
자바스크립트에서 빠질 수 없는 prototype
자바스크립트는 프로토타입 기반 언어다.
자바스크립트는 기존의 객체를 복사하여 새로운 객체를 생성하는 프로토타입 기반 언어이다.
프로토타입을 보기 전 constructor, instance, 객체에 대해 먼저 알아야할 것이 있다.
constructor 생성자 함수
자바스크립트에서 함수를 일반적으로 연산등의 실행문 묶음을 위해서 쓰지만, 다른 객체를 생성하는 용도로도 쓰일 수 있다.
이렇게 다른 개체를 생성하는데 사용되는 함수를 생성자 함수라고 한다.
보통 함수 이름 맨앞을 대문자로 쓴다.
instance 인스턴스
new 생성자함수()를 통해 만들어진 객체
<script>
function func(name){
this.name = name;
console.log(name);
};
const example1 = new func("soyeon");
</script>
이 예시에서 example1을 생성함과 동시에 function func는 생성자 함수가 된다.
example1은 function func의 인스턴스라고 한다.
자바스크립트 객체
자바스크립트의 function, array, object는 모두 Object이다.
const func = function(){};
const arr = [];
const obj = {};실은 이것 모두 아래와 같다
const func = new Function();
const arr = new Array();
const obj = new Object();
//각각의 함수들 모두 따라 파라미터 받지 않고 실행요구하는 statement도 없기 때문에 빈 것으로 생성됨함수, 배열 등 자바스크립트로 만든 것은 자바스크립트에서 거의 다 객체라고 봐도 무방하다!!
이제 본격적으로 프로토타입을 공부할 준비가 되었다.
prototype property
프로토타입은 객체의 원형을 말한다.
함수와 함께 반려자처럼 함께 만들어지는 prototype 객체 내에 있는 property이다.
(함수객체만 가지고 있다)
<script>
function Student(name, grade){
this.name = name;
console.log(this.name);
}
const soyeon = new Student("soyeon", 1);
//function Student는 생성자 함수, soyeon은 인스턴스
</script>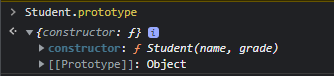
Student.prototype을 살펴보면 constructor는 Student인 것을 알 수 있다.
이렇게만 보면 constructor, instance, prototype 3개가 굉장히 헷갈린다.
이 세개를 유전자 전달의 관계로 생각하면 보다 이해하기 쉽다.
constructor = 부모,
prototype = 유전자,
instance = 자식Student 예시로 살펴보면
<script>
//constructor = 부모,
function Student(name, grade){
this.name = name;
console.log(this.name);
}
//prototype: 유전자
Student.prototype
const soyeon = new Student("soyeon", 1);//soyeon 객체는 자식 객체
</script>그래서 Prototype 어떻게, 왜 쓰는건데?(feat.prototype 체인)
<script>
function Citrus(name){
this.name = name;
this.taste = "mostly sour";
this.inner = "juicy";
console.log(this.name);
}
const lemon = new Citrus();
const bergamot = new Citrus();
console.log(lemon.taste);//mostly sour
console.log(bergamot.taste);//mostly sour
console.log(lemon.inner);//juicy
console.log(bergamot.inner);//juicy
</script>Citrus의 taste, inner는 Citrus 함수가 가지고 있는 statement이기 때문에 새로운 인스턴스들이 생겨날 때마다 각각 다른 메모리에 들어간다.
//lemon 저장 메모리
{taste: "mostly sour", inner: "juicy"}
//bergamot 저장 메모리
{taste: "mostly sour" inner: "juicy"}인스턴스마다 생기는 taste, inner는 사실 같은 내용인데도 따로 저장해야하므로 인스턴스 양이 몇 백개로 많아지면 이는 메모리 낭비가 된다.
이렇게 하나의 생성자 함수(부모)에서 새로운 생성되는 인스턴스(자식)마다 계속 같은 것을 줄 경우 prototype에 저장하면 인스턴스는 이 것을 사용할 수 있게 되어 메모리를 효율적으로 쓸 수 있다.
<script>
function Citrus(name){
this.name = name;
console.log(this.name);
}
//인스턴스 공통인 데이터는 prototype(유전자)에 저장한다.
