Collective Communication
여러 개의 GPU를 활용하여 AI/ML 학습 속도를 높이는 것은 매우 중요하지만, 이 GPU들 간에 효율적은 통신을 구축하는 일은 까다롭다. 바로 이 지점에서 NVIDIA의 NCCL 라이브러리가 중요한 역할을 한다. NCCL은 기본적으로 GPU 간의 collective communication을 빠르게 처리하기 위해 만들어진 라이브러리이다. 따라서 NCCL이 실제로 무엇을 가속하고 최적화하는지 알기 위해선, 그 대상인 collective communication 개념을 먼저 알아야 한다.
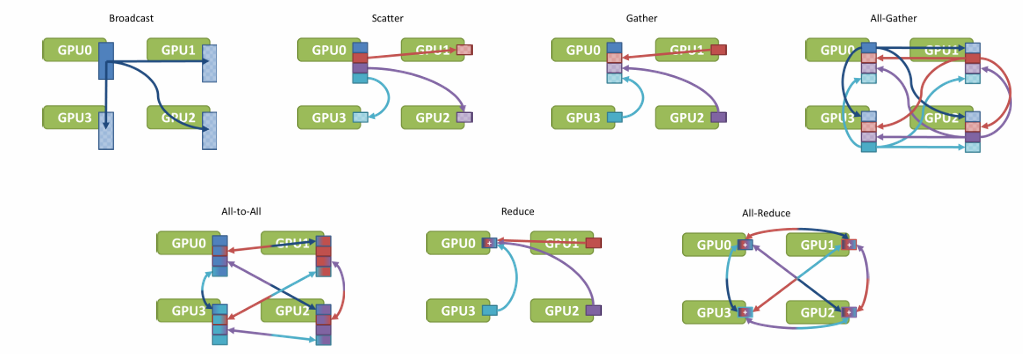
collective communication이란 여러 processes가 참여하여 하나의 data를 n개의 processes에게 나눠주거나, n개의 processes의 데이터를 하나로 모으거나, 또는 모든 processes 간에 데이터를 교환하는 통신 패턴을 의미한다. 대표적인 방식들은 다음과 같다.
- Broadcast
- Scatter
- Gather
- All-Gather
- All-to-All
- Reduce
- All-Reduce
Broadcast
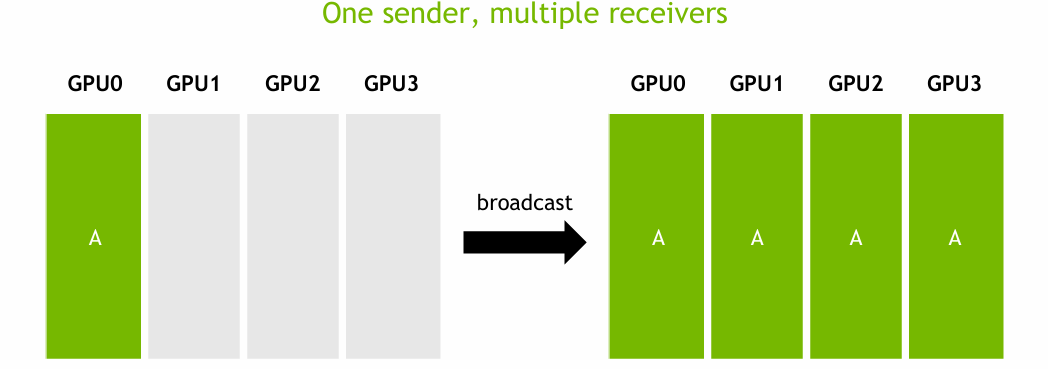
Broadcast는 하나의 source GPU (root)에서 생성된 data을 동일한 그룹에 속한 다른 모든 GPU에게 전달하는 방식이다. 예를 들어 모델 학습 초기에 root GPU가 초기 파라미터를 가지고 있을 때, 이 파라미터를 모든 GPU가 동일하게 갖도록 전달하는 데 사용된다.
