1. 데이터 탐색
R 기본 데이터인 ‘Iris’ 데이터를 활용하여 LDA 모델을 사용하기에 앞서 데이터의 기본적인 구조를 탐색한다.
Target Variable은 Species로 설정하고, setosa와 nonsetosa의 이진분류로 나눈다.
iris$Species <- as.character(iris$Species)
iris$Species[iris$Species !="setosa"] <- "non setosa"
iris$Species <- as.factor(iris$Species)2. LDA 모형적합
library(gmodels)
library(MASS)
iris
set.seed(1000)
N=nrow(iris)
tr_idx=sample(1:N, size=N*2/3, replace=FALSE)
iris_train<-iris[tr_idx,-5]
iris_test<-iris[-tr_idx,-5]
trainlabels<-iris[tr_idx,5]
testlabels<-iris[-tr_idx,5]
train<-iris[tr_idx,]
test<-iris[-tr_idx,]
iris_lda <- lda(Species ~ ., data=train)
iris_lda
#Test error 계산
testpred <- predict(iris_lda, test)
testpred
CrossTable(x=testlabels,y=testpred$class, prop.chisq=FALSE)
# accuracy : 1.0, error rate = 0
3. 결과분석
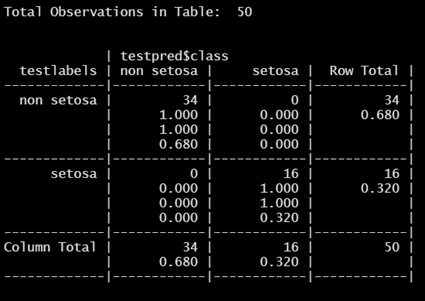 LDA를 진행한 결과, accuracy = 1.0, error rate = 0의 완벽한 성능을 확인 할 수 있다.
LDA를 진행한 결과, accuracy = 1.0, error rate = 0의 완벽한 성능을 확인 할 수 있다.

잡학꾸러기