Prerequisite
NVLink
NVIDIA가 NVIDIA가 개발한 고속 interconnect 기술로 주로, GPU-GPU 또는 GPU-CPU 간 데이터 전송을 빠르고 효율적으로 처리하기 위해 사용된다. 기존의 PCIe 대비 훨씬 높은 bandwidth와 낮은 latency를 제공하며, 여러 GPU를 하나의 shared memory pool처럼 연결할 수 있어서 대규모 병렬 연산과 데이터 처리에 유리하다.
NVLink 도메인이란, 여러 GPU가 있을 때 NVLink로 직접 연결돼 있는 GPU의 집합을 의미한다. 같은 도메인 안의 GPU들은 PCIe가 아닌, NVLink로 데이터를 주고받으므로 빠르게 통신할 수 있다.
InfiniBand
InfiniBand는 여러 서버 간 데이터를 빠르고 효율적으로 전송하기 위해 사용되는 고속 interconnect 기술이다. NVLink와 달리 연결 범위가 서버 내부에 국한되지 않고, 데이터센터나 HPC 클러스터 전체의 네트워크 수준에서 여러 서버들을 연결한다.
2D hierarchical ring
2D hierarchical ring이란 통신 구조를 intra-node(같은 서버 안에 있는 GPU끼리의 통신), inter node(서로 다른 서버 간 GPU끼리의 통신) 이렇게 두 개의 차원으로 나누어 구성한다. 즉, 각 노드 내부에서 reduce-scatter 연산을 수행한 뒤, 노드 간 여러 번의 all-reduce 연산을 수행하고, 마지막으로 노드 내부에서 다시 all-gather 연산을 수행하는 식으로 동작한다.
이런 식이다. 먼저 각 노드에서 reduce-scatter를 마친 뒤 상황이 아래와 같다고 하자.
Node 0:
GPU0: a0+b0 → chunk0 (partial sum)
GPU1: a1+b1 → chunk1 (partial sum)
GPU2: a2+b2 → chunk2 (partial sum)
GPU3: a3+b3 → chunk3 (partial sum)
Node 1:
GPU0: c0+d0 → chunk0 (partial sum)
GPU1: c1+d1 → chunk1 (partial sum)
GPU2: c2+d2 → chunk2 (partial sum)
GPU3: c3+d3 → chunk3 (partial sum)이후 노드 간 여러 번 all reduce를 수행한다.
GPU0들끼리: chunk0 all-reduce → global chunk0
GPU1들끼리: chunk1 all-reduce → global chunk1
GPU2들끼리: chunk2 all-reduce → global chunk2
GPU3들끼리: chunk3 all-reduce → global chunk3마지막으로 각 노드에서 global chunk들을 모아서 계산한다.
Background
오늘날 모든 딥러닝 프레임워크는 multi-GPU, multi-maching training을 지원하며, 이렇게 신경망 학습에 여러 GPU를 사용하는 방식은 매우 일반화되었다. 여러 GPU의 gradients를 합산하는 All-Reduce 연산은 일반적으로 ring topology로 구현되어 왔다. ring topology는 높은 bandwidth를 얻을 수 있지만, GPU의 수가 증가함에 따라 latency도 선형적으로 증가한다는 단점이 있어서, 수백 개 이상의 GPU 구조에는 적용하기가 어렵다. 이 문제를 해결하기 위해 NCCL 2.4가 등장하였다.
많은 large scale의 experiments에서는 flat ring topology를 계층적 2D ring algorithm으로 대체하여 latency도 줄이고 적당한 bandwidth도 확보하였다. NCCL 2.4는 double binary trees 방식을 사용여, 전체 bandwidth는 유지하면서도 latency를 로그 수준으로 낮췄다. 이 latency는 2D ring algorithm보다도 더 작다.
Double binary trees
Double binary tree 자체는 2009년에 MPI(Message Passing Interface)에서 제안된 개념이다. 이 방식은 Broadcast와 Reduce 연산에 full bandwidth를 제공한다. (두 연산을 결합하면 all-reduce 연산이 된다.) 또한 로그 수준의 latency를 제공한다는 장점이 있다. NCCL에서는 이미 MPI에서 성능이 검증된 double binary tree를 GPU 간 collective operation에도 적용하여 이러한 이점을 그대로 가져갔다.