NCCL에서는 이 boradcast 작업을 효율적으로 처리하기 위해 트리 기반 알고리즘을 사용한다. 이 방식은 root GPU가 모든 GPU에게 데이터를 한 번에 전송하는 것이 아니라, 일부 GPU들에게 먼저 데이터를 보낸 후, 데이터를 받은 GPU들이 다시 다른 GPU들에게 데이터를 전파하는 식으로 진행된다. 이렇게 계층적으로 데이터를 전파하면 전체 GPU 수가 많아져도 communication overhead가 급격히 증가하지 않으며, latency를 줄일 수 있다.
Scatter
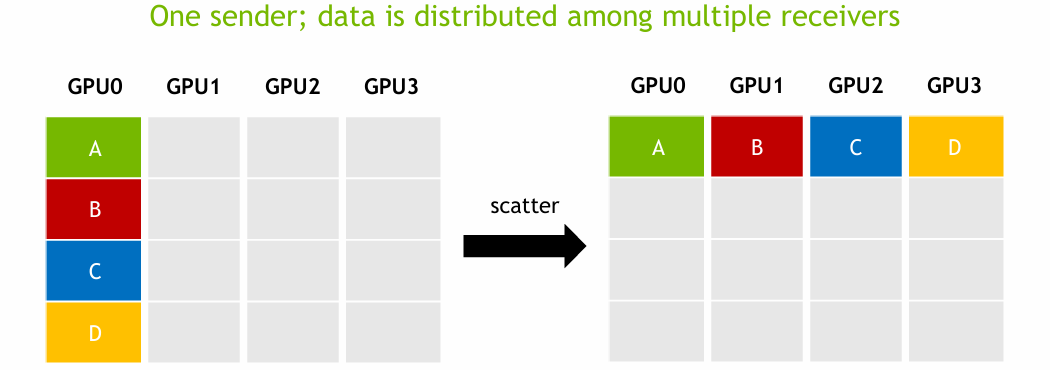
Scatter은 하나의 GPU(보통 root GPU)가 가지고 있는 데이터를 여러 chunk로 나누어, 각각의 GPU에 하나씩 전달하는 방식이다.
Scatter는 하나의 큰 작업을 병렬하여 분산 처리할 때 유용하다.
Gather
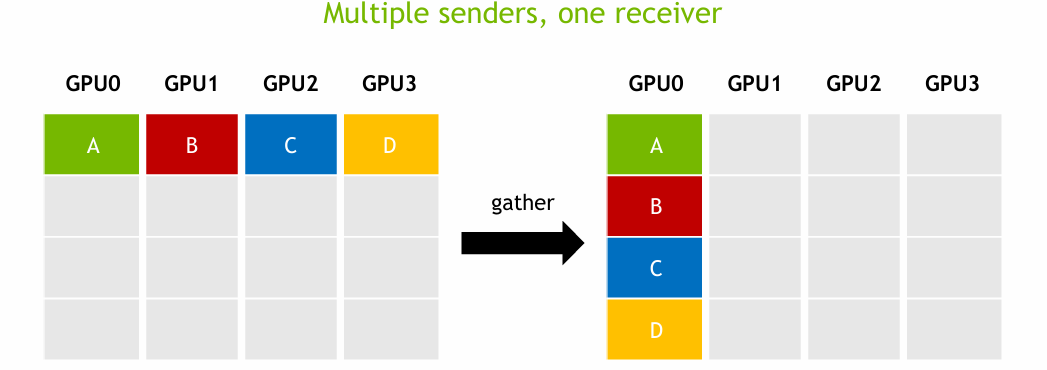
Gather는 Scatter의 반대로, 여러 GPU가 각각 가지고 있는 데이터를 하나의 GPU로 모으는 연산이다.
