
들어가기 전에... python set
python에서 set은 집합형 자료구조라고 배웠다. 특징으로는 중복을 허용하지 않는다는 특징과 순서를 보장하지 않는다는 특징이 있다. 사용예시는 아래와 같다.
선언
setStructure = set() set은 중괄호 {} 를 사용한다. 하지만
setStructure = {}위와 같이 하면 dictionary를 선언하는 것이기 때문에 헷갈리지 않도록 주의한다.
add method 와 set의 주소값도 알아보자.
setStructure = set()
print(setStructure)
Out : set()
print(hex(id(setStructure)))
Out : 0x7f99716cd9e0
setStructure.add(3)
print(setStructure)
Out : {3}
print(hex(id(setStructure)))
Out : 0x7f99716cd9e0간단히 원소 3(int)을 삽입하는 예시이고, set은 Mutable 자료형이므로 3을 삽입하더라도 주소값이 변경되지 않았다.
mutable? 파이썬의 메모리 관리기법 보러가기
remove, discard method를 알아보자.
둘 다 set에서 원소를 삭제하는 method인데 둘은 어떻게 다를까?
1 . remove method
print(setStructure)
Out : {1, 2, 3, 4} # 이미 1,2,3,4 네개의 원소가 있는 상태
setStructure.remove(4)
print(setStructure)
Out : {1, 2, 3} # 4 원소가 잘 삭제되었다.
setStructure.remove(4)
KeyError : 4없는 원소를 삭제하려고 하면 error를 뱉는다.
2 . discard method
print(setStructure)
Out : {1, 2, 3, 4} # 이미 1,2,3,4 네개의 원소가 있는 상태
setStructure.discard(4)
print(setStructure)
Out : {1, 2, 3} # 4 원소가 잘 삭제되었다.
setStructure.discard(4)
print(setStructure)
Out : {1, 2, 3} 원소가 없는 상태에서 discard를 하더라도 error를 뱉지 않는다. 명시적으로 확실히 있는 원소를 삭제할 때 remove, 있든 없든 무조건 삭제가 되었으면 하면 discard를 쓰면 되겠다.
pop
일반적인 list(stack)의 pop method와 set에서의 pop method를 비교해보자
1 . pop method in list
popList = list()
popList.append(-3)
popList.append(-1)
popList.append(2)
print(popList)
Out : [-3, -1, 2]
print(popList.pop())
Out : 2append한 순서대로 값이 삽입되고 pop을 하자 가장 마지막에 들어간(last in) 2가 먼저 pop(first out)됨을 알 수 있다. set에서는 어떨까
2 . pop method in set
popSet = set()
popSet.add(-3)
popSet.add(-1)
popSet.add(2)
print(popSet)
Out : {2, -3, -1}
print(popSet.pop())
Out : 2애초에 add한 순서대로 출력되지도 않는다.(순서가 보장되지 않음) 그리고 pop을 했을 때 가장 앞에 출력된 2가 출력됨을 알 수 있다. 이는 set이 python 내부적으로 hashtable data structure로 구성되어 있기 때문이다.
dict, set은 모두 hashtable이다.
python의 set, dict 객체는 모두 hashtable data structure이다. 둘의 차이는 set는 value가 존재하지 않고 Key만 존재하는 데이터 구조이고, dict는 key, value가 매핑되어있는 데이터 구조이다. 그럼 그 구조차이는 어디에서 오는가? C python의 코드를 보며 알아보자.
< 참조 >
dictobject.c
setobject.c
위 링크를 참조하면 알 수 있는 점이 있다.
1 . dict는 hashtable 로 구현했다.

2 . set은 dict를 참조해서 구현했다.

