1. 데이터 탐색
R 기본 데이터인 ‘Iris’ 데이터를 활용하여 Naïve Baye 방법론을 사용하기에 앞서 데이터의 기본적인 구조를 탐색한다.
Target Variable은 Species로 설정한다.
str(iris)
table(iris$Species)
#Target variable
table(iris$Species)2. Training / Test data 분류
전체 데이터는 150개로, 3:1로 나누어 Training data는 105개, Test data는 45개로 나누어 모델의 학습과 테스트를 실시한다.
각 샘플링은 랜덤으로 진행되도록 하며, 샘플된 데이터는 고정시켰다.
set.seed(1)
train <- round(0.7*dim(iris)[1])
train_index = sample(1:dim(iris)[1], train, replace =F)
iris_train <- iris[train_index,]
iris_test <- iris[-train_index,]
iris_train_labels <- iris[train_index,5]
iris_test_label <- iris[-train_index,5]
iris_train_labels
prop.table(table(iris_train_labels))
prop.table(table(iris_test_label))3. Naïve Bayes
Naïve bayes로 classification을 진행한 결과, accuracy가 1로 관측되어, Laplace 보정을 시행하였다.
library(e1071)
iris_classifier = naiveBayes(iris_train, iris_train_labels)
iris_test_pred = predict(iris_classifier, iris_test)
library(gmodels)
CrossTable(iris_test_pred, iris_test_label, prop.chisq = FALSE,
prop.c = FALSE, prop.r = FALSE, dnn = c('predicted', 'actual'))
# accuracy : 1 (error rate : 0)
### accuracy가 너무 높게 나와 #Laplace estimator 이용해서 Laplace 보정 ###
iris_classifier2 = naiveBayes(iris_train, iris_train_labels, laplace = 1)
iris_test_pred2 = predict(iris_classifier2, iris_test)
CrossTable(iris_test_pred2, iris_test_label, prop.chisq = FALSE,
prop.c = FALSE, prop.r = FALSE, dnn = c('predicted', 'actual'))
# accuracy : 0.978 (error rate : 0.022) 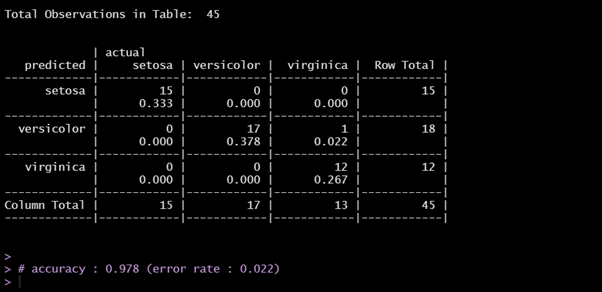
Laplace 보정을 한 Naïve Bayes모델로 Iris Data의 Species Classification를 수행한 결과는, accuracy = 0.978, error rate = 0.022이다.

잡학꾸러기