K-Nearest Neighbor (KNN)
= instance-based learning 객체/사례 기반 학습
= lazy learning 게으른 학습 (모델을 준비하지 않고 새로운 데이터가 들어올 때까지 기다렸다가 작동하는 것을 게으르단 표현을 사용한다)
훈련 데이터셋을 그냥 저장한는 것이 모델을 만드는 과정 전부
새로운 데이터 포인트에 대해서 예측할 댄 알고리즘이 훈련 데이터셋에 가장 가까운 데이터 포인트, 최근접 이웃을 찾는다.
KNN의 경우 다른 머신러닝 알고리즘과 다르게 모델을 학습해 예측하는 것이 아니라 학습 데이터가 있는 가운데 새로운 객체가 주어지면 그 데이터의 특성(x)과 유사한 학습 데이터를 찾아 정답(y)를 예측하는 방법을 사용한다
모델이 학습하는 형태가 아니라서 학습데이터를 참조 데이터라고 부른다.
training data = reference data
한 데이터에서 가장 가까운 이웃 데이터 K개를 찾는다.
어떤 것을 우선순위로 두어 예측해야 할 지 판단이 어렵다. 판단 기분을 명확하게 하기 위해서 '가깝다'의 기준을 명확히 해야함
가깝다의 기준으로,
기준 : euclidean distance or cosine similarity
데이터 종류에 따라서 선택해서 사용
객체
※ 객체간의 거리를 측정하게되는 경우 정규화 또는 스케일링 과정을 통해 각 변수들이 거리에 주는 영향이 왜곡되지 않도록 주의해야 한다.
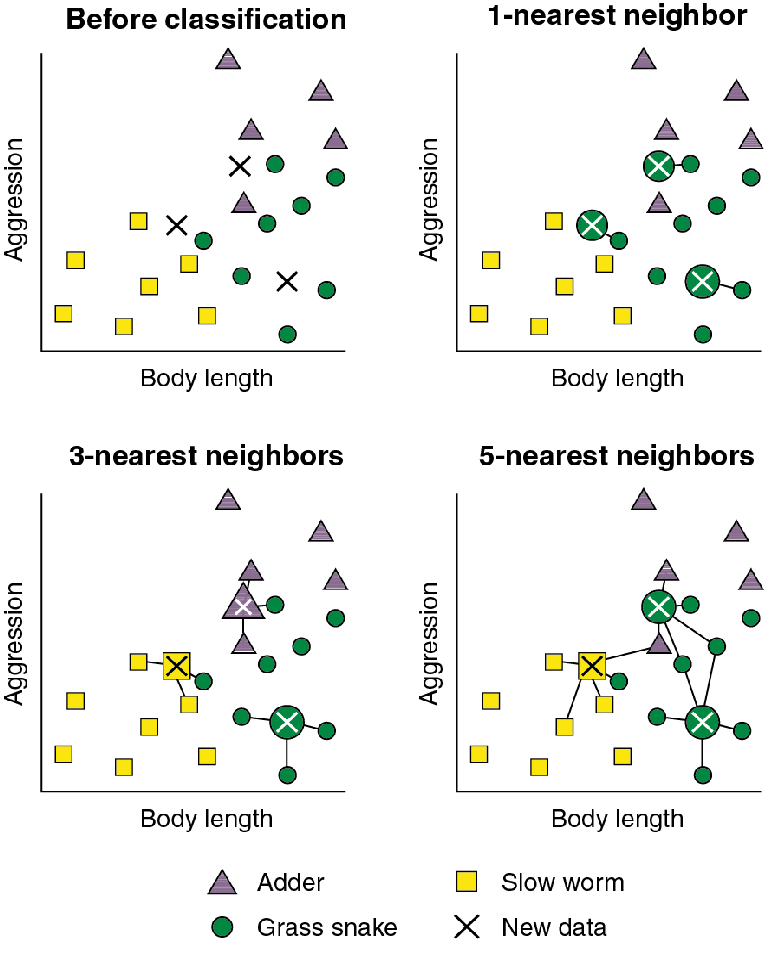
새로 들어온 X가 주변의 K개의 이웃에 의해 결정되는 방식
- 이웃들의 거리정보를 반영해 결정하는 가중합(weighted voting)방식
