YOLO9000: Better, Faster, Stronger
https://arxiv.org/pdf/1612.08242
Abstract
먼저 저자들은 YOLO에서 발전된 모델인 YOLOv2를 소개한다. 이후 object detection과 classification을 jointly하게 train 하는 방식을 소개하고, 이 방식이 적용된 YOLO9000을 소개한다. 이 YOLO9000은 9000개가 넘는 obejct categories를 detect할 수 있는 real-time object detection system이다.

1. Introduction
당시 대부분의 detection method는 small set of objects에 대해 여전히 잘 detect하지 못한다는 문제가 있었다. 또한 당시 object detection dataset은 classification이나 tagging dataset에 비해 그 수가 제한적이었다. 저자들 또한 labelling된 detection image dataset을 구하고 싶었으나, 다른 분야에 비해 그 비용이 많이 든다는 점이 문제였다. 따라서 저자들은 새로운 방식을 제안한다. 이미 갖고 있는 상당한 양의 classification data를 detection system에 활용하는 것이다. 또한 object detectors를 detection 분야뿐만 아니라 classification data에 대해서도 train시키는 joint training algorithm을 제안한다. 이러한 두 방식을 활용하여 9000개가 넘는 categories를 분류할 수 있는 YOLO9000을 훈련시킨다.
2. Better
YOLO의 단점은 상당한 수의 localization error를 발생시킨다는 것이다. 게다가 YOLO는 region proposal-based methods와 비교하였을 때 비교적 낮은 recall을 보인다. 따라서 저자들은 recall과 localization을 향상시키면서 classification accuracy는 유지할 수 있는 방법을 도입하였다.
Batch Normalization
Batch Normalization은 수렴 속도에 상당한 개선을 가져오며, 다른 형태의 regularization이 필요 없게 만든다. 저자들도 batch normalization을 추가함으로써 dropout을 제외시켰다. YOLO에 있는 모든 convolutional layer에 batch normalization을 추가함으로써 2%의 mAP 향상을 얻을 수 있었다.
High Resolution Classifier
original YOLO에서는 classifier network를 224 x 224 크기의 image를 활용하여 훈련시키고, detection 과정에서 이미지의 resolution을 448로 증가시켰다. 저자들은 이 과정에서 network가 object detection을 학습하는 동시에 새로운 입력 resolution에도 적응해야 하므로 network에 추가적인 load가 발생한다고 설명했다. 따라서 YOLOv2에서는 classfication network를 처음 fine tuning할 때 10 epochs 동안은 448 x 448 크기의 ImageNet dataset을 활용하여 학습한다. 그런 다음에 detection을 수행한다. 이 high resolution classification network는 거의 4%의 mAP 향상을 이뤘다.
Convolutional WIth Anchor Boxes
YOLO는 convolutional feature extractor 제일 위에 있는 fully connected layer를 활용하여 bounding box의 좌표를 직접 예측한다. 반면 Faster R-CNN 방식은 오직 convolutional layer만을 활용하여 anchor box의 offset과 confidence를 예측한다. 이 offset을 예측하는 방식은 좌표를 직접 예측하는 것보다 문제를 더 쉽게 만들고 network가 학습하기에도 더 쉽다.
따라서 저자들은 YOLO에서 fully connected layer를 제거했다. 또한 network를 448 X 448 크기의 image로 학습시키는 게 아니라 416 X 416 이미지를 통해 학습시켰다. 이는 feature map의 크기를 홀수로 만들어 single center cell을 만들기 위함이다. YOLO의 output feature map의 크기는 input image의 크기를 32로 나눈 값인데 448 X 448 크기를 input으로 사용하면 output feature map의 크기가 14 X 14가 된다. 14 X 14 크기의 feature map에는 center cell이 없기 때문에 object의 중심을 보려면 4개의 cell을 참고해야 한다. 반면 416 X 416 크기의 image를 사용하면 output feature map의 크기가 13 X 13이 되어 object의 중심을 볼 때 가운데 cell 1개만 참고하면 된다. object는, 특히 크기가 큰 object들은 보통 image의 가운데에 위치하는 경우가 많은데 이럴 때 4개의 cell을 보는 것보다 1개의 cell만을 보는 것이 훨씬 좋다.
