YOLOv3: An Incremental Improvement
https://arxiv.org/abs/1804.02767
1. Introduction
- managed to make some imporvements to YOLO
- nothing like super interesting, just a bunch of small changes that make it better
2. The Deal
2.1. Bounding Box Prediction
- predicts bounding boxes using dimension clusters as anchor box
- predicts 4 coordinates for each bbox
- predicts an objectness score for each bbox using logistic regression
- should be 1 if the bbox overlaps a ground truth object by more than any other things
- overlap a ground truth object by more than some threshold -> ignore
- only assign one bounding box prior for each ground truth object
YOLOv2처럼 각 bounding box의 상대적인 좌표 4개와 objectness score를 계산하되, YOLOv3에서는 objectness score를 logistic regression을 이용하여 계산한다. 즉, 각 ground truth마다 IoU가 가장 높은 하나의 bounding box만 남고, 그 box의 objectness score는 1로 설정되며 나머지 box들은 학습에 사용되지 않는다.
2.2. Class Prediction
- bbox may contain using multilabel classification
-> use independent logistic classifiers (not softmax) also use binary cross-entropy loss during training
이러한 방식은 overlapping labels(object가 Woman이자 Person인 경우)가 많은 Open Images Dataset에 적합하다고 한다.
2.3. Predictions Across Scales
- YOLOv3 predicts boxes at 3 different scales
- predict 3 boxes at each scale
- so the tensor is X X
- 4 bbox offsets, 1 objectness prediction, 80 class predictions
다음 내용은 아래 사이트를 참고하여 작성한 내용이다.
https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b
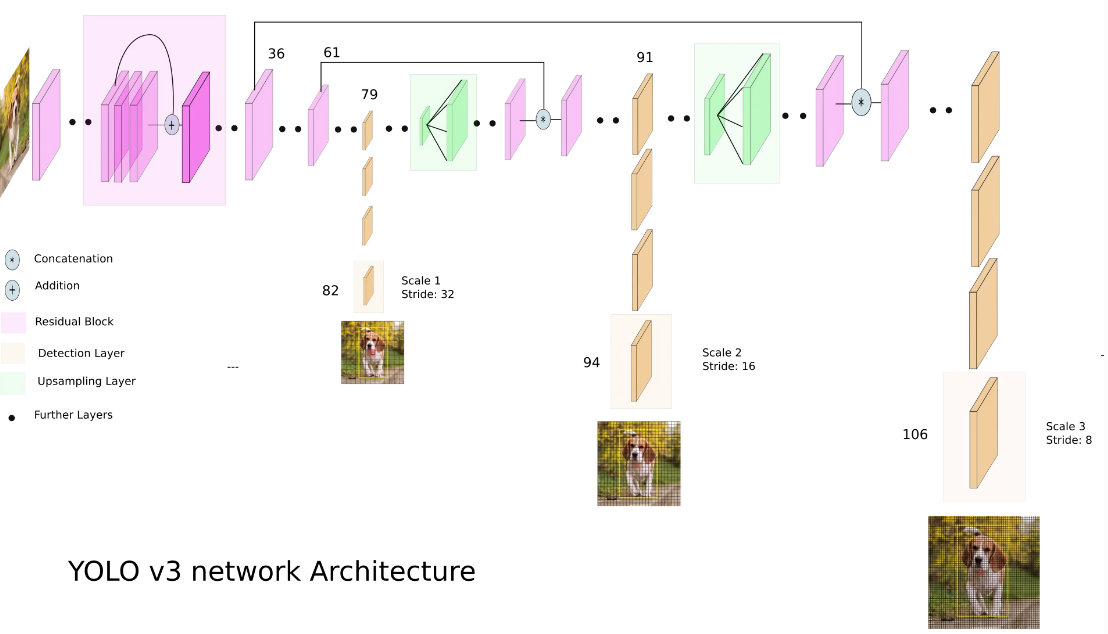
- the detections is done by applying 1 x 1 detection kernels on feature maps of three different sizes at three different places in ther network
- Predictions are precisely given by downsampling the dimensions of the input image by 32, 16 and 8 respectively
- first detection is made by the 82nd layer. For the first 81 layers, the image is down sampled by the network, such that the 81st layer has a stride of 32. If we have an image of 416 x 416, the resultant feature map would be of size 13 x 13.
- downsampling 이후 82번째 layer에 detection 수행
- 큰 물체를 탐지하는 데 사용
- then the feature map from layer 79 is subjected to a few convolutional layers before being up smapled by 2x to dimensions of 26x26.
- 79번째 layer에서 upsampling
- get meaningful semantic information
- this feature map is then depth concatenated with the feature map from layer 61.
- 2단계 전의 feature map과 concat
- get finer-grained information (which help in detecting small objects)
- then the combined feature maps is again subjected a few 1 x 1 convolutional layers
- fuse the features from earlier layer (61).
