머신러닝 소개
머신러닝이 무엇이길래 컴퓨터 공학 전공자들 사이에서 뜨거운 감자가 되었을까?? 개념만 들었을 때는 어렵게 느껴질 수 있지만 파헤쳐보면 결코 어렵지 않은 머신러닝의 세계로 들어가보자.
1. AI, Machine Learning, and Deep Learning
머신러닝 얘기를 하기 전에 용어들에 관해 살펴보자. 우리는 살면서 위 세 가지 용어 중 적어도 하나는 들어봤을 것이다. AI, Machine Learning, Deep Learning 각각 인공지능, 기계학습(머신러닝), 딥러닝이라는 한국어로 번역이 되며, 적어도 인공지능이라는 단어는 들어봤지 않겠는가? 최근 인공지능이 우리 삶에 화두를 던진 것이 있는데 그 유명한 알파고와 이세돌 9단의 바둑 경기이다. 바둑은 가능한 수가 워낙 많아 컴퓨터 연산이 인간을 따라잡을 수 없을 것이라고 모두가 공언했지만, 결국 알파고가 이세돌 9단을 4:1로 이기고 인공지능이 인간의 능력을 상회할 수 있음을 세상에 입증하게 되었다. 인공지능을 다루는 영화들도 많이 있다. Iron man, Terminator, her, minority report 등... 이로써 인공지능을 우리가 알게 모르게 많이 접해왔다는 것을 실감할 수 있겠다.



이 인공지능과 머신러닝이라는 용어는 엄연히 다르다. 또한 공부해본 사람은 알겠지만 머신러닝과 딥러닝도 차이가 있다. 아래 그림은 이를 대변하며, 각각의 대표적인 특징을 정리하자면 다음과 같다.
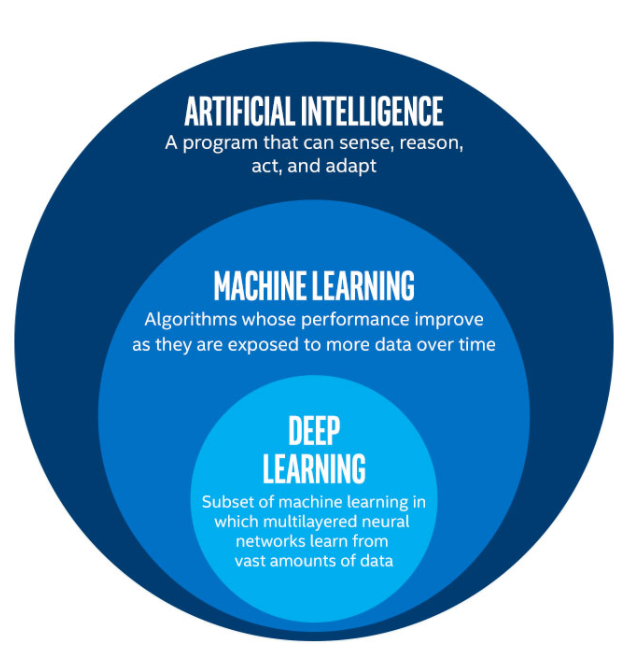
- 인공지능(AI) : 기계나 소프트웨어에 의해 보여지고 연출되는 지능
- 기계학습 / 머신러닝(ML) : 명시적으로 프로그램 되어있지 않고 컴퓨터가 알아서 데이터로부터 학습하는 능력을 얻게하는 학문 분야. 주로 확률과 통계적 방법을 이용함
- 딥러닝(DL, Deep learning) : 머신러닝의 한 분야(하위 집합)로, 심층 신경망에 기반한 고수준의 추상화가 적용된 알고리즘의 집합을 아우르는 분야
위 그림을 살펴보면 수학적 집합관계로 인공지능이 최상위 집합이고 그 안에서 머신러닝과 딥러닝이 부분집합을 이룬다는 것을 알 수 있다. 즉 인공지능에 대한 연구가 먼저 선행된 다음 나머지 두가지가 파생되었다는 것인데, 이 인공지능 개발은 세가지의 단계를 갖고 발전해왔다.
