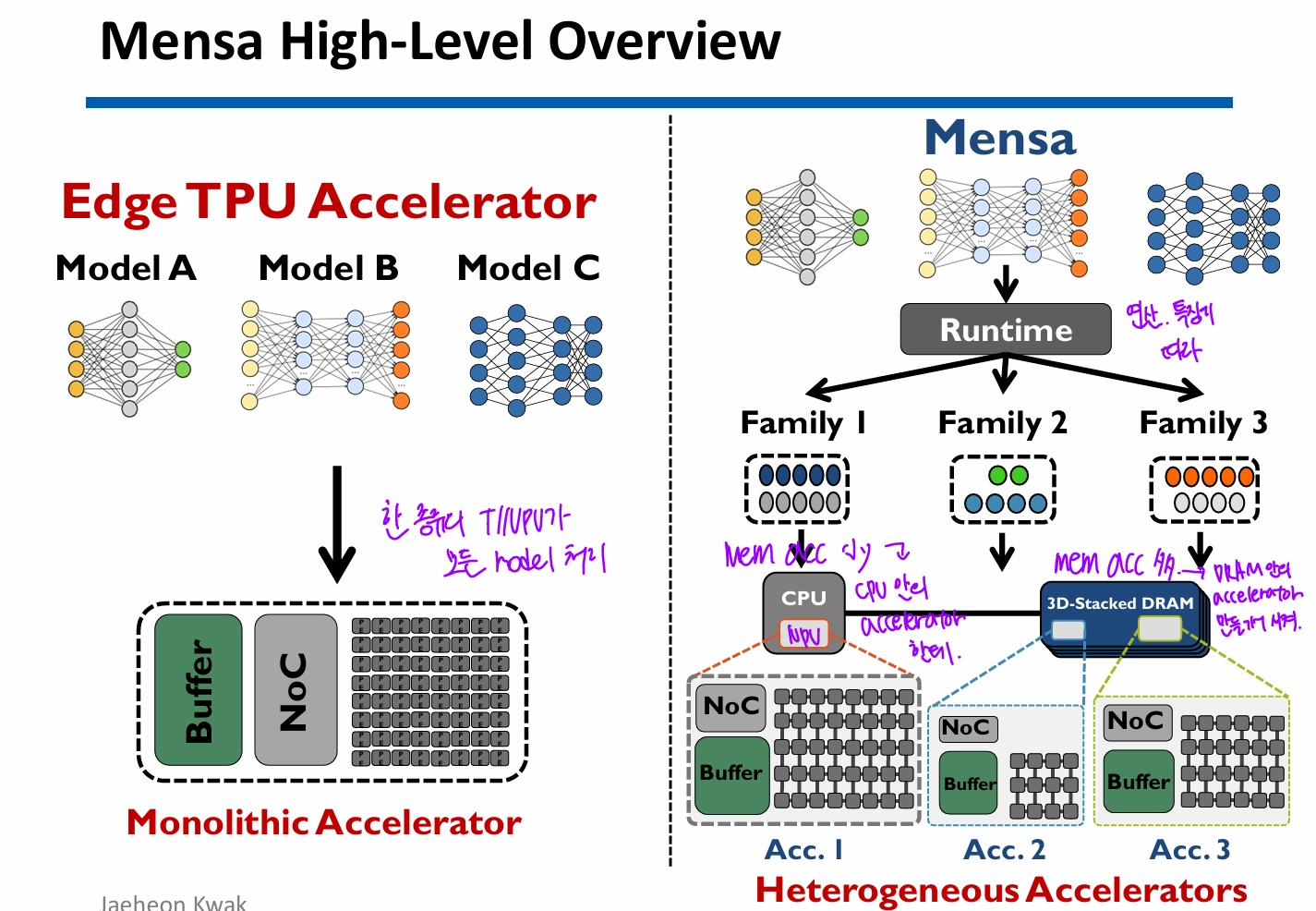
H/W FLOPs는 3배 증가했는데 DRAM bandwidth나 Interconnect Bandwidth는 1.6배, 1.4배Model 크기나 training FLOPs는 420배, 750배 증가했는데 accelerator mem은 2배 증가intra/inter chi