- a similar procecure is followed again
- Detections at different layers help address the issue of detecting small objects, a frequent complaint with YOLOv2.
- Each layer is responsible for detecting particular objects
- 13x13 layer -> large objects
- 26x26 layer -> medium obejcts
- 52x52 layer -> smaller objects
- YOLO v3 predicts more bounding boxes than YOLOv2 which could easily understand why it's slower than YOLOv2
- input image: 416x416
- YOLOv2: 13 x 13 x 5 = 845
- YOLOv3: (13 x 13 x 3) + (26 x 26 x 3) + (52 x 52 x 3) = 10,647
2.4. Feature Extractor
다음 내용은 아래 사이트를 참고하여 작성한 내용이다.
https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b
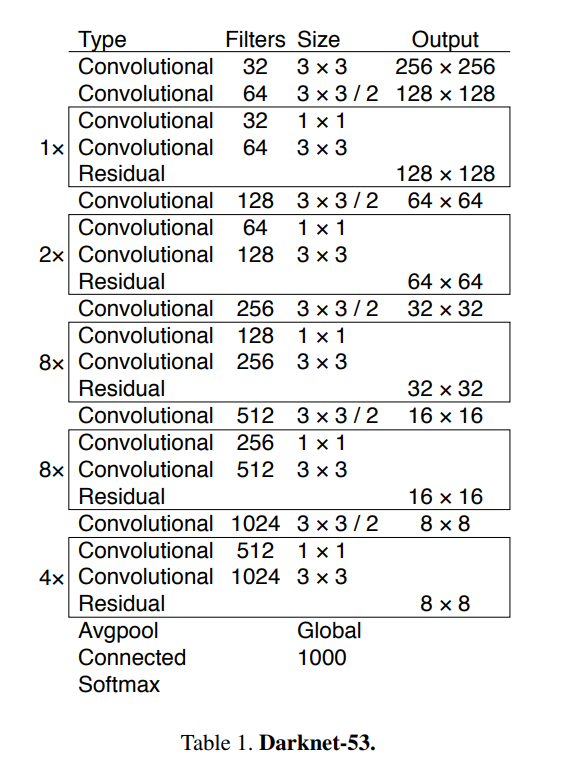
- YOLOv3 uses a variant of Darknet, which originally has 53 network trained on Imagenet. For the task of detection, 53 more layers are stacked onto it, giving us a 106 layer fully convolutional underlying architecture for YOLO v3.
- YOLOv2's architecture has no residual blocks, no skip connections and no upsampling. YOLOv3 incorportates all of these.
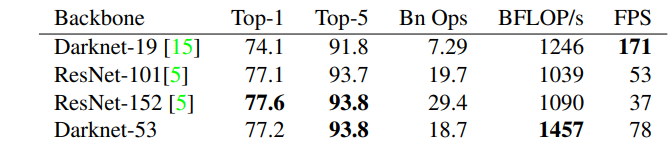
- This new network is much more powerful than Darknet-19 but still more efficient than ResNet-101 or ResNet-152.
- 18.7 Bn Ops: 18.7억 번의 연산을 수행
- BFLOP/s: Billion Floating Point Operations, 컴퓨터가 초당 수행할 수 있는 부동 소수점 연산 수
- 확실히 Darknet-19에 비해 연산량은 많아지고, 속도가 느려진 것을 알 수 있다. 다만 BFLOP/s를 봤을 때, Darknet-53의 network structure가 다른 network에 비해 GPU를 매우 잘 utilize한다는 것을 알 수 있다.