👉🏻 1st wave 1956년 다트머스 대학의 Arthur Samuel의 checkers 문제. 영어를 러시아어로 번역하는 것이었는데 결과가 당시에는 저평가 되었다.
👉🏻 2nd wave 1965년 DENDRAL, 1975년 PROSPECTOR, 1979년 MYCIN, 1989년 XCON 등의 지식 기반체계의 붐이 일어나면서 인공지능 연구가 활발히 진행되었다.
👉🏻 3rd wave 3차 물결은 AI가 폭발적으로 성장한 시기로 컴퓨터 계산 연산 알고리즘의 발전과 GPU등의 자원 발전으로 이어졌다.
그리하여 AI 물결에 따른 타임라인은 다음과 같다. 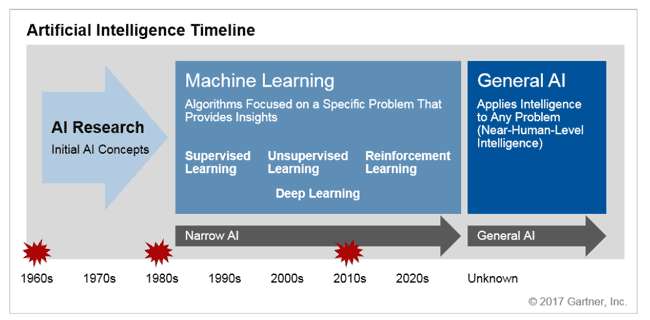
![]()
이제 본격적으로 머신러닝에 대해 살펴보자.
2. Machine Learning concepts
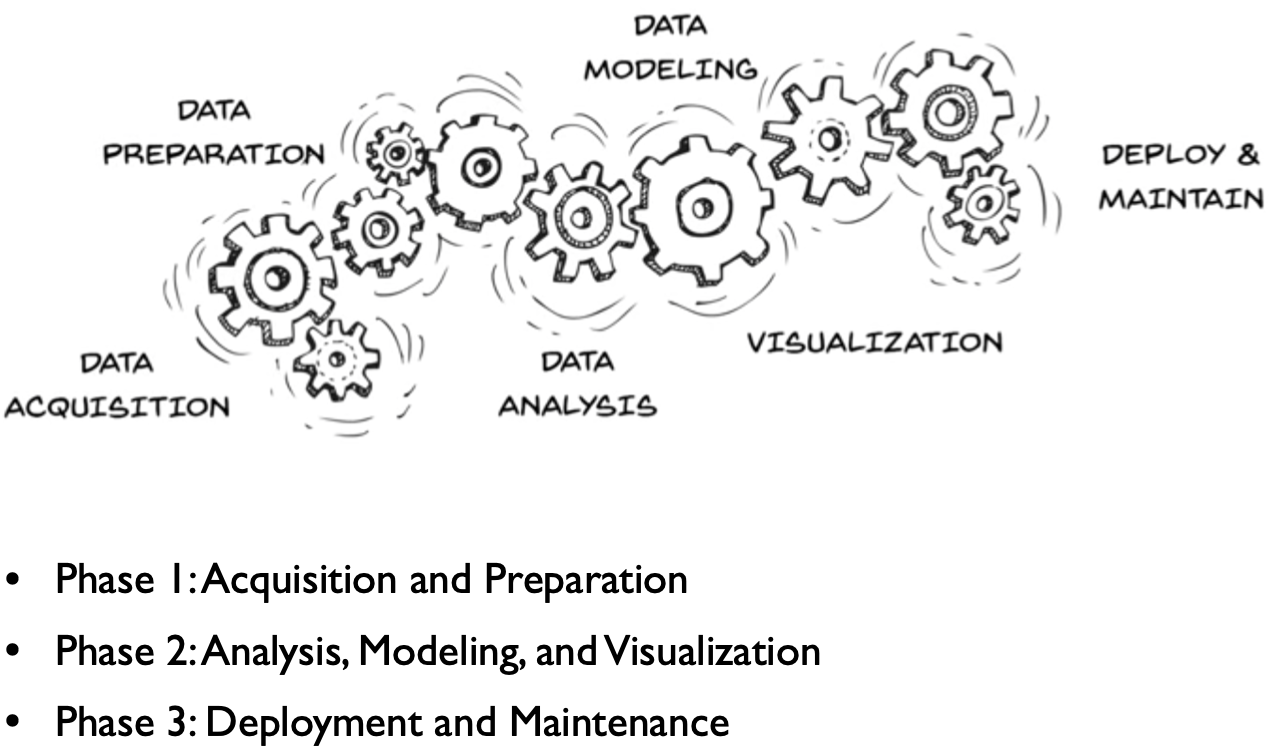
머신러닝의 과정은 위 그림으로 표현할 수 있다. 세 가지 단계로 나눌 수 있으며, 데이터를 가지고 작업을 수행한다. 먼저 데이터를 크롤링이나 합법적으로 지원 받은 다음, 이를 분석하고 데이터를 작업 수행에 맞게 적절히 가공한다. 