두 번째로 bounding box를 예측하기 위해 anchor box를 사용한다. 그러면서 자연스럽게 class prediction mechanism이 spatial location로부터 분리되었다. 즉, 모델이 특정 위치에 객체가 어떤 클래스에 속하는지 동시에 예측하는 것이 아니라 객체의 위치와 상관없이 모델은 이 anchor box가 어떤 클래스에 속하는지, 이 anchor box가 실체 객체를 포함하는지를 예측한다. (objectness를 평가할 땐 YOLO와 마찬가지로 ground truth와의 IOU 값을 계산한다.)
anchor box를 사용함으로써 mAP는 조금 떨어졌지만 recall 값이 81%에서 88%로 향상하였다. 이 recall 값이 높아졌다는 말은 모델이 더 많은 실제 객체를 정확하게 탐지하고 있다는 것을 나타냄과 동시에 더 나은 성능을 위해 추가적인 개선이 가능하다는 것을 시사한다.
Dimension Clusters
저자들은 hand picked anchor boxes를 사용하는 것이 아니라, training set에 대해 k-means clustering을 활용하여 좋은 prior를 찾으려고 했다. 이때 사용된 방식은 Euclidean distance를 활용한 k-means clustering이 아니라 IOU score를 활용한 k-means clustering 방식이다. 큰 box의 경우, 실제로 작은 위치 차이(예: 몇 픽셀)가 전체 box의 의미 있는 변화로 이어지지 않을 수 있다. 하지만 Euclidean distance는 이 작은 차이를 절대적인 거리로 계산하기 때문에 큰 box일수록 상대적으로 작은 차이가 더 큰 오류로 해석될 수 있다. 이는 큰 box에 대해 Euclidean distance가 적절하지 않을 수 있는 이유 중 하나이다. 이렇듯 larger boxes는 smaller boxes보다 더 많은 오류를 발생시키므로 저자들은 box size와는 독립적인 값인 IOU score를 활용했다. 그 distance metric은 아래와 같다. 이 식의 의미는 IOU 값이 높은 box끼리 묶겠다는 의미이다.
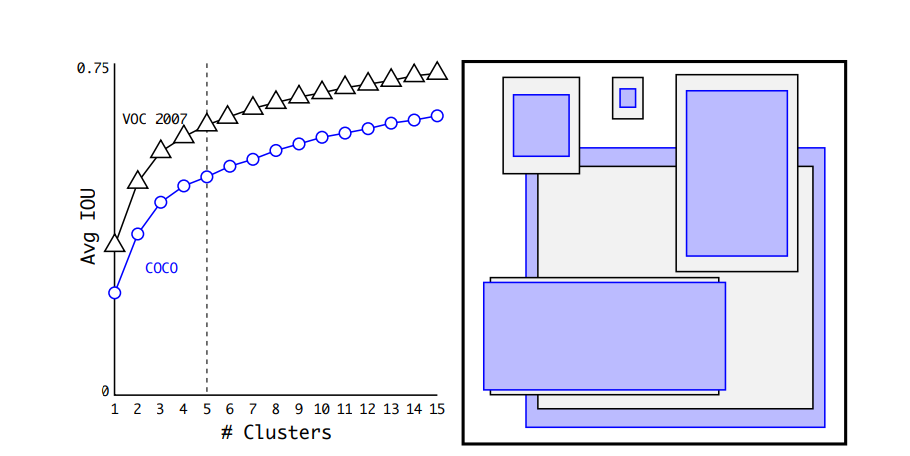
왼쪽 사진은 k 값에 따른 Avg IOU를 나타내고, 오른쪽 사진은 thinner 하고 taller한 prior들이 선호됨을 나타낸다.
저자들은 model complexity와 high recall 사이의 tradeoff를 고려하여 k의 값을 5를 설정했다. 아래의 표는 다른 clustering method와 hand-picked anchor box를 활용한 방식의 Avg IOU 값을 나타낸다. k를 5로 설정했을 때의 Cluster IOU의 Avg IOU 값이 9개의 hand-picked anchor box를 활용한 Avg IOU 값과 별 차이가 없다는 걸 확인할 수 있다.
Direct location prediction
YOLO에 anchor box를 활용했을 때의 또 다른 문제점은 초기 iteration 동안의 model instability이다. 대부분의 instability는 box의 값을 예측하는 데에서 비롯된다. 반면 region proposal network에서는 값을 예측한다. 는 anchor box의 중심에서 x축 방향으로 얼마나 이동해야 하는지를 나타내는 값이다. 예를 들어 가 1이라는 건, 예측 상자가 anchor box의 너비만큼 오른쪽으로 이동하라는 것을 의미한다.
