CNN-LSTM model for Image Captioning
Image Captioning은 이미지를 언어로 설명하는 작업이다.
CNN as an encoder is used to learn features in images.
LSTM as a decoder generates a text sequence describing image features.
이미지의 특징을 학습하는 인코더로서 CNN(Convolutional Neural Network)을 사용하고,
이미지 특징을 설명하는 텍스트 시퀀스를 생성하는 디코더로서 LSTM(Long Short-Term Memory)을 사용한다.
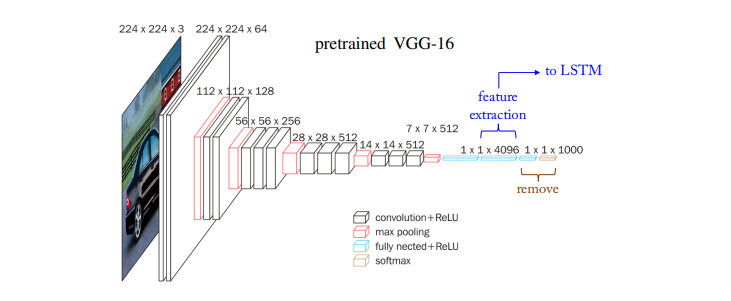
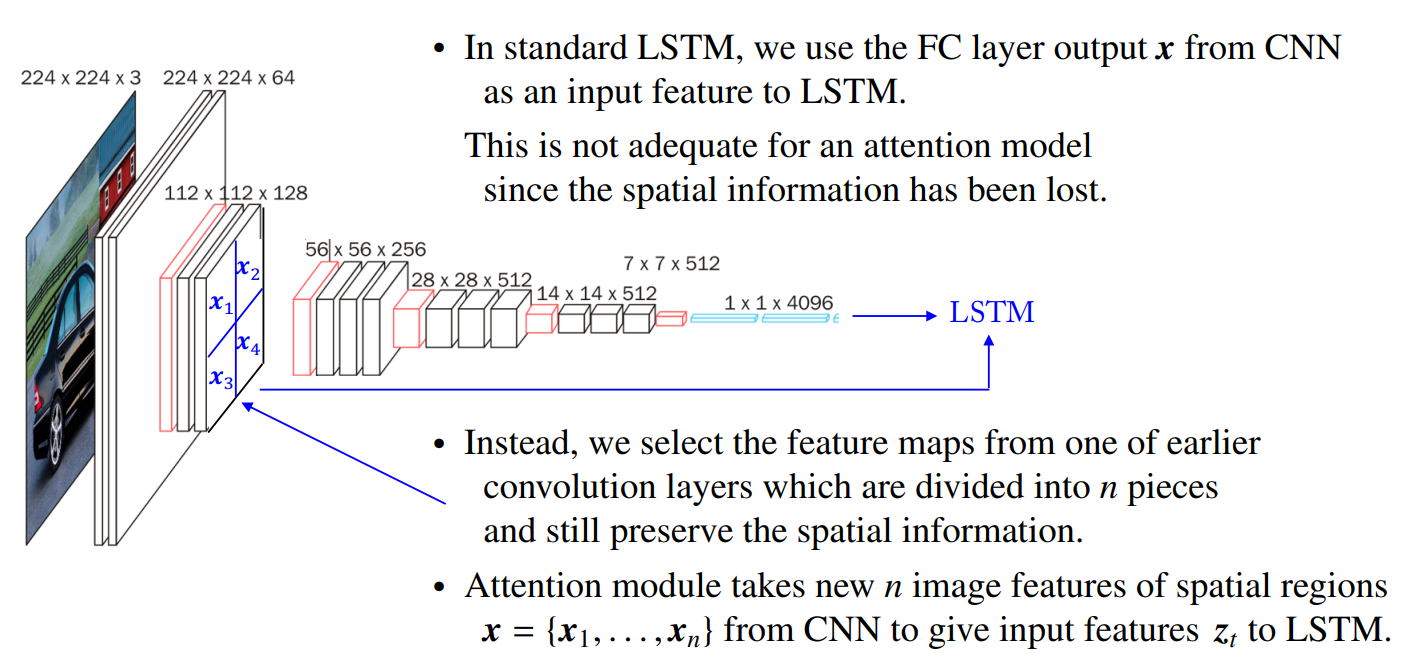
Pretrained CNN like VGG-16 or Resnet after removing the final FC classification layer acts as a feature extractor that compresses the image information into a smaller feature vector x.