All-gather
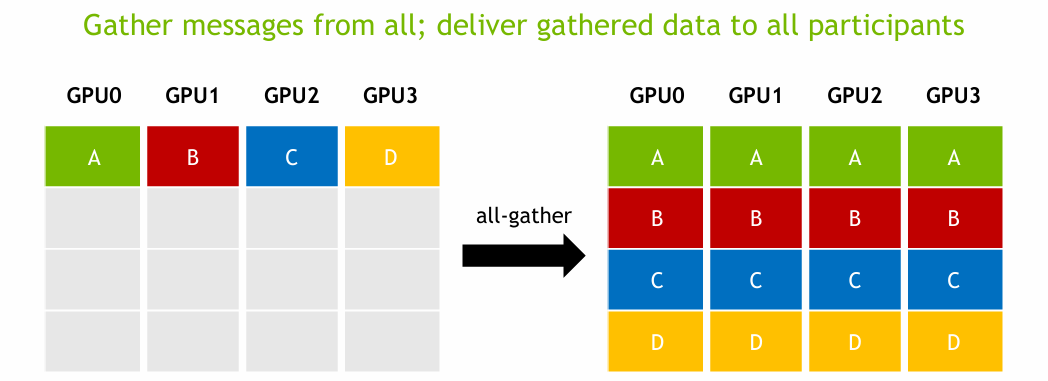
All-gather는 Gather와 Broadcast의 조합이라고 볼 수 있다. 즉, 먼저 각 GPU가 갖고 있는 데이터들을 모으고(Gather), 그 결과를 다시 모든 GPU에게 뿌리는(Broadcast) 방식이다.
All-gather는 각 GPU가 계산한 중간 결과를 모두가 공유해야 할 때 사용된다. 예를 들어 문장이 4개 있고, 두 개의 GPU가 각각 두 문장씩 임베딩을 계산했다면, 이후 self-attention과 같은 연산을 위해 모든 문장의 임베딩을 각 GPU가 모두 가지고 있어야 한다. 따라서 각 GPU는 자신의 임베딩을 다른 GPU에게 보내고, 다른 GPU로부터도 임베딩을 받아야 한다. 이처럼 각 GPU가 서로의 결과를 주고받아 전체 데이터를 공유해야 하는 상황에서 All-Gather 연산이 사용된다.
All-to-All
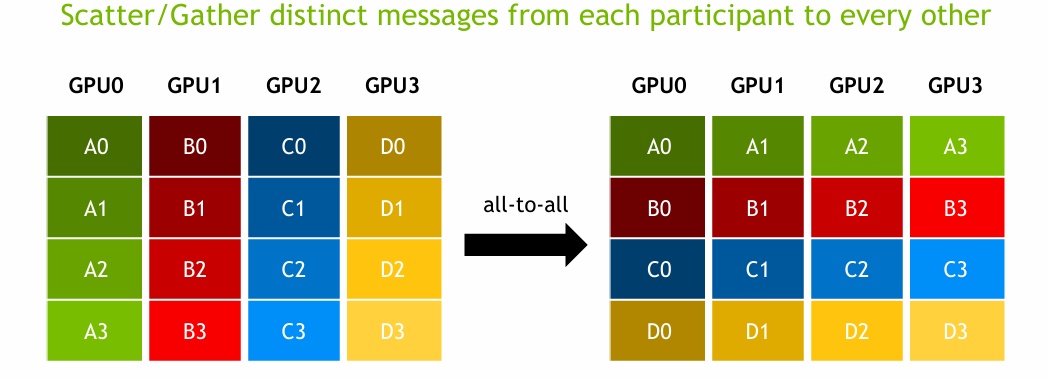
All-to-All은 모든 GPU가 서로에게 unique한 데이터를 주고받는 방식이다. 각 GPU는 자신이 갖고 있는 데이터를 여러 chunk로 나눠서 다른 모든 GPU에게 나눠 보내고, 동시에 다른 모든 GPU로부터 data chunks를 받는다. 그리고 각 GPU는 받은 data chunks를 모아서 하나의 전체 data로 reconstruct 한다.