Citrus.prototype.taste = "mostly sour";
Citrus.prototype.inner = "juicy";
const lemon = new Citrus("lemon");
const bergamot = new Citrus("bergamot");
</script>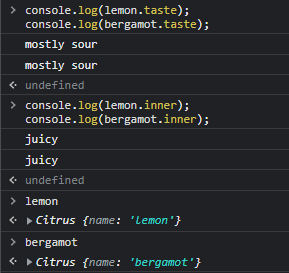
위의 사진을 보면 lemon과, bergamot은 분명 taste와 inner 값을 선언하지 않았는데도 값이 존재하게 된다. 그 이유는 바로 prototype(유전자)에 이미 저장이 되어있기 때문이다.
인스턴스 자체에서 정의하지 않은 속성은 부모의 유전자(property)에서 가진 속성으로 대신한다.
그리고 만약 바로 위 단계의 부모 property에 존재하지 않는다면 그 위의 부모...이런식으로 적용이 된다. 이것을 '프로토타입 체인'이라고 한다.
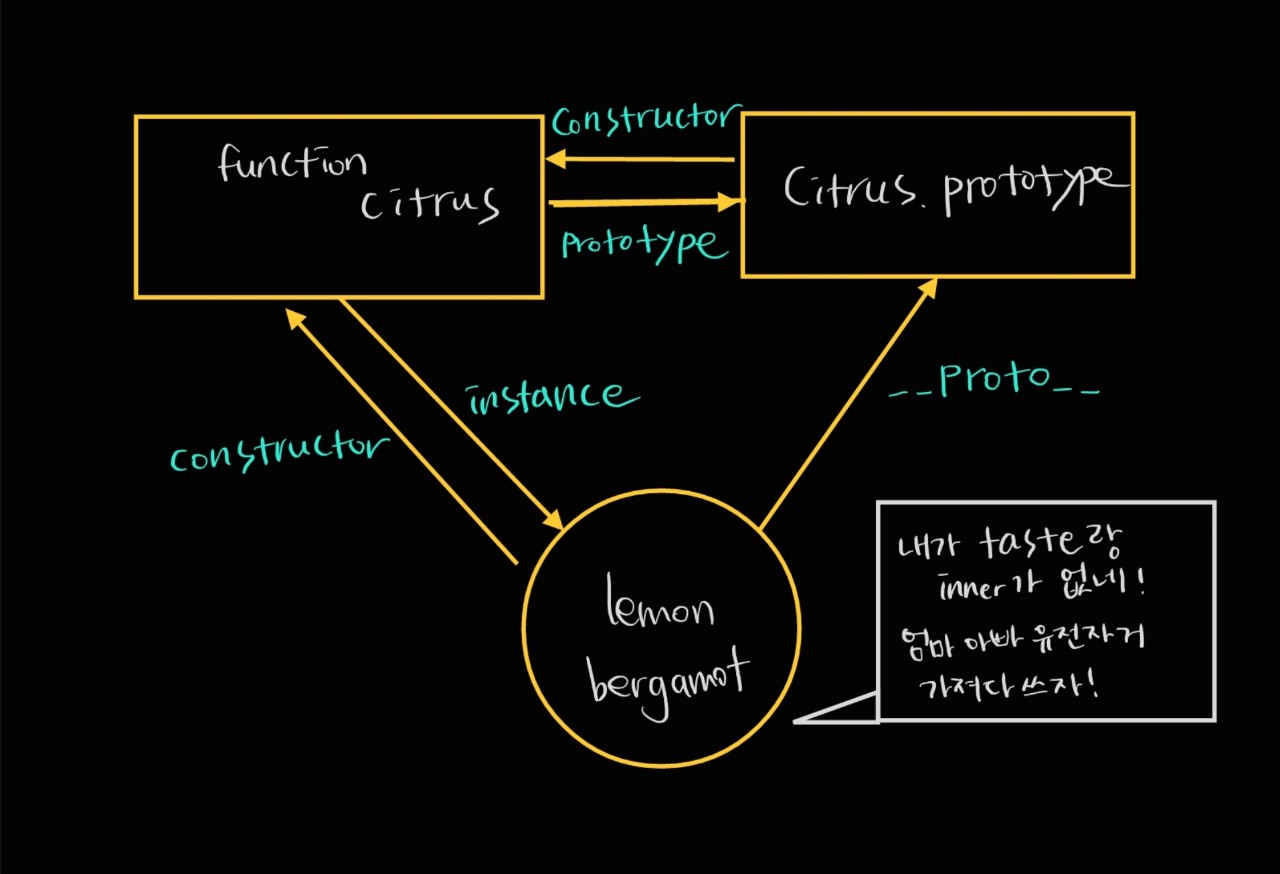
__proto__
일명 자식이 부모님 유전자 찾는 법.