이처럼 region proposal network는 이 anchor box를 기반으로 새로운 객체가 발견된 곳으로 상자를 이동시키고, 크기를 조정하여 최종 예측 박스를 생성한다.
YOLOv2도 coordinate이 아닌 offset를 예측한다. 앞서 언급했듯 offset을 예측하는 것이 coordinates를 예측하는 것보다 더 쉽기 때문이다.
다만 이 공식은 predicted box가 반드시 현재 위치 근처에 있어야 하는 제약이 없다. 그래서 모델이 처음에는 box를 이미지 내 아무 위치로도 이동시킬 수 있어, predicted box가 제자리를 찾는 과정에서 시간이 오래 걸리게 되고 불안정적이다. 따라서 저자들은 anchor box가 특정 범위를 벗어나지 않도록 제약을 걸어 모델이 너무 먼 위치로 box를 이동시키는 문제를 방지했다.
먼저 network는 output feature map의 각 cell마다 5개의 bounding box를 예측한다. 그리고 각 bounding box에 대해 다음 5개의 coordinates: 를 예측한다. 각각은 box의 중심 좌표(x, y)의 offset, box의 너비와 높이, box 안에 객체가 존재할 확률을 나타낸다. 다음으로 모델은 특정 좌표에 있는 객체를 예측하기 위해, 각 셀에서의 bounding box 좌표를 anchor box로부터의 상대적인 값으로 계산한다. 좌표 계산을 좀 더 자세히 살펴보자
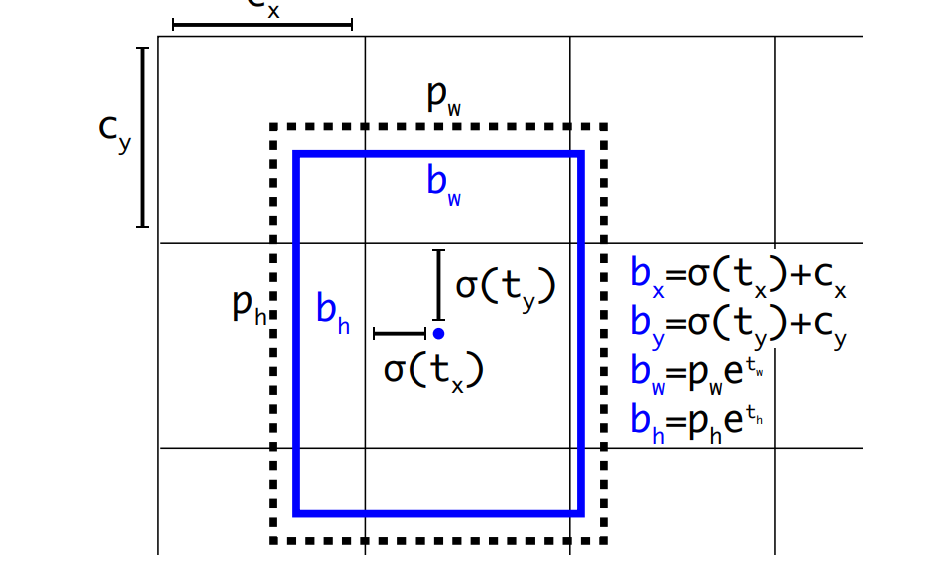
-
중심 좌표
여기서 는 sigmoid 함수를 적용함으로써 의 값을 0~1 사이의 값으로 제한한다. 이를 통해 예측된 중심 좌표가, 그 좌표가 속한 cell을 벗어나지 못하도록 한다.
-
width, height
bounding box의 weight와 height 또한 anchor box의 에 대한 상대적은 크기로 예측된다. 모델은 를 예측하며 이를 통해 anchor box의 크기를 조정할 수 있다.
여기서 와 는 지수 함수(exponential function)를 적용해, 모델이 예측한 값이 음수라도 박스의 크기를 양수로 만들 수 있도록 한다. 즉, 너비와 높이가 anchor box의 크기를 기반으로 지수적 비율로 조정됨을 의미한다. -
object 존재 확률
는 해당 bbox 안에 객체가 존재할 확률을 나타낸다. 이 값 또한 sigmoid 함수로 제한되어 0~1 사이의 값을 갖게 된다.