그런 다음, 데이터를 가지고 모델링과 시각화를 하여 결과를 산출하고 이를 보류하거나 알맞게 사용한다. 각 단계를 체계적으로 정리하면 이러하다.
- 획득(Acquisition) : 다양한 출처로부터 데이터 수집. 실험이나 설문조사, 메타 데이터 분석 등
- 준비(Preparation) : 데이터를 정돈하고 적절히 전처리하여 실험에 알맞는 데이터셋 구조를 갖춤
- 분석(Analysis) : 데이터가 실행되기 위해 사전 평가와 결과물과 비교분석을 위해 데이터를 온전히 파악해둠
- 모델링(Modeling) : 데이터가 어떤 패턴으로 정형화되고 모델로서 일반화 되는 단계. 이를 통해 추론이나 예측을 형성한다.
- 시각화(Visualization) : 직관적인 관찰을 나타내기 위한 단계로 적절한 시각화 툴을 이용해 관찰자가 판단하기 쉽도록 함
- 사용 및 유지보수(deployment and maintenance) : 실험 결과를 현장에서 적용하거나 생산적인 효과를 거두는 단계
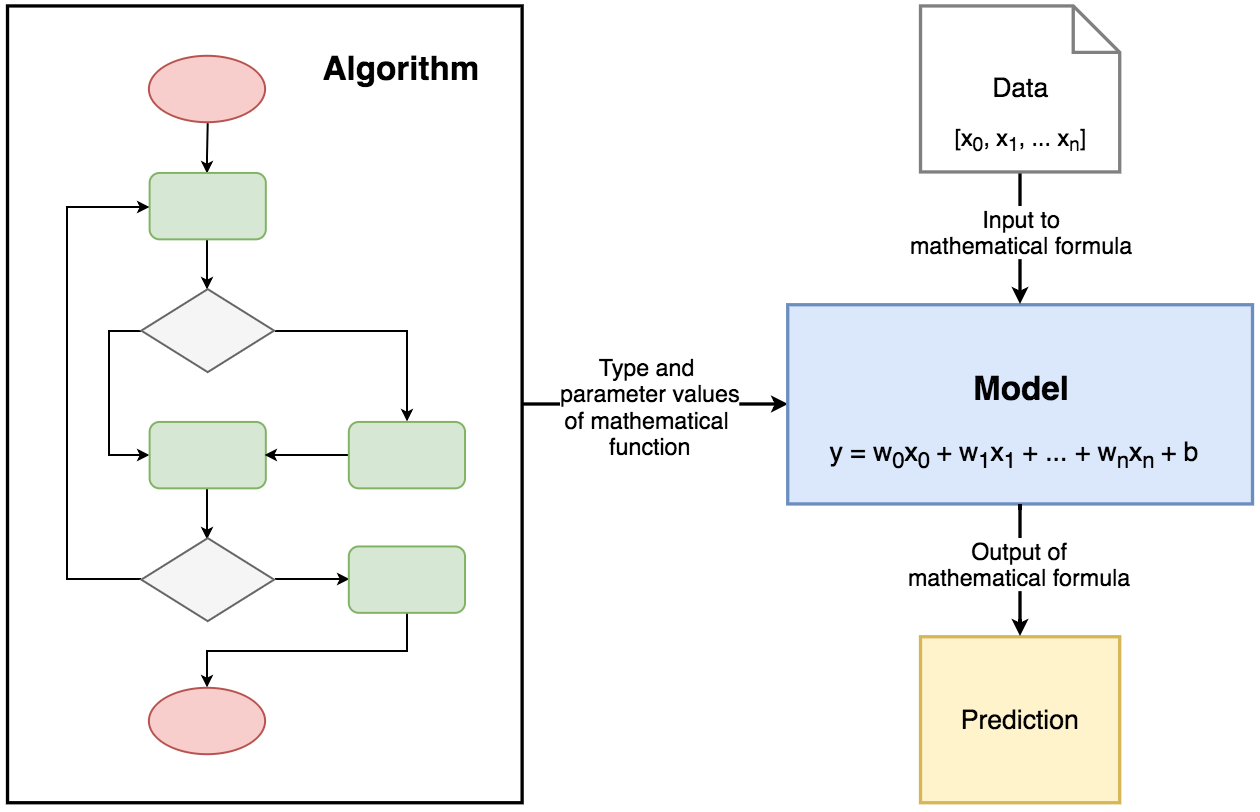
3. Main Language to Do This Process
