machine learning
1.K-Nearest Neighbor (KNN)
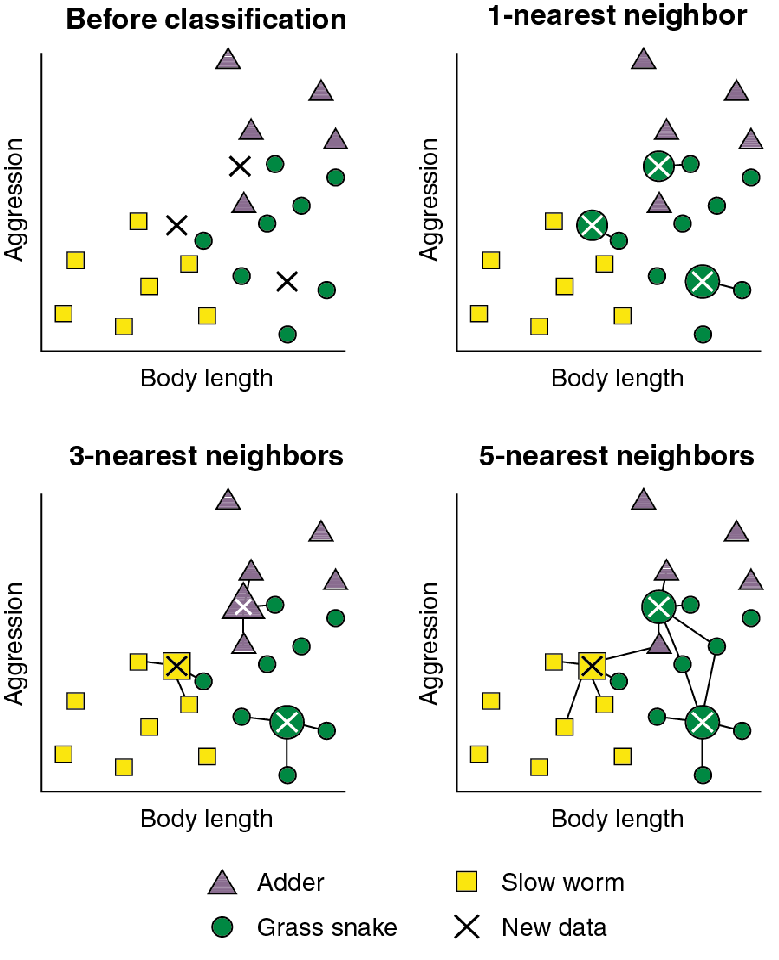
= instance-based learning= lazy learningtraining dat = reference data기준 : euclidean distance or cosine similarity데이터 종류에 따라서 ※ 객체간의 거리를 측정하게되는 경우 정규화
2.machine learning
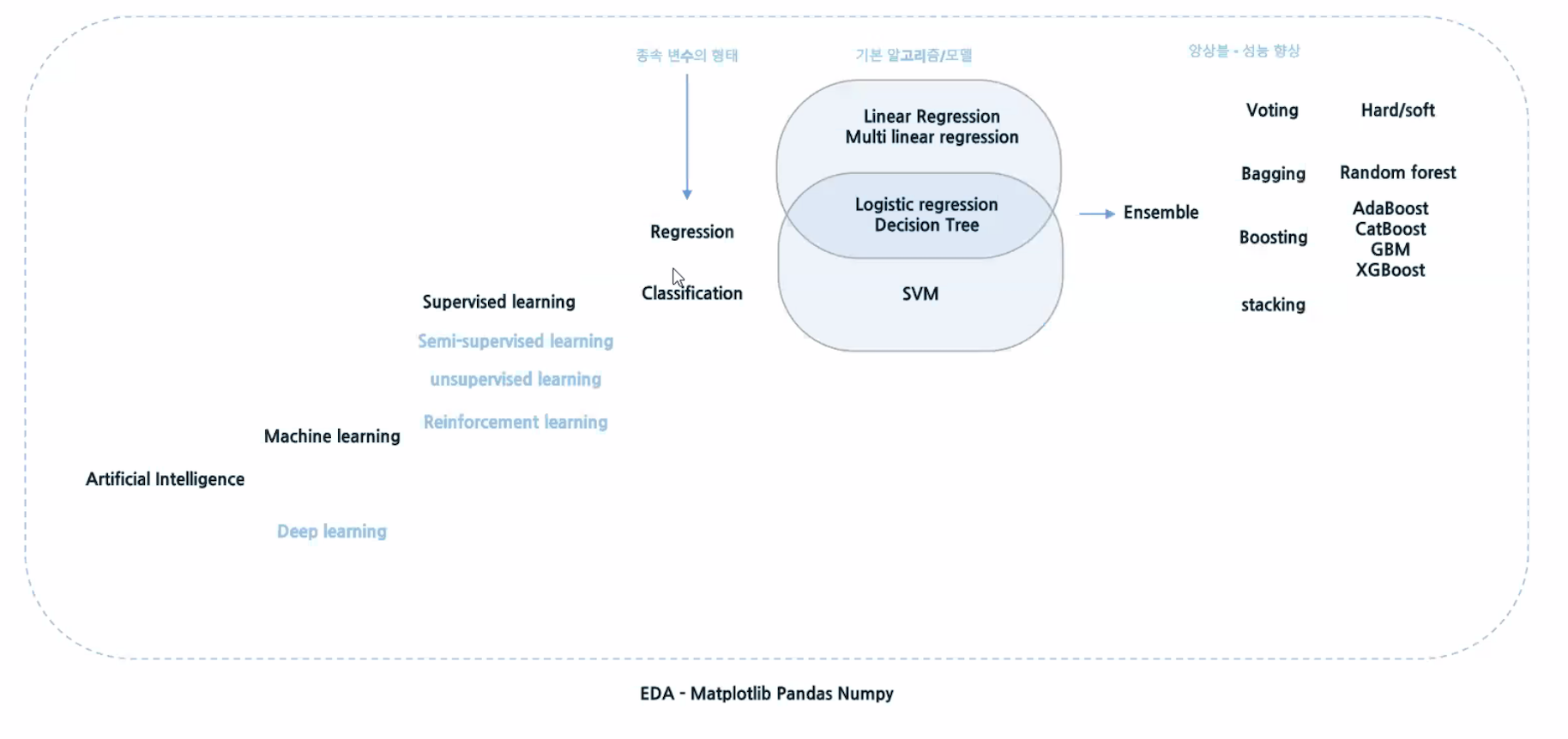
기계가 학습한다는 건, 프로그램이 특정 작업(T)을 하는데 경험(E)(= 데이터)을 통해 작업의 성능(P)을 향상시키는 것 - Tom Mitchell세상에 사용 가능한 데이터가 많아졌다.컴퓨터 성능이 좋아졌다.활용성이 증명되었다.빅데이터 : 데이터 보관/처리법, 데이터