2.5. Training
- still train on full images with no hard negative mining
- YOLOv3의 background class를 사용하지 않고 objectness score를 통해 bbox를 filtering 방식은 hard negative mining의 필요성을 줄여줌
3. How We Do
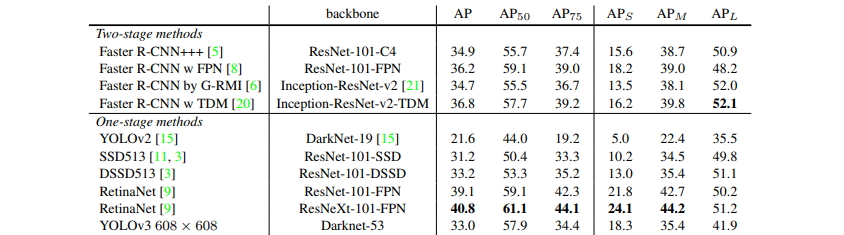
- Performance drops significantly as the IOU threshold increses indicating YOLOv3 struggles to get the boxes perfectly aligned with the object
- comparatively worse performance on medium and larger size objects
- 은 IOU threshold를 0.5한 경우
- 는 Small size, M은 Medium, L은 Large
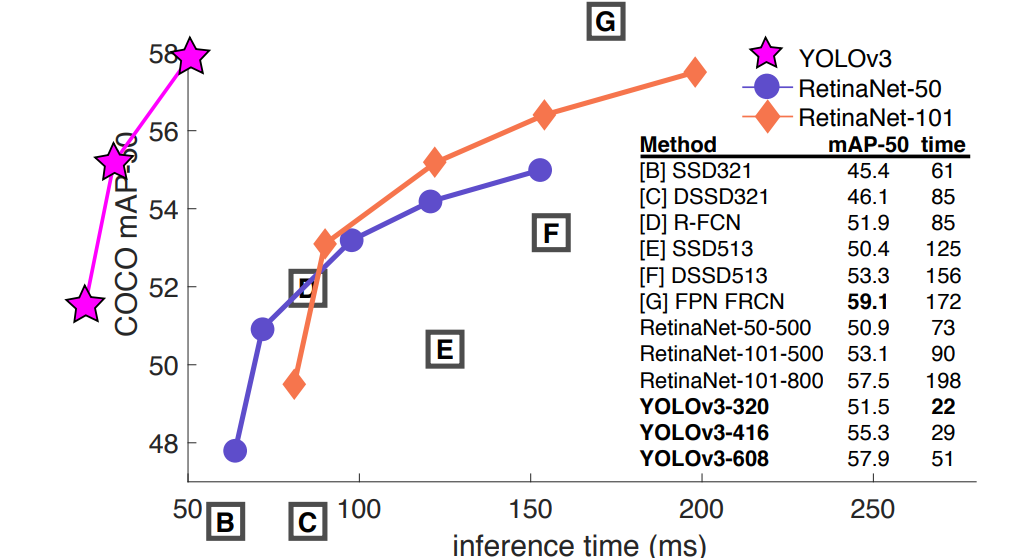
- mAP 값을 .5 IOU metric으로 계산했을 때 speed/accuracy tradeoff를 나타낸 지표이다.
- 확실히 YOLOv3이 짧은 inference time으로 RetinaNet 모델들과 비슷한 mAP에 도달하는 것을 확인할 수 있다.
4. Things We Tried That Didn't Work
Anchor box offset predictions.
- linear activation을 이용하여 bbox의 offset을 anchor box의 width와 height의 multiple로 나타내려고 했지만 model stability로 이어짐
Linear predictions instead of logistic.
- offset을 logistic activation이 아니라 linear activation으로 직접 나타내려고 했지만, mAP만 감소를 초래함
Facal loss.
- Focal loss는 foreground와 background 케이스 비율 차이를 개선하기 위해 각 클래스의 loss에 weight를 곱하여 loss 값을 조절하는 방식이다.
- YOLOv3 may already be robust to the problem focal loss is trying to solve due to separate objectness predictions and conditional class predictions
Dual IOU thresholds and truth assignments.
- Faster R-CNN은 two IOU thresholds를 사용한다. 다음과 같은 방식이다.
- overlap the ground truth by : positive
- [.3 - .7] : ignore
- : negative
- YOLOv3에서 동일한 방식을 적용하려고 했으나 좋은 결과가 나오지 않았다.
느낀 점
실전! 프로젝트로 배우는 딥러닝 컴퓨터 비전을 읽던 중 직접 논문을 살펴볼 필요성을 느껴서 찾아보게 되었다.
논문을 읽으며 기억에 남는 점은, YOLOv3은 upsampling을 추가해 의미 있는 semantic information을 얻고 이전 layer와 concat하여 finer-grained information을 얻음으로써 YOLOv2의 한계를 극복해 보고자 했다는 것이다. 다만 이제는 medium이나 large object에 대한 performance가 안 좋아졌다는 게 의외였다. 부족한 지식으로 고민해 봤을 때, 규모가 어느 정도 있는 object에 대해서는 small object만큼 정보가 없어도 충분히 detect 할 수 있는데 오히려 서로 다른 scale에서 detect 해낸 정보들이 쌓이며 큰 object에 대한 detect를 방해하는 건가? 싶었다. 좀 더 지식을 쌓고 나서 다시 돌아와 위 의견의 타당성을 판단해 봐야겠다.
앞서 YOLO와 YOLO9000에 대해 읽고 YOLOv3을 읽으니, 이해가 더 잘 되었다. network architecture 부분을 읽을 땐 좀 어렵게 느껴지긴 했으나 다른 자료를 찾아보니 이해할 수 있었다. 영어로 쓰인 논문을 읽었을 때 이해가 안 되었어서 이 자료를 읽어도 이해하지 못하면 어떡하지 같은 걱정이 있었는데, 같은 내용을 다른 영어 표현으로 나타낸 것만으로도 이해도가 달라질 수 있구나 싶었다.