- 다수결(majority voting)로 결정하는 방식
※ 가중치로는 1/d, 1/(1+d), 1/(1+d^2), e^(-d) 등의 방식을 사용 (d = distance)
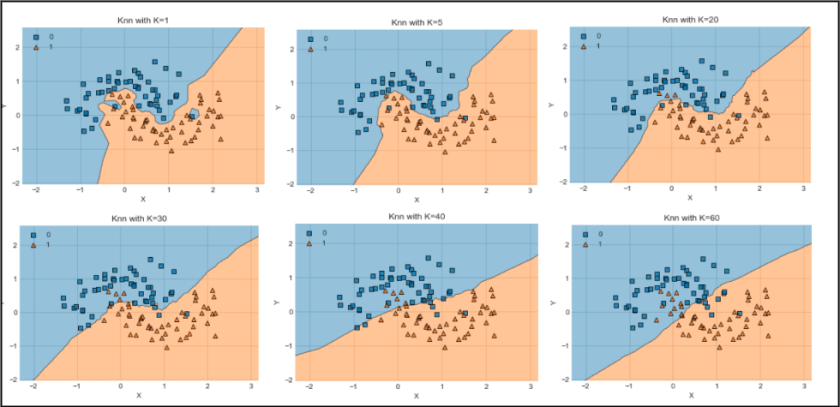
이웃을 하나 선택했을 때는 결정 경계가 훈련 데이터에 가깝게 따라가고 있음. 이웃 수를 늘릴 수록 결정 경계는 더 부드러워짐. 부드러운 경게는 단순한 모델을 의미, 이웃을 적게 사용하면 모델 복잡도는 높아지고 많이 사용하면 복잡도는 낮아짐.
훈련 데이터 전체 개수를 이웃의 수로 지정하는 극단적인 경우에는 모든 테스트 포인트가 같은 이웃(모든 훈련 데이터)를 가지게 되므로 테스트 포인트에 대한 예측은 모두 같은 값이 됨. 훈련 세트에서 가장 많은 데이터 포인트를 가진 클래스가 예측 값이 됨.
K = ? (Hyper-parameter)
※ 하이퍼 파라미터(Hyper-parameter)는 어떠한 임의의 모델을 학습시킬때 컴퓨터가 아닌 사람이 직접 튜닝(tuning)하는 변수를 말한다.
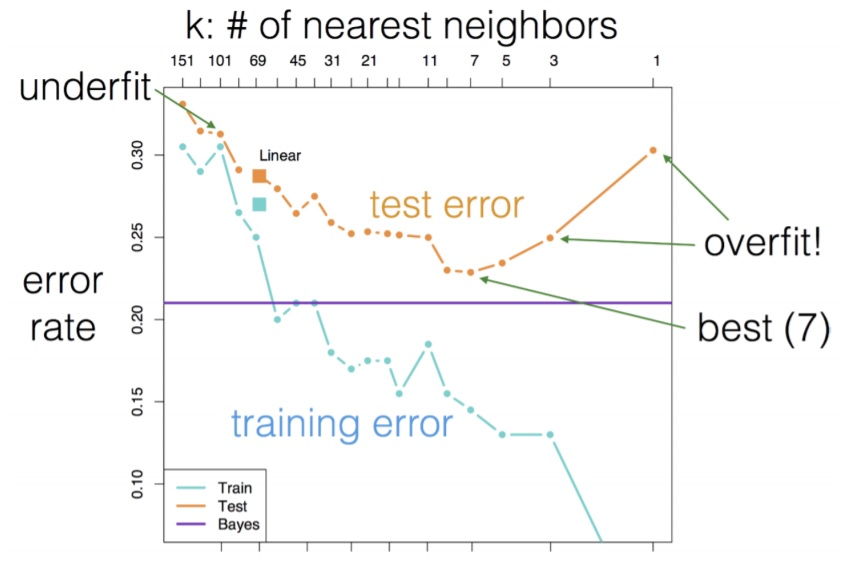
알고리즘의 이름에도 들어가 있는 만큼 이웃의 수(K)를 결정하는것은 KNN 알고리즘의 핵심이다. 일반적으로 K값이 너무 작게 설정되는 경우 분류 경계면이 노이즈(noise)에 민감하게 반응해 과적합(over-fitting)의 우려가 있는 반면에 K값이 너무 크게 설정되는 경우 지역적 구조(local structure)를 민감하게 파악하는 능력을 잃어 부적합(under-fitting)하는 경향이 있다. 즉, 적절한 K값을 찾아내는 것이 KNN의 성능을 좌우하는(최적화시키는) 가장 핵심적인 요소이다.