사전에 학습된 CNN 모델인 VGG-16이나 ResNet과 같은 모델을 사용한다.
CNN 모델의 마지막 FC(Fully-Connected) 분류 레이어를 제거한 뒤, 이미지 정보를 더 작은 특징 벡터 x로 압축하는 특징 추출기로 사용한다. 이 벡터 x는 이미지에 대한 중요한 특징을 나타낸다.
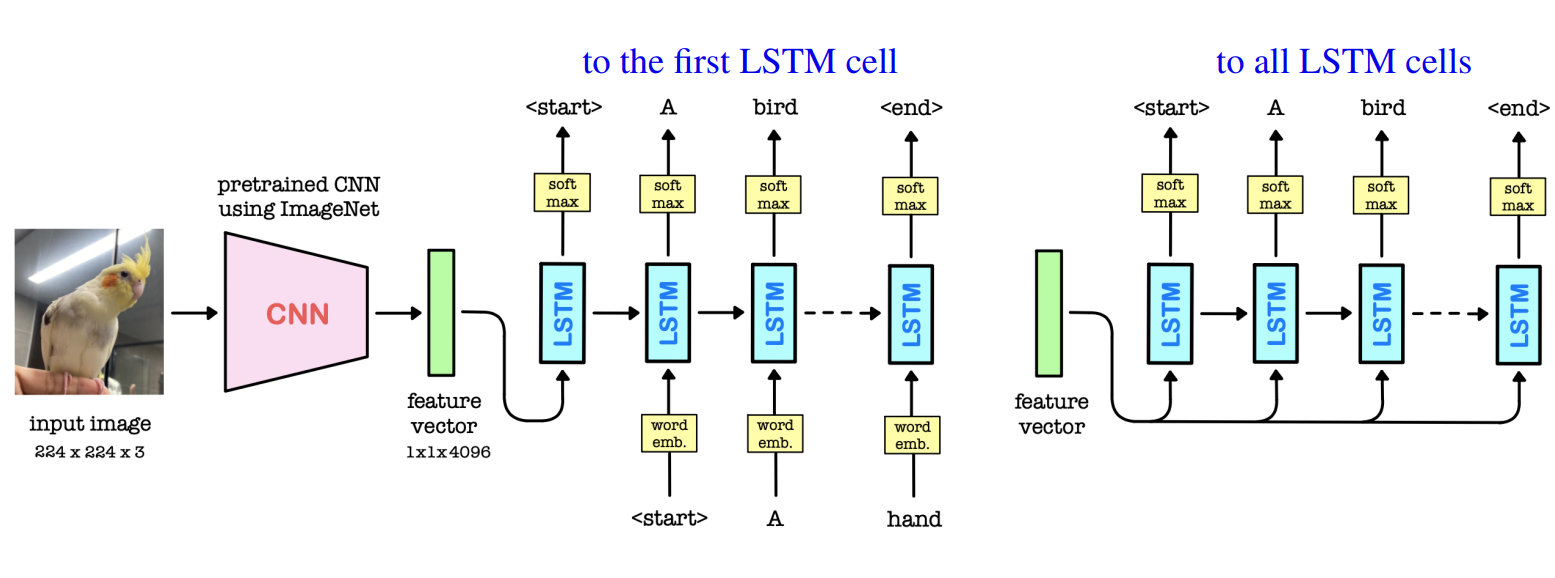
input으로 image -> CNN 구조로 그림을 인식 + LSTM 문장 생성 token(word) 단어를 토큰화
CNN -> Feature Vector (Encoder)
LSTM -> Feature로 문장 생성 (Decoder)
- LSTM decodes this feature vector (initial input) into a text sequence.
- We feed the image feature vector x to the first or all LSTM cells.
- LSTM starts the caption with a
starttoken and repeatedly generate one word at a time until we predict theendtoken.
