P2P, SHM, NET에 대해서 알아보려고 한다. 참고한 자료이다.
이미 한국어로 잘 정리된 글을 다시 한 번 정리하는 것이라 내용은 거의 같다.
데이터 로딩 시 병목 현상
데이터가 메모리에 이미 로드되어 있고 단일 GPU를 사용하는 상황이라고 가정하자.
전통적인 워크플로우의 경우, 데이터셋을 스토리지(NVMe)에서 GPU 메모리로 로드할 때 해당 데이터가 CPU와 PCIe bus를 거쳐 디스크에서 GPU 메모리로 복사된다.
이때 데이터 로딩에는 최소 2번의 data copy 작업이 필요하다. 스토리지에서 CPU RAM으로 데이터를 전송할 때 첫 번째 copy가, 호스트 메모리에서 GPU VRAM으로 전송할 때 두 번째 copy가 진행된다.
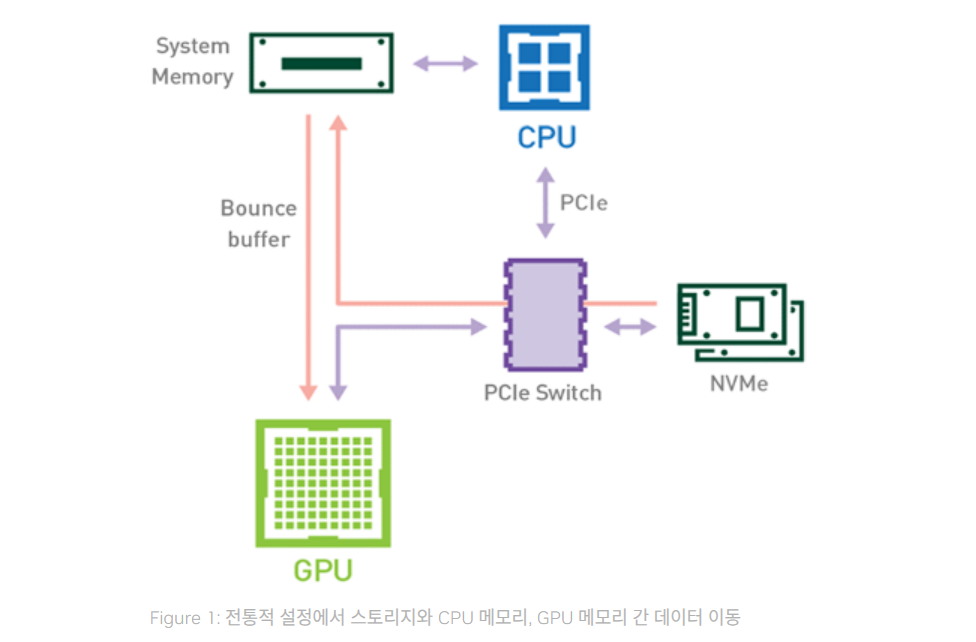
상황: 단일 GPU
데이터셋 이동 경로: NVMe → CPU RAM → GPU VRAM
- 첫 번째 data copy: NVMe → CPU RAM
- 두 번째 data copy: CPU RAM → GPU VRAM
GPUDirect Storage
GPUDirect Storage 기술을 사용하면 CPU와 호스트 메모리를 쓰지 않고 PCIe bus만 이용해 데이터가 스토리지에서 GPU 메모리로 곧장 이동한다. 이때 데이터는 한 번만 copy되므로 전체 실행 시간이 줄어든다. 또한 이 과정에서 사용하지 않는 CPU와 CPU RAM을 파이프라인 내 다른 CPU 기반 작업에 활용할 수 있다.
