Prerequisite
BAR (Base Address Register)
PCIe device가 자신의 메모리 또는 레지스터 공간을 호스트 시스템의 PCIe 메모리 주소 공간에 매핑하기 위해 사용하는 하드웨어 레지스터이다. 예를 들어, GPU VRAM의 일부를 BAR에 매핑하면, 이 주소 범위는 호스트 PCIe의 memory address space에 등록되어 다른 장치나 CPU가 이 주소로 PCIe Memory read/write transation을 보낼 경우, 요청이 GPU VRAM으로 라우팅된다.
BAR는 단순히 시작 주소만 저장하는 register이지만, 이 시작 주소는 항상 정해진 크기와 짝을 이루어 의미를 가진다. 이 크기는 하드웨어적으로 고정돼 있으며, PCIe 초기화 과정에서 os가 이를 확인한다. 따라서 'BAR 공간'이라고 하면, 해당 BAR가 시작 주소로부터 커버하는 전체 주소 범위를 의미한다.
TLP (Transaction Layer Packet)
PCIe 프로토콜에서 데이터 전송에 관한 패킷이다. TLP 헤더에는 주소, 요청 타입(read/write), 길이, 요청자 ID 등이 들어있고, write일 경우 payload가 뒤따른다. PCIe에서 CPU ↔ GPU, GPU ↔ NIC 간의 모든 메모리 접근은 결국 본질적으로 TLP 교환 과정이다.
Memory Read TLP: "이 주소에서 데이터를 읽어와라" 요청
Memory Write TLP: "이 주소에 데이터를 써라" 요청
Completion TLP: Memory read 요청에 대한 응답 데이터 P2P(Peer-to-Peer)
PCIe에서 P2P란 한 PCIe device가 다른 PCIe 장치의 BAR에 매핑된 메모리 공간에 대해, TLP를 보내어 DMA를 수행하는 것을 말한다. GPUDirect RDMA 상황을 예로 들면, NIC의 DMA 엔진이 GPU가 BAR로 노출한 VRAM 주소를 목적지로 해서 memory write TLP를 보낸다. 이 packet은 PCIe 스위치가 주소 디코딩을 통해 GPU가 매달린 downstream port로 전달하고, GPU는 해당 쓰기 요청을 받아 VRAM에 반영한다. Memory read의 경우엔 NIC이 read TLP를 보내고, GPU가 completion TLP를 보낸다. 이 전체 과정에서 호스트(CPU/RAM)의 개입은 없다.
Background
NVIDIA GPUDirect는 대규모 GPU 클러스터에서 데이터의 이동을 최적화하는 Magnum IO(GPUDirect, NCCL 등 여러 하위 기술을 묶어 제공하는 패키지 느낌)의 일부이다. GPUDirect를 사용하면 network adapter나 storage drive가 GPU에 직접 읽기/쓰기를 수행할 수 있어, 불필요한 메모리 copy나 cpu overhead를 줄일 수 있다.
기존 방식에서는 네트워크 어댑터나 스토리지 장치가 데이터를 GPU로 직접 전송하지 못했기 때문에, 장치의 DMA 엔진이 데이터를 CPU 메모리(DRAM)에 먼저 전송하고, 이후 다시 CPU 메모리에서 GPU 메모리로 복사하는 과정을 거쳐야 했다.
GPUDirect는 이런 중간 단계를 제거해 network adapter나 storage drive가 GPU 메모리에 '직접' read/write를 수행할 수 있도록 한다. 이를 통해 전반적인 처리 성능을 높일 수 있다. GPUDirect에는 GPUDirect Storage, GPUDirect RDMA, GPUDirect Peer-to-Peer, GPUDirect Video 등 여러 세부 기술이 포함돼 있으며, 각각 stroage, network, GPU 간 통신, video 장치와의 데이터 송수신을 최적화하는 역할을 한다.