이처럼 저자들은 location prediction에 제한을 두어 모델이 보다 쉽게 정확한 좌표값을 학습할 수 있게 만들었고 network 또한 더 stable해졌다.
여기까지 anchor box를 활용한 내용을 정리해 보자면, YOLOv2에서는 K-means clustering을 사용하여 anchor box들을 정의하고, 각 셀마다 5개의 anchor box를 생성한다. 모델은 이 anchor box들에 대해 각각 bounding box 좌표와 크기를 예측하고, 객체 존재 확률 도 예측한다. 최종적으로는 이 5개의 bounding box 중에서 객체 존재 확률 가 가장 높은 박스를 최종 bounding box로 사용한다.
Fine-Grained Features
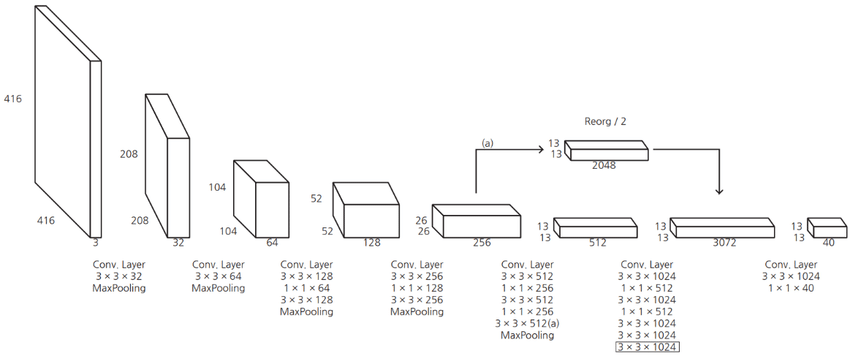
modified YOLO는 13 X 13 feature map을 예측한다. 이 크기는 large objects를 detect 하기엔 충분하지만 small objects를 탐지하기 위해선 보다 finer grained features가 필요할 수 있다. 따라서 저자들은 passthrough layer를 추가하여 26 X 26 X 512 feature map을 13 X 13 X 2048 feature map에 concat시켰다. 이렇게 함으로써 higher resolution feature와 lower resolution feature를 모두 가져갈 수 있다.
Multi-Scale Training
이 YOLOv2 모델은 오직 convolutional layer와 pooling layer만을 사용하기 때문에 다양한 size의 input을 처리할 수 있다. 따라서 저자들은 다양한 학습을 위해 10번의 배치마다 학습 데이터는 {320, 352, ..., 608}의 크기로 randomly resize 된다.
Further Experiments
저자들은 YOLOv2를 VOC2012 dataset을 이용하여 train시켰다. 다음은 YOLOv2와 다른 state-of-the-art detection systems의 성능을 비교한 결과이다. 다양한 resolution에 대해서 다른 detection methods에 비해 빠르고 정확한 것을 알 수 있다.
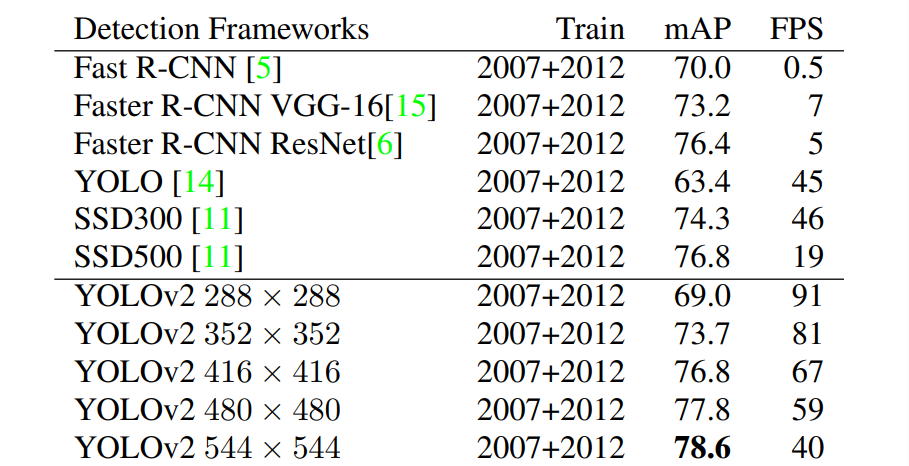
여태까지의 성능 개선을 살펴보면 아래와 같다.