3.Linear Regression
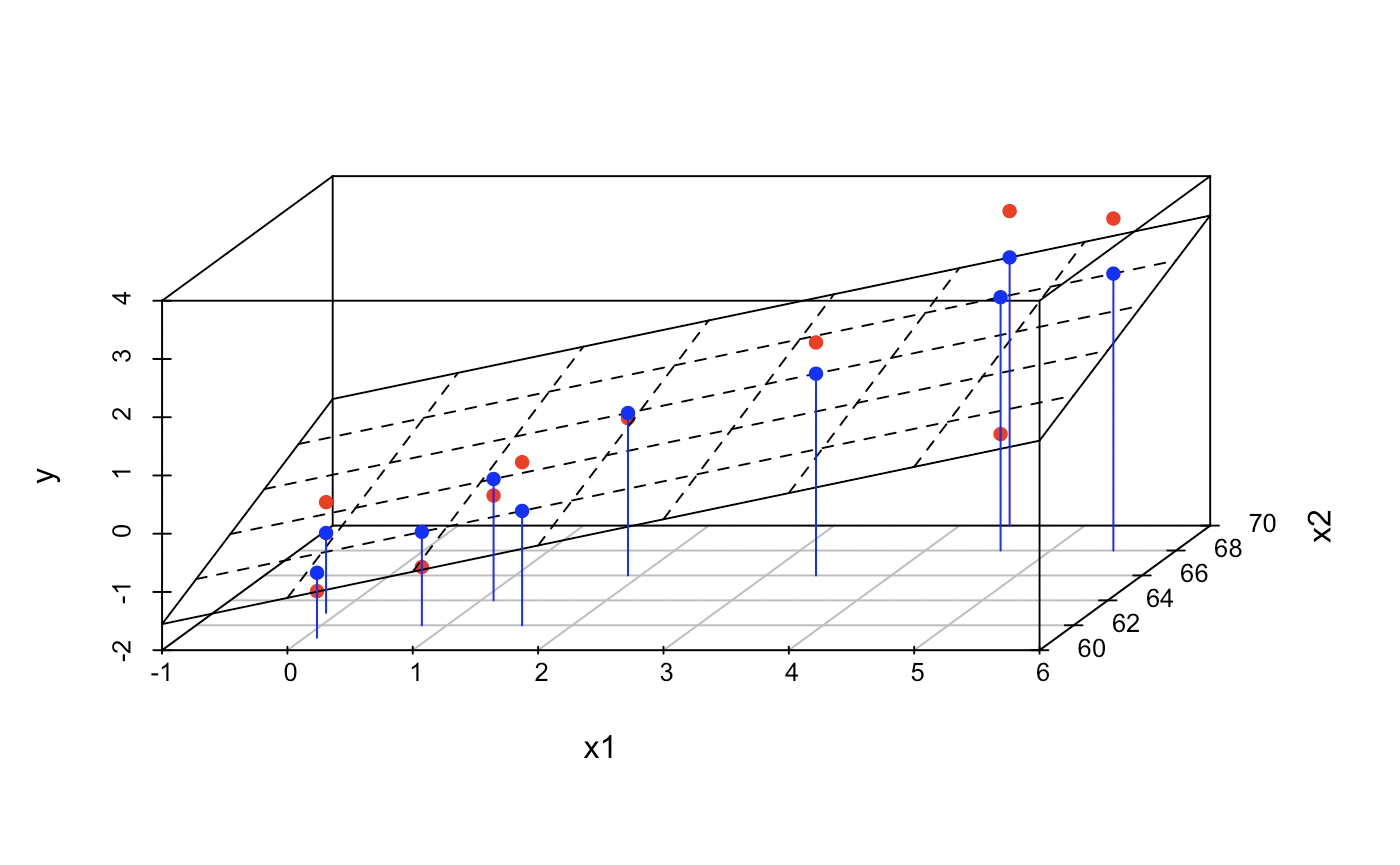
관계를 잘 설명하는 직선은 산점도에 있는 점들 대부분이 직선과 가까운 위치에 있는 경우어떤 점의 경우 직선 위에 놓여있을 정도로 가까운 직선이라면 우리가 찾던 직선일 가능성이 높다. 아쉽게도 모든 점들이 직선 위에 놓일 수는 없기 때문에 우리는 직선이 모든 점에 대해
4.Logistic Regression
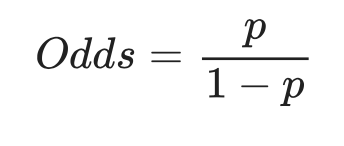
분류선형 회귀는 예외적인 데이터에 너무 민감하게 반응하기 때문에 데이터를 분류하고 싶을 때 잘 사용하지 않음 (대다수 데이터 예측 실패), 결과가 범위 없이 얼마든지 크거나 작아질 수 있음 > 분류하기 부적합로지스틱 회귀데이터에 가장 잘 맞는 시그모이드 함수(무조건 0
5.Decision Tree

데이터를 분할하는 것은 각 분할된 영역(결정트리의 리프)이 한 개의 타깃값(하나의 클래스, 하나의 회귀분석결과)를 가질 때까지 반복새로운 데이터 포인트에 대한 예측은 주어진 데이터 포인트가 특성을 분할할 영역 중 어디에 놓이는지 확인그 영역의 타깃값 중 다수(순수 노드
6.장점과 단점
장점 1\. 기준 분류 체계 값을 모두 검사하여 비교하므로 정확도가 높음, 수치 기반 데이터 분류 작업에서 성능 우수 - 학습데이터의 수가 충분하다면 좋은 성능을 낸다.2\. 비교하여 가까운 상위 k개의 데이터만 활용하기 때문에 오류 데이터는 비교 대상에서 제외되어 오