머신러닝은 보통 통계학자, 빅데이터 전문가, 데이터 사이언티스트들이 주로 작업하는 분야이며, 주로 사용되는 언어로는 통계용 언어인 R과 범용 프로그래밍 언어인 python이 있다. python을 많이 사용하며, python에는 머신러닝 기능을 탑재한 다양한 오픈 소스 모듈들이 있어 손쉽게 머신러닝을 수행할 수 있다. pandas, scikit-learn, mglearn이 대표적인 툴들이다. 한편, 파이썬은 C언어로 구현된 언어인데, 프로그래밍 언어 중 배우기가 무척 쉽고 가독성이 뛰어나며, 객체지향적이고, 동적 데이터 타입과 가비지 콜렉터 기능을 제공한다는 강력한 특성이 있어 머신러닝을 수행하는데에 최적의 언어이다. C나 자바만큼 빠르지 않다는 단점만 빼면 명확한 문법에, 데이터 조작이 쉽고 개발자 pool이 잘 형성되어있다는 최고의 장점을 갖는다.
머신러닝 학습 종류
머신러닝의 학습방법에는 큰 범주로 세 가지 방식이 있다. 비지도학습과 지도학습, 그리고 강화학습이다. 어떤 방식으로 하냐에 따라 모델링이 다르고, 또 데이터 형태와 목적에 따라 선택해야 하는 방식도 다르기에 하나씩 살펴보자.