3. Faster
저자들은 detection 과정이 정확하고 빠르길 바란다. 대부분의 detection framework는 VGG-16을 base feature extractor로 사용한다. VGG-16은 강력하고 정확하지만 말할 필요도 없이 복잡하다. 따라서 YOLO framework는 Googlenet architecture를 base로 하는 custom network를 사용한다. 그러나 이 network는 VGG-16과 비교했을 때 빠르긴 하지만 정확도가 조금 떨어진다. 따라서 저자들은 새로운 classification model, Darknet-19를 제안한다.
Darknet-19
Darknet-19는 19개의 convolutional layer와 5개의 maxpooling layer로 구성돼 있다. model 구조를 보면 VGG 모델과 유사하게 대부분 3 X 3 filter를 쓴 것을 알 수 있다. 또한 NIN 연구에 따라, global average pooling을 사용함으로써 계산되는 parameters 수를 확 줄이고 3 X 3 convolutions 사이에 1 X 1 filter를 사용함으로써 bottleneck 구조를 형성한 것을 알 수 있다.
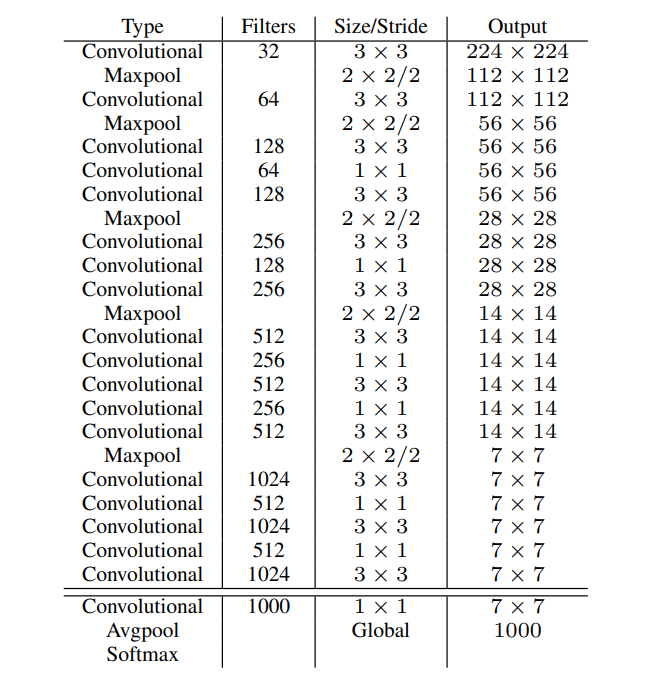
Training for classification
저자들은 network를 standard ImageNet에 대해 학습시켰다. 이 과정에서 stochastic gradient descent, polynomial rate decay, momentum 값을 설정해서 활용하였다. 또한 data augmentation도 사용하였다. 마지막으로 앞에서 언급했듯, 224 X 224 images에 대해 초기 학습을 시키고, fine tuning 과정에서는 448 X 448 images를 이용하였다. 저자들은 이 과정을 거치며 top-1 accuracy 76.5%와 top-5 accuracy 93.3%를 달성했다. (top-n accuracy는 모델이 예측한 상위 n개의 클래스 중 하나라도 실제 class와 일치하는 비율이다.)
Training for detection
앞에서 언급했듯 저자들은 detection 수행을 위해 마지막 convolutional layer를 제거하고 3 X 3 convolutional layer를 추가했다. 또 1x1 convolutional layer를 추가하여, 각 셀에서 5개의 anchor box에 대한 예측값(와 20개의 클래스 확률)을 동시에 출력한다. 따라서 최종 1 X 1 convolutional layer에서는 각 anchor box마다 예측해야 하는 25개의 값(좌표 5개 + 클래스 확률 20개) × 5개의 anchor box = 125개의 filter가 필요하다.
또 앞서서 fine grain feature를 위해 passthrough layer를 추가시킨 걸 잊지 말자. 저자들은 이러한 network를 학습률 부터 시작하여 60과 90 epoch에 10씩 감소시키며 총 160 epoch 동안 학습시켰다.
