Generative Adversarial Network (GAN)
- GAN has had a profound impact on the AI industry since Ian Goodfellow proposed in 2014.
Yann LeCun described GAN as “the most interesting idea in the last 10 years in Machine Learning”.
- GAN changed Deep Learning paradigm that has been focused on
supervised learningtounsupervised learning.
Various follow-up studies and applications of GAN as a
generative modelare spreading widely because they cancreate fake datathat are difficult to distinguish from real data.
GAN
training is hardbecause ofnon-convergenceandmode collapse problems.
지도학습(Supervised Learning) 과 비지도학습(Unsupervised Learning)

Supervised Learning
• It learns from a training data set with labels.
• It learns a general rule for regression or classification to predict the labels for the remaining data.
Unsupervised Learning
• It learns from a training data set without any label.
• It detects patterns in the data by clustering similar data that have common characteristics.
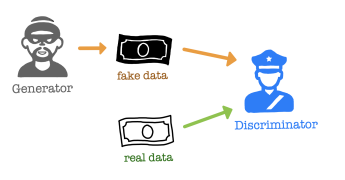
Generative: Learn a generative model
생성 모델
Adversarial: Trained in an adversarial setting
G(generator)andD(dscriminator)
GAN은 Generator와 Discriminator라는 두 모델로 구성됩니다.
Use deep neural Networks: ranging from MLP, CNN, RNN to AE, DRL
GAN architecture

•
Generator Ggenerates ‘fake’ samples that are intended to come from the same distribution as ‘real’ data, to maximize the probability of D making a mistake.
Generator는 latent vector 를 입력으로 받아 이미지(real data) 와 유사한 형태의 가짜 이미지(sample data) 를 생성합니다.
•
Discriminator Devaluates the probability that the sample came from real data rather than G.
Discriminator는 Generator가 생성한 위조 데이터(Sample data,)와 실제 데이터를 구별하는 역할을 한다.
실제 이미지 x를 입력으로 받았을 때 1을 출력하고, Generator가 생성한 가짜 이미지 G(z)를 입력으로 받았을 때 0을 출력합니다.
따라서, Discriminator는 "이것은 진짜 이미지다" 또는 "이것은 가짜 이미지다"를 판별하는 역할을 수행합니다.
G and D oppose each other, but at the same time help each other in their own tasks.
Repeatedly train the two networks alternately and we get better G and D.
After finishing the training, we usually discard D, which is used just for training G
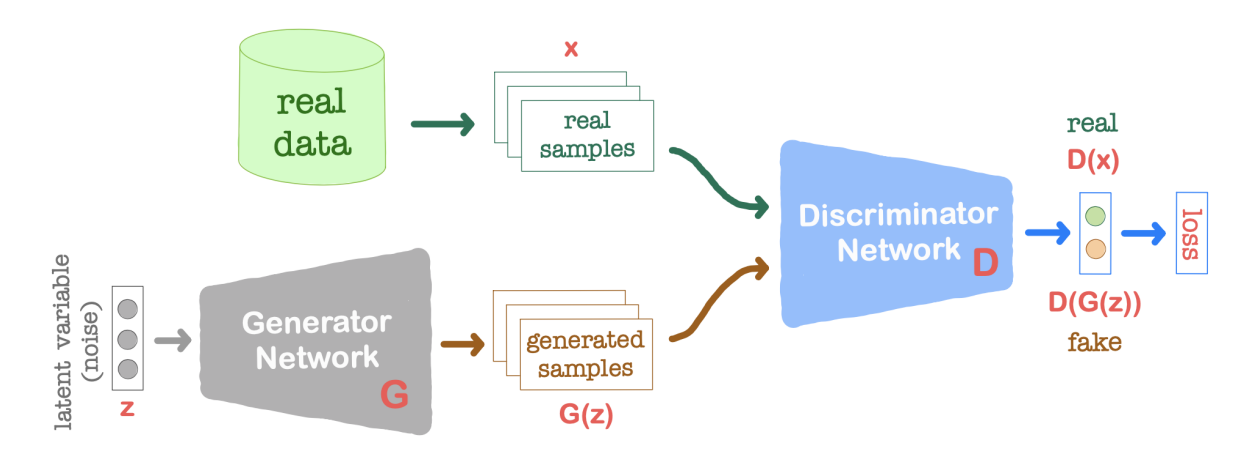
Generator와 Discriminator 간의 경쟁과 피드백 과정입니다.
Generator는 Discriminator가 가짜 이미지를 진짜로 판별하지 못하도록 학습을 진행하고,
Discriminator는 Generator가 생성한 가짜 이미지와 실제 이미지를 구분할 수 있도록 학습을 진행합니다.
이러한 경쟁과 피드백 과정을 통해 Generator는 점차적으로 진짜 이미지와 유사한 가짜 이미지를 생성하게 되고, Discriminator는 더욱 정확하게 가짜와 진짜를 구별하게 됩니다.
Generator는 주로 1차원의 잠재 벡터(Latant Vector) z를 입력으로 받습니다. 이 벡터는 일반적으로 균일한 분포를 따르는 난수로 구성됩니다.
Generator는 이 잠재 벡터를 입력으로 받아 실제 이미지와 동일한 형태의 가짜 이미지를 출력합니다. 예를 들면, 만약 실제 이미지가 28x28 크기의 이미지라면, Generator는 잠재 벡터 z를 입력으로 받아 28x28 크기의 가짜 이미지를 생성하게 됩니다.
