
Feedforward neural network (FFNN) as MLP(Multi Layer Perceptron)
정보가 한 방향으로만 흐르는 인공 신경망이다.
이전 데이터에 대한 시간적인 개념이나 기억을 가지고 있지 않다.
Recurrent neural network (RNN)
순환 신경망(RNN)은 순차적인 데이터를 처리하기 위해 설계된 신경망으로, 시간적 종속성을 포착할 수 있는 능력을 갖고 있다.
RNN에서는 정보가 여러 방향으로 흐르며 각 뉴런은 현재 입력뿐만 아니라 이전 은닉 상태를 고려하기 위한 순환 연결을 가지고 있다.
(hidden state vector )
RNN은 시간적인 개념과 기억을 갖추고 있으며 언어 모델링, 음성 인식, 시계열 분석 등의 작업에 적합하다.

Time Delay Neural Network (TDNN)
• TDNN is a FFNN whose purpose is to classify temporal patterns with shift-invariance (independency on the beginning points to insure data i.i.d for MLP, so we may shuffle) in sequential data like 1D Conv with stride 1.
• It is the simplest way of controlling time-varying sequential data and allows conventional backpropagation algorithms.
• TDNN gets its inputs by sliding a window of size n across multiple time steps in sequential data and treating these n consecutive data samples as one input data.
Disadvantages of TDNN
The success of TDNN depends on finding an appropriate window size.
- small window size does not capture the longer dependencies.
- large window size increases the parameter number and may add unnecessary noise.
small window size는 더 긴 의존성(dependencies)을 포착하지 못합니다.
large window size 매개 변수 수를 증가시키고 불필요한 노이즈를 추가할 수 있습니다.
TDNN works well for some short-memory problems such as Atari games, but cannot handle long-memory problems over hundreds of time steps such as stock prediction.
일부 단기 기억 문제에는 잘 작동하지만,
주가 예측과 같은 수백 개의 시간 단계를 거치는 장기 기억 문제를 다루기 어렵습니다.
Because TDNN has a fixed window size, it cannot handle sequential data of variable length such as language translation.
TDNN은 고정된 창 크기를 가지고 있기 때문에 언어 번역과 같은 가변 길이의 순차 데이터를 처리할 수 없습니다.
FFNNs do not have any explicit memory of past data.
Their ability to capture temporal dependency is limited within the window size.
Even for a particular time window, input data is treated as a multidimensional feature vector rather than as a sequence of observations, so we lose the benefit of sequential information.
(Unaware of the temporal structure)
FFNN(Feedforward Neural Network)은 이전 데이터에 대한 명시적인 기억이 없습니다.
시간 의존성을 포착하는 능력은 창 크기 내에서 제한적입니다.
특정 시간 창에 대해 입력 데이터는 연속된 관측값의 순차열이 아닌 다차원 특징 벡터로 처리되므로, 순차적인 정보의 이점을 잃게 됩니다.
(시간 구조에 대해 알지 못함)
따라서 TDNN은 일부 단기 기억 문제에 대해 효과적이지만, 장기 기억 문제나 가변 길이의 순차 데이터 처리에는 제한이 있습니다.
시간 지연 신경망 (TDNN)은 변동에 불변한 특성을 유지하면서 순차적인 데이터에서 시간적 패턴을 분류하기 위한 특정 유형의 피드포워드 신경망(FFNN)입니다.
TDNN은 고정된 크기의 윈도우를 사용하여 연속된 데이터를 처리하며, 이를 통해 시간적으로 지역적인 패턴을 파악할 수 있습니다. 하지만 TDNN은 고정된 창 크기를 가지고 있어 가변 길이의 순차 데이터를 처리할 수 없으며, 장기 기억 문제에는 제한이 있습니다.
TDNN은 입력 데이터를 다차원 특징 벡터로 처리하여 순차적인 정보를 잃게 됩니다.
이와 달리 RNN은 시간적 의존성을 인코딩하기 위해 순환 구조를 사용하며, LSTM은 RNN의 한 종류로서 장기적인 의존성을 학습하기 위해 설계된 메모리 유닛을 포함하고 있습니다.
Recurrent Neural Network (RNN)
• RNN (LSTM) makes predictions based on current and previous inputs recurrently, while FFNN makes decisions based only on the current input.
• RNN processes the input sequence one data xt at a time (current input) and maintains a hidden state vector ht as a memory for past information (previous inputs).
• It learns to selectively retain relevant information to capture temporal dependency or structure across multiple time steps for processing sequential data.
• RNN does not require a fixed sized time window and can handle variable length sequences.