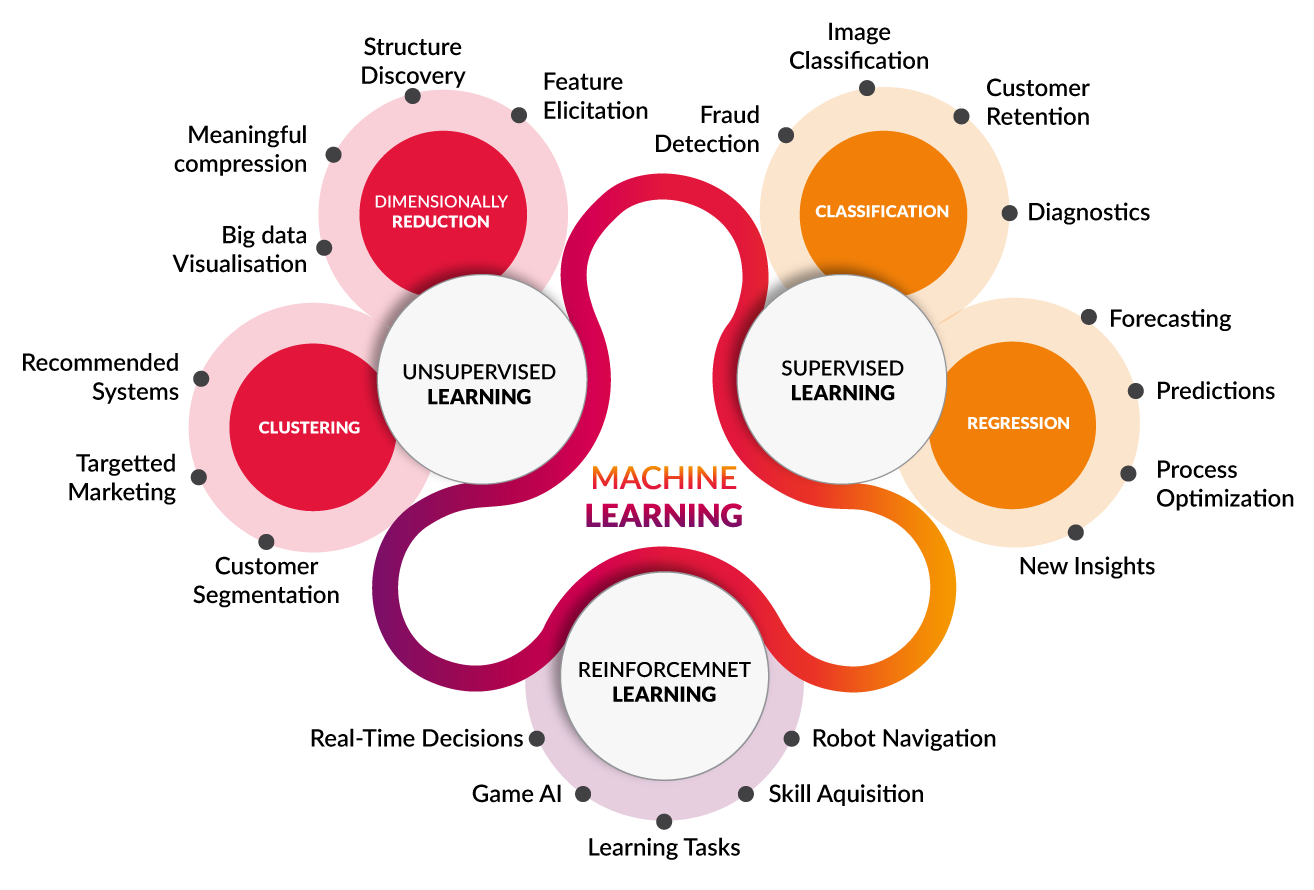
1. 지도학습(Supervised learning)
어떤 데이터가 있다고 하면, 머신러닝을 하기 위해선 데이터 하나마다 'label'이라고 하는 정답이 있기 마련이다. 이 label이 모델링 전에 주어지고 학습이 진행되어 머신이 정답을 맞추었는지 판별하게 하는 이를 supervised learning, 우리말로는 지도학습이라고 한다. label이 주어졌을 때 데이터는 확실한 input-output 짝을 갖게 되고, 이 지도학습이 이루어지는 머신러닝에는 대표적으로 분류 문제(classification)와 회귀 문제(Regression)가 있다.