이렇게 생성된 가짜 이미지는 학습이 진행되면서 실제 이미지와 유사한 형태를 갖게 됩니다.
Objective function
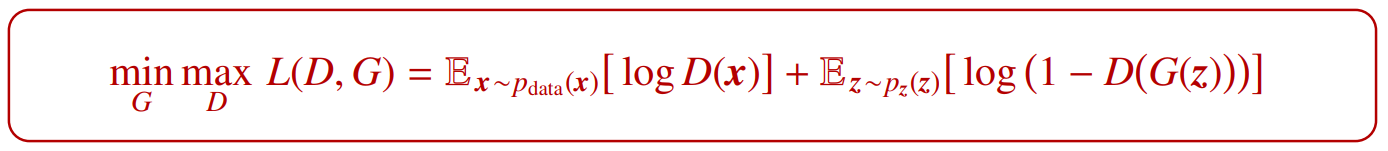
- Discriminator is trying to maximize so that
- on the real data distribution is close to ‘real’
- on a simple distribution such as uniform or normal is close to ‘fake’.
- Generator G is trying to minimize Discriminator’s reward so that is close to
Discriminator is fooled into thinking that G(z) is real
Nash equilibrium
- In two-player minimax problem,
the solution is the same as Nash equilibrium

Globally optimal solution is that the generated distribution matches the real distribution
내시 균형(Nash equilibrium)은 게임 이론에서 사용되는 개념으로, 경쟁자들이 최선의 선택을 한다고 가정할 때, 서로가 자신의 선택을 바꾸지 않는 균형 상태를 말합니다. 다른 말로 하면, 모든 플레이어들이 현재 전략을 유지한다는 가정 하에, 더 이상 개인적으로 전략을 변경할 동기가 없는 상태를 나타냅니다. 이 개념은 죄수의 딜레마(Prisoner's Dilemma)와 밀접한 관련이 있습니다.
게임 이론의 관점에서 보면, Generator와 Discriminator는 서로 경쟁 관계에 있습니다. Generator는 Discriminator를 속이기 위해 최선의 전략을 선택하고, Discriminator는 가짜 이미지와 실제 이미지를 구별하기 위해 최선의 전략을 선택합니다. 이 경쟁과 피드백 과정을 통해 GAN은 학습을 진행하며, 이상적으로는 내시 균형 상태인 전략의 조합을 찾게 됩니다.
그러나 내시 균형을 달성하는 것은 어렵습니다. 게임은 다양한 내시 균형 상태를 가질 수 있으며, 게임에 따라 내시 균형이 존재하지 않을 수도 있습니다. Generator와 Discriminator 간의 학습 과정은 수렴하지 않을 수도 있고, 적절한 조정과 훈련 파라미터 설정이 필요합니다.
요약하면, 두 플레이어의 최소최대 문제에서 해결책은 내시 균형과 동일합니다. 그러나 내시 균형을 달성하는 것은 어렵고, GAN의 학습 과정은 수렴 문제를 가지고 있을 수 있습니다. 이러한 이유로 GAN의 훈련에는 조정과 튜닝이 필요합니다.
• A set of player strategies is a Nash equilibrium if no player can do better by unilaterally changing his strategy (every player’s strategy is optimal, holding constant the strategies of all the other players).
A game may have multiple Nash equilibria or none at all.
Training D(Discriminator) by Backpropagation
- Fix Generator parameter .
- Perform gradient ascent on Discriminator (parameter ) using real and generated data.
Minibatch of real {} and fake {}

Training Generator G by Backpropagation
• Fix Discriminator parameter .
• Perform gradient descent on Generator using sample noise vectors z from or .
Early in learning, because G is poor, so we train G to minimize .
or


GAN의 entire network 에서는 backpropagation을 사용해서 training 할 수 있다.
D와 G는 주어진 데이터셋을 기반으로 훈련되며, 훈련 과정에서 Backpropagation이 사용됩니다.
Backpropagation은 네트워크의 출력과 실제 값 사이의 오차를 역으로 전파하여 각 뉴런의 가중치를 조정하는 방식이다.
Backpropagation을 통해 각 모델의 가중치가 업데이트되면서 전체 모델의 성능이 점진적으로 개선되어 가짜 데이터의 품질이 향상되고, 진짜와 가짜를 구분하는 능력이 향상됩니다.
Pros and Cons for GAN
Pros:
• Unsupervised learning, so no need for labeled data.
• Generate high-quality images.
• The entire network can be trained with backpropagation.
Cons:
• Non-convergence (수렴하지 않을 수 있다)
• Diminished gradient
• Mode collapse (low diversity)
• No explicit representation of
이는 생성자가 원하는 분포 를 정확하게 모델링하기 어렵게 만들어 학습 과정을 어렵게 만들 수 있다.
• Sensitive to the hyper-parameter selections, and so need to manually babysit during training.
예를 들어, 학습률, 배치 크기 등의 하이퍼파라미터를 적절하게 선택하지 않으면 훈련이 제대로 수렴하지 않을 수 있다. 이로 인해 훈련 과정에서 하이퍼파라미터를 수동으로 조정해야 할 필요가 있다.