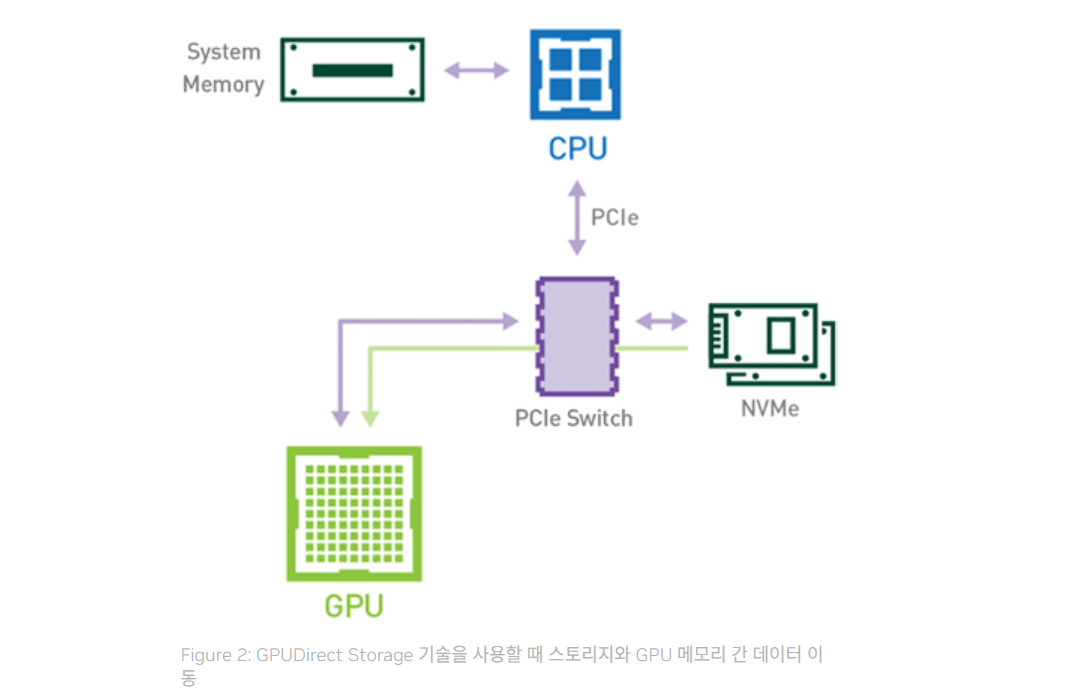
상황: 단일 GPU
데이터셋 이동 경로: NVMe → GPU VRAM
- 첫 번째 data copy: NVMe → GPU VRAM
Intra 데이터 전송 시 병목 현상
SHared Memory
워크로드에 따라선 동일한 노드(서버) 내에 위치한 복수의 GPU 간에 데이터를 교환하기도 한다. NVIDIA GPUDirect Peer to Peer 기술이 활성화되지 않은 시나리오에서는 먼저 source GPU의 데이터가 CPU와 PCIe bus를 거쳐 shared pinned memory로 copy 된다. 다음으로 shared pinned memory의 데이터가 CPU와 PCIe를 거쳐 타깃 GPU로 copy 된다. 이 과정은 CPU와 호스트 메모리가 모두 사용될 뿐만 아니라, data copy가 두 차례 진행된다.