GPUDirect Storage
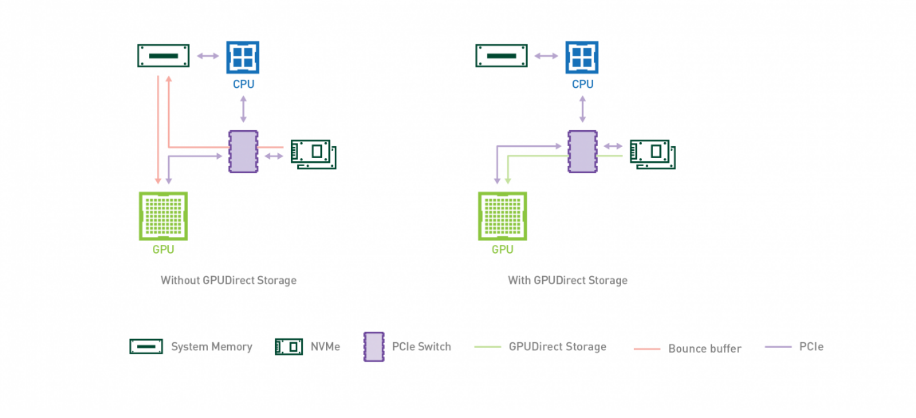
AI, HPC 등의 규모가 점점 더 커지면서, 데이터를 로딩하는 데 걸리는 시간이 application 성능에 영향을 미치기 시작했다. 즉, storage에서 GPU 메모리로 데이터를 불러오는 과정이 느려지면서 GPU 처리가 지연된 것이다.
GPUDirect Storage는 로컬 또는 원격 storage(e.g. NVMe, NVMe over Fabric)와 GPU memory 간의 direct data path를 제공한다. 즉, NIC 또는 storage의 DMA 엔진이 직접 GPU memory에 접근할 수 있으므로, CPU memory의 bouce buffer를 거쳐야 하는 불필요한 data copy를 피할 수 있다. 이 모든 과정은 CPU에 어떠한 부담도 주지 않는다.
GPUDirect RDMA
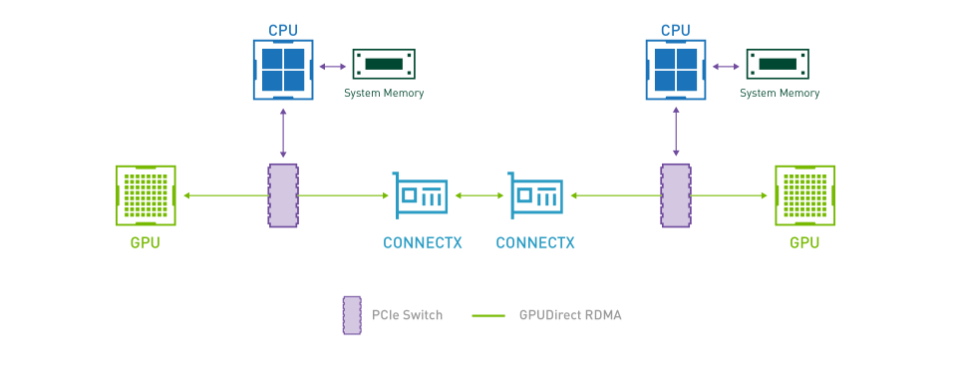
How GPUDirect RDMA Works
GPUDirect RDMA는 Kepler-class GPUs와 CUDA 5.0에 처음 도입된 기술로, PCIe를 이용하여 GPU와 또 다른 GPU, NIC, storage adpater 등 여러 device 간에 데이터를 직접 교환할 수 있는 direct path를 제공한다.
GPUDirect RDMA를 위해선, 두 device가 동일한 upstream PCI Express root complex를 공유해야 한다. root complex는 CPU, memory와 직접 연결돼 있고, PCIe로 연결된 모든 device들의 통신을 관리한다.
왜 같은 RC(Root Complex)를 공유해야 할까?
PCIe의 라우팅과 검증은 Root Complex(RC) 단위로 이루어진다. GPU와 NIC이 동일한 RC에 속해 있으면, PCIe 스위치는 목적지 주소를 기반으로 다운스트림 → 다운스트림 경로를 설정해, 한 장치가 다른 장치의 BAR(Base Address Register)에 매핑된 메모리 공간으로 직접 TLP(Transaction Layer Packet)를 전송하는 P2P(Peer-to-Peer) 트래픽을 정상적으로 포워딩할 수 있다.
Standard DMA Transfer
표준 DMA 전송은 userspace에서 시작해 kernel과 device까지 이어지는 일련의 절차로 진행된다.
- userspace program은 먼저 communication library의 API를 호출하여 전송할 데이터의 virtual address와 크기를 전달한다.
- communication library는 해당 메모리가 DMA 전송에 필요한 준비(physical page 확보, 고정, 매핑)가 되어 있는지 확인하고, 아니라면 kernel driver에 등록 요청을 보낸다.
- kernel driver는 전달받은 virtual address의 범위를 list of physical pages 변환하고, 이 physical page를 고정(pin)하여 이 page가 swap이 되지 않도록 한다.