• No evaluation metric, so unclear stopping criteria and hard to compare with other models. (평가 지표가 없어서 중단 기준이 명확하지 않고 다른 모델과의 비교가 어렵다.)
Discriminator is not a good metric in measuring the image quality or its diversity.
(Inception Score and Frechet Inception Distance measure the performance of GAN.)
GAN의 생성된 이미지의 품질을 정량적으로 측정하기 어렵다.
GAN의 성능을 평가하기 위해 인셉션 스코어나 프레셰 인셉션 거리와 같은 측정 지표를 사용하는 것이 일반적입니다.
Difficulty in Training GAN
Non-convergence in two-player minimax problem
• In the original GAN objective, the update of G and D is done independently with no respect to other player in the game.
• Even if each player successfully moves downhill on that player’s update, the same update might move the other player uphill.
• Sometimes two players reach Nash equilibrium, which is the unique globally optimal solution. In other scenarios, they repeatedly undo each other’s progress without arriving anywhere useful.
• In practice, GAN’s loss functions often seem to oscillate (not to converge) without eventually reaching an equilibrium.
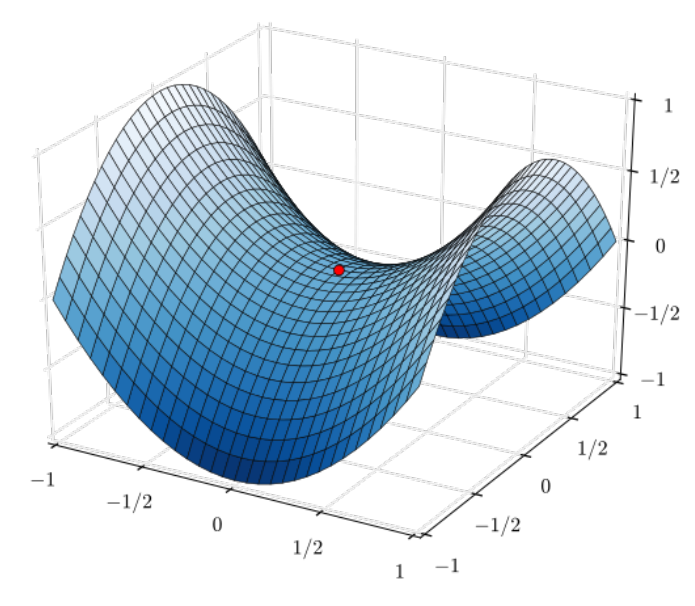
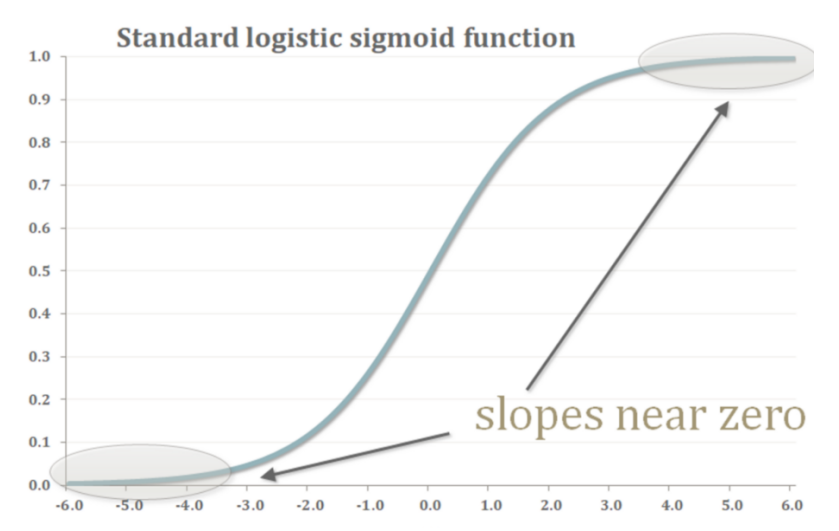
Diminished gradient
• If discriminator D is too powerful, generator G would fail to train effectively.
Since D tells that the generated images are fake, is always close to 0.
• If D is too lenient, the generated images are useless.
Then G is able to fool D easily.
• In either case, learning stops for both neural networks because neither one is receiving any feedback on how to get better.
Mode collapse (most severe form of non-convergence)
• Real-life data distributions are multimodal.
Ex. MNIST dataset has 10 major modes.
• The generator does not cover all the data distribution and loses diversity.
It easily gets trapped in local optima by memorizing training data, and so it will continue to generate similar images.
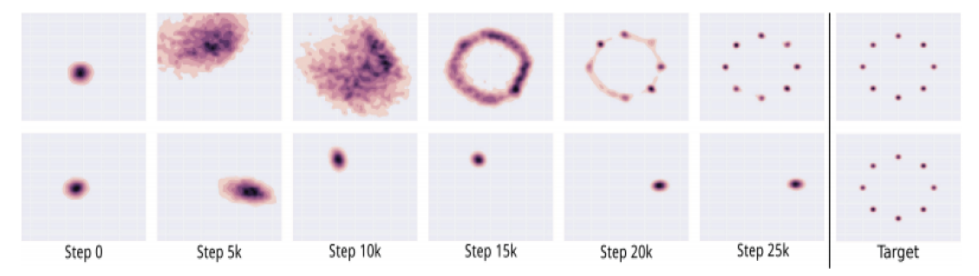
다양성이 없어진다.
