
출처 : 생활코딩(https://opentutorials.org/course/4570)
Tensorflow w/ python
오리엔테이션
- 머신 러닝 중 지도 학습 : 회귀(숫자), 분류(종류)
- 머신 러닝 알고리즘 예
- Decision Tree
- RandomForest
- KNN
- SVM
- Neural Network
- 인공신경망 = 딥러닝
- 인공신경망을 깊게 쌓아서 만든 기계라는 뜻
- 인간의 신경을 모방한 이론
- 딥러닝 이론을 코딩으로 이용할 수 있도록 하는 라이브러리 예시
- 텐서 플로우- PyTorch
- Caffe2
- Theano
지도학습의 빅피처
- 지도 학습의 과정
- 과거의 데이터를 준비
- 원인(독립변수)과 결과(종속변수)를 인식함 (중요!)
- 모델의 구조를 만듦
- 데이터로 모델을 학습(FIT) 한다 : 모델을 데이터에 맞게 피팅(FITTING) 한다.
- 모델 완성! 이용하기
판다스 : 표를 다루는 도구
import pandas as pd
# 파일들로부터 데이터 읽어오기
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/lemonade.csv'
레몬에이드 = pd.read_csv(파일경로)
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/boston.csv'
보스턴 = pd.read_csv(파일경로)
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/iris.csv'
아이리스 = pd.read_csv(파일경로)
# 변수 안에 어떤 데이터가 들어있는지 확인 - 데이터 모양으로 확인하기 (행,열)
print(레몬에이드.shape)
print(보스턴.shape)
print(아이리스.shape)
# 칼럼 이름 출력
print(레몬에이드.columns)
print(보스턴.columns)
print(아이리스.columns)
# 독립변수와 종속변수를 분리하여 저장
x = 레몬에이드[['온도']]
y = 레몬에이드[['판매량']]
print(x.shape, y.shape)
x = 보스턴[['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax',
'ptratio', 'b', 'lstat']]
y = 보스턴[['medv']]
print(x.shape, y.shape)
x = 아이리스[['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭']]
y = 아이리스[['품종']]
print(x.shape, y.shape)
레몬에이드.head()
보스턴.head()
아이리스.head()
딥러닝 실습
첫번째. 레몬에이드 판매 예측
- shape=[숫자] : 독립변수의 개수
- Dense(숫자) : 종속변수의 개수
- epochs : 전체 데이터를 몇번 반복하여 학습 시킬지를 정함
- Loss 손실