3 . set struct와 dict struct의 차이
struct 는 이곳에 있다. dictobject.h setobject.h
dictobject entry의 struct
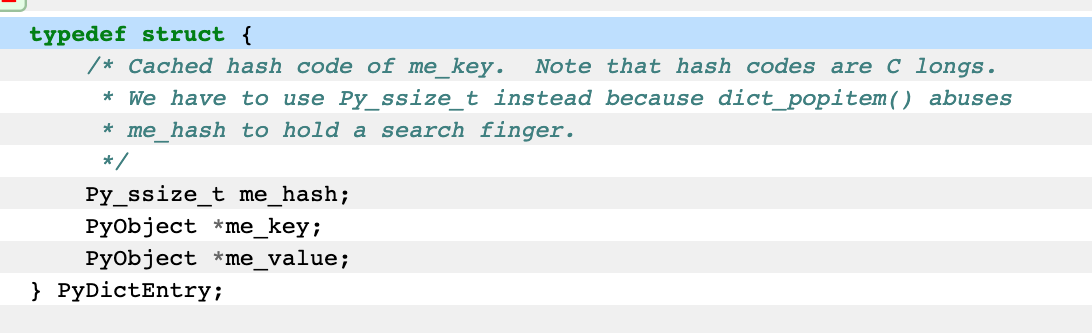
setobject entry의 struct

언뜻 보면 비슷해 보이지만 큰 차이가 있다. dictentry에는 value를 가르키는 주소값이 추가로 저장되어 있고 setentry에는 value없이 key만 저장하고 있음을 알 수 있다. 실제로 c 코드를 보니 set에는 value가 없고 dict에는 key, value로 매핑되어 있는지 확실히 알 수 있다.
그럼 set에서 pop하면?
hash table을 구현해보면 알겠지만 hash table을 순회하면 첫번째 bucket부터 안의 키를 순회하고 다음 bucket으로 가는 식으로 순회한다.
이렇게 순회를 하니 pop을 한다고 가장 뒤에 있는 값까지 순회해서 내뱉는 것이 아닌 가장 처음에 나온 값을 뱉게되는 것이다.
setobject.c에서 pop method
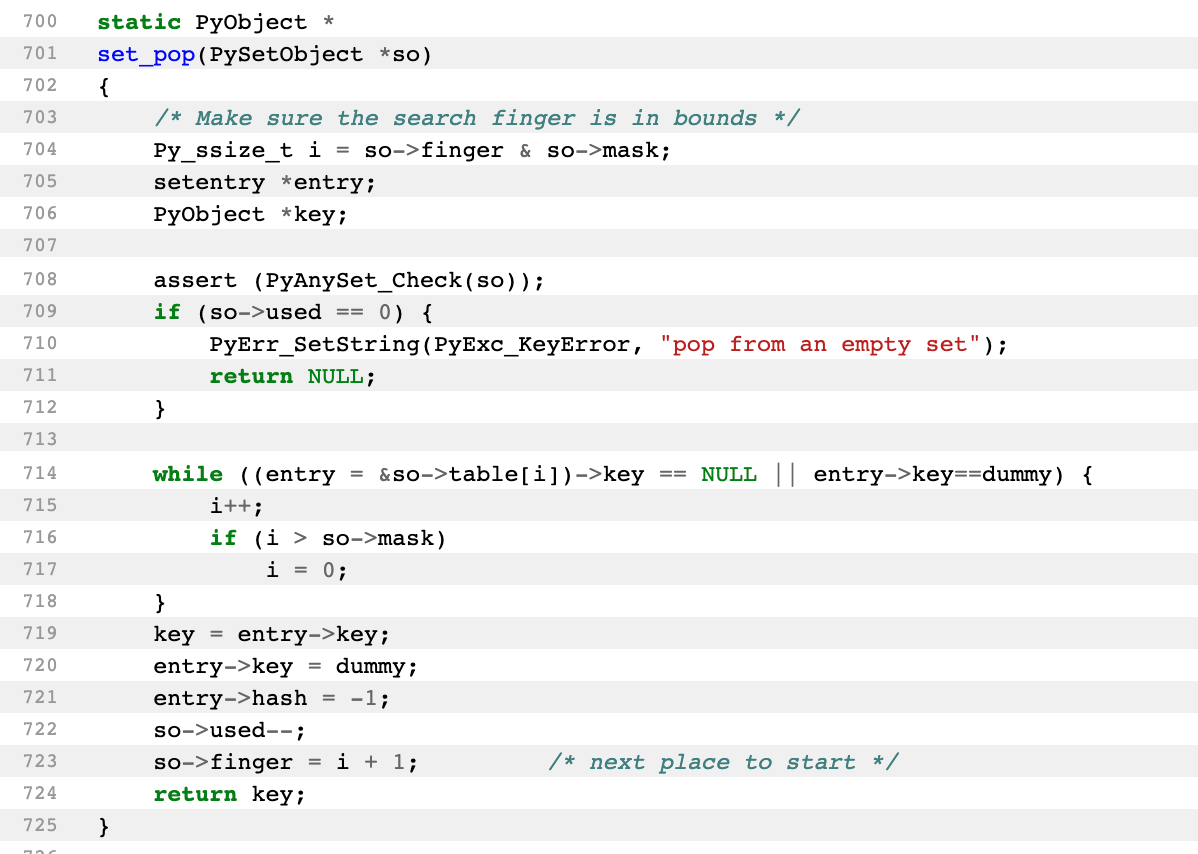
간단히 말하면, while에서 존재하는 key가 나올 때까지 순회를 하고 나오면 해당 key를 return한다.
set이 hashtable인 것을 이용할 수 있을까?
먼저 list, set, dict를 사용해야 할 때를 정리해보자.
list
순서가 중요할 때(set, dict는 순서없음)
set
중복없이 특정값이 이미 있는지 여부만 알면되고 순서는 필요없을 때
dict
key와 함께 value가 필요할 때(list, set은 key, value mapping 없음) 그리고 그 값을 효과적으로 찾고싶을 때