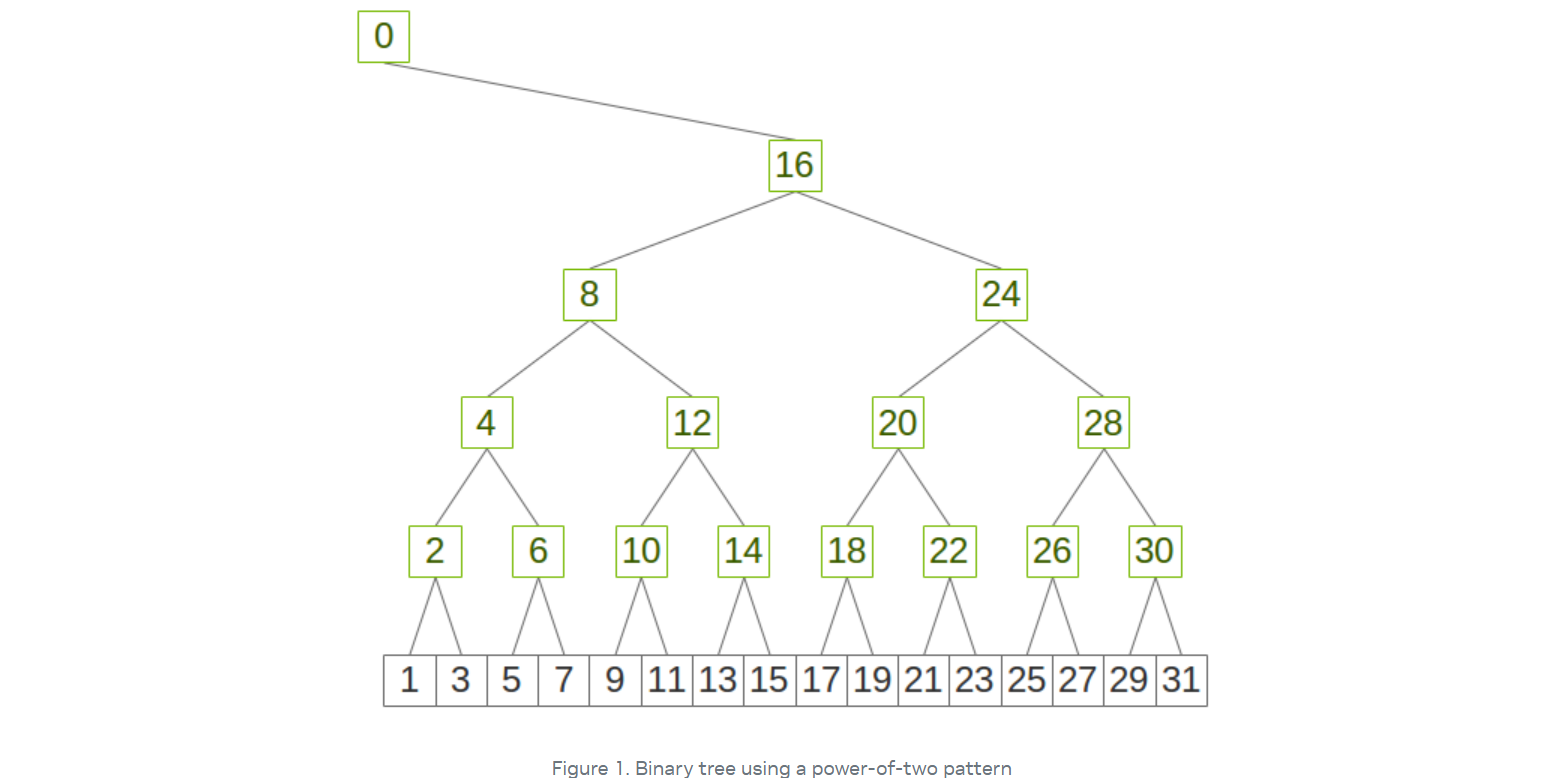
NCCL에서는 위 그림과 같이 locality를 최대화하면서 구현이 쉬운 패턴으로 트리를 구성한다. 다시 말해서 트리를 간단한 규칙으로 트리를 빠르게 만들되, 물리적으로 가까운 GPU끼리를 우선적으로 edge로 연결해서 통신에 필요한 거리를 줄인다. 예를 들어, 같은 서버/같은 NUMA/같은 NVLink 도메인 안의 GPU들 먼저 묶어서 edge로 연결하고, 그 다음에 다른 서버/노드로 확장해 나가 느린 링크를 거치는 횟수를 최소화한다.
위 그림에서는 2의 거듭제곱 패턴을 사용하여 구성한 binary tree이다. 이러한 트리는 GPU ID만 보고 부모/자식을 단순한 비트 시프트 연산(>> 1, << 1)로 계산할 수 있어 구현이 단순하고, 처음에는 번호가 가까운 GPU끼리는 가깝게, 먼 번호는 멀게끔 유지함으로써 locality를 높일 수 있다.
binary tree는 level이 늘어날수록, 노드 수도 급격하게 많아져서, 트리 전체에서 절반 이상이 leaf node가 되고 절반 이하가 내부 node가 된다. 즉, 참여하는 GPU 중 절반 이하는 데이터 전달의 역할(내부 노드를 하고, 나머지 절반 이상은 leaf node로서 데이터의 시작점 또는 끝점 역할만 한다.
double binary tree는 이 특성을 이용해서, binary tree에서 leaf node였던 rank(GPU의 unique ID)를 내부 node로, 내부 node였던 rank를 leaf node로 바꾸어 두 번째 트리를 만든다. 이때 두 트리에서 모두 leaf node인 rank는 하나 있을 수 있지만, 두 트리에서 모두 내부 노드가 되는 rank는 없다.
아래 그림은 왼쪽의 내부 node와 leaf node를 뒤집어 두 번째 binary tree를 만든 예시이다.