instance가 constructor의 prototype을 찾는 방법이다.
ex) lemon.__proto__
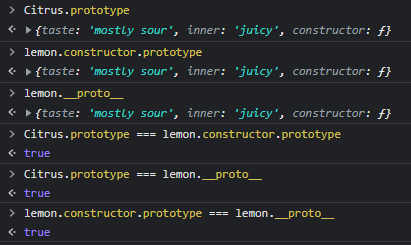
생성자함수.prototype === 인스턴스.constructor.prototype === 인스턴스.__proto__
라는 흥미로운 사실을 알 수 있다!!
프로토타입의 최상위: null
함수, Array 등은 모두 다 Object라는 것은 자바스크립트 객체 부분에서 알 수 있었다.
그럼 Object의 최상위는 무엇일까?
바로 null이다. 자바스크립트의 모든 것은 결국 Object이기 때문에 그 상위의 것은 존재할 수 없는 것이다. Object는 자바스크립트의 시조...유일 신 같은 너낌이다.
<script>
Object.prototype.__proto__ -> null
</script>출처
https://medium.com/@bluesh55/javascript-prototype-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-f8e67c286b67
Hash Table 해시 테이블
해쉬 브라운 밖에 난 몰라 근데 해쉬 아니고 해시래
What is Hash?
여러 개의 데이터를 한정된 길이의 데이터에 mapping한 값
Hashing은 mapping하는 행위
** mapping: 하나의 값을 다른 값으로 대응시키는 것
출처: http://wiki.hash.kr/index.php/%EB%A7%A4%ED%95%91
Hash Table
A hash table is a data structure that you can use to store data
in key-value format with direct access to its items in constant time.
해시 테이블은 데이터를 key-value 형식으로 저장하기 위해 사용할 수 있는 데이터 구조이며,
이 데이터 접근에 소요되는 시간은 일정하다해시 테이블의 대표적인 예시는 전화번호부, 사전 등이 있다.
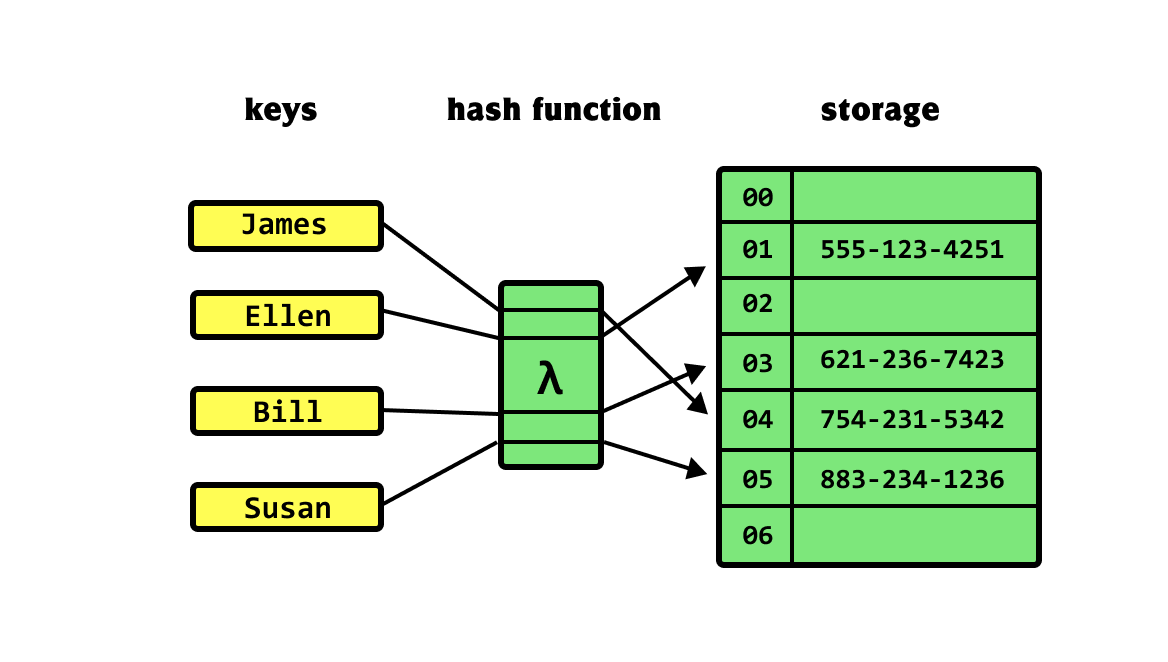
출처: https://khalilstemmler.com/blogs/data-structures-algorithms/hash-tables/
다른 말로 설명해보자면 Hash Table은
사용자가 key와 value를 입력
-> Hash function에 의해 key ---> 데이터를 넣을 공간의 index(숫자)로 변경
-> 해당 index에 value 저장사전 형식을 예로 일반적인 배열과 Hash Table의 차이점을 비교하면 다음과 같다
//일반 Array
const myFruits = [
{name: apple, number: 2},
{name: banana, number: 7},
{name: watermelon, number: 1},
{name: peach, number: 4}
]
//watermelon number??일반 Array에서 watermelon을 검색하려면 myFruits에 접근하여 처음부터 순서대로 살펴봐야한다.