Deep Convolutional GAN (DCGAN)
• DCGAN is a successful network for GAN and unsupervised learning with CNN.
DCGAN은 Deep Convolutional Generative Adversarial Network의 약어로, CNN(Convolutional Neural Network)을 사용한 GAN(Generative Adversarial Network)의 성공적인 구조입니다.
• The generator has interesting vector arithmetic properties allowing for easy manipulation of many semantic qualities of generated samples.
DCGAN은 이미지 생성에 특화된 네트워크 구조로, CNN을 사용하여 생성자(Generator)와 판별자(Discriminator)를 구성합니다. 생성자는 잠재 벡터(latent vector)를 입력으로 받아 실제 이미지와 유사한 가짜 이미지를 생성하는 역할을 합니다. 판별자는 실제 이미지와 생성자가 생성한 가짜 이미지를 구별하는 역할을 합니다.
CNN 아키텍처: DCGAN은 CNN을 사용하여 이미지의 공간적 특징을 추출하고 처리합니다. 이는 이미지 생성에 더 적합하며, 고해상도 이미지의 생성에도 효과적입니다.
DCGAN은 이미지 생성 및 비지도 학습에 효과적인 모델로 평가되며, CNN을 기반으로 한 GAN의 중요한 발전 중 하나입니다. 이 모델은 다양한 분야에서 이미지 생성, 데이터 확장, 도메인 변환 등에 활용될 수 있습니다.

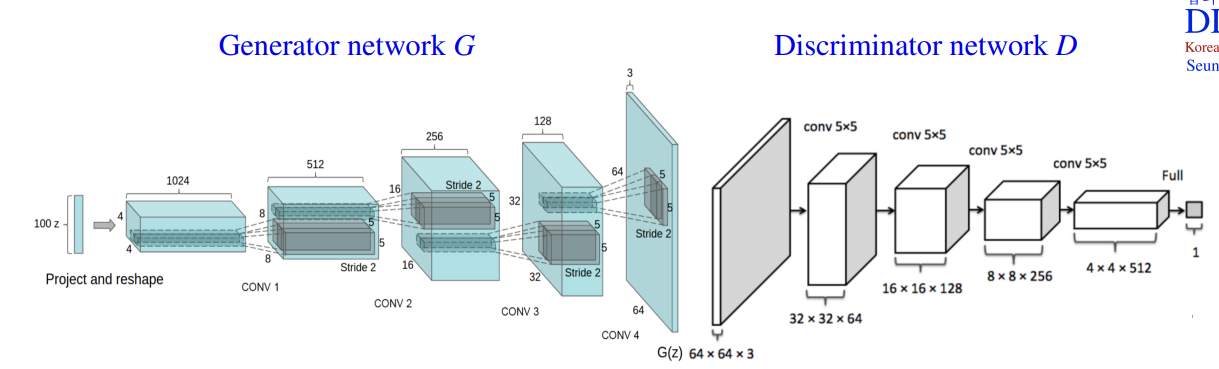
DCGAN architecture
• Generator uses fractionally-strided (or transposed) convolutions for up-sampling.
생성자(Generator)는 Up-sampling을 위해 fractionally-strided (또는 transposed) convolutions을 사용합니다. 이를 통해 점진적으로 이미지를 확대하면서 가짜 이미지를 생성합니다. Up-sampling 과정에서는 이미지의 크기를 키우고 상세한 특징을 복원하는 역할을 수행합니다.
• Discriminator uses convolutions with stride for down-sampling.
판별자(Discriminator)는 Down-sampling을 위해 stride를 사용하는 convolutions을 사용합니다. 이를 통해 이미지의 크기를 줄이고, 점진적으로 이미지의 특징을 추상화하여 실제 이미지와 생성된 이미지를 구별하는 역할을 수행합니다.
• Remove max pooling and FC hidden layers in convolution networks.
최대 풀링과 완전 연결(hidden) 레이어를 제거합니다. DCGAN에서는 최대 풀링 대신에 stride를 사용하여 다운샘플링을 수행하며, 완전 연결 레이어를 사용하지 않습니다. 이를 통해 더 많은 이미지의 공간 정보를 유지하고, 파라미터의 수를 줄여 모델을 더 간단하게 만듭니다.
• Use batch normalization in both Generator and Discriminator.
Generator와 Discriminator 모두 배치 정규화(batch normalization)를 사용합니다. 배치 정규화는 네트워크의 안정성과 학습 속도를 향상시키는 데 도움을 주는 방법입니다. Generator와 Discriminator의 각 레이어에서 입력 데이터의 정규화를 수행합니다.
• Generator uses ReLU activation except for the output which uses tanh (−1, 1).
생성자는 출력을 제외한 모든 레이어에 ReLU 활성화 함수를 사용합니다. ReLU는 비선형성을 도입하여 네트워크가 다양한 특징을 학습하고 복잡한 패턴을 표현할 수 있게 합니다. 생성된 이미지의 출력은 tanh 함수를 사용하여 값의 범위를 [-1, 1]로 조정합니다.
• Discriminator uses LeakyReLU except for the output which uses sigmoid (0, 1).
