
💁🏻♂️ Managed Language vs Unmanaged Language
- Managed Language는 사용자가 일부러 메모리 할당 및 해제를 하지 않아도 되는 언어를 뜻한다. 대표적으로 JAVA, Python이 있다.
- Unmanaged language는 그 반대로 대표적으로 C가 있다.
💁🏻♂️ 글을 쓰게 된 이유
C로 프로젝트를 4개를 했다. 특히, 그중 malloc lab까지 했었다. 메모리 할당과 해제에 대해서 깐깐히 해야하는 C를 했던 입장으로 python은 어떻게 메모리가 관리되는지 궁금했다.
💁🏻♂️ 변수할당부터
a = 10001 . 1000의 값을 메모리 주소에 담는다.
2 . a라는 변수는 그 메모리 주소를 참조한다.
어떤 주소를 참조하는데?
In[1] : a = 1000
In[2] : print(hex(id(a)))
Out[1] : 0x7fee093b9c700x7fee093b9c70 주소를 참조함을 알 수 있다.
💁🏻♂️ 자연스럽게 메모리 주소값을 반환하는 함수
id(a)id(obj)는 해당 객체 / 변수의 메모리 주소값을 반환하는 함수이다.
C에서 & 포인터 연산자와 동일하다. 그럼 비교 해봐야지.
💁🏻♂️ C와 python의 메모리 주소값 비교
C
char chr = 'a';
printf("%x", &chr);python
hex(id('a')) # hex는 16진수로 바꾸어주는 함수이다.위 두가지는 동일한 역할을 하는 함수이다.
💁🏻♂️ is, == 의 차이를 아시나요?
1번 예시
In[1] : a = [1,2,3]
In[2] : b = [1,2,3]
In[3] : print(a is b)
Out[1] : False
In[4] : print(a == b)
Out[1] : True2번 예시
In[1] : a = [1,2,3]
In[2] : b = a
In[3] : print(a is b)