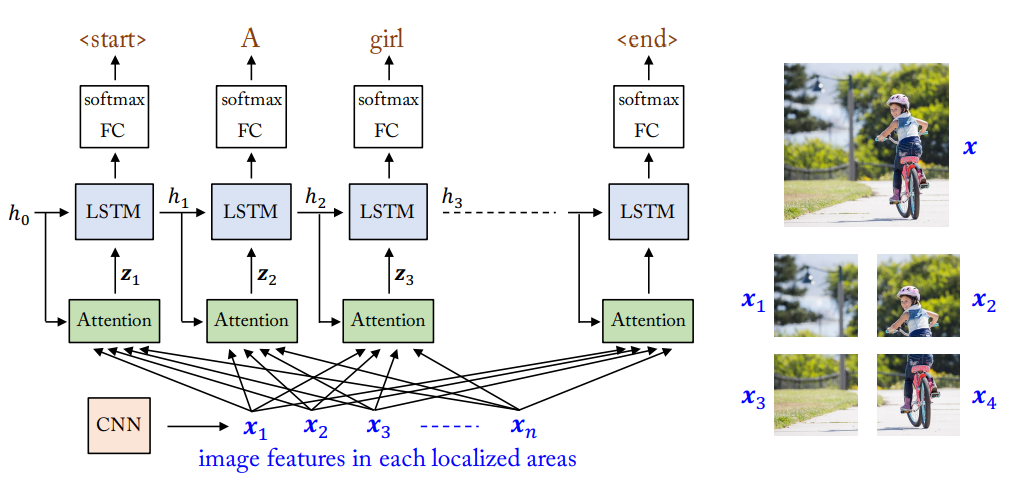
Visual Attention
Visual Attention, inspired by the way humans perform visual recognition tasks, pays attention to particular areas or objects rather than treating the whole image equally.
Ex) When we make a next prediction ‘sign’ based on the context ‘stop’ and the image, our attention shifts to the related area of the image

We use an attention module having a context and image features in each localized areas

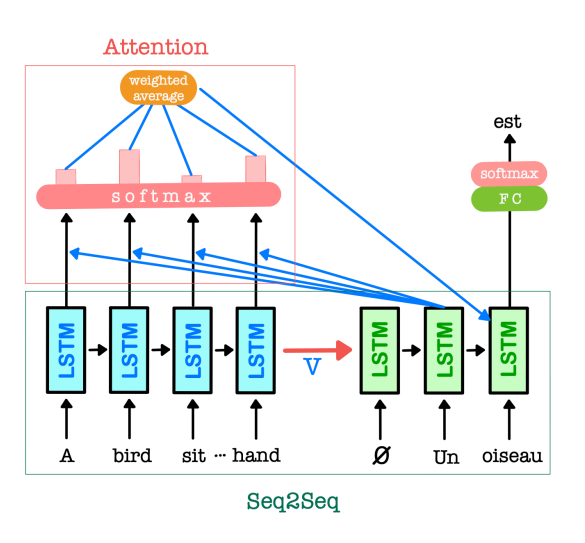
Seq2Seq for Machine Translation
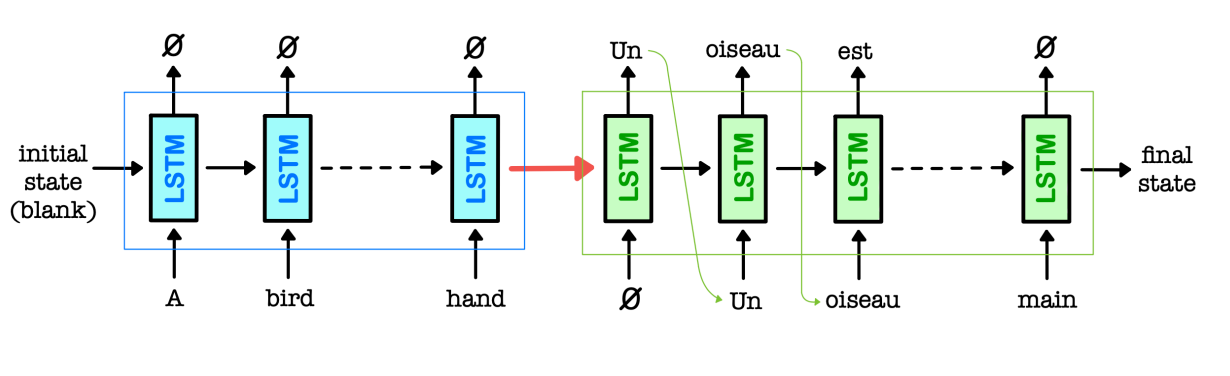
• Seq2Seq learning is a framework for mapping one sequence to another sequence.