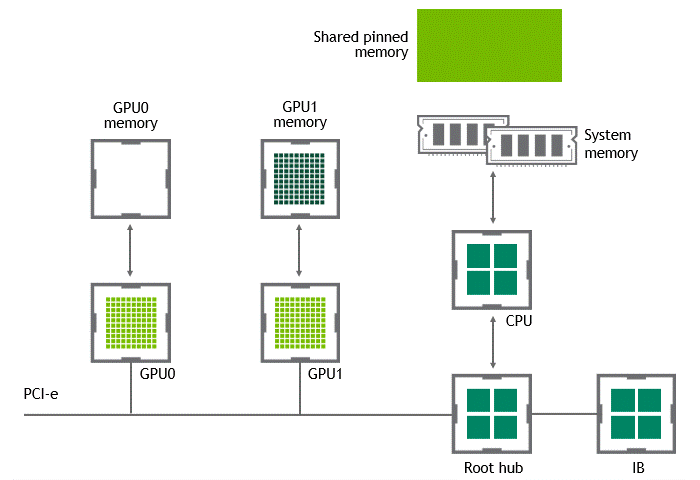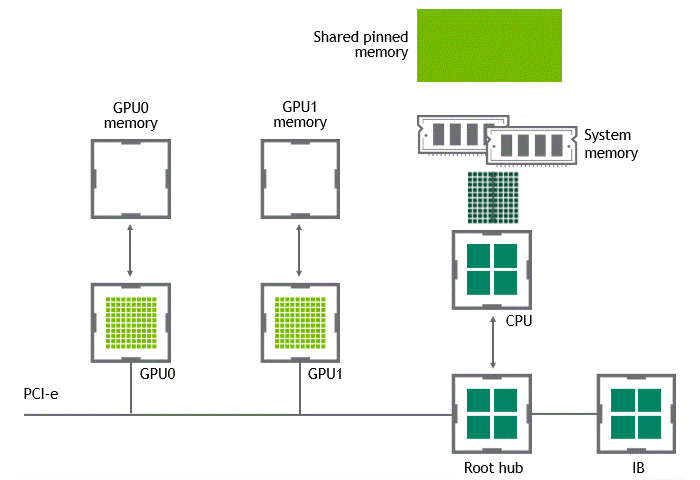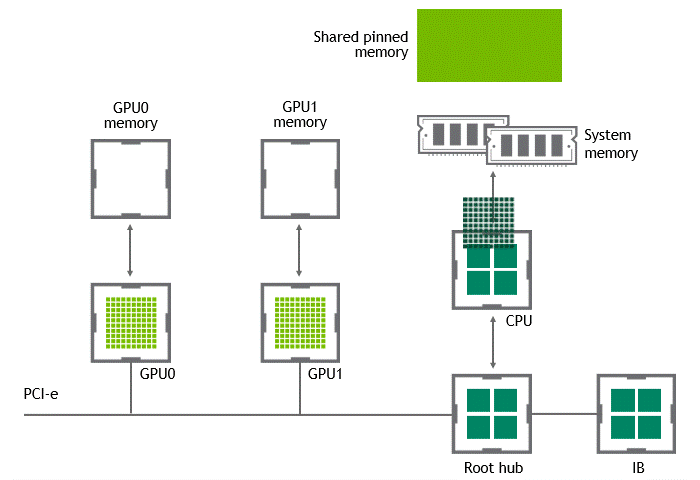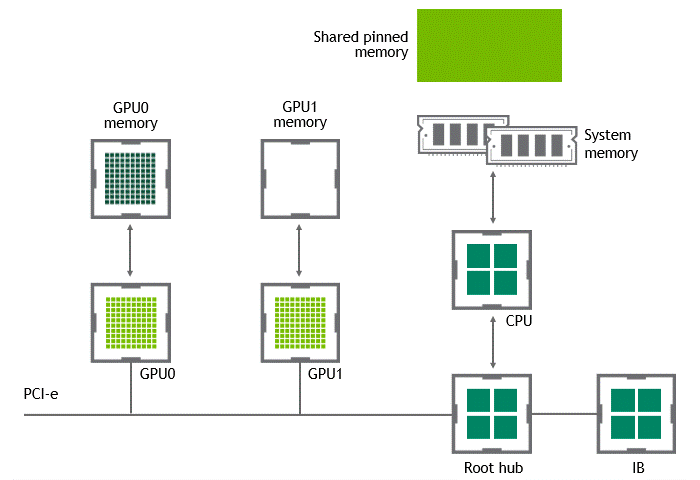
상황: 단일 노드, 복수 GPU
데이터셋 이동 경로: GPU VRAM → SHM → target GPU
- 첫 번째 data copy: GPU VRAM → SHM
- 두 번째 data copy: SHM → target GPU
GPUDirect P2P
GPUDirect Peer to Peer을 사용하면 source GPU에서 동일 노드 내의 다른 GPU로 copy 하려는 데이터를 호스트 메모리에 임시 staging할 필요가 없다. 두 GPU가 동일한 PCIe bus에 연결돼 있는 한 CPU를 거치지 않아도 된다. GPUDirect P2P는 동일한 작업의 수행에 필요한 data copy 수를 절반으로 줄인다.