이후 IOMMU를 통해 physical page를 device가 접근 가능한 DMA 주소로 매핑하고, device의 DMA 엔진이 이 주소들을 참조하도록 설정한다. - 설정이 끝나면 DMA 전송이 시작되며, devcie는 CPU 개입 없이 메모리에서 데이터를 읽거나 쓰는 작업을 수행한다.
- 전송이 완료되면 device가 interrupt나 polling을 통해 완료를 알리고, driver가 이를 처리한 뒤 userspace에 결과를 전달한다.
- 마지막으로 communication library나 driver는 DMA 매핑을 해제하고, 고정했던 페이지를 해제(unpin)하여 메모리 자원을 반환한다.
GPUDirect RDMA Transfers
GPUDirect RDMA를 지원하려면 기존 DMA 전송 시퀀스에 몇 가지 변경이 필요하다.
먼저, 두 가지 새로운 구성 요소가 추가된다.
- Userspace CUDA 라이브러리
- NVIDIA 커널 드라이버
CUDA를 사용하는 프로그램은 주소 공간이 CPU virtual address와 GPU virtual address로 나뉜다. 따라서 communication library는 CPU address와 GPU address를 구분해서 각각 다른 처리 경로를 구현해야 한다.
이 구분을 위해 userspace CUDA library는 communication library가 특정 address가 CPU 메모리인지 GPU 메모리인지 판별할 수 있는 함수를 제공한다. 그리고 GPU 메모리 address인 경우, 그 address가 가리키는 GPU 메모리를 고유하게 식별하기 위한 추가 메타데이터도 함께 반환한다.
Design Considerations
Lazy Unpinning Optimization
BAR에 GPU 메모리를 pin 하는 작업은 비싼 작업이며, 최대 수 밀리초까지 걸릴 수 있다. 따라서 pin/unpin을 언제 요청할지 결정하는 userspace의 application은 overhead를 최소화할 수 있도록 설계되어야 한다.
GPUDirect RDMA의 가장 직관적인 구현 방식은, 전송 전에 메모리를 pin하고, 전송이 완료된 직후 unpin하는 것이다. 하지만 데이터를 전송하기 직전, 직후마다 매번 kernel에 진입하고, 매번 수 밀리초의 overhead를 감당하는 것은 성능을 악화시킨다.
메모리 unpin을 지연시키는 방식(lazy unpinning)은 고성능 RDMA 구현이 핵심이다. 이는 전송이 끝난 후에도 메모리를 계속 pin 상태로 유지하는 것을 말하며, 동일한 메모리 영역이 재사용될 가능성이 높다는 가정을 기저에 두고 있다. 즉, 예를 들어, pin 된 메모리 영역의 set을 유지하다가, 이 set의 크기가 특정 임계값에 도달하거나 혹은 새로운 영역을 pin 하려고 했지만 BAR 공간 부족으로 인해 실패하는 경우에만, 일부 영역(e.g. 가장 오랫동안 사용되지 않은 영역)을 unpin 하는 방식이다.
Registration Cache
application이 RDMA, GPU-Direct 같은 API를 호출하면, communication middleware(MPI, UCX, libfabric 등)는 이 요청을 가로채서 registration cache를 조회한다.
RDMA와 같은 고속 데이터 전송 과정에서 매번 메모리를 pin/unpin 하면 커널 진입과 BAR 매핑 작업으로 인해 오버헤드가 크다. 이를 줄이기 위해 registration cache 또는 pin-down cache라는 optimization을 사용한다. 쉽게 말해서 이미 pin 된 메모리를 일정 기간 유지하면서 재사용하는 캐시로, 대부분 communication middleware 안에 구현돼 있다.
registration cache는 CPU 메모리를 RDMA 할 때 pin/unpin overhead를 줄이기 위해 개발된 캐시이다. 최근에는 GPU 메모리도 RDMA 대상이 되면서 기존의 register cache 개념을 GPU로 확장시켜 적용한 것이다.
이 캐시에는 lazy unpinning이나 LRU 같은 전략이 적용된다. 예를 들어, registration cache는 application의 메모리 free event를 가로채서 페이지를 바로 unpin하지 않고 pinned memory나 이와 관련된 하드웨어 자원(e.g. BAR)을 그대로 유지한다. 이후 나중에 이 메모리 영역이 reuse 되면 이미 존재하는 매핑 정보를 활용하여 불필요한 매핑 작업을 생략한다.