• Encoder LSTM processes an input sentence word by word in word embedding form
and compresses the entire content of the input sequence into a small fixed-size vector.
• Decoder LSTM predicts the output word by word based on the encoded vector,
taking the previously predicted word as input at every step.
∗ Encoder network reads in English (blue) and Decoder network writes in French (green).
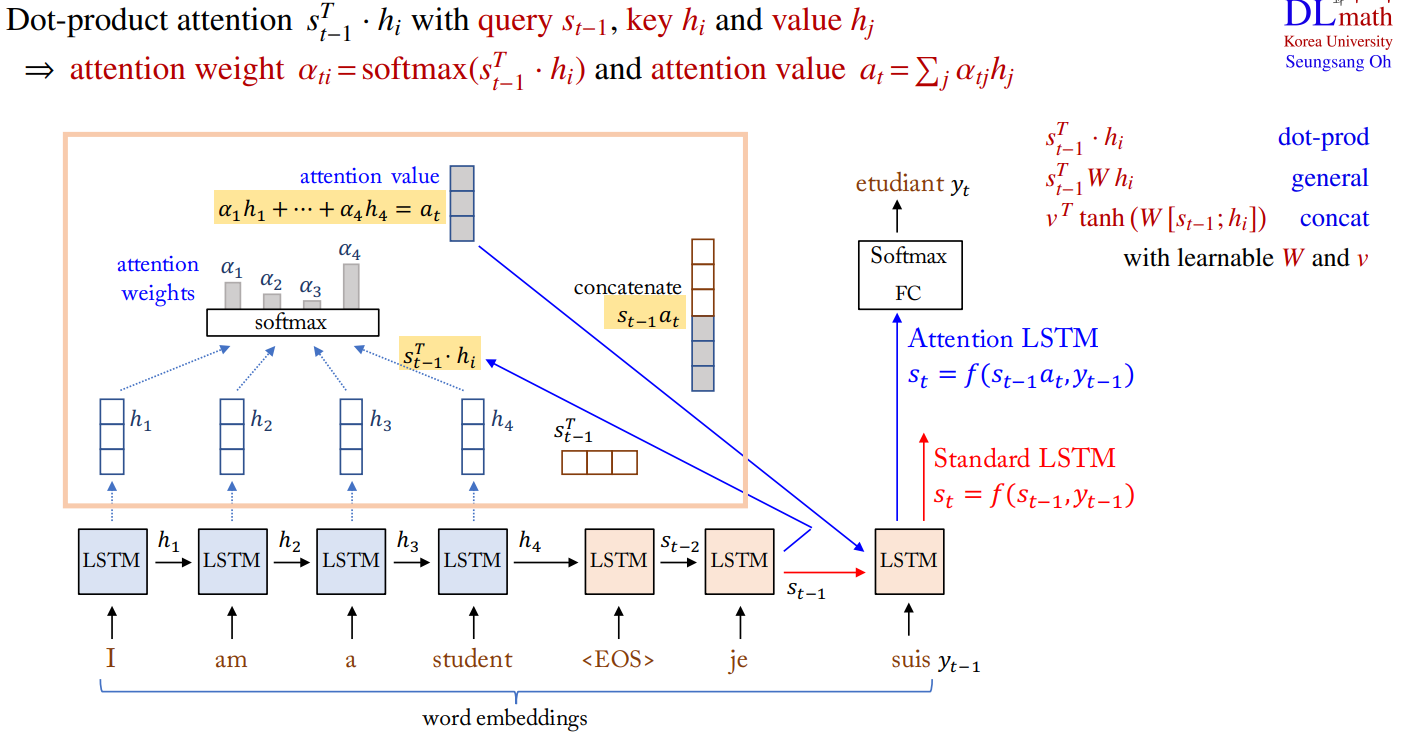
Attention LSTM
Attention mechanism is one of the core innovations in Machine Translation.
• Main bottleneck of Seq2Seq is that it requires to
compress the entire content of the input sequence
into a small fixed-size vector V.
• Attention (using query, key and value vectors) allows
Decoder to look at Encoder hidden states, whose
weighted average is an additional input to Decoder.
Decoder can pay attention to specific words in the input
sequence again based on each hidden state of Decoder.
• It provides a glimpse (based on the attention weights)
into the inner working of the model by inspecting
which input parts are relevant for a particular output.
(unveiling DNN black box)