이걸 Hash Table로 나타내면 다음과 같다
//Hash table
const myFruits = {
apple: 2,
banana: 7,
watermelon: 1,
peach: 4
}
//watermelon number??이러면 watermelon을 찾으면 바로 number가 나오기 때문에 값을 일정한 속도로 보다 빠르게 찾을 수 있다.
값을 추가/삭제할 때도 hash function이 index를 항상 지정해주고 지정된 index에 대입/삭제하기 때문에 시간은 일정하다.
Hash Table 장단점
- 장점: key와 value를 한정된 공간에 저장하고 그걸 빠르게 찾을 수 있다.
- 단점
- 순서가 중요한 배열의 경우 적절하지 않다(따라서 Big O Access는 N/A)
(순서 상관없이 hash function의 결과대로 index를 배정하고 여기저기 데이터를 넣기 때문) - 공간 효율성이 떨어진다 : 데이터 저장 전 미리 저장 공간이 있어야 한다.
- Hash function에 따라 시간 복잡도가 달라질 수 있다.
- 순서가 중요한 배열의 경우 적절하지 않다(따라서 Big O Access는 N/A)
Hash Table 시간 복잡도
일반적으로 O(1)으로 항상 일정하다.
hash function이 항상 하나의 index를 만들어주고, 그 index에 바로 자료가 있기 때문에
자료를 삭제, 추가, 검색 모두 시간은 O(1)이다.
하지만 hash function에 따라서는 최악의 경우 O(n)까지 될 수 있다.
해시 충돌 Hash Collision
하지만 이렇게 좋아보이는 해시 테이블도 위험이 있으니...
바로 서로 다른 데이터 값을 입력해도 hash function에 의해 같은 index값이 나와서 같은 저장소에 여러 개의 데이터가 들어가야 할 경우가 발생할 수 있다.
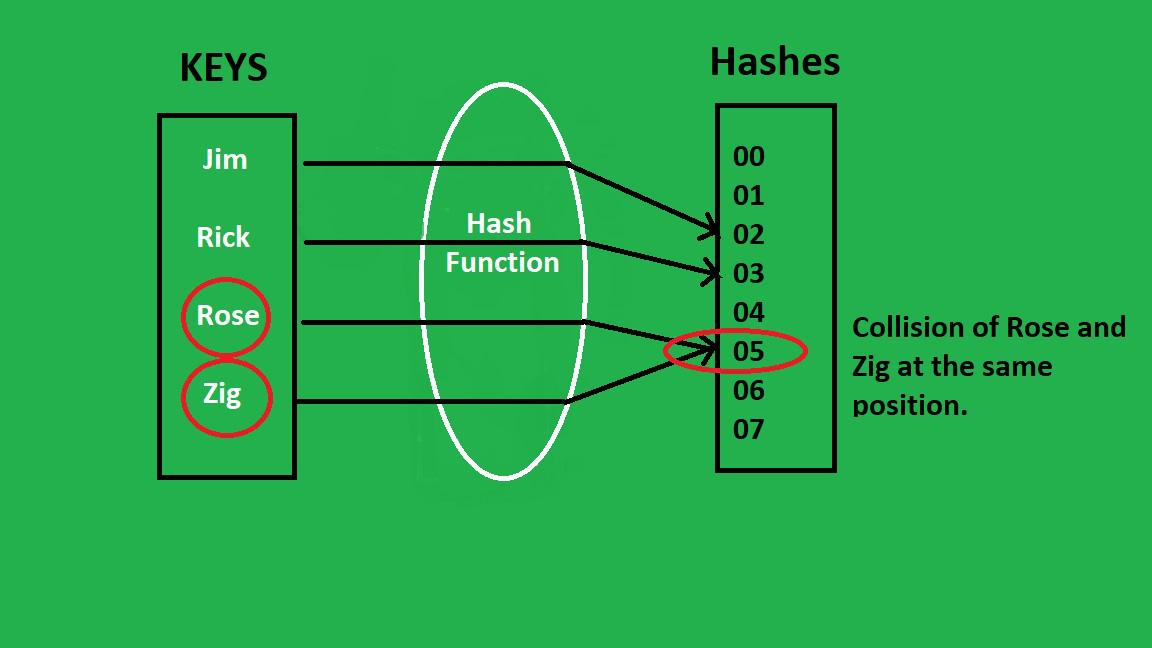
이런 식으로 데이터의 index가 겹치게 되는 현상을 Hash Collision이라고 한다.