논문에는 없지만 여태까지의 모델 구조를 시각적으로 잘 나타낸 그림 같아서 가져왔다.
https://wikidocs.net/167664
4. Stronger
저자들은 detection images와 classification images를 섞어서 사용한다. 따라서 network에 input으로 detection image가 들어오면 full YOLOv2 loss function에 따라 오차를 역전파시키고, classification image가 들어오면 오차를 오직 classification-specific한 part에만 전파시킨다.
이러한 방식에는 몇몇 어려움이 있다. 먼저 Detecction dataset(ex. COCO)에는 오직 common objects와 general labels(ex. dog)만 있지만, classification dataset(ex. ImageNet)은 훨씬 범위가 세세하고 넓다(ex. Norfolk terrier, Yorkshire terrier). 이 차이점을 해결해야 두 dataset을 합쳐서 train 할 수 있다.
또한 대부분의 classification에서는 softmax를 사용하는데, softmax는 class들이 상호 배타적이라고 암묵적으로 가정한다. 즉 "cat", "dog" 같이 서로 완전히 구별되는 class들이 있을 것이라고 가정한다. 그러나 ImageNet dataset과 COCO dataset을 합치면, class들이 서로 배타적이지 않다. 예를 들어, "dog"과 "Norfok terrier"처럼 말이다.
Hierarchical classification
ImageNet label들은 WordNet을 기반으로 하는데, 이 Wordnet은 tree 구조가 아닌 directed graph 구조이다. tree 구조로는 나타낼 수 없는 이유가, 에를 들어 "dog"는 "canine"의 한 종류이기도 하지만, "domestic animal"의 한 종류이기도 하기 때문이다. 즉, root node(여기서는 "physical object")로 가는 길이 여러 개일 수 있다. 따라서 저자들은 root node로 가는 여러 path 중 가장 짧은 길이의 path만을 선택했다.
그런 다음 만약 어떤 특정 node에 대해 absolute probability를 계산하고 싶다면, 그 node에서 root node까지의 path를 따라가며 conditional probabilities를 계산한다. 예를 들어, Norfolk terrier를 계산하고 싶다면 아래와 같이 계산하면 된다
()
이런 방식으로 구축된 WordTree1k는 ImageNet의 1000개의 클래스만 사용하는 것이 아니라 그 사이에 존재하는 중간 계층의 노드들도 포함시킴으로써 라벨을 1369개로 확장시켰다.
Training 과정에서는 하위 개념의 label을 상위 개념까지 전파한다. 예를 들어 어떤 이미지가 "Norfolk terrier"로 labelling 되었으면 그 image는 "dog"와 "mammal"로도 자동으로 labelling된다. 이렇게 하면 "Norfolk terrier"라는 세부적인 클래스에 대한 이미지가 적더라도 "dog"나 "mammal"라는 상위 개념을 통해 좀 더 많이 학습할 수 있다.
conditional probability를 계산하기 위해서는 같은 상위 개념을 공유하는 하위 개념들 간의 확률을 계산한다. 예를 들어, 모델은 이미지를 보고 "dog"라는 상위 개념 아래에서 가장 가능성이 높은 하위 개념("Norfok Terrier", "Beagle", "German Shephered" ...)을 예측하기 위해, 같은 상위 개념을 공유하는 하위 클래스들끼리만 이용하여 softmax를 계산한다.
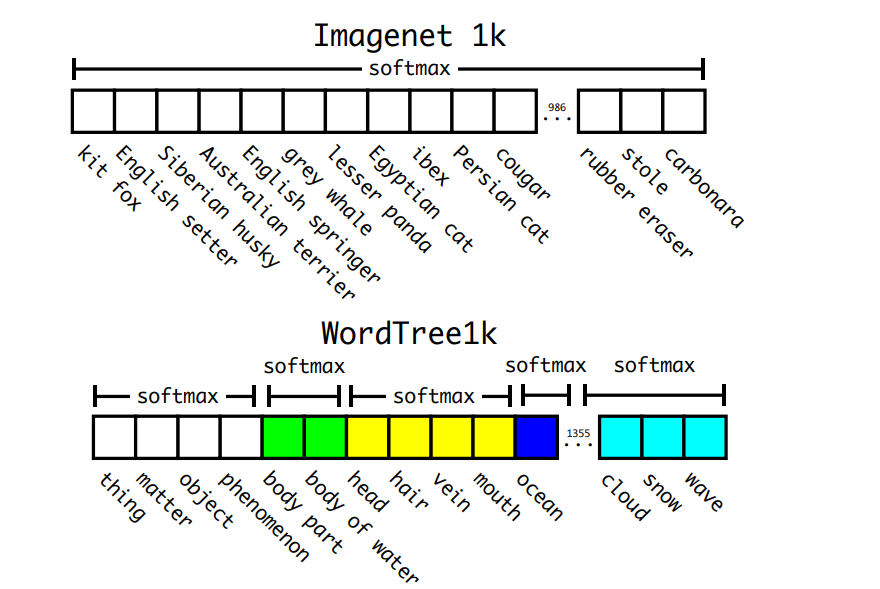
이 방식을 사용하여 hierarchical Darknet-19는 71.9 top-1 accuracy 그리고 90.4% top-5 accuracy를 달성했다.