위에서 언급한 듯이 set은 특정값이 이미 있는지 여부를 확인할 때 매우 효과적이다.
hash table 특성 상 member를 찾을 때 시간복잡도는 평균 O(1), 최악의 경우 O(n)(python set에서는 그럴일 거의 없음)이기 때문에 이분탐색 등 다른 탐색법 보다 훨씬 빠른 속도를 갖는다.
풀어보면 좋은 문제 백준 소수경로 1964번
위 문제를 이분탐색으로 풀어보고 set을 사용해서 두번 풀어보자.
set에서 멤버 찾는 건 안 알려줬는데?
inSet = set([1,2,3]) # 이렇게도 선언 가능하다.
print(1 in inSet)
Out : True추가할 점
1 . hashmap, hashtable, hashset의 차이점
전공책도 읽어보고 구글링도 오래 해봤는데 명쾌한 답이 나오지 않는다. 아마 차이가 없어서 그런 것일 수도... 또 각 언어마다 사용하는 단어가 조금씩 다른 것 같다. 특히 java는 아예 저런 객체가 존재한다.(hashmap vs hashtable in java) 혹시 잘 아시는 분은 피드백 부탁드립니다.
2 . C로 해쉬테이블을 구현해보자
조만간 시간내서 C로 구현해보고 블로그 작성해보겠습니다. 특히 bucket을 single linked list 혹은 double linked list로 구현했을 때의 삭제에서의 시간차이에 대해서 매우 궁금하기 때문에 직접 해보고 작성하도록 하겠습니다.
결론
언어를 많이 안다는 것이 무조건 좋은 건 아닌 것 같다는 생각이 들었다. 잘 안다고 생각하는 언어를 실제로 잘 아는 것일까? 겸손한 마음으로 깊은 공부를 해야겠다는 다짐을 했다. 😀

"2 . C로 해쉬테이블을 구현해보자" 이걸 해요?? 보기만해도 토나오는군요 벌써 C 다 까먹은거 같아요. 현기증 나니까 들어갈게요