두 트리를 동시에 보면 모든 rank는 두 개의 parent node와 두 개의 child node를 갖게 된다. 예를 들어 rank 24를 보자. 왼쪽 그래프에서는 rank 16을 parent로, rank 24와 rank 28을 child node로 갖고 오른쪽 그래프에서는 rank 25를 parent ndoe로 갖게 된다. 총 2개의 parent node와 child node가 존재하게 되는 것이다.
double binary tree에서는 전체 데이터를 절반으로 나누어 각각의 tree에 보낸다. 즉 전체 데이터가 S라고 하면 binary tree 1에는 S/2를, binary tree 2에는 S/2만큼의 데이터를 보낸다. double binary tree에서 각 rank는 parent node 2개와 child node 2개를 갖는다. 이는 한 rank가 parent로부터 S/2만큼의 데이터를 최대 두 번 받고, child에게 S/2만큼의 데이터를 최대 두 번 전송할 수 있다는 뜻이다.
즉, double binary tree에서 각 rank는 최대 S만큼의 데이터를 받고 S만큼의 데이터를 전송할 수 있는데, 이 값은 ring topology에서 한 rank가 받고 보내는 데이터의 양과 동일하다. 다만, ring topology에서는 총 N개의 rank가 있으면 latency가 O(N)에 비례하지만, double binary tree에서는 O(log N)에 불과해 latency가 훨씬 낮아진다.
사실 binary tree에서, single binary tree에서 발생한 link contention 현상을, tree를 두 개 쓴다고 완화할 수 있는 건지는 아직 의문이다.
Performance at scale
최대 24,576개의 GPU를 사용하여 NCCL 2.4를 테스트한 결과이다. 그래프에서 볼 수 있듯, 규모가 커질수록 트리 구조에서의 latency가 확연히 개선되고, 24,000개의 GPU 환경에서는 최대 180배 개선되었다고 한다.

double binary tree 구조를 사용하더라도, ring topology와 비슷하게 full bandwidth를 유지할 수 있었다. 다만, 규모가 아주 커졌을 경우 (e.g. 수천~수만 GPU)에는 InfiniBand 네트워크에서 L3 스위치를 거쳐 통신해야 하므로 bandwidth가 다소 감소하는 현상이 나타난다. 여기서 L3 스위치는 InfiniBand의 상위 계층 스위치로, 다른 노드에 위치한 GPU에 연결될 때 반드시 거쳐야 하는 구간이다. 이 구간에서 발생하는 bandwidth 감소는 NCCL의 communication pattern이 InfiniBand routing algorithm과 잘 맞지 않아서라고 추측한다. 즉, NCCL의 double binary tree 데이터 흐름이 그 라우팅 규칙과 일부 충돌하면서 bandwidth가 감소한다고 추측한다.

Effect on DL training
아래 그림에선 딥러닝 학습에서 NCCL 2.4를 사용했을 때의 성능 향상이 상당하며, GPU 개수가 늘어날수록 그 향상 폭이 점점 커지는 모습을 보여준다.
실험에서는 NCCL 2.3, NCCL2.4, 그리고 NCCL 2.3 기반의 2D hierarchical ring 방식을 사용하였다.

그래프에서 N128/1024는 총 128개의 노드가 있고 총 1024개의 GPU가 있다는 것을 의미한다. 같은 방식으로 보면 N32/256 → 32 노드, 총 256 GPU → 노드당 8 GPU, N64/512 → 64 노드, 총 512 GPU → 노드당 8 GPU가 된다. 즉, 이 실험에서는 항상 노드당 8 GPU 구성을 유지한 채 노드 수를 늘려 전체 GPU 개수를 확장했다고 보면 된다.
가장 오른쪽의 초록색 막대 그래프 위에 적혀 있는 499,863 images/sec라는 건, 노드 수를 늘려 GPU의 개수를 1024개로 확장했을 때, double binary tree를 통해 초당 50만 장이라는 높은 처리량을 달성했다는 것을 의미한다.
일반적으로 GPU 개수가 많아질수록 통신 overhead로 인해 처리량 증가에 제약이 생긴다. 다른 구조들도 노드 수가 증가함에 따라 처리량이 증가하는 경향을 보이지만, double binary tree 구조가 다른 구조에 비해 큰 규모에서도 뛰어난 성능을 계속 보이는 것을 알 수 있다.
double binary tree 구조에 대해 알아보았다. 이 구조에서는 한 rank가 intermediate node와 leaf node의 역할을 동시에 맡게 된다. 이렇게 두 역할을 동시에 갖게 되면, 한 rank에 부하가 집중되는 것을 막을 수 있으면서도 이 rank가 처리하는 bandwidth는 ring topology일 때와 다름이 없다.
즉, double binary tree는 latency는 tree 수준으로 낮추면서, bandwidth는 ring 수준으로 유지하는 장점을 지닌 구조이다.
참고 자료
https://developer.nvidia.com/blog/massively-scale-deep-learning-training-nccl-2-4/
https://blogs.nvidia.com/blog/what-is-nvidia-nvlink/