model.fit(독립, 종속, epochs = 10)- 몇번째 반복인지 / 각 학습마다 얼마의 시간이 걸렸는지 / 학습이 얼마나 진행되었는지(loss)
- 그 시점에 얼마나 정답에 가까이 맞추는 정도가 높아짐
- (예측-결과=Error)^2 의 평균 = LOSS
: 즉 0이 되면 예측 = 결과 이므로 학습이 완벽하게 된 모델이라고 할 수 있음
코드
#라이브러리 사용
import tensorflow as tf
import pandas as pd
#데이터 준비
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/lemonade.csv'
data = pd.read_csv(파일경로)
data.head()
# 종속변수, 독립변수
x = data[['온도']]
y = data[['판매량']]
print(x.shape, y.shape)
#모델 만들기
X = tf.keras.layers.Input(shape=[1])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
#모델 학습
model.fit(x, y, epochs=10000, verbose=0) # 화면 출력을 off
model.fit(x, y, epochs=10)
# 모델을 이요하기
model.predict(x)
model.predict([[15]])두번째. 보스턴 집값 예측
- 인공신경망에서 뉴런의 역할을 하는 것 : 만든 모형과 수식
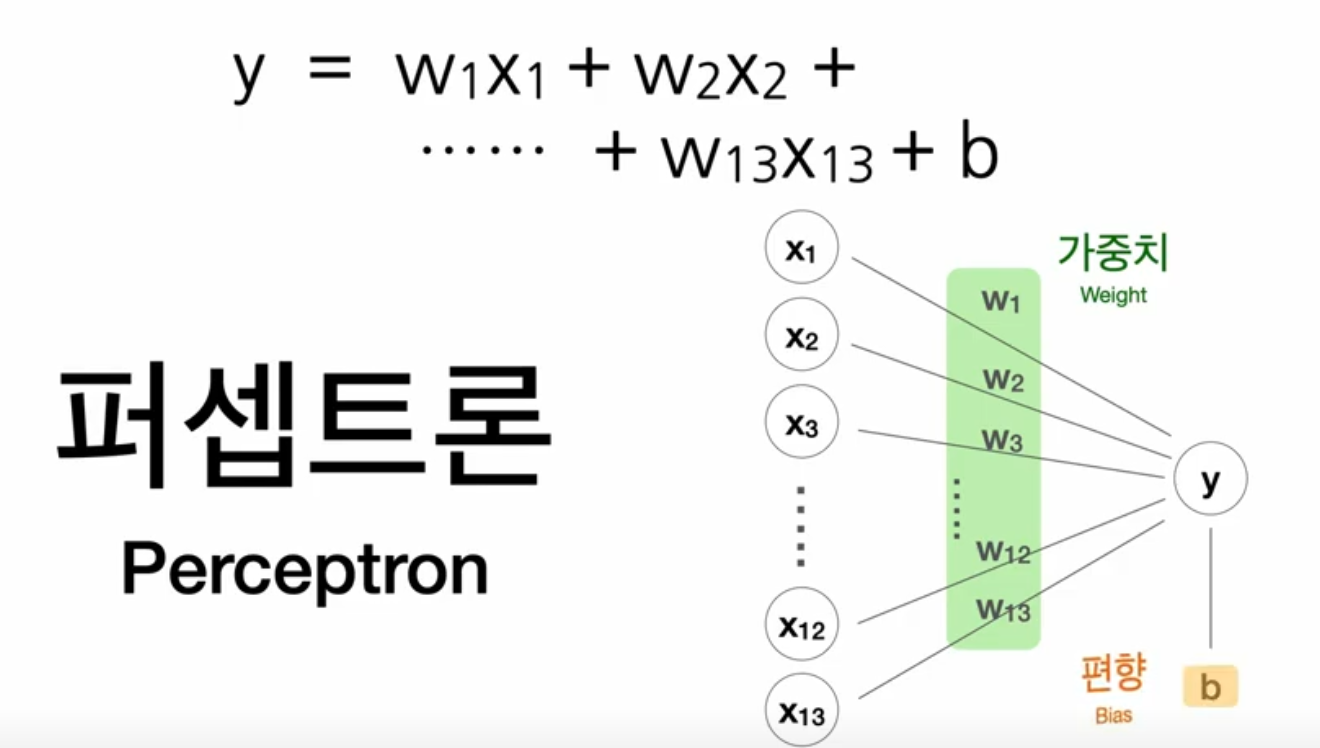
--> 퍼셉트론 Perceptron - 가중치(weight) w1,w2,w3... w13
- 편향(Bias) b
- 코드
# 라이브러리 사용
import tensorflow as tf
import pandas as pd
# 과거의 데이터 준비
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/boston.csv'
보스턴 = pd.read_csv(파일경로)
보스턴.head()
print(보스턴.columns)
# 모델의 구조 만듦
독립 = 보스턴[['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax',
'ptratio', 'b', 'lstat']]
종속 = 보스턴[['medv']]
print(독립.shape, 종속.shape)
x = tf.keras.layers.Input(shape=[13])
y = tf.keras.layers.Dense(1)(x)
model = tf.keras.models.Model(x,y)
model.compile(loss='mse')
# 데이터로 모델을 학습(FIT)
model.fit(독립, 종속, epochs=1000, verbose=0)
model.fit(독립, 종속, epochs=10, verbose=1)
# 모델을 이용
model.predict(독립[:5])
종속[0:5] #python의 슬라이싱(slicing)
# 모델의 수식 확인
model.get_weights()* 학습의 실제
- 수식의 가중치를 찾는 방법?