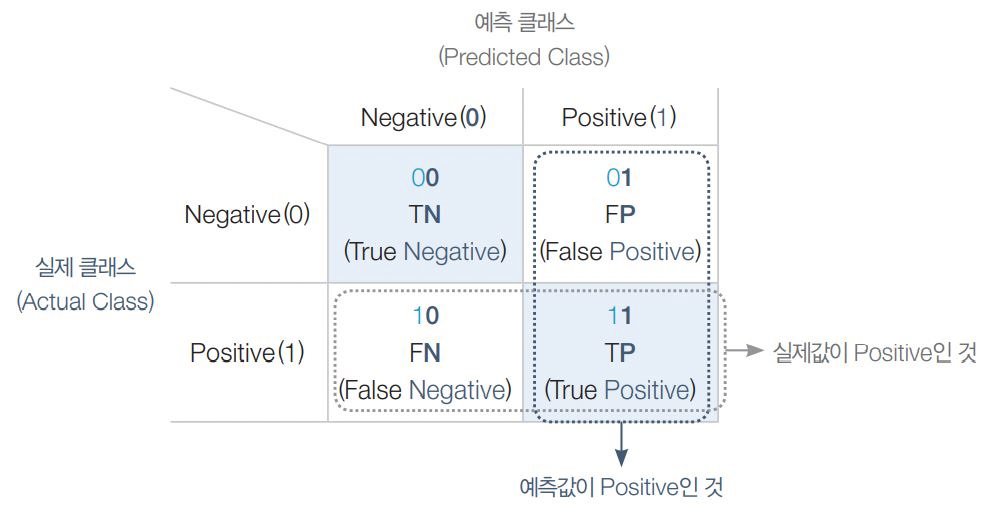
성능평가지표 - 오차행렬 (confusion matrix)
가장 간단한 KNN알고리즘은 가장 가까운 훈련 데이터 포인트 하나를 최근접 이웃으로 찾아 예측에 사용
가장 가까운 이웃 하나가 아니라 임의의 K개를 선택할 수 있음
둘 이상의 이웃을 선택할 때는 레이블을 정하기 위해 투표를 함. 즉 테스트 포인트 하나에 대해 클래스 0에 속한 이웃이 몇 개 인지, 그리고 클래스 1에 속한 이웃이 몇개 인지를 센다. 이웃이 더 많은 클래스를 레이블로 지정한다.
K 최근접 이웃 중 다수의 클래스가 레이블이 된다.
최근접 이웃 수가 하나일 때는 훈련 데이터의 정확도는 줄어든다. 이웃을 하나 사용한 테스트 세트의 정확도는 이웃을 많이 사용했을 때보다 낮다. (복잡하게 모델을 만들었다)
이웃을 많이 사용했을 때는 모델이 너무 단순해서 정확도는 나빠짐. 정확도가 가장 좋을 때는 중간 정도인 여섯 개를 사용한 경우.
KNN 분류기에 중요한 매개변수 : 데이터 포인트 사이의 거리를 재는 방법(기본적으로 유클리디안 거리 방식 사용)과 이웃의 수
매우 빠르게 만들 수 있따는 장점, 훈련 세트가 매우 크면 예측이 느려짐
데이터 전처리 과정이 중요하다.
많은 특성(수백 개 이상)을 가진 데이터셋에는 잘 동작하지 않고, 특성 값이 대부분 0인 (즉 희소한) 데이터셋과는 특히 잘 작동하지 앟는다.
예측이 느리고 많은 특성을 처리하는 능력이 부족
그래서 이런 단점이 없는 알고리즘이 선형 모델