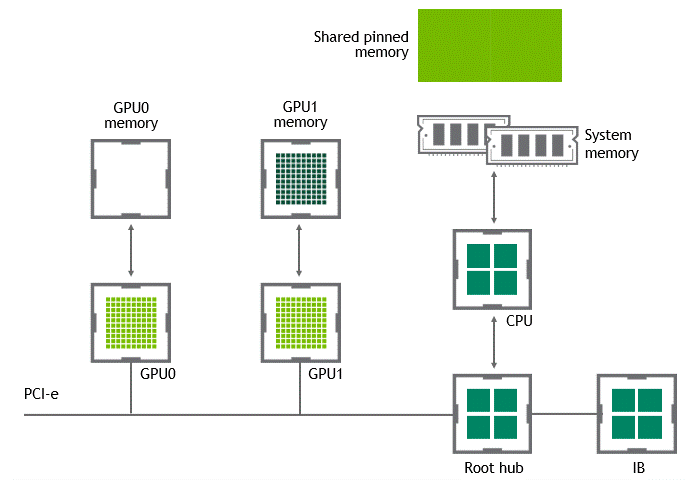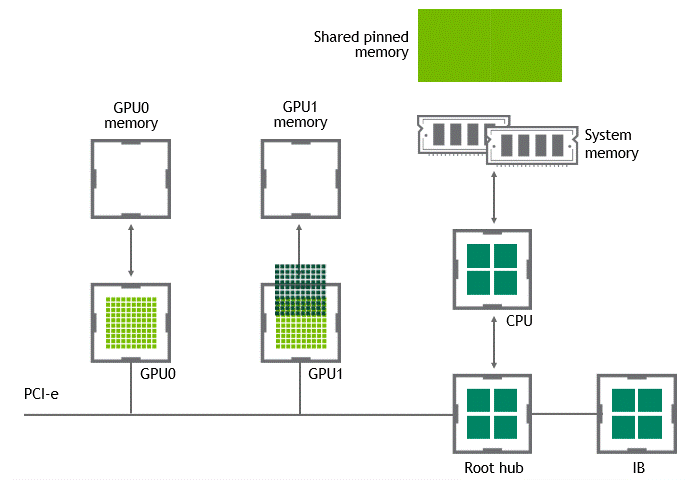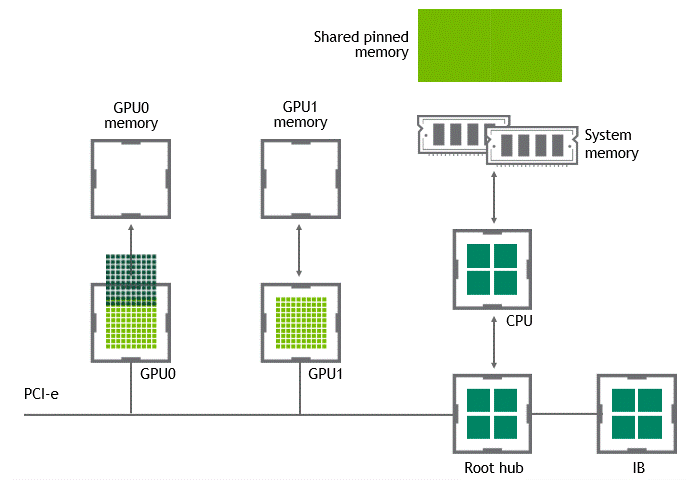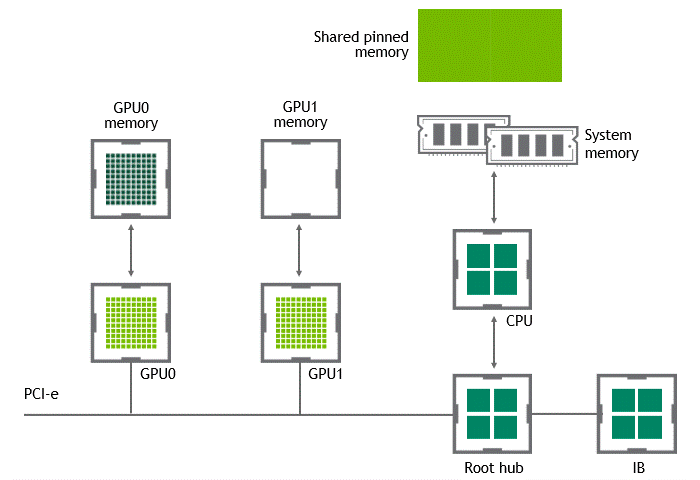
상황: 단일 노드, 복수 GPU
데이터셋 이동 경로: GPU VRAM → target GPU
- 첫 번째 data copy: GPU VRAM → target GPU
Inter 데이터 전송 시 병목 현상
Host RDMA
NVIDIA GPUDirect RDMA를 사용하지 않는, 여러 개의 노드가 존재하는 환경에서는 서로 다른 노드에 존재하는 두 GPU 간 데이터 전송에 5번의 data copy 과정이 필요하다.