Reduce
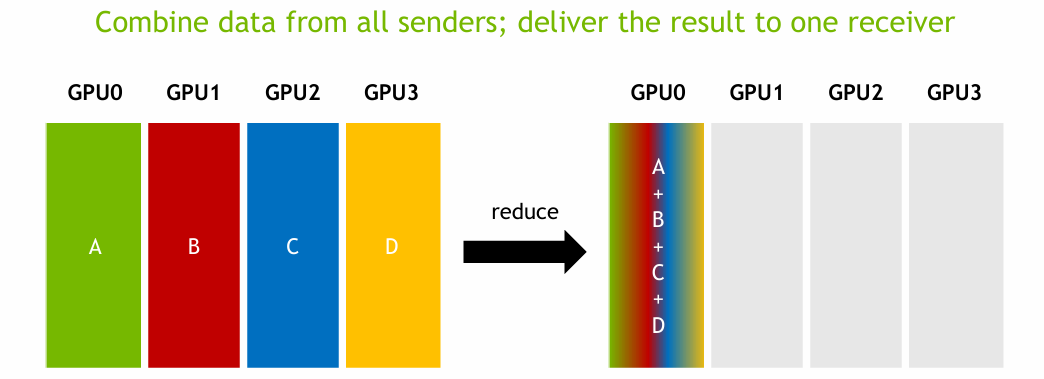
Reduce는 모든 GPU가 갖고 있는 데이터를 하나로 aggregate하고, 그 결과를 하나의 GPU에만 저장하는 방식이다.
예를 들어, 모든 GPU의 loss 값을 더해서 root에서 출력할 때 사용될 수 있다.
Reduce-Scatter

Reduce Scatter에서 각 GPU는 자신의 데이터를 먼저 동일한 크기의 chunk로 분할한다. 그런 다음, 자신의 chunk를 이웃 GPU에게 전송하면서, 이전 GPU로부터 받은 chunk와 자신의 chunk를 연산하여 누적한다. 이 과정을 반복하면 모든 GPU가 전체 reduce 결과의 일부를 갖게 된다.
All-Reduce
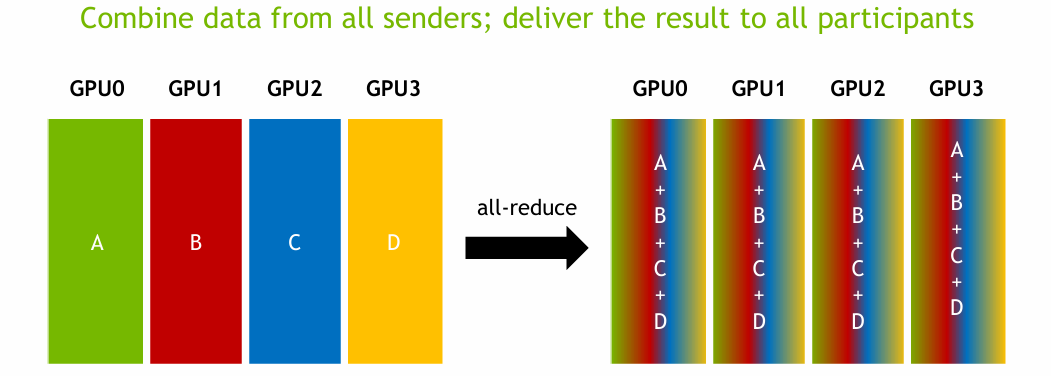
All-Reduce는 모든 GPU가 갖고 있는 데이터를 하나로 aggregate 한 뒤, 그 결과를 다시 모든 GPU가 공유하도록 하는 연산이다.