Synchronization and Memory Ordering
원래 GPU 메모리에 접근하는 방식은, 호스트 application이 CUDA API를 호출하고, CUDA 런타임이 NVIDIA 커널 드라이버를 거쳐 GPU 내부의 명령 처리 유닛에 명령을 전달하고, GPU 메모리 컨트롤러가 VRAM에 read/write를 수행하는 구조이다. 이 경로에서는 CUDA 런타임과 드라이버가 명령 실행 순서를 보장하고, cache invalidate(데이터 접근 시 GPU나 GPU의 캐시가 아닌 반드시 메인 메모리에 접근하도록 하는 동작)와 buffer flush(GPU나 CPU가 갖고 있는 write buffer에 남아 있는 데이터를 즉시 메모리에 쓰도록 하는 동작)를 수행한다. 즉 이 경로에서는 CUDA 런타임과 드라이버가 연산 순서, CPU↔GPU 간 올바른 데이터 복사를 관리한다.
하지만 GPUDirect를 사용하면, NIC과 같은 third-party device가 PCIe를 통해 GPU에 직접 접근하는 별도의 경로가 생긴다. 이 경로는 CUDA 런타임과 드라이버의 관리 하에 있지 않기 때문에 GPU 커널이 데이터를 모두 쓰기 전에 RDMA device가 읽어 버리거나, RDMA device가 쓴 데이터를 CUDA 커널이 캐시에 남아 있는 이전 값으로 덮어쓰는 문제가 발생할 수 있다.
따라서 GPUDirect RDMA를 사용하려면, BAR mapping 시 CUDA 드라이버가 해당 메모리 영역을 GPUDirect RDMA 대상 영역으로 인식하도록 register해야 한다. register는 CUDA 드라이버에게 이 메모리 영역을 GPUDirect RDMA용으로 관리해 달라고 알려주는 절차이다.
register는 이 메모리가 CUDA 관리 대상임을 표시만 하는 것이고, 실제로 언제/어떻게 일관성과 순서를 보장할 것인지는 GPU 작업 제출이나 동기화를 수행하는 CUDA API 호출 시점에 결정된다.
주절주절 길게 썼지만 결국 GPUDirect RDMA 과정에 CUDA 런타임을 인위적으로 개입시켜서 RDMA 과정에서 발생할 수 있는 데이터 불일치 등의 문제를 없애고 메모리 일관성을 유지하게 만드는 것이다.
How to Perfrom Specific Tasks
GPU BAR 공간 표시
CUDA 6.0부터 NVIDIA SMI 유틸리티에서 BAR1 메모리 사용량을 출력하는 기능이 생겼다. BAR1 메모리 용량이란 GPU의 BAR1에 매핑된 호스트 PCIe 주소 공간이 현재 얼마나 사용되고 있는지를 보여주는 값이다.
total은 BAR1이 커버하는 전체 크기를 의미하고, Used는 현재 pin 되어 BAR1에 매핑된 GPU 메모리의 크기, Free는 아직 매핑 가능한 남은 BAR1 크기를 의미한다.
$ nvidia-smi -q
...
BAR1 Memory Usage
Total : 256 MiB
Used : 2 MiB
Free : 254 MiB
...GPU 메모리를 pin하면 BAR1 공간에서 고정된 크기 단위로 할당된다. 즉, GPU BAR 공간은 일반적으로 64KB 페이지 단위로 매핑되므로, 만약 application이 100KB를 요청해도 실제 할당되는 크기는 64KB * 2 = 128KB가 된다. 따라서 표시되는 Total의 크기가 예상과는 다를 수 있다. 또한 BAR 공간의 일부는 driver가 사용하고자 예약하므로, GPUDirect RDMA에서 모든 메모리를 사용할 수 있는 것은 아니다.
Pinning GPU Memory
cuPointerSetAttribute(..., CU_POINTER_ATTRIBUTE_SYNC_MEMOPS)를 설정하면, 해당 메모리에 대해 수행되는 모든 CUDA API 호출이 자동으로 동기화 모드로 동작한다. 즉, 그 메모리를 대상으로 한 CUDA API는 GPU 연산이 100% 다 끝날 때까지 CPU에 control을 돌려주지 않는다.