판별자는 출력을 제외한 모든 레이어에 LeakyReLU 활성화 함수를 사용합니다. LeakyReLU는 ReLU와 비슷하지만, 음수 입력 값에 대해 작은 기울기를 가집니다. 이는 네트워크의 표현 능력을 향상시키고, 그래디언트 소실 문제를 완화하는 데 도움을 줍니다. 판별자의 출력은 sigmoid 함수를 사용하여 값을 [0, 1] 범위로 조정합니다.
• Latent vectors capture interesting patterns (vector arithmetic).
DCGAN의 장점 중 하나는 잠재 벡터(latent vector)의 흥미로운 패턴을 포착할 수 있다는 것입니다. DCGAN에서 잠재 벡터는 이미지의 다양한 시맨틱 특징을 표현하는 역할을 합니다. 이러한 잠재 벡터는 벡터 간의 산술 연산을 통해 이미지의 시맨틱 품질을 쉽게 조작할 수 있는 흥미로운 특성을 가지고 있습니다. 예를 들어, 두 개의 잠재 벡터를 보간(interpolation)하여 그 사이의 점들을 생성하면, 이미지의 외관이 부드럽게 변화하는 모습을 볼 수 있습니다. 이는 DCGAN이 학습된 잠재 벡터 공간이 시맨틱 속성을 유지하면서 자연스러운 이미지 변환을 가능하게 한다는 것을 보여줍니다.
따라서, DCGAN은 잠재 벡터 공간에서 원하는 특징을 표현하기 위한 휴리스틱 방법이나 잠재 벡터 간의 보간을 통해 이미지의 시맨틱 특성을 조작하는 것이 가능합니다. 이러한 특성은 DCGAN의 생성자와 판별자의 아키텍처가 이미지 생성 및 분류에 탁월한 성능을 발휘하고 있다는 것을 보여줍니다.
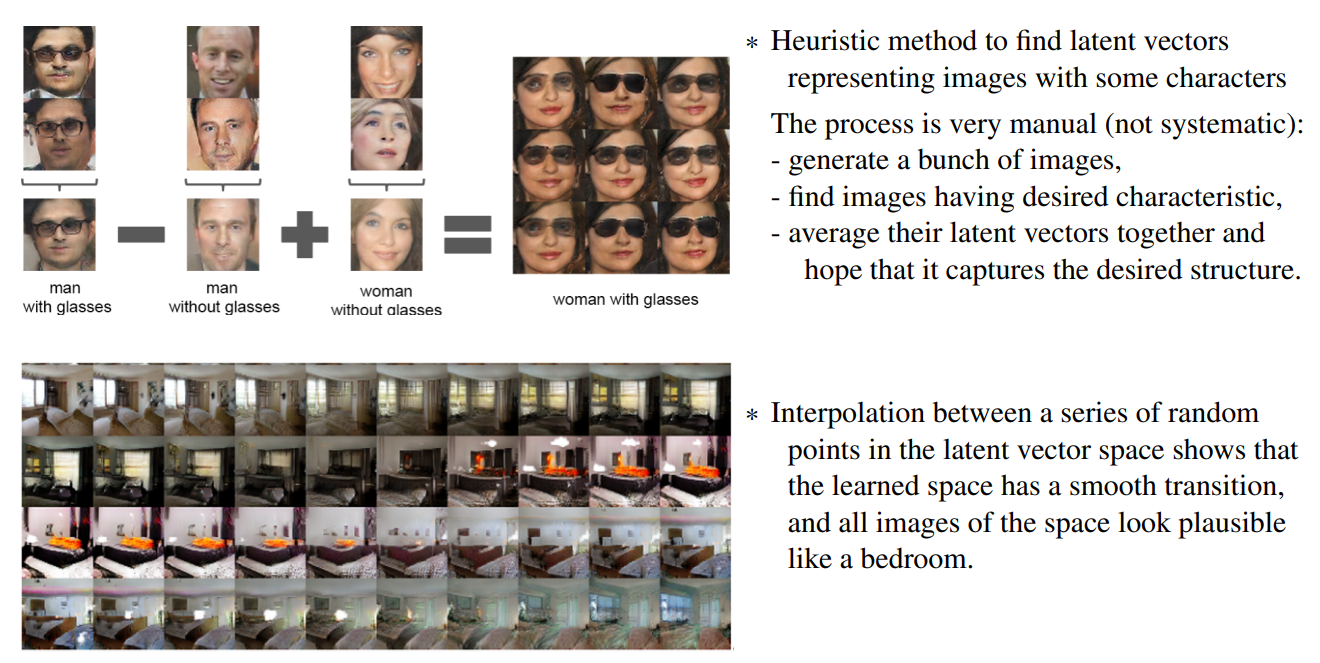
잠재 벡터 공간에서 특정한 특징을 나타내는 이미지의 잠재 벡터를 찾기 위한 휴리스틱 방법
이미지 생성: 먼저, 생성자를 사용하여 다양한 잠재 벡터를 입력으로 사용하여 이미지를 생성합니다. 생성된 이미지는 다양한 시각적 특징을 가질 수 있습니다.
원하는 특징 탐색: 생성된 이미지 중에서 원하는 특징을 가진 이미지를 찾습니다. 예를 들어, "침실"이라는 특징을 가진 이미지를 찾고자 한다면, 침실을 나타내는 이미지를 탐색합니다.
잠재 벡터 평균화: 원하는 특징을 가진 이미지를 찾은 후, 해당 이미지의 잠재 벡터를 추출하여 평균화합니다. 이를 통해 원하는 특징을 잘 포착하는 잠재 벡터를 생성할 수 있습니다.