Dataset combination with WordTree
다음 figure는 WordTree를 이용하여 ImageNet과 COCO dataset을 combine한 결과를 보여준다.
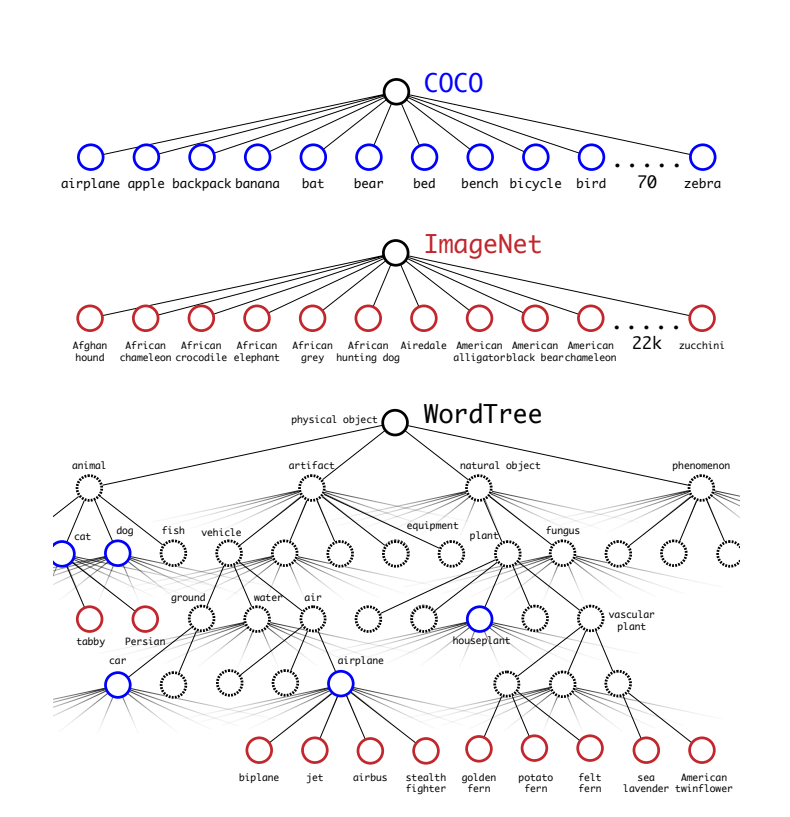
Joint classification and detection
이제 dataset을 combine하고 이에 대해 모델을 훈련시킬 수 있다. 저자들은 combined dataset을 COCO detection dataset과 ImageNet의 top 9000 classes로 구성했다. 이때, dataset들간의 불균형을 어느 정도 맞추기 위해 COCO dataset을 oversampling하였다. 그리고 모델 평가를 위해 이미 포함되지 않은 ImageNet data를 몇 개 추가했다.
이러한 dataset을 이용하여 YOLO9000을 훈련시켰다. 그 과정에서 detection image가 들어올 경우에는 일반적인 detection loss(bounding box의 위치, 크기, confidence score, class probability)를 backpropagate한다. classification data를 만났을 경우에는 오직 loss를 같은 level과 상위 level로만 역전파시켰다. 즉 "Norfok terrier"로 labelling된 이미지를 만났을 경우에는, "Norfok terrier", "dog", "mammal"로만 loss를 역전파시킨다. 하위 level로 loss를 역전파시키지 않는 이유는 그 image가 어떤 하위 class에 속하는지는 알 수 없기 때문이다. 예를 들어 "dog"라고 labelling된 이미지는 그 "dog"이 "German Shepherd"인지 "Golen Retriever"인지는 알 수 없다.