-
- Classification - the outcome is discrete 즉, 결과가 이진(0,1)이나 범주형으로 나오는 이산적인 양상을 띄는 문제
- Regression - the outcome is real or continuous number 즉, 어떤 데이터의 특징(feature)값을 토대로 값을 예측한 결과가 실수나 연속된 값의 양상을 띄는 것. e.g) 사람의 기대 수명 예측
지도학습 과정을 그려낸 다이어그램
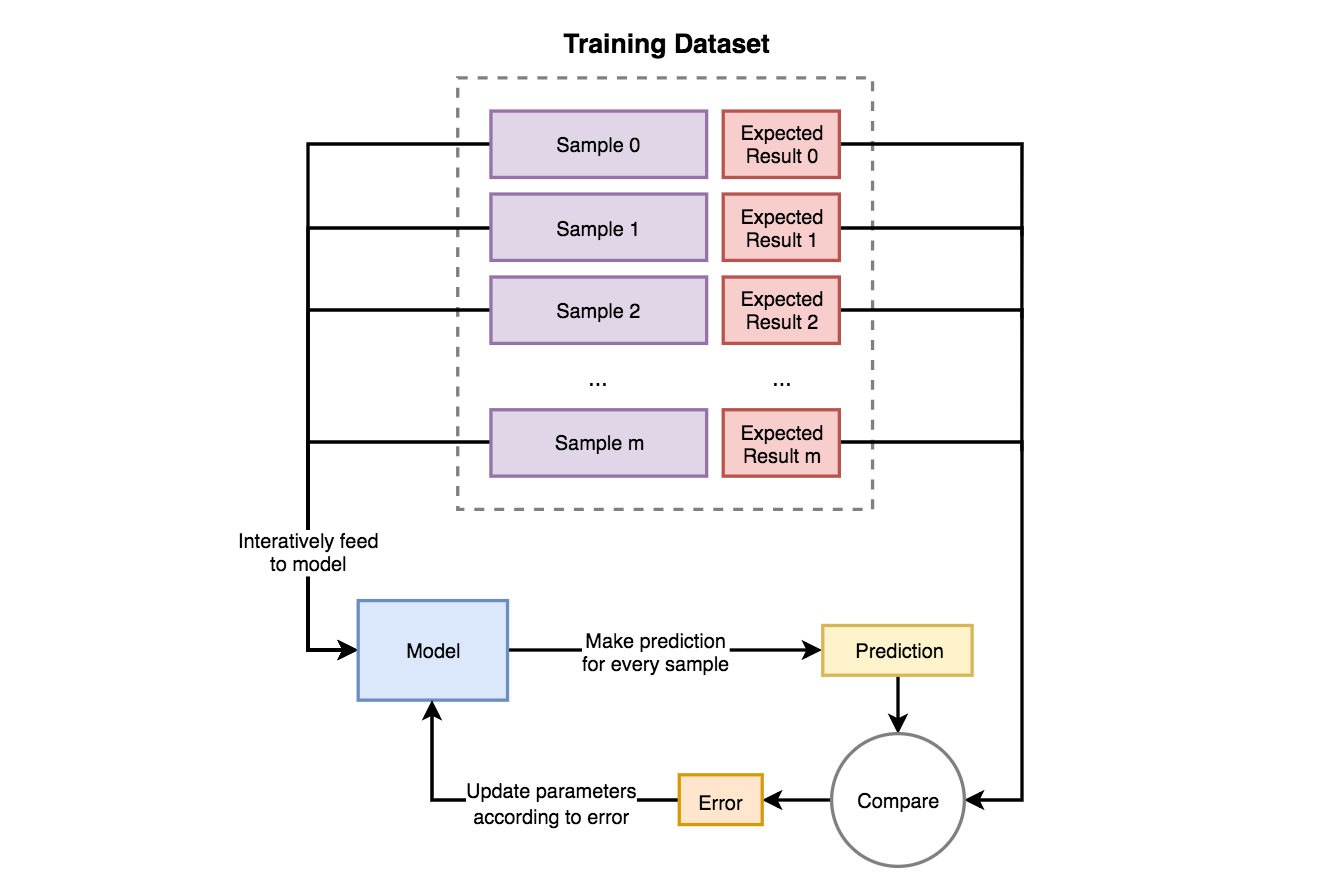
IMG source from towardsdatascience.com
2. 비지도학습(Unsupervised learning)
지도학습과 달리 label이 없거나 제공하지 않고 학습을 수행하는 방식을 말하며, 비슷한 데이터들을 clustering(군집화)하는데에 사용된다. 즉 기계는 학습을 통해 정답을 내놓지는 않지만, 주어진 데이터를 비슷한 것 끼리 묶어주는 것이다. 이런 군집화 외에도 결측치 탐색, 자동인코더 등에 사용된다.