기대하는 특징 포착: 잠재 벡터의 평균화를 통해 얻은 벡터를 사용하여 이미지를 생성하면, 해당 특징을 가진 이미지를 생성할 수 있습니다. 이는 기대하는 특징을 잘 포착한 잠재 벡터를 찾는 데 도움을 줍니다.
이 방법은 매우 수동적인 과정으로, 시스템적이지 않습니다. 원하는 특징을 가진 이미지를 찾기 위해 여러 이미지를 생성하고, 수작업으로 확인해야 합니다. 그 후, 해당 이미지들의 잠재 벡터를 평균화하여 기대하는 특징을 포착할 수 있는 잠재 벡터를 찾습니다.
또한, 잠재 벡터 공간에서 임의의 점들 사이에서 보간(interpolation)을 수행하면, 학습된 공간이 부드러운 전환을 가지며 공간 내의 모든 이미지가 현실적으로 보이는 부작용을 확인할 수 있습니다. 이는 잠재 벡터 공간이 다양한 시맨틱 특징을 포착하고, 이미지 간의 자연스러운 변환을 가능하게 한다는 것을 의미합니다. 이를 통해 침실이나 다른 시맨틱 속성을 가진 이미지들을 잘 탐색하고 조작할 수 있게 됩니다.
Progressive growing GAN (PGGAN)
Progressive growing GAN (PGGAN)은 점진적으로 해상도를 높여가며 네트워크 D와 G에 레이어를 추가하여 학습하는 훈련 방법론입니다.
• Training methodology for PGGAN is starting with a low resolution image, and then progressively increase the resolution by adding layers to the networks D and G.
• This incremental nature allows the training to first discover large-scale structure of the image, and then shift attention to increasingly finer scale details during training.
• This both speeds the training up and greatly stabilizes it, producing high resolution images
PGGAN의 훈련 방법은 낮은 해상도의 이미지로 시작하여 네트워크 D와 G에 레이어를 점진적으로 추가하여 해상도를 증가시킵니다. 이러한 점진적인 접근 방식은 훈련 과정에서 먼저 이미지의 대규모 구조를 발견하고, 그 다음에 점점 미세한 세부 사항에 주목할 수 있도록 합니다. 이는 훈련 속도를 높이고 안정성을 크게 향상시켜 고해상도 이미지를 생성하는 데 도움을 줍니다.

Progressive Growing of GANs for Improved Quality, Stability, and Variation, NVIDIA 2017
• Start training with both D and G having a low resolution of 4×4 pixels.
• During training, we incrementally add layers to D and G to increase the resolution.
• All existing layers can be trained throughout the process.
• This allows stable synthesis in high resolutions, and also training speed is increased.
PGGAN의 훈련은 초기에 D와 G 모두 4×4 픽셀의 낮은 해상도로 시작합니다. 그리고 훈련 중에 D와 G에 레이어를 점진적으로 추가하여 해상도를 높입니다. 기존의 모든 레이어는 훈련 과정 전체에서 계속해서 학습됩니다. 이는 고해상도에서의 안정적인 합성을 가능하게 하며, 훈련 속도도 증가시킵니다.
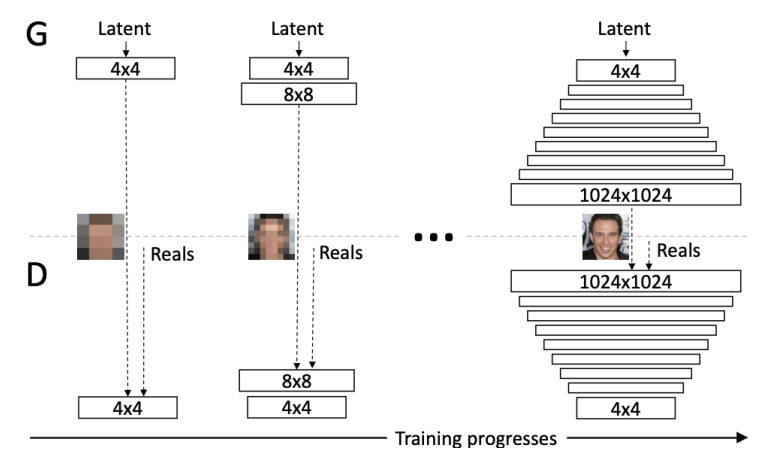
PGGAN은 해상도를 점진적으로 키워가는 훈련 방식을 통해 고해상도 이미지를 안정적으로 생성할 수 있다는 장점을 가지고 있습니다. 이러한 방식은 먼저 전체 이미지의 구조를 학습하고, 이후에 점점 세부적인 특징을 학습함으로써 더욱 풍부하고 세밀한 이미지를 생성하는 데에 도움이 됩니다. 또한, 훈련 과정에서 안정성이 크게 향상되고, 학습 속도도 향상되어 고해상도 이미지의 생성과 훈련을 효과적으로 수행할 수 있습니다.
Conditional GAN (cGAN)
cGAN is a simply extended version to a conditional model so that both D and G are conditioned on some extra information y such as class labels
cGAN은 기존의 생성적 적대 신경망(GAN)에 추가적인 입력 정보인 y인 클래스 레이블과 같은 조건을 주는 방식입니다. 이를 통해 생성자와 판별자는 주어진 클래스 레이블에 대한 조건에 맞춰 이미지를 생성하고 판별합니다.