NCCL의 All-Reduce는 성능을 극대화하기 위해 ring-based algorithm을 사용하며, 이는 Reduce-Scatter와 All-Gather 과정을 순차적으로 진행하는 방식으로 볼 수 있다. 예를 들어, 먼저 각 GPU는 자신의 데이터를 chunk로 나눈 후, 이를 이웃 GPU들과 교환하며 동시에 덧셈 연산을 수행(Reduce-Scatter)한다. 이어서 각 GPU가 가진 부분 합 결과들을 다시 주고받아 전체 sum을 얻고, 모든 GPU에게 이 결과를 공유(All-Gather)한다.
현재 NCCL은 all-gather, all-reduce, broadcast, reduce, reduce-scatter 과 같은 collective 연산들을 지원한다.
Ring-based AL
processor 혹은 GPU간 collective communication을 효율적으로 구현하는 방법에는 여러 가지가 있다. 하지만 연결된 processor 간의 네트워크 구조(=topology)를 고려하는 것은 매우 중요하다.
two step tree AL example
예를 들어, 하나의 CPU에 4개의 GPU가 PCIe로 연결된 PCIe topology가 있다. GPU0에서 다른 모든 GPU로 데이터를 broadcast하는 상황이고, 빨간색 화살표는 PCIe x16 connections를 의미한다. (하나의 통로가 16차선)
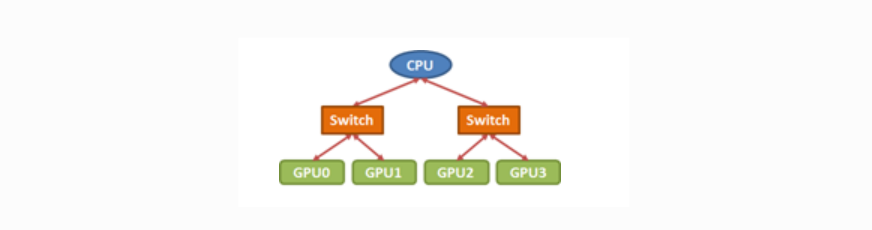
이러한 상황에서는 two-step 트리 알고리즘이 일반적으로 사용된다. 즉 첫 setp에서 GPU0가 다른 GPU 하나에게 데이터를 보내고, 이 두 GPU가 나머지 두 GPU에게 데이터를 전달하는 방식이다.
이때 선택지가 존재한다. 첫 번째는 GPU0이 먼저 GPU1에게 데이터를 보내고, 그 다음 GPU0는 GPU2에게, GPU1은 GPU3에게 전달하는 방식이다.
GPU0 → GPU1
GPU0 → GPU2
GPU1 → GPU3두 번째는 GPU0이 먼저 GPU2에게 데이터를 보내고, 그 다음은 GPU0이 GPU1에게, GPU2가 GPU3에게 데이터를 보내는 방식이다.
GPU0 → GPU2
GPU0 → GPU1
GPU2 → GPU3이 PCIe topology에 두 번째 방식이 더 바람직하다. 첫 번째 방식에선, GPU0 → GPU2와 GPU1 → GPU3 전송이 동시에 일어날 경우, 둘 다 CPU를 통해 양쪽 switch 간 통신을 시도하게 되므로 CPU 주변의 상단 PCIe 링크(CPU와 각 switch 사이의 링크를 의미)에 contention이 생긴다. 따라서 이 링크의 bandwidth를 두 전송이 동시에 공유하게 되면서 effective bandwidth(실제 얻어진 데이터 전송 속도)가 절반이 된다.
결론적으로, collective communication의 성능을 높이기 위해서는 네트워크 topology를 신중하게 고려해야 한다.
ring-based AL example
Broadcast bandwidth를 더욱 최적화하기 위해서는 위 PCIe 구조를 ring-topology로 다룰 수 있다. ring-topology에서 각 GPU는 오직 이웃 GPU들과만 직접 통신한다.