Out[1] : True
In[4] : print(a == b)
Out[1] : True예시를 보면 알 수 있듯이 ==은 값을 비교하는 비교연산자인 반면에 is는 주소값을 비교하는 비교연산자임을 알 수 있다. 따라서 == 연산자는 해당 값을 찾고 그 값을 비교하는 연산과정이 있고 is 는 바로 주소값을 비교하기때문에 is 가 ==에 비해 약간 더 빠르다.
💁🏻♂️ 파이썬의 자료형 (mutable vs immutable)
mutable
mutable형은 변경 가능한 객체이다. 객체 값이 변경되더라도 메모리의 재할당이 일어나지 않는다. 예로 set, list, dict 등이 있다.
In[1] : mutable1 = ['alpha'] # list
In[2] : print(hex(id(mutable1)))
Out[1] : 0x7f9cee27eb40
In[3] : mutable1.append('bravo')
In[4] : print(hex(id(mutable1)))
Out[2] : 0x7f9cee27eb40 # 주소값이 같다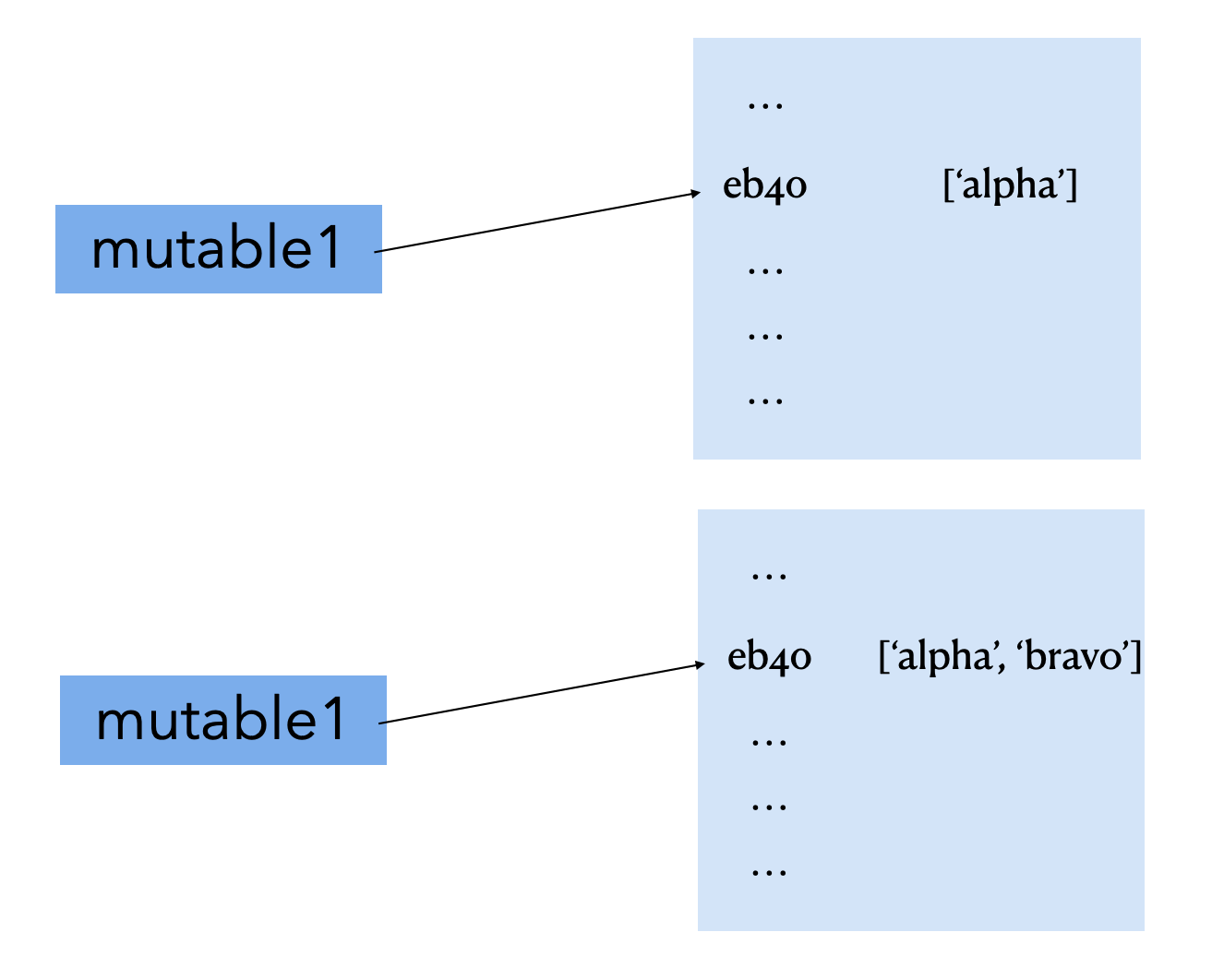
immutable
immutable형은 변경 불가능한 객체로 객체값 변경 시 메모리에서 재할당이 일어난다. 예로 int, float, string 등 대부분 원시 자료형들이 속한다.
In[1] : immutable1 = 1000 # int
In[2] : print(hex(id(immutable1)))
Out[1] : 0x7fc68f2a2c50
In[3] : immutable1 += 1
In[4] : print(hex(id(immutable1)))
Out[1] : 0x7fc68f2a2d10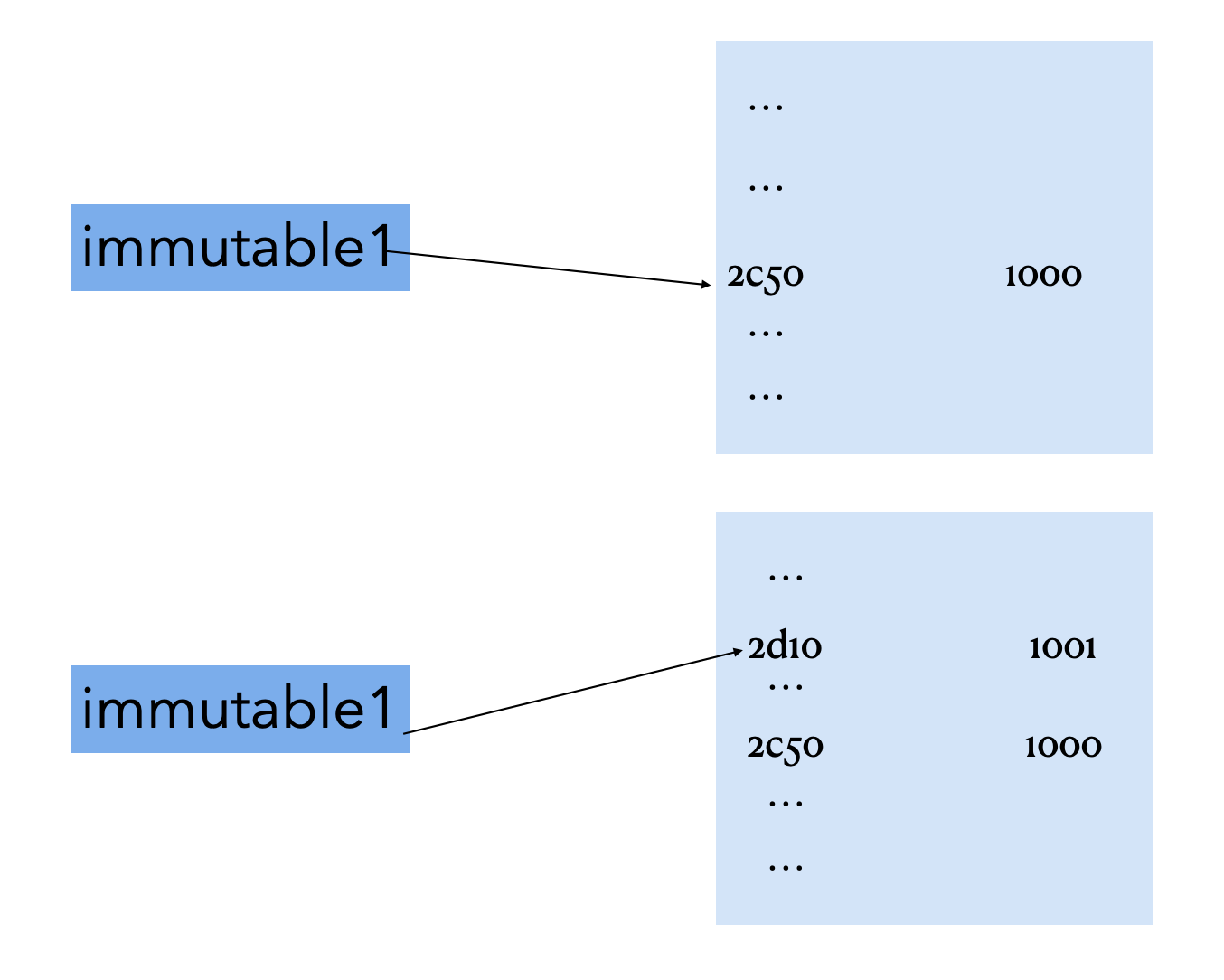
is를 사용해서 주의할 점을 알아보자.
1번 예시
In[1] : a = 1000