해시 충돌 해결법
(1) separate chaining
해시 충돌이 발생할 때 충돌이 발생한 데이터끼리 Linked List 형식으로 저장시키는 것
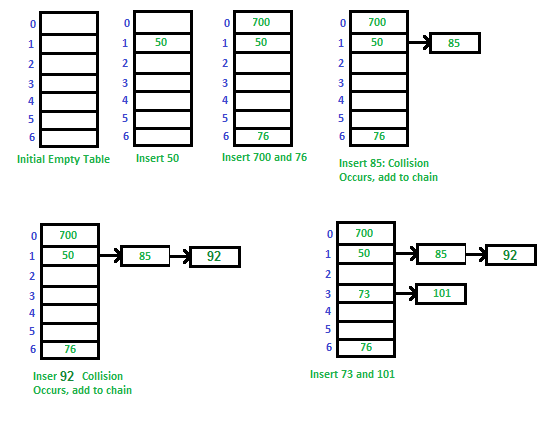
ex)
//어떤 데이터를 입력하면 특정한 숫자로 반환하는 hash function이 있다고 가정
'summer: hot' --> (put in hash function) --> index = 333,
--> index 333 위치에 데이터 [summer: hot] 형태로 입력
'winter: cold' ---> (put in hash function) --> 333, index 333의 1번째로 입력summer와 winter 데이터는 chaining 된 관계가 되었다.
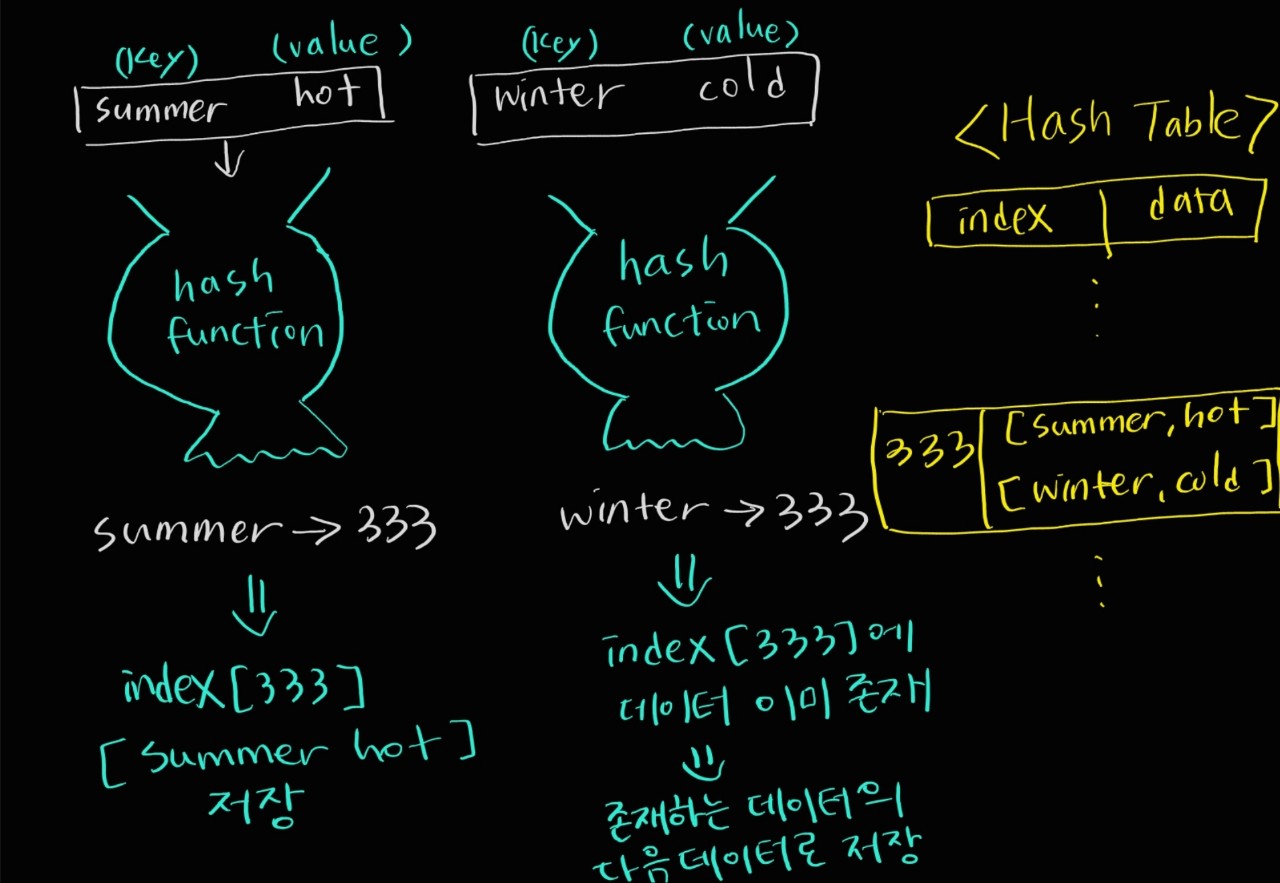
장점
- 해시 테이블의 확장이 필요없다
- 버킷의 데이터 사이의 자료구조를 활용하는 방식이라 구현이 간단하다
단점
- 이미 데이터가 있는 인덱스에 다른 데이터를 연결시킬 때 메모리가 추가적으로 사용된다
- 외부 저장 공간을 사용한다.
- 버킷에 chaining이 많아지면 검색 효율성이 감소한다.
(2) Open addressing