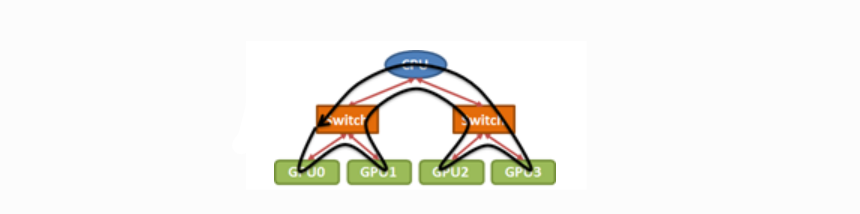
이 예시에선 GPU0에서 GPU3으로 이어지는 ring topology를 따라 입력 데이터를 작은 chunck로 나누어 전달한다.
relay: GPU0 → GPU1 → GPU2 → GPU3 → GPU0위와 같은 트리 구조의 PCIe 환경에서도 거의 최적에 가까운 bandwidth 성능을 낼 수 있다. 다만 이 방식을 사용할 땐 ring order를 잘 설정하는 것이 중요하다. 또한 GPU 수가 많아질수록 latency가 증가되고, 중간 node가 느려지면 전체가 느려진다는 단점이 있다.
GPU Collectives with NCCL
NCCL은 내부적으로 GPU들에 optimal ring order를 부여하므로 사용자는 hw configuration에 대해 신경 쓰지 않아도 된다.
대부분의 collective 연산은 중간 결과를 위한 buffer를 필요로 한다. NCCL에선 GPU 당 메모리 사용량을 수 MB 수준으로 줄이기 위해, 큰 collective 연산을 작은 chunk 여러 개로 나눈다.
나눈 chunck마다 별도의 커널(GPU에서 실행되는 함수)과 cudaMemcpy(CPU ↔ GPU, GPU ↔ GPU 간 data copy 함수)를 매번 호출하는 것은 비효율적이다. 예를 들어 1GB를 256KB씩 나누면 4,000번, 4KB씩 나누면 무려 256,000번 커널을 실행해야 한다.
따라서 NCCL은 각 collective마다 monolithic CUDA kernel을 둔다. 다시 말해서, 하나의 monolitic kernel만 실행하고, 내부에서 반복문을 돌리며 각 chunck에 대한 copy와 연산 작업을 모두 통합적으로 처리한다.
이를 가능하게 만드는 건 바로 GPU 간 Peer-to-Peer(P2P) memory access 기능이다. 즉, 한 GPU의 커널 내부에서 다른 GPU의 메모리 주소로 접근하는 것도 가능하다는 뜻이다. 현대의 GPU (같은 노드 내에서 PCIe root complex가 공유되거나 NVLink로 연결된 경우)는 서로의 글로벌 메모리를 직접 읽고 쓸 수 있다. 이 기능을 GPUDirect P2P라 부른다.
P2P가 불가능한 경우에는, 즉 GPU들이 서로의 메모리에 직접 접근하는 것이 허용되지 않는 경우에는, pinned system memory(페이지 아웃되지 않는 영역)를 사용한다. 이 pinned system memory에는 GPU 간 동기화를 위한 volatile 변수를 둘 수도 있다. (동기화가 왜 필요할까. GPU1이 GPU0의 데이터를 받기도 전에 연산을 해서는 안 될 것이다.) 따라서 NCCL에서는 GPU 간 동기화를 위해, pinned memory에 volatile 변수를 두어, 이 변수로 GPU의 상태를 표시하고, 변수의 값을 다른 GPU가 polling으로 계속 확인할 수 있게끔 한다.
여러 processor 간 데이터를 주고받는 방식인 collective communication과 NCCL에 대해 간략히 알아보았다.
참고 자료
https://developer.nvidia.com/blog/fast-multi-gpu-collectives-nccl/
https://images.nvidia.com/events/sc15/pdfs/NCCL-Woolley.pdf