https://docs.google.com/spreadsheets/d/1-bg8CeN2I55og4nnFXcPBnIxdW_n1ToOdrfwd0_A5Qc/edit#gid=0
세번째. 아이리스 품종 종류
-
원핫인코딩(onehot-encoding)
python 아이리스 = pd.get_dummies(아이리스)
-> 품종.setosa , 품종.virginica, 품종.versicolor... -
소프트맥스 / cf. 시그모이드
-
비율을 예측하는데 사용 됨
-
softmax(함수 식) -> 결과 값을 0과 1 사이로 나오게 함
-
Indentity(y=x) 회귀모델
-
Softmax 분류모델
-
Activation 활성화 함수
-
categorical_crossentropy : mse(loss)를 계산하는 확률
-
metrics = 'accuracy' <- 0에서 1사이의 확률
-
코드
# 라이브러리 사용
import tensorflow as tf
import pandas as pd
# 과거 데이터 준비
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/iris.csv'
아이리스 = pd.read_csv(파일경로)
아이리스.head()
# 모델 구조 만들기 / 원핫인코딩
인코딩 = pd.get_dummies(아이리스)
인코딩.head()
인코딩.columns
# 독립변수와 종속변수
독립 = 인코딩[['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭']]
종속 = 인코딩[['품종_setosa', '품종_versicolor',
'품종_virginica']]
print(독립.shape, 종속.shape)
# 모델 구조 생성
x = tf.keras.layers.Input(shape=[4])
y = tf.keras.layers.Dense(3, activation='softmax')(x)
model = tf.keras.models.Model(x,y)
model.compile(loss = 'categorical_crossentropy',
metrics='accuracy') # 사람이 보기 편한 정확도라는 척도
# 데이터로 모델을 학습 (FIT)
model.fit(독립, 종속, epochs=100)
# 모델 이용하기
model.predict(독립[0:5])
print(종속[0:5])
model.predict(독립[-5:])
print(종속[-5:])
# 학습한 가중치 출력
model.get_weights()네번째. 신경망의 완성 : 히든 레이어
- 각각의 모델을 여러개 연결하여 하나의 모델을 만드는 것이 딥러닝, 인공지능망
x = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(5, activation='swish')(x) # 히든 레이어 추가
y = tf.keras.layers.Dense(1)(H) # x가 아닌 H임을 주의
model = tf.keras.models.Model(x,y)
model.compile(loss='mse')- swish는 최근에 발표된 성능 좋은 히든 레이어 활성화 함수
추가 실습
데이터타입 : 숫자형->범주형으로 바꾸기
import tensorflow as tf
import pandas as pd
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/iris2.csv'
아이리스 = pd.read_csv(파일경로)
아이리스.head()
# 원핫인코딩
인코딩 = pd.get_dummies(아이리스)
인코딩.head()
# 결과: 인코딩 되지 않음! -> 왜? 범주형이지만 숫자 데이터이기 때문에.
print(아이리스.dtypes)
# 품종 타입을 범주형으로 바꾸기
아이리스['품종'] = 아이리스['품종'].astype('category') # 아이리스의 품종 컬럼을 astype 함수로 '카테고리'로 바꿈
아이리스.dtypes
# 원핫인코딩
인코딩 = pd.get_dummies(아이리스)
인코딩.head()NA 데이터값 평균값으로 바꾸기
# NA값 체크해보기
아이리스.isna().sum() # column 별로 na가 있는지 합을 보여줌
아이리스.tail()
# NA값에 꽃잎폭 평균값 넣어주기
mean = 아이리스['꽃잎폭'].mean()
아이리스['꽃잎폭'] = 아이리스['꽃잎폭'].fillna(mean)
아이리스.tail()학습 모델 향상시키기
# 보스턴 집값 예측 데이터로 학습이 잘 되는 모델 만들기
- 사용할 레이어
- tf.keras.layers.BatchNomalization()
- tf.keras.layers.Activation('swish')
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/boston.csv'
보스턴 = pd.read_csv(파일경로)
독립 = 보스턴[['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax',
'ptratio', 'b', 'lstat']]
종속 = 보스턴[['medv']]
print(독립.shape, 종속.shape)
# 모델의 구조 만들기
X = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(8, activation='swish')(X) # 히든 레이어 3층 만들기
H = tf.keras.layers.Dense(8, activation='swish')(H)
H = tf.keras.layers.Dense(8, activation='swish')(H)
Y = tf.keras.layers.Dense(1)(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
model.fit(독립, 종속, epochs=1000)
# 결과가 아주 만족스럽지는 않음
# BatchNormalization을 사용해 성능 높이기
X = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(8)(X)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(8)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(8)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
Y = tf.keras.layers.Dense(1)(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
model.fit(독립, 종속, epochs=1000, batch_size=150)
# loss가 10대 초반으로 떨어짐
시작