Table에 비어있는 곳을 찾아 데이터를 저장하는 방식
장점
- 별도의 저장공간 준비가 필요없고 해시테이블 내에서 데이터 저장과 처리를 할 수 있다.
단점
- 해시 함수의 성능에 따라 전체 테이블의 효율성이 달라진다.
- 데이터가 일정 양 이상 많아지면 더 늘려야 한다.
Linear probing
hash function으로 key를 변환한 index 자리에 이미 데이터가 존재할 경우 그 다음을 살펴보고 비어있는 저장하는 방식.
다음 인덱스가 비어있지 않다면 계속 그 다음 인덱스로 이동한다
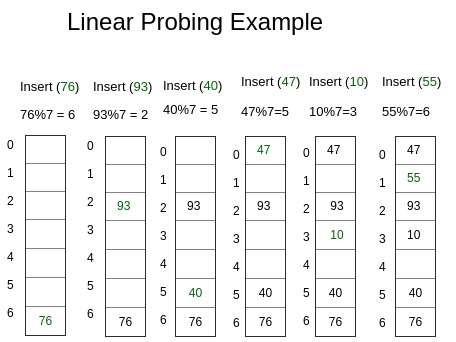
사진출처
Quadratic probing
linear chaining과 약간 비슷한데 hash function으로 key를 변환한 index 자리에 데이터가 존재할 경우 제곱한 만큼 이동해서 비어있는지 확인하고 저장하는 방식
처음에는 1²만큼 이동해서 비어있는지 확인 --> 이미 데이터 있으면 2², 그 다음은 3²...이런식으로 이동하면서 빈곳을 찾아 저장한다.
linear chaining, Quadratic chaining 둘 다 데이터를 삭제할 경우 삭제한 곳에 deleted를 표시할 수 있는 넣어야한다.