In[2] : b = a
In[3] : print(a is b)
Out[1] : True
In[4] : b += 1
In[5] : print(a, b, a is b)
Out[2] : 1000 1001 Falsea는 b와 같은 주소값을 참조하고 있었지만 immutable 형인 Int형 b에 1을 더함으로서 메모리 재할당이 일어났고 b의 주소값이 바뀌어 out[2]에서는 False가 나옴을 알 수 있다.
2번 예시
In[1] : a = ['Mon', 'Tue']
In[2] : b = a
In[3] : b.append('Wed')
In[4] : print(a, b, a is b)
Out[1] : ['Mon', 'Tue', 'Wed'] ['Mon', 'Tue', 'Wed'] Trueb에만 'Wed' element를 더했는데 a에도 더해져있다. mutable형인 list a와 b는 서로 같은 주소값을 참조하고 있기때문에 서로 종속된 관계를 갖는다.
2번을 해결하기 위한 방법 1
이미 글을 올린 적이 있지만 해당 글의 설명을 위해 한번 더 설명하도록 한다.
이전 글에서 python clone, copy 보러가기
In[1] : a = ['Mon', 'Tue']
In[2] : b = a[:]
In[3] : b.append('Wed')
In[4] : print(a, b, a is b)
Out[1] : ['Mon', 'Tue'] ['Mon', 'Tue', 'Wed'] Falseslice를 하는 방법으로 쉽게 해결했다.
2번을 해결하기 위한 방법 2
In[1] : a = ['Mon', 'Tue']
In[2] : b = a.copy()
In[3] : b.append('Wed')
In[4] : print(a, b, a is b)
Out[1] : ['Mon', 'Tue'] ['Mon', 'Tue', 'Wed'] Falsecopy 함수를 사용해서 해결했다.