- 데이터를 source GPU에서 source 노드 내 host pinned memory buffer로 전송할 때
- 해당 데이터가 source 노드 NIC의 드라이버 버퍼에 복사될 때
- 데이터가 네트워크를 통과해 target 노드 NIC의 드라이버 버퍼로 전송될 때
- 데이터가 타깃 노드의 NIC 드라이버 버퍼에서 타깃 노드 내 host pinned memory buffer로 복사될 때
- PCIe bus를 사용해 데이터를 타깃 GPU로 복사할 때
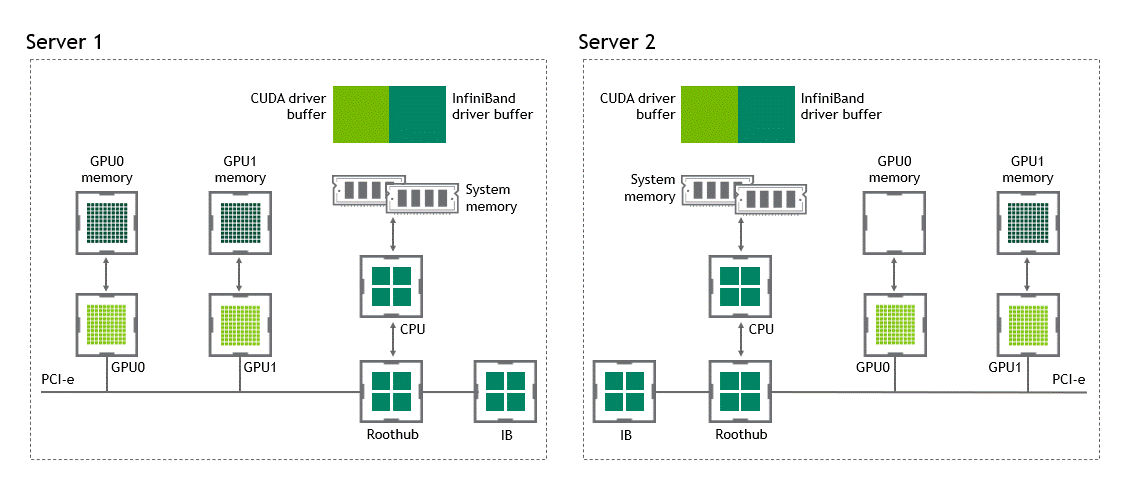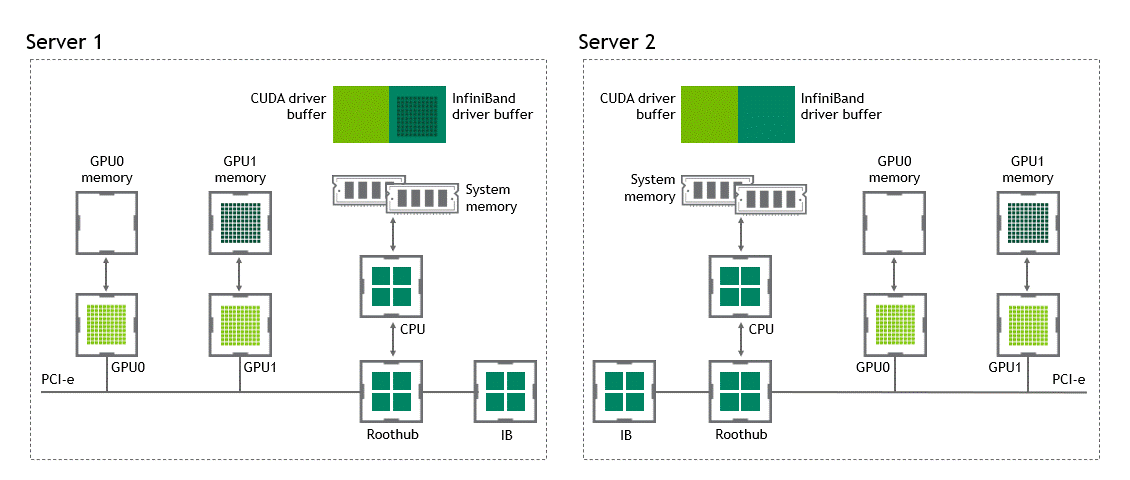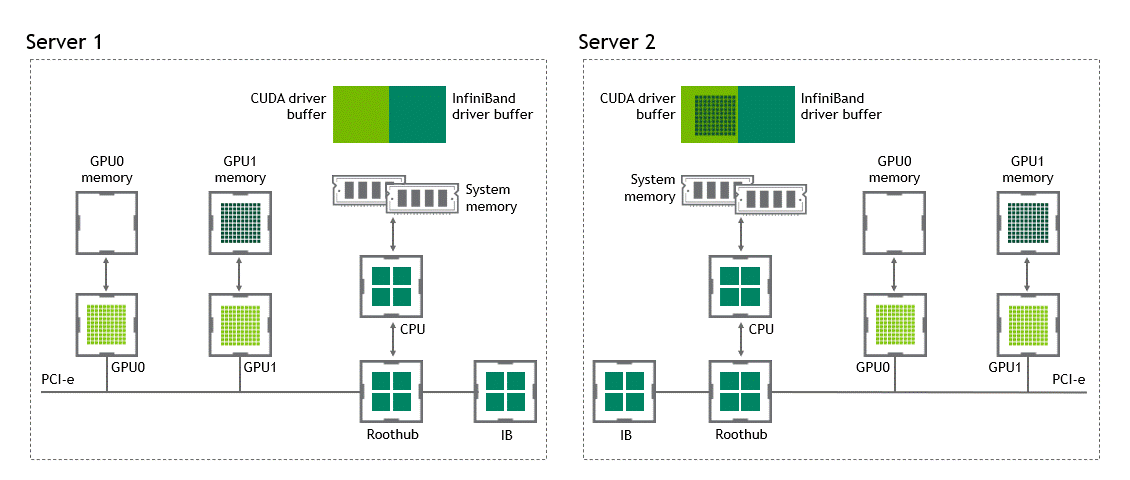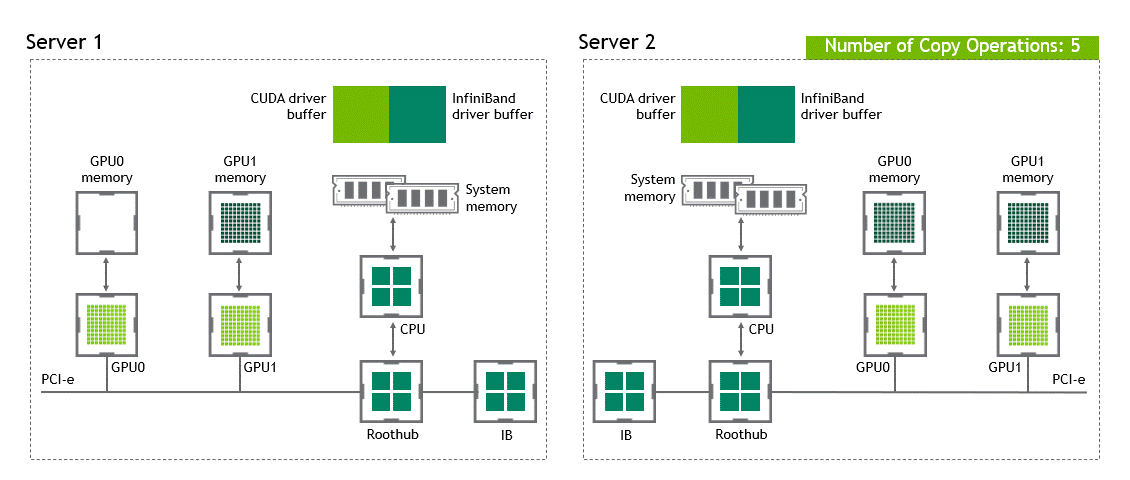
상황: 복수 노드, 복수 GPU
데이터셋 이동 경로: source GPU → host pinned memory buffer (같은 노드) → NIC의 드라이버 버퍼 (같은 노드) → NIC 드라이버 버퍼 (타깃 노드) → host pinned memory buffer (타깃 노드) → target GPU
- 첫 번째 data copy: source GPU → host pinned memory buffer (같은 노드)
- 두 번째 data copy: host pinned memory buffer (같은 노드) → NIC의 드라이버 버퍼 (같은 노드)
- 세 번째 data copy: NIC의 드라이버 버퍼 (같은 노드) → NIC 드라이버 버퍼 (타깃 노드)
- 네 번째 data copy: NIC 드라이버 버퍼 (타깃 노드) → host pinned memory buffer (타깃 노드)
- 다섯 번째: host pinned memory buffer (타깃 노드) → target GPU
참고로 그림 속 CUDA driver buffer와 InfiniBand driver buffer는 다음과 같다.