D와 G가 클래스 레이블과 같은추가 정보 y에 대해조건이 추가된 모델
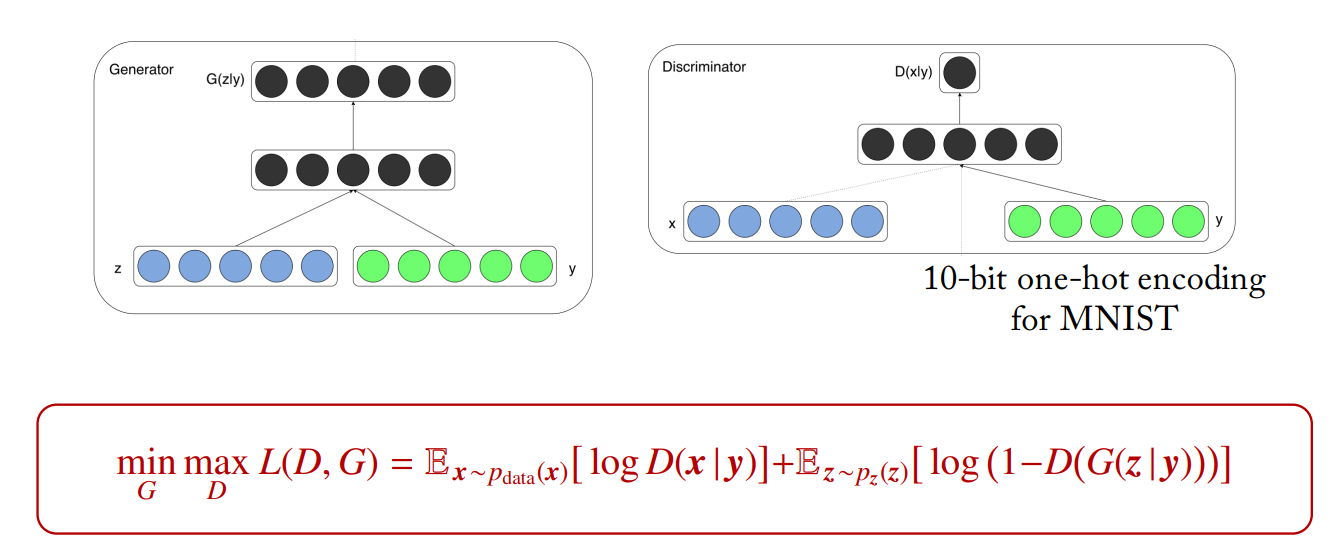
Conditional Generative Adversarial Nets, 2014
• MNIST: each row is conditioned on one label by one-hot encoding.

• Face aging with cGAN

cGAN은 기존의 생성적 적대 신경망(GAN)에 추가적인 입력 정보인 y인 클래스 레이블과 같은 조건을 주는 방식입니다. 이를 통해 생성자와 판별자는 주어진 클래스 레이블에 대한 조건에 맞춰 이미지를 생성하고 판별합니다.
cGAN은 일반적인 GAN의 구조와 유사하게 작동하지만, 생성자 G와 판별자 D가 입력 데이터 x뿐만 아니라 클래스 레이블 y에 대해 조건을 추가적으로 고려합니다. 이렇게 함으로써 생성자는 특정 클래스에 해당하는 이미지를 생성하도록 학습되며, 판별자는 입력 이미지의 실제/가짜 여부를 판별하는 동시에 클래스 레이블에 대한 조건을 고려합니다.
cGAN은 다양한 응용 분야에서 활용될 수 있습니다. 예를 들어, 이미지 생성에서는 특정한 클래스(예: 고양이, 개, 자동차 등)에 해당하는 이미지를 생성할 수 있으며, 이미지 변환에서는 주어진 입력 이미지를 다른 클래스로 변환하는 작업에 사용될 수 있습니다. 이처럼 cGAN은 데이터 생성과 변환 작업에서 추가 정보에 따라 생성 및 변환 결과를 조절할 수 있는 강력한 방법론입니다.
Pix2Pix with cGAN
• Pix2Pix is a cGAN oriented to image-to-image translation tasks, especially those involving high resolution outputs.

Pix2Pix는 주로 그래픽 → 사진과 같은 이미지 간 변환 작업에 사용되는 cGAN입니다. 무조건적인 GAN과 달리 Pix2Pix는 입력 그래픽 x를 관찰합니다. 이를 통해 생성자와 판별자는 입력 그래픽을 바탕으로 출력 이미지를 생성하고 평가합니다.
Pix2Pix는 이미지 간 변환 작업에서 탁월한 결과를 보여줍니다. 그래픽 → 사진, 흑백 → 컬러 등과 같은 다양한 변환 작업에서 실제같은 고해상도 출력을 생성할 수 있습니다. 이를 통해 예술적인 이미지 스타일 변환, 도시 풍경의 지오메트릭 변환 등 다양한 응용 분야에서 활용될 수 있습니다.
• cGAN maps graphic → photo.
Unlike an unconditional GAN, both observe the input graphic x.
• Generator uses U-Net, which is an encoder-decoder with skip connections between mirrored layers.