그렇다면 둘은 만병통치약일까? 예시 3
In[1] : a = ['Head', ['Sub']]
In[2] : b = a.copy() # or a[:]
In[3] : b[1].append('Sub2')
In[4] : print(a, b)
Out[1] : ['Head', ['Sub', 'Sub2']] ['Head', ['Sub', 'Sub2']]list안의 list (nested list)는 완전히 copy가 되지 않았음을 알 수 있다.
slice와 copy의 작동원리는 새로운 객체를 만들고(새로운 주소에) element의 주소값을 복사해 넣는 것이기 때문에 nested list의 주소값은 마찬가지로 종속된 관계가 되어서 이런 일이 일어났다. 이것을 해결하기 위한 모듈이 있다.
💁🏻♂️ copy module
copy.copy() method
[:] 나 copy()와 같은 기능이다.
주목해야할 copy.deepcopy() method
해당 객체와 하위 객체들의 메모리를 새로 할당해서 완전히 새로운 객체를 만든다.
In[1] : import copy
In[2] : a = ['Head', ['Sub']]
In[3] : b = copy.deepcopy(a)
In[4] : b[1].append('Sub2')
In[5] : print(a, b)
Out[1] : ['Head', ['Sub']] ['Head', ['Sub', 'Sub2']]잘 해결되었음을 볼 수 있다.
💁🏻♂️ del
del 키워드로 변수를 명시적으로 제거함으로서 변수의 선언을 취소하고 필요없는 메모리값을 지울 수 있다.
In[1] : a = 1000
In[2] : print(a)
Out[1] : 1000
In[3] : del a
In[4] : print(a)
NameError : name 'a' is not defined💁🏻♂️ reference count
특정 메모리 주소를 참조하는 곳의 수이다. 0이 될 경우 다음 GC때 메모리에서 해제된다.
레퍼런스카운트를 확인하는 방법
import sys
In[1] : a = {'Jewelry', 'Kim'}
In[2] : b = a
In[3] : print(sys.getrefcount(a))
Out[1] : 3 # 3 인것에 주의여기서 3이 나온 이유는
1 . a를 선언할 때 + 1
2 . b 를 a의 참조로 쓰면서 +1
3 . sys.getrefcount에서 인자로 쓰면서 +1
이렇게 3이 된 것이다.
💁🏻♂️ Garbage Collection