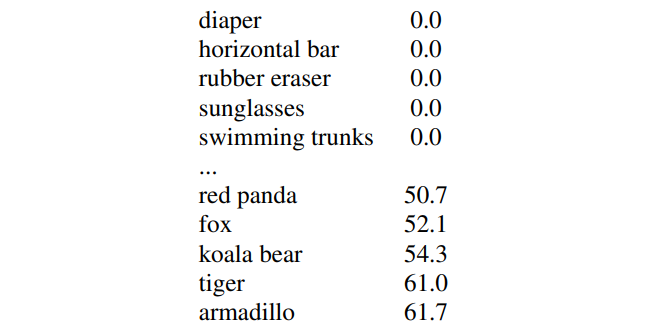
이렇게 학습된 YOLO9000을 ImageNet detection task에 대해 평가했다. ImageNet detection task는 학습에 사용됐던 COCO dataset과 오직 44개의 object catgories밖에 공유하지 않음에도 불구하고(즉 테스트 이미지들의 대부분에 대해서는 detection imformation이 아닌 clssification imformation만 학습한 상태) 44개의 categories에 대해 19.7 mAP를 기록했다. 그리고 나머지 156 object classes에 대해서도 16.0 mAP를 기록했다.
YOLO9000는 new species of animals에 대해서는 잘 detect 해내지만 clothing과 equiqment 같은 categories에 대해서는 어려움을 겪는다. COCO dataset으로부터 animal을 detect 하는 방법은 잘 generalizae 할 수 있었지만 이 dataset에는 clothing과 같은 categories에 data는 없기 때문이다.
5. Conclusion
지금까지 YOLOv2와 YOLO9000에 대해 살펴보았다. YOLOv2는 YOLO의 단점을 보완함으로써 다른 detection system보다도 빠르면서 여러 size의 image들을 정확하게 처리할 수 있다는 장점이 있었다. 특히, Anchor Box의 도입을 통해 작은 객체에서도 높은 정확도를 보일 수 있었다.
YOLO9000은 detection과 classification dataset을 합쳐서 훈련함으로써 9000개가 넘는 object categories를 detect할 수 있었다. 또 일부 object에 대한 detection data 없이도 classification data를 기반으로 detection 작업을 수행할 수 있게 한 점이 중요한 혁신이었다.
느낀 점
실전! 프로젝트로 배우는 딥러닝 컴퓨터 비전을 읽던 중 직접 논문을 살펴볼 필요성을 느껴서 찾아보게 되었다.
논문을 읽으며 기억에 남는 점은 두 가지 정도가 있었다. 먼저 anchor box에 관한 부분이다. anchor box를 사용했다는 부분을 읽으며 YOLO는 잘 detect하지 못했던 작은 objects의 detection 성능은 높일 수 있을 것 같았지만, 아무래도 각 cell에 대해 예측해야 할 파라미터들이 늘어나기 때문에 모델의 복잡도도 늘어날 것 같았다. 그러나 이 점을 k-means clustering with IOU를 사용하여 효율적으로 앵커 박스를 설정하고 불필요한 계산을 줄인 것이 인상 깊었다. 또 YOLOv2는 여전히 단일 네트워크 path로 객체 검출을 수행하는 end-to-end 방식이므로 속도는 여전히 실시간 처리가 가능할 만큼 빠르기 때문에 anchor box를 도입해도 충분히 괜찮구나라고 느꼈다.
두 번째는, 일부 obejct에 대해 detection data가 없더라도 classification data를 기반으로 detection 작업을 수행할 수 있다는 점이었다. 이는 hierarchical class structure를 활용하여 특정 하위 개념에 대한 detection 정보를 모델이 학습하지 않았더라도 유사한 상위 개념을 기반으로 object를 예측할 수 있다는 점에서 비롯된 결과였다. 즉 model이 상위 object의 특징을 기반으로 처음 접한 하위 object를 detect 할 수 있다는 게 굉장히 흥미로웠다. 이는 보통 사람이 많이 하는 사고 방식인 것 같았기 때문이다. 동시에 model이 처음 본 class라도 그 class에 대한 정보를 사전에 제공했다면, model이 detect할 수 도 있겠다는 생각을 하였다. 적은 data의 한계를 극복하고 다양한 object를 detect할 수 있는 다른 방법들도 궁금해졌다.