- CUDA driver buffer: CUDA 드라이버가 GPU↔Host 간 데이터 전송 시 쓰는 임시 staging 버퍼 (host-pinned)
- InfiniBand driver buffer: NIC 드라이버가 네트워크 패킷 송수신을 위해 관리하는 메모리 버퍼
GDR
GPUDirect RDMA를 사용하면 data copy 작업을 1회로 줄여준다. host pinned memroy buffer에서 data를 copy 하는 과정이 더 이상 필요 없다. 단 한 번의 실행으로 source GPU의 데이터가 타깃 GPU에 copy되므로 전통적인 워크플로우에 포함된 4번의 불필요한 data copy 과정을 생략할 수 있다.
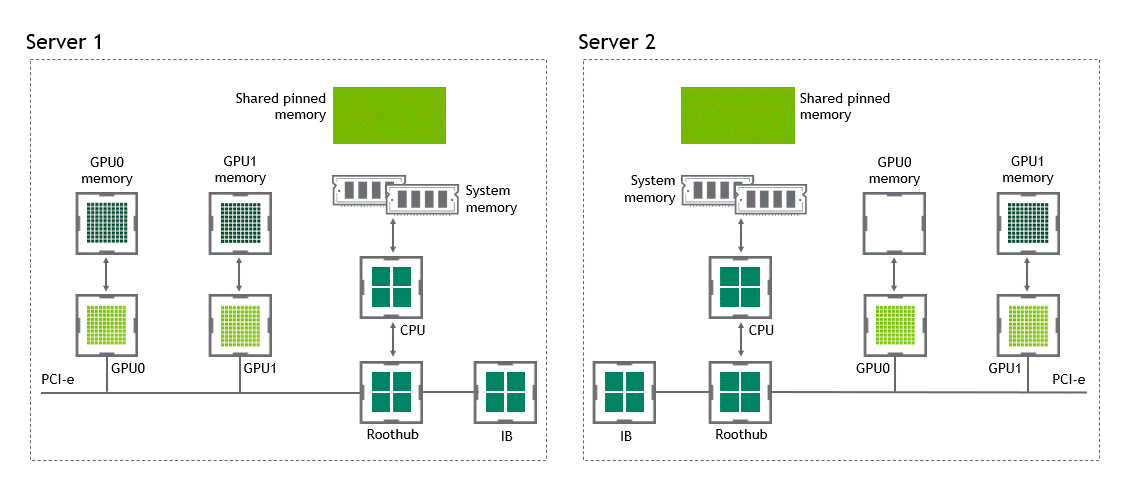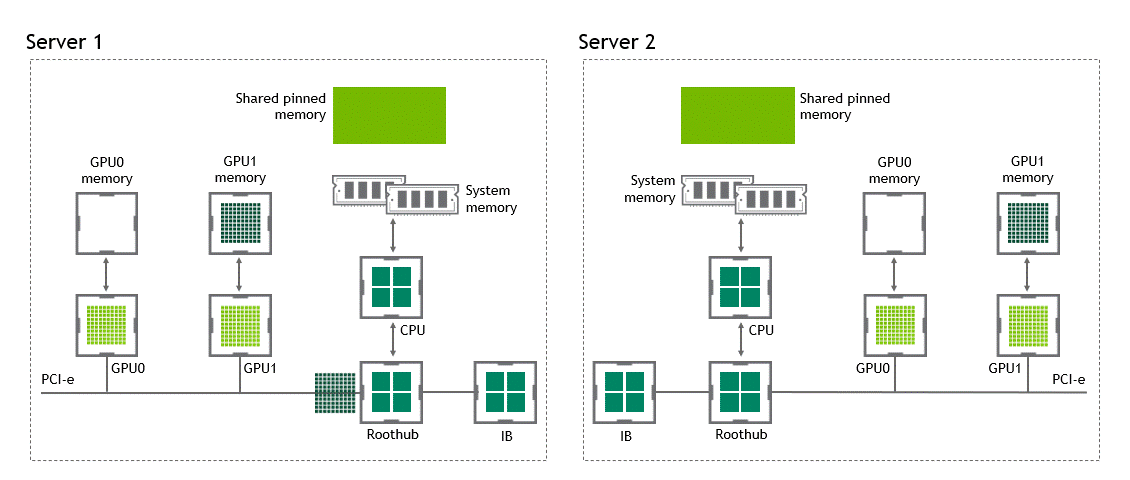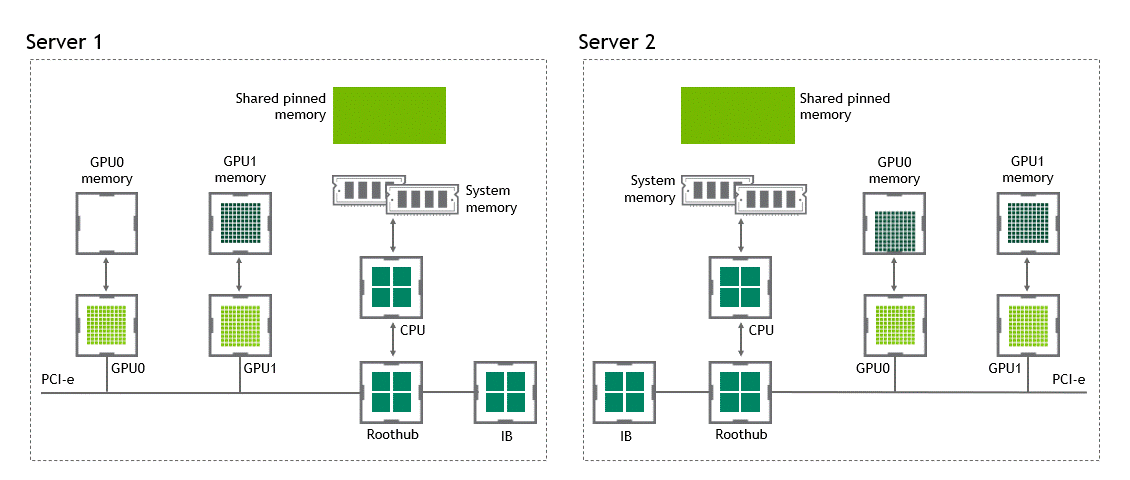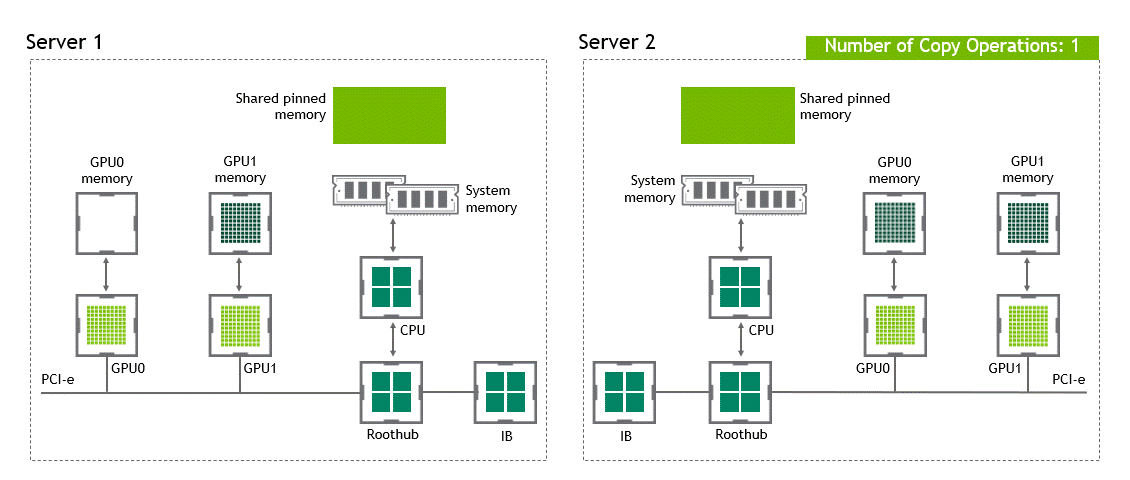
상황: 복수 노드, 복수 GPU
데이터셋 이동 경로: source GPU → target GPU
- 첫 번째 data copy: source GPU → target GPU