필요없는 메모리를 자동으로 해제한다. 이때 reference count를 이용한다. 또한 Generation을 나눠서 관리한다. (0,1,2 세대), 세대마다 가지고 있을 수 있는 메모리의 개수 threshold가 존재한다. 0이 가장 young한 세대고 2로 갈수록 old한 세대가 되는데 가장 young한 세대부터 GC를 한다. 그 이유는 가장 최근에 선언된 변수일수록 쓸모없어질 가능성이 높기때문이다.(ex. loop를 돌때 선언한 인덱스 변수)
threshold가 3이라고 가정하고 예를 들어보자

각 제네레이션마다 3개씩 들어갈 수 있다.
a = 'alpha'를 선언해본다.
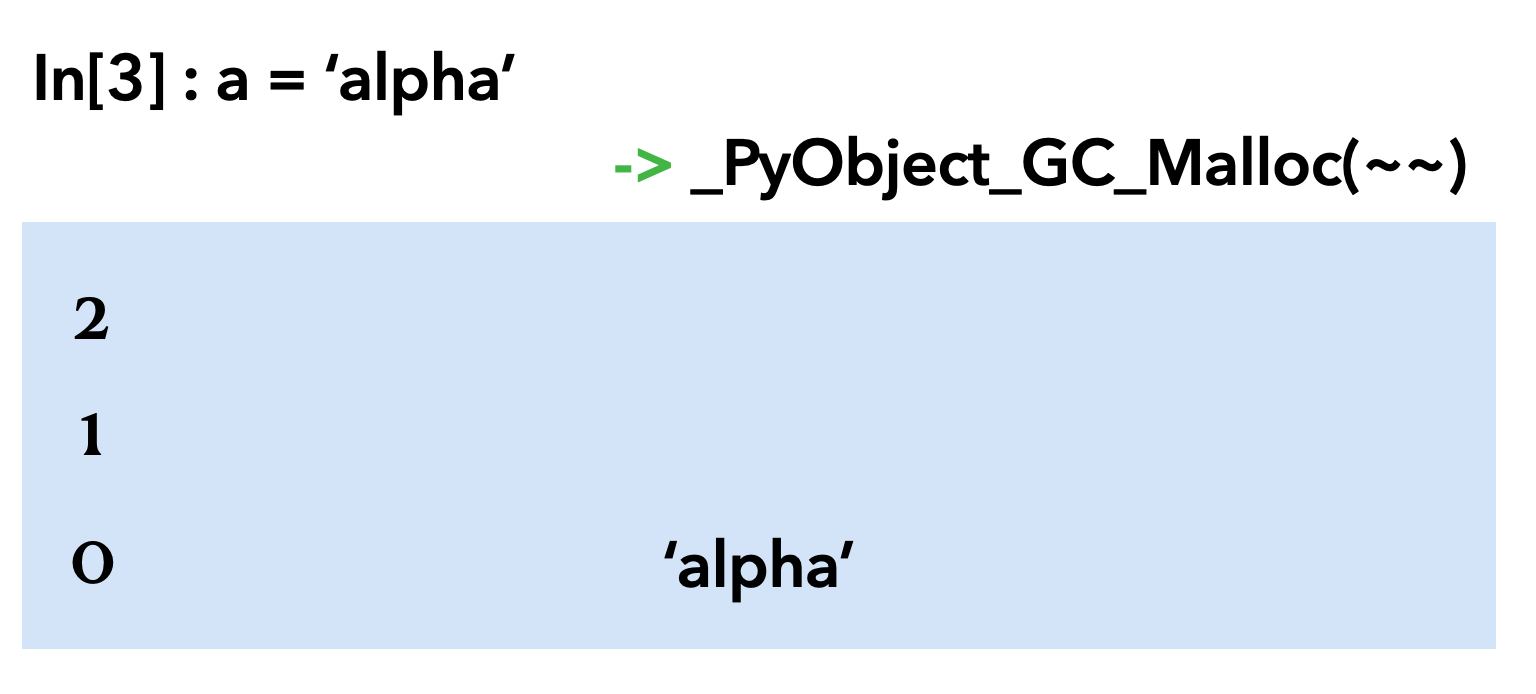
malloc 함수가 수행되고 a가 아닌 'alpha'가 0세대에 들어간다.
이어서 'bravo', 'charlie'를 선언한다.
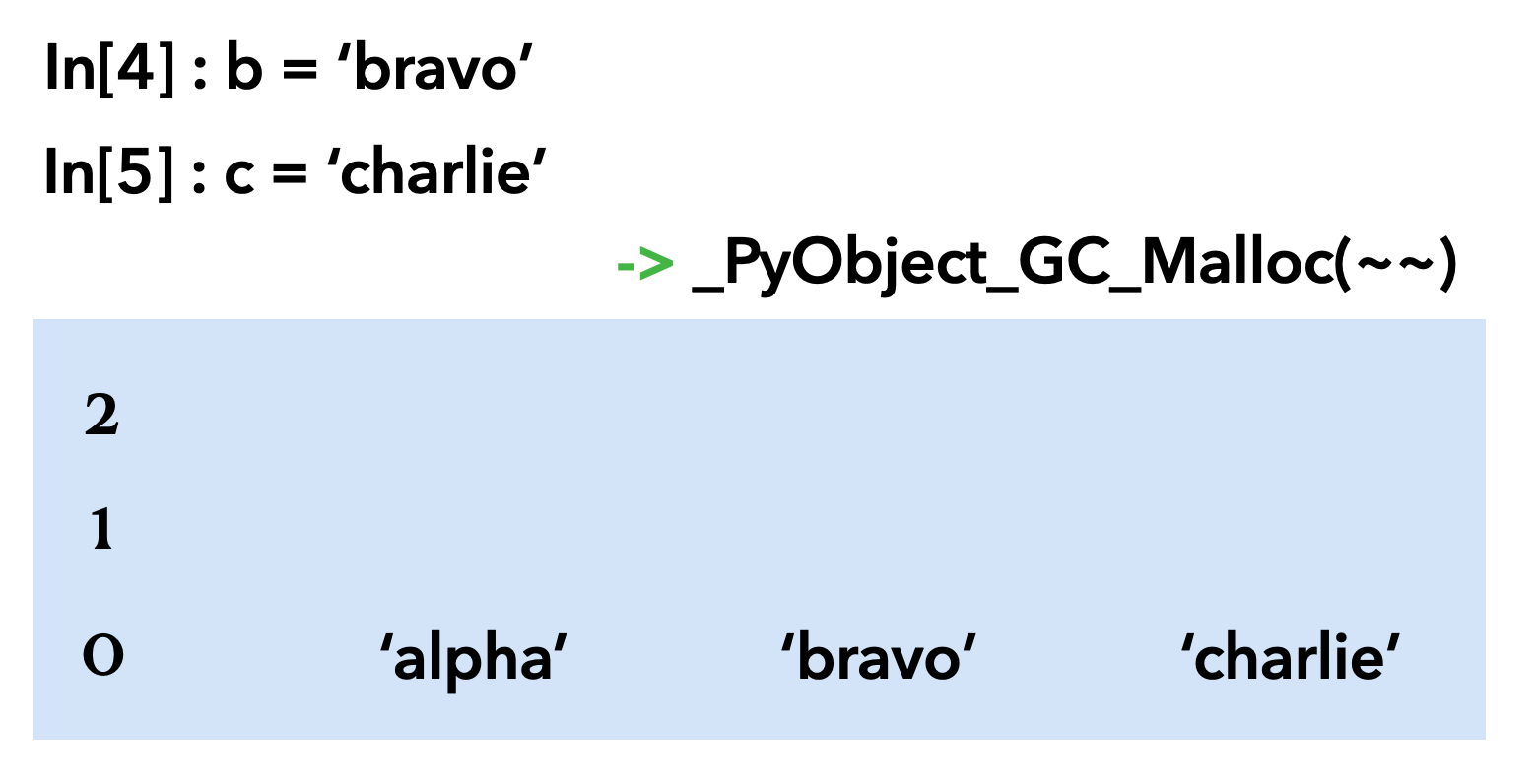
여기에 'delta'가 선언된다면
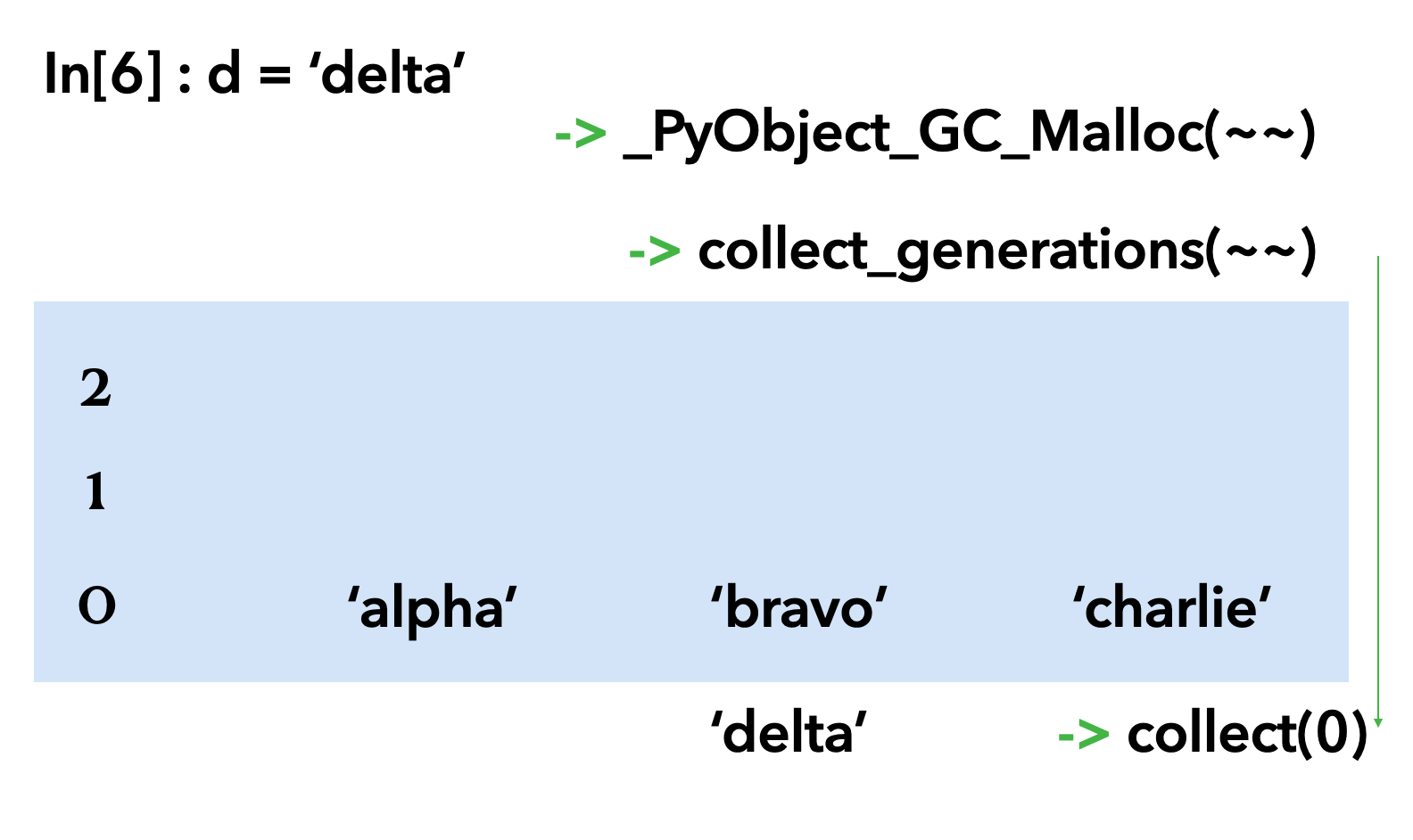
collect 함수가 수행되고 0 제네레이션에서 refcount가 0일 경우 지우고 아닐 경우 1 제네레이션으로 올린다.