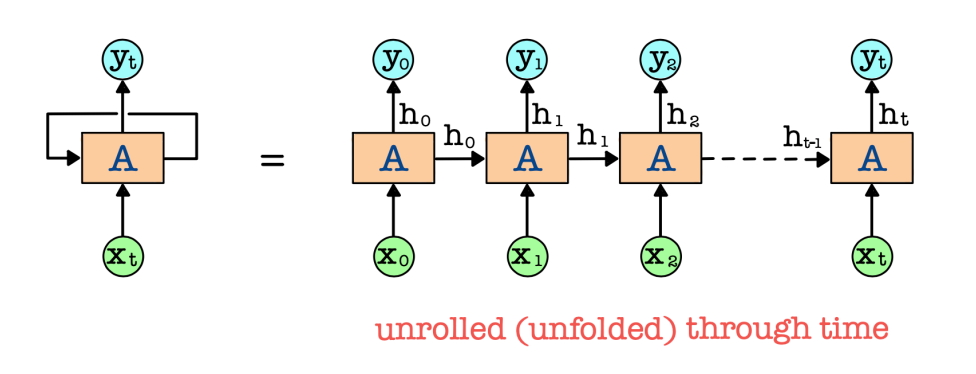
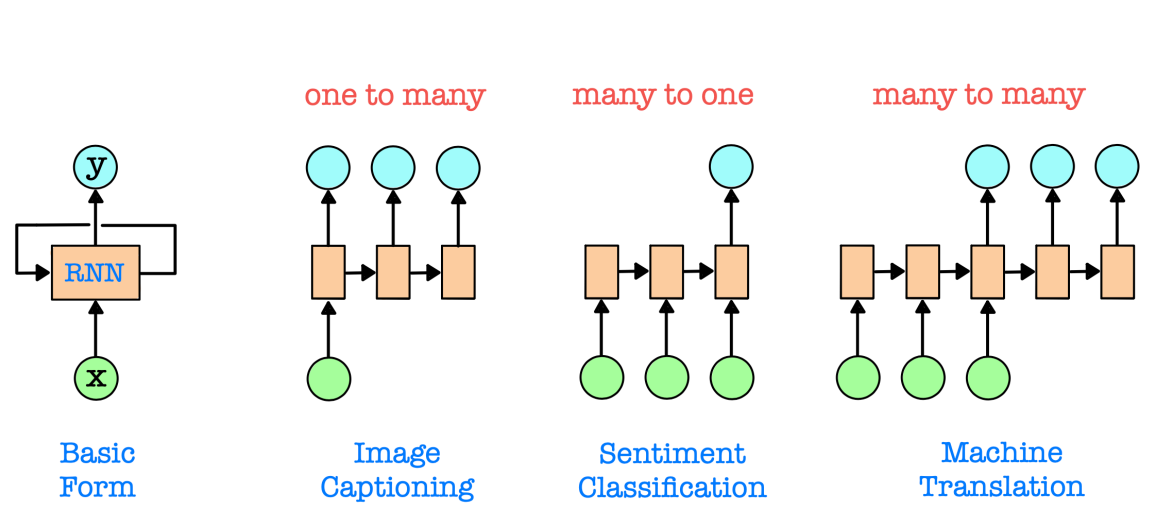
순환 신경망 (RNN)은 현재 및 이전 입력에 기반하여 재귀적으로 예측을 수행하는 반면, 피드포워드 신경망 (FFNN)은 현재 입력에만 기반하여 결정을 내립니다. RNN은 입력 시퀀스를 하나의 데이터 xt(현재 입력)씩 처리하며, 과거 정보(이전 입력)를 기억하기 위해 hidden state vector ht를 유지합니다. RNN은 순차적인 데이터를 처리하기 위해 여러 시간 단계를 거쳐 시간적 의존성이나 구조를 포착하기 위해 관련된 정보를 선택적으로 보존하는 방법을 학습합니다. RNN은 고정 크기의 시간 창이 필요하지 않으며 가변 길이의 시퀀스를 처리할 수 있습니다.
RNN (Recurrent Neural Network)은 순차적인 데이터나 시계열 데이터와 같이 이전 단계의 정보를 현재 단계에 전달하는 데 특화된 인공 신경망입니다. RNN은 반복적인 구조를 가지며, 이전 단계의 출력이 현재 단계의 입력으로 사용됩니다. 이를 통해 RNN은 순차적인 패턴을 학습하고 시간적 의존성을 인코딩할 수 있습니다.
하지만 기본적인 RNN은 "기울기 소실" 또는 "기울기 폭발"과 같은 문제를 가지고 있습니다. 긴 시퀀스를 처리할 때, 이러한 문제로 인해 이전 정보가 제대로 전달되지 않고 학습이 어려워집니다. 이를 해결하기 위해 LSTM (Long Short-Term Memory)이라는 RNN의 변형이 개발되었습니다.
LSTM is designed to capture long-term dependency and overcomes the vanishing/exploding gradient problem in SimpleRNN.
LSTM은 RNN의 단점을 보완하기 위해 설계된 네트워크 구조입니다. LSTM은 입력 게이트(input gate), 삭제 게이트(forget gate), 출력 게이트(output gate) 등의 구조적인 요소를 사용하여 장기적인 의존성을 학습할 수 있습니다. LSTM의 핵심 아이디어는 "셀 상태(cell state)"라는 메모리 유닛을 도입한 것입니다. 셀 상태는 정보를 보존하고 업데이트하는 역할을 수행하여 긴 시간 동안 정보를 기억할 수 있습니다.
각 게이트는 시그모이드 함수와 함께 동작하여 어떤 정보를 유지하고, 어떤 정보를 삭제하고, 어떤 정보를 출력할지를 결정합니다. 이러한 메커니즘을 통해 LSTM은 장기적인 의존성을 학습하면서도 "기울기 소실" 문제를 해결하고 더 효과적으로 시계열 데이터를 모델링할 수 있습니다.
요약하면, RNN은 순차적인 데이터 처리에 특화된 네트워크이며, LSTM은 RNN의 한 종류로서 장기적인 의존성을 학습할 수 있는 메모리 유닛을 포함한 구조로 기울기 소실 문제를 해결하는 데 효과적입니다.