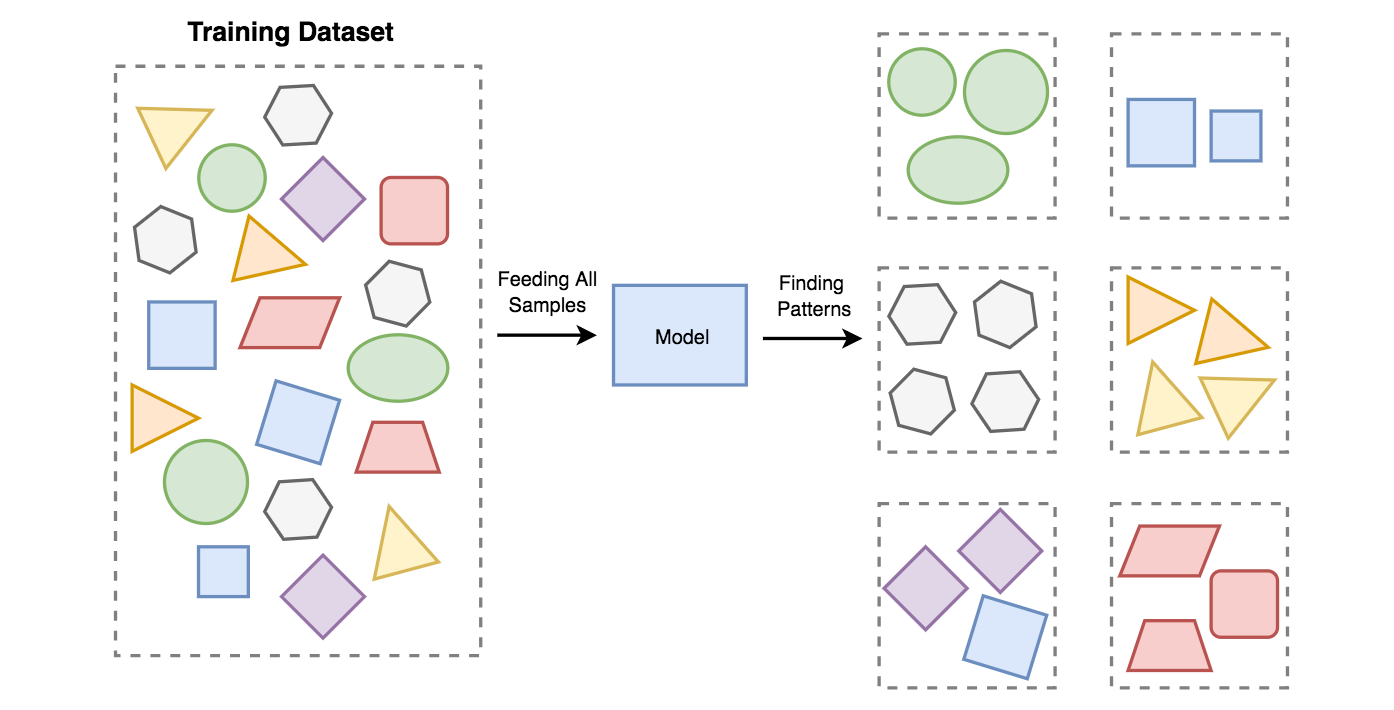

IMG source from towardsdatascience.com
3. 강화학습(Reinforcement / Semisupervised learning)
부분적으로 label이 있는 데이터, 즉 레이블이 있는 데이터와 없는 데이터를 섞어 기계를 학습시키고 여기에 대해 잘했다, 못했다와 같은 긍부정 피드백을 배우게 하는 것을 말한다. 지도학습과 비지도학습의 하이브리드 형태이며, semisupervised와 reinforcement는 '보상' 측면에서 엄연히 다른데 보통 비슷한 관점에서 보며, 강화학습 알고리즘은 아래와 같다.