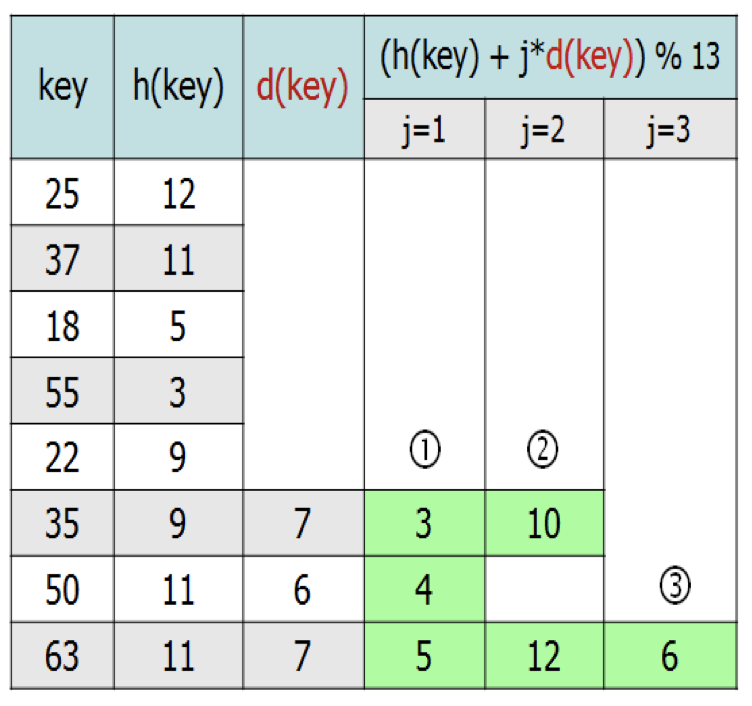
Double Hashing probing
2번 hashing 한 index에 데이터를 저장하는 것
보통 해싱함수는 두개가 주어진다
hash의 규칙성을 없앤다. 다른 오픈 어드레싱보다 시간이 오래 걸릴 수 있다.
더블 해싱의 원리는 다음과 같다.
(해싱함수1은 h(), 해싱함수2는 d(), key는 주어진 데이터,
j는 1부터 시작하여 빈 저장 공간을 찾을 때까지 증가하는 정수, 저장공간 길이는 13)
- h(key)에 아무 데이터도 없다면 key를 저장한다.
- 만약 h(key)에 데이터가 있다면 d(key)에 저장한다.
- h(key), d(key)에 모두 데이터가 있다면 j = 1으로 하고
(h(key) + 1 * d(key)) % 13에 저장한다.
(이후에도 데이터가 있으면 j=2,3...순으로 증가시켜가며 빈자리를 계속 찾고 채운다)
이번주 과제는 Hash Table 생성자 함수 내의 값 입력/삭제/찾기 함수를 구현하는 문제였다.
문제 조건을 공개하면 저작권 문제가 될 것 같아 내가 구현한 코드의 내용만 나열해보려고 한다.
해시 충돌을 막기 위한 방법으로는 Separate Chaining을 선택했다.
** 값 입력(insert), 값 삭제(delete), 값 찾기(search)
값 입력(insert)
(k,v)을 Hash function에 의해 index 값을 연산
만약 table[index]에 데이터가 없다면
[k,v]를 저장한다.
만약 table[index]에 데이터가 있다면
만약 table[index][i][0] === k 인 값이 있다면
table[index][i][1]에 v로 덮어씌워 저장한다.
만약 table[index][i][0] ===k 인 값이 없다면
table[index]의 가장 마지막에 저장한다.
값 찾기(search)
k를 입력했을 때
table[index][i][0] === k인 값이 있다면
table[index][i][1]을 반환한다.
값 삭제(delete)
k를 입력했을 때
table[index][i][0] === k인 값이 있다면
table[index][i].length를 0으로 만든다(모든 내용을 없애버림)더블 해시로도 구현해서 나중에 어느정도 데이터 저장공간이 많이 추가되거나 삭제되면 데이터 공간을 늘리거나 줄어들게 하는 것도 구현해봐야겠다.
출처:
https://baeji77.github.io/cs/data-structure/data-structure(2)/
https://dayzen1258.tistory.com/entry/%ED%95%B4%EC%8B%9C%ED%85%8C%EC%9D%B4%EB%B8%94%EC%9D%B4%EB%9E%80
https://mangkyu.tistory.com/102
https://baeharam.netlify.app/posts/data%20structure/hash-table