• Discriminator uses a convolutional PatchGAN classifier, which only penalizes structure at the scale of image patches N×N, so it tries to classify if each patch is real or fake
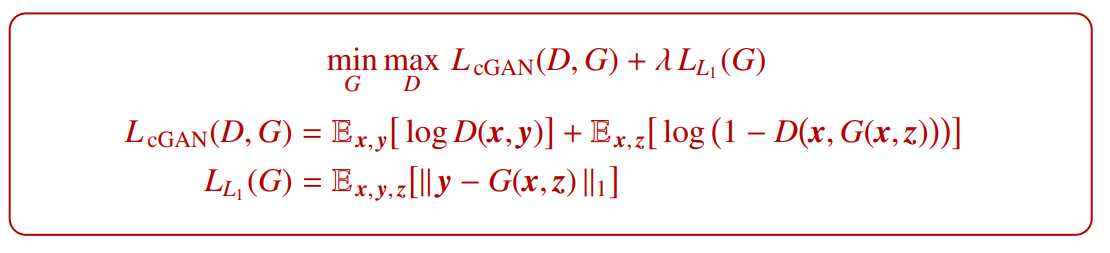
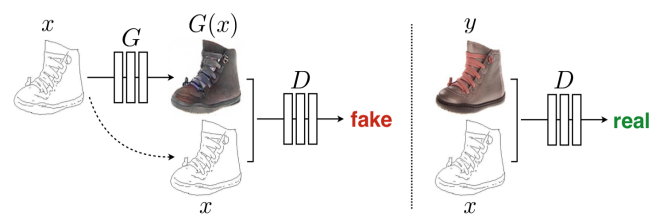

Pix2Pix에서는 U-Net이라는 인코더-디코더 구조를 사용하는 생성자를 사용합니다. U-Net은 대칭된 레이어 사이의 스킵 연결을 가지고 있어 정보의 흐름을 보존하면서 상세한 특징을 전달할 수 있습니다. 이를 통해 입력 그래픽과 유사한 형태의 사진을 생성할 수 있습니다.
판별자는 컨볼루션 PatchGAN 분류기를 사용합니다. PatchGAN은 이미지 패치의 크기 N×N에서 구조를 판별하는데 사용됩니다. 이 방식은 각 패치가 실제인지 가짜인지를 분류하는 것을 목표로 하며, 전체 이미지의 구조를 판별하고자 하는 특징에 집중합니다.
• Different losses induce different quality of results.

If we take a na¨ıve CNN to minimize L1 distance between predicted and ground truth pixels, it will tend to produce blurry results, which do not look real images. This is why we use GAN to generate sharper images.
서로 다른 손실 함수는 결과물의 품질에 영향을 줍니다. 예측된 픽셀과 실제 픽셀 간의 L1 거리를 최소화하는 단순한 CNN을 사용하면 흐릿한 결과물이 생성되는 경향이 있습니다. 이는 실제 이미지와 유사하지 않은 흐릿한 이미지를 생성하게 됩니다. 이러한 이유로 GAN을 사용하여 더 선명한 이미지를 생성합니다.
• Patch size variations.

Pix2Pix와 같은 이미지 변환 작업에서는 패치 크기를 고려해야 합니다. 패치 크기가 작으면 작은 지역에 대한 세부 정보를 고려할 수 있지만, 전체 이미지에 대한 일관성을 보장하기 어렵습니다. 패치 크기가 크면 전체 이미지에 대한 일관성은 높아지지만 작은 지역의 세부 정보는 무시될 수 있습니다. 따라서 패치 크기는 결과물의 품질과 세부 정보의 보존 여부에 영향을 줄 수 있습니다. 알맞은 패치 크기를 선택하여 원하는 결과물을 얻을 수 있도록 조정해야 합니다.
Summary
DCGAN
- CNN(Convolutional Neural Network)을 사용한 GAN
- CNN을 사용하여 G(Generator)와 D(Discriminator)를 구성
- CNN을 사용하여 이미지의 공간적 특징을 추출하고 처리
- 비지도 학습: DCGAN은 비지도 학습 방식으로 동작
- 잠재 벡터의 각 차원(이미지의 특징)을 활용하여 생성된 샘플의 다양한 시맨틱 퀄리티(semantic qualities)를 쉽게 조작
- 이미지 생성에 특화된 네트워크 구조
PGGAN
- Progressive growing GAN (PGGAN)은 점진적으로 해상도를 높여가며 네트워크 D와 G에 레이어를 추가하여 학습하는 훈련 방법
- 낮은 해상도의 이미지로 시작하여 네트워크 D와 G에 레이어를 점진적으로 추가하여 해상도를 증가
- 이미지의 대규모 구조에서 세부 구조를 학습한다
- 훈련 속도를 높이고 안정성을 크게 향상시킨다
cGAN
- 추가적인 입력 정보인 y인 클래스 레이블과 같은 조건을 주는 방식
- D와 G가 클래스 레이블과 같은 추가 정보 y에 대해 조건이 추가된 모델
pix2pix
-Pix2Pix는 이미지 간 변환 작업에서 탁월한 결과를 보여줍니다. 그래픽 → 사진, 흑백 → 컬러 등과 같은 다양한 변환 작업에서 실제같은 고해상도 출력을 생성할 수 있습니다
출처
고려대학교 수학과 딥러닝의 수학 (오승상 교수)
https://sites.google.com/view/seungsangoh/home