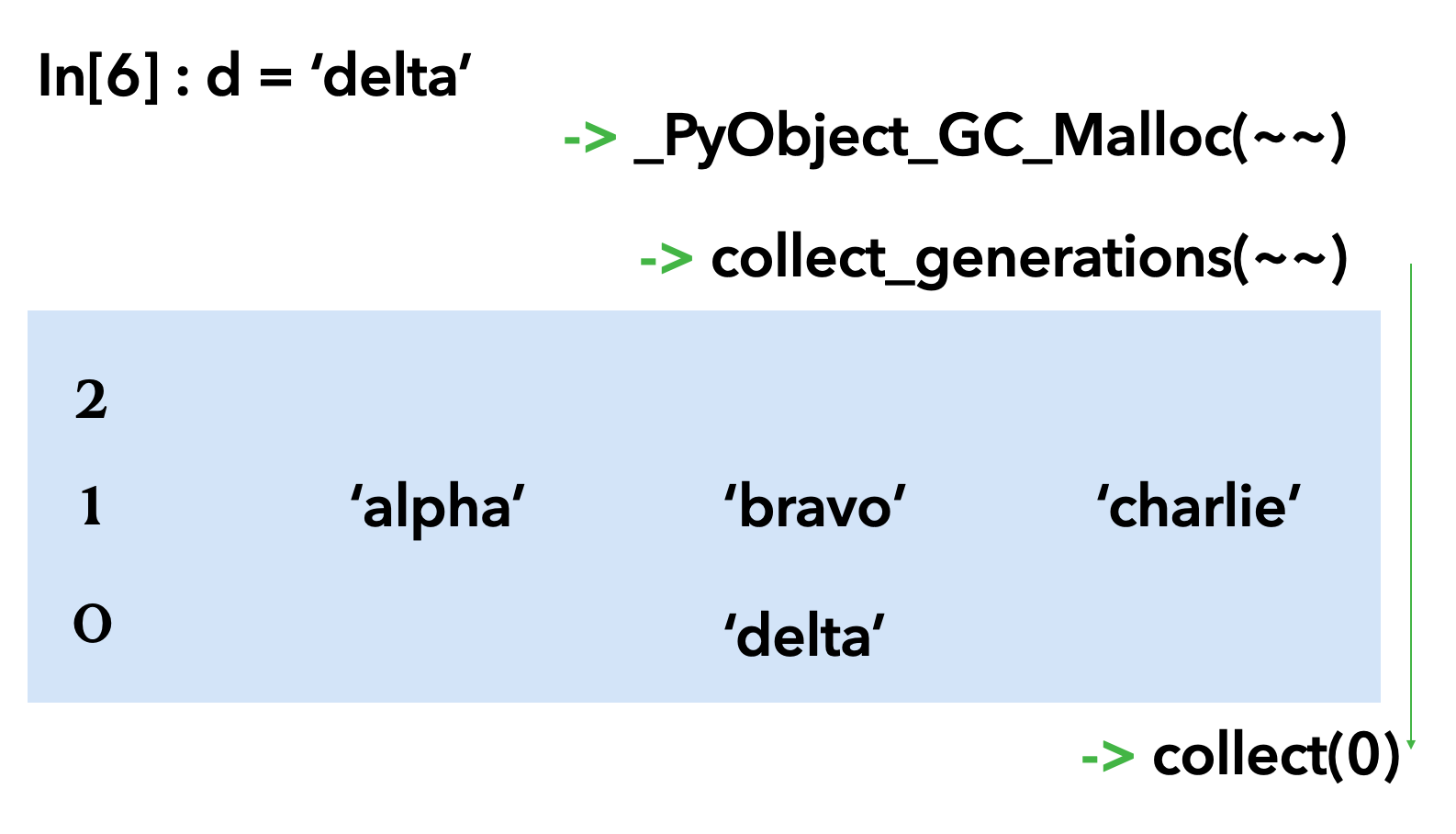
이번엔 b를 지워보고 'echo', 'foxtrot', 'golf'를 선언해보자