이로써 GPU와 호스트 간, 또는 GPU와 RDMA 장치 간의 메모리 일관성과 접근 순서가 보장된다. 비동기 실행을 통한 성능 최적화는 포기하지만, 그 대신 안전하고 예측 가능한 데이터 접근이 가능해진다.
void pin_buffer(void *address, size_t size)
{
unsigned int flag = 1;
// flag: 1 == enable, flag: 0 == disable
// SYNC_MEMOPS: 해당 메모리에 대한 모든 CUDA API 호출을 동기화 모드로 강제한다는 의미
// address: 적용할 메모리 주소
CUresult status = cuPointerSetAttribute(&flag, CU_POINTER_ATTRIBUTE_SYNC_MEMOPS, address);
if (CUDA_SUCCESS == status) {
// GPU path
pass_to_kernel_driver(address, size);
} else {
// CPU path
// ...
}
}CUDA 드라이버 단계에서 필요한 처리가 끝났다면, 커널 드라이버 단계에서는 nvidia_p2p_get_pages() 함수를 호출해 RDMA에 필요한 페이지 정보를 획득한다.
BAR1 등록이 완료되면 GPU VRAM의 일부가 호스트 PCIe Memory Address Space에 노출된다. 이 영역에 대해 다른 장치(NIC, FPGA 등)나 CPU가 PCIe Memory Read/Write Transaction을 보내면, GPU PCIe 엔드포인트가 해당 요청을 받아 VRAM으로 라우팅된다고 하였다.
하지만 BAR1에 노출된 전체 범위가 항상 고정된 것은 아니다. 드라이버는 보통 필요한 부분만 순간적으로 매핑하고 해제할 수 있으므로 매핑 정보는 언제든 변경될 수 있다. 그렇기 때문에 RDMA 장치는 해당 주소가 현재도 유효한지 알 수 없으며, 해당 주소가 실제로 어떤 VRAM 물리 페이지를 가리키는지 모른다.
이를 해결하기 위해 nvidia_p2p_get_pages()를 호출한다. 이 함수는 요청된 GPU virtual address가 현재 어떤 VRAM 물리 페이지에 매핑되어 있는지 확인하고, 해당 페이지를 pin 처리해 재매핑이나 교체가 되지 않도록 잠근다. 그리고 해당 페이지의 PCIe Bus Address(RDMA 장치가 직접 접근 가능한 주소)를 반환하여 RDMA 장치는 GPU 메모리에 안전하고 일관되게 접근할 수 있게 한다.
// for boundary alignment requirement
#define GPU_BOUND_SHIFT 16
#define GPU_BOUND_SIZE ((u64)1 << GPU_BOUND_SHIFT) // 64
#define GPU_BOUND_OFFSET (GPU_BOUND_SIZE-1) // 한 페이지 내부에서 가장 큰 offset
#define GPU_BOUND_MASK (~GPU_BOUND_OFFSET)
struct kmd_state {
nvidia_p2p_page_table_t *page_table;
// ...
};
void kmd_pin_memory(struct kmd_state *my_state, void *address, size_t size)
{
// do proper alignment, as required by NVIDIA kernel driver
// start address를 64의 배수로 만듦, 가까운 64 배수로 내림
u64 virt_start = address & GPU_BOUND_MASK;
// end address를 가까운 64 배수로 올림
size_t pin_size = (address + size - virt_start + GPU_BOUND_SIZE - 1) & GPU_BOUND_MASK;
if (!size)
return -EINVAL;
// my_state->page_table에 RDMA device가 PCIe Memory read/write 할 수 있는 주소가 저장됨
int ret = nvidia_p2p_get_pages(0, 0, virt_start, pin_size, &my_state->page_table, free_callback, &my_state);
if (ret == 0) {
// Succesfully pinned, page_table can be accessed
} else {
// Pinning failed
}
}GPUDirect RDMA에 대해 집중적으로 정리해 보았다. GPUDirect RDMA는 PCIe를 이용하여 GPU와 또 다른 GPU, NIC 등 간에 데이터를 직접 교환할 수 있는 path를 제공하는 기술이었다. 기존과 달린 direct path를 제공하므로 RC, synchronization 등 고려해야 할 다른 점들이 생겨났다.
여전히 패킷을 주고받는 과정이다.
BAR 개념이 나오면서, 이건 third party devcie가 physical address를 알아내어 '직접' 접근하는 과정인가? 헷갈렸는데 그렇지 않다. 여전히 NIC이 패킷을 만들 때, 그 패킷의 header 영역에 알아낸 PCIe bus address를 기입하고, payload 영역에 GPU VRAM에 실제 쓸 데이터를 넣는 과정이 진행된다. 이렇게 만든 패킷을 전송하는 것뿐이다.
참고 자료
https://developer.nvidia.com/gpudirect
https://docs.nvidia.com/cuda/gpudirect-rdma/index.html#lazy-unpinning-optimization