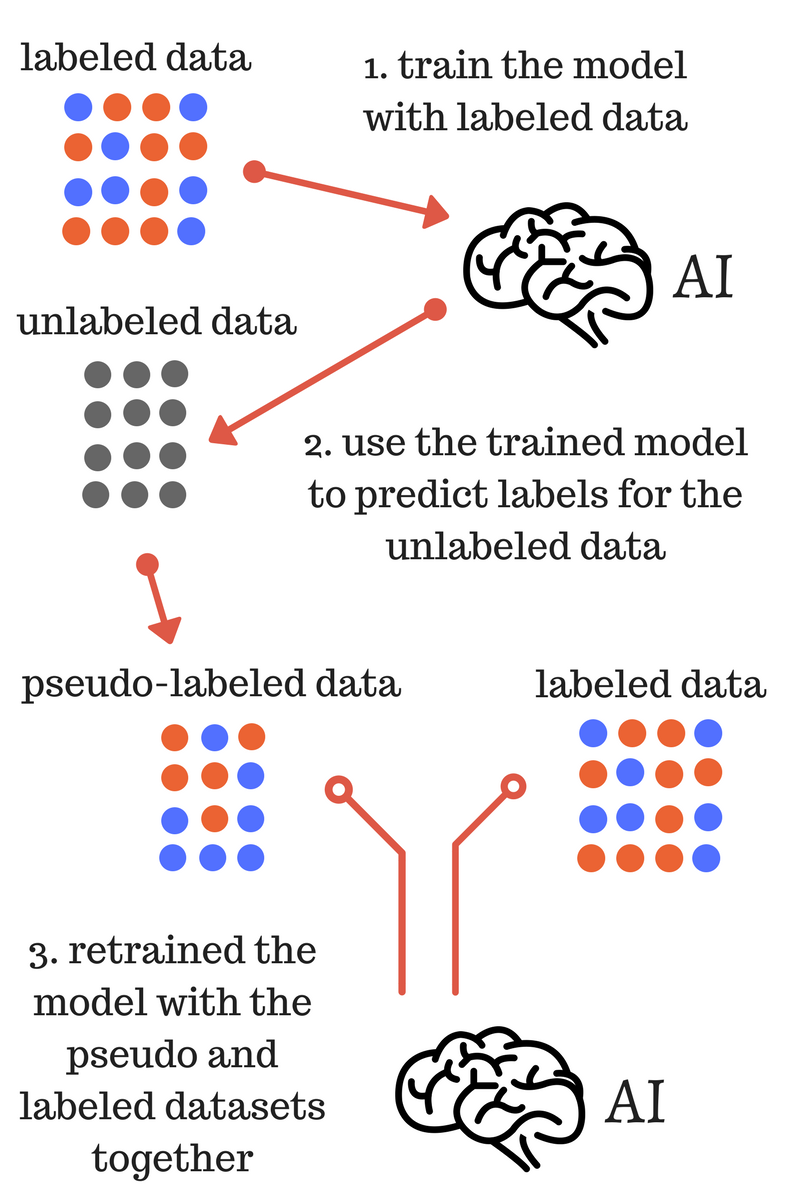

IMG source from datawhatnow.com / towardsdatascience.com
1편을 마치며....
머신 러닝 첫 번째 포스트를 시작했다. 아마 개인적으로 긴 여정이 되지 않을까 생각하지만, 내가 그동안 얻은 머신러닝 지식을 블로그 포스트를 통해 다시 한번 정리, 복습하고 또 다른 사람에게 유익한 도움을 줄 수 있었으면 하고 시작해본다. 이번 포스트에서는 머신러닝에 관한 배경, 소개와 학습 종류를 간단하게 살펴보았다. 다음 2편에서는 머신러닝 프로세스 세부 탐구와 지도학습 부분에서의 대표적인 방법들에 대해 살펴보겠다.
References
- Charmgil H.(2019) day1.key - Introduction of ML. Machine learning summer camp day 1 lecture. HGU, South Korea
- Injung K.(2020) IntroductionMachineLearning. Deeplearning application subject in fall semester. HGU, South Korea
- Kamil K.(Jul 25, 2018) Coding deep learning for beginners. towards-data science blog post. Retrieved from
https://towardsdatascience.com/coding-deep-learning-for-beginners-types-of-machine-learning-b9e651e1ed9d