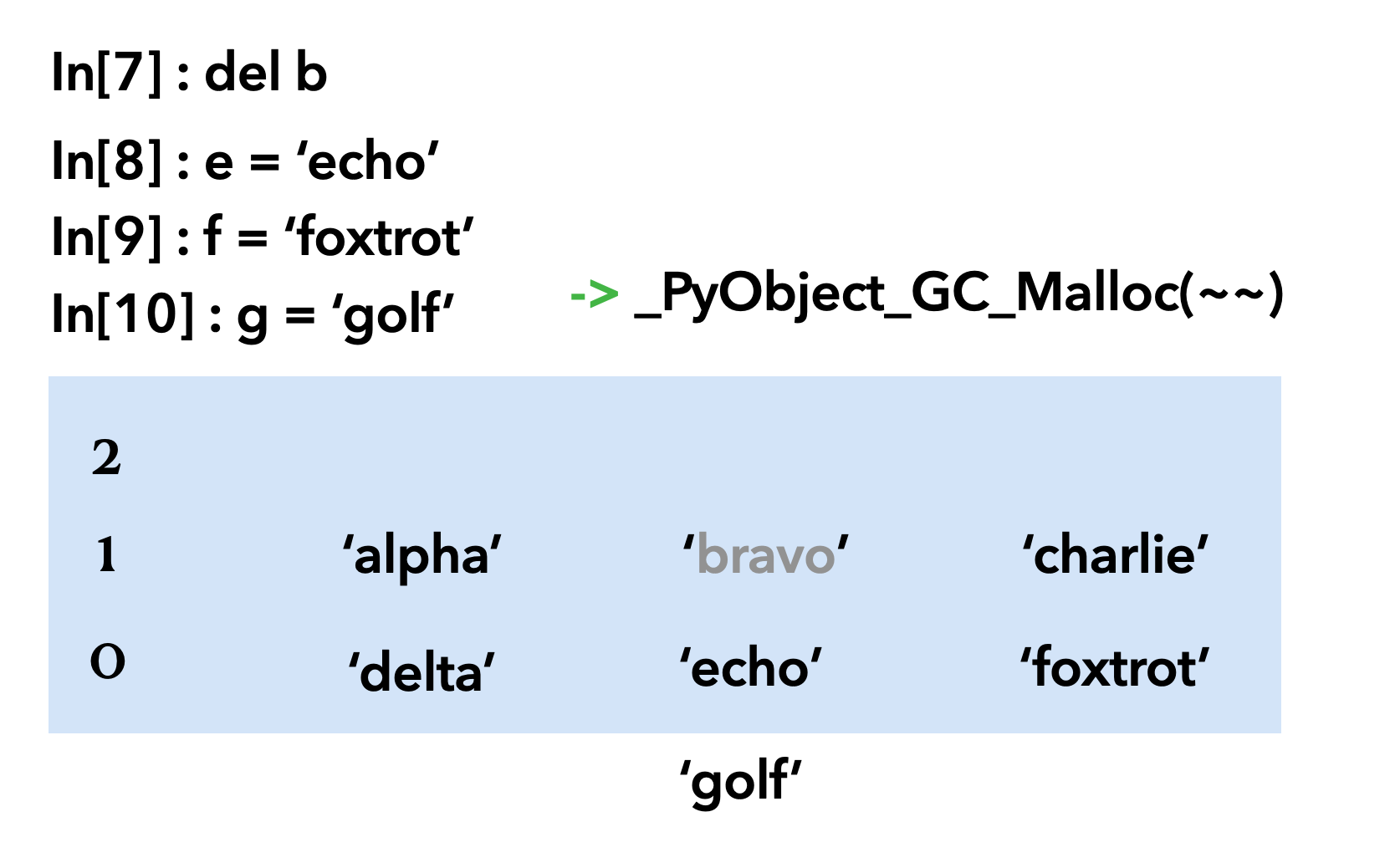
bravo는 아직 살아있지만 얼마 가지 못할 것 같다. 다음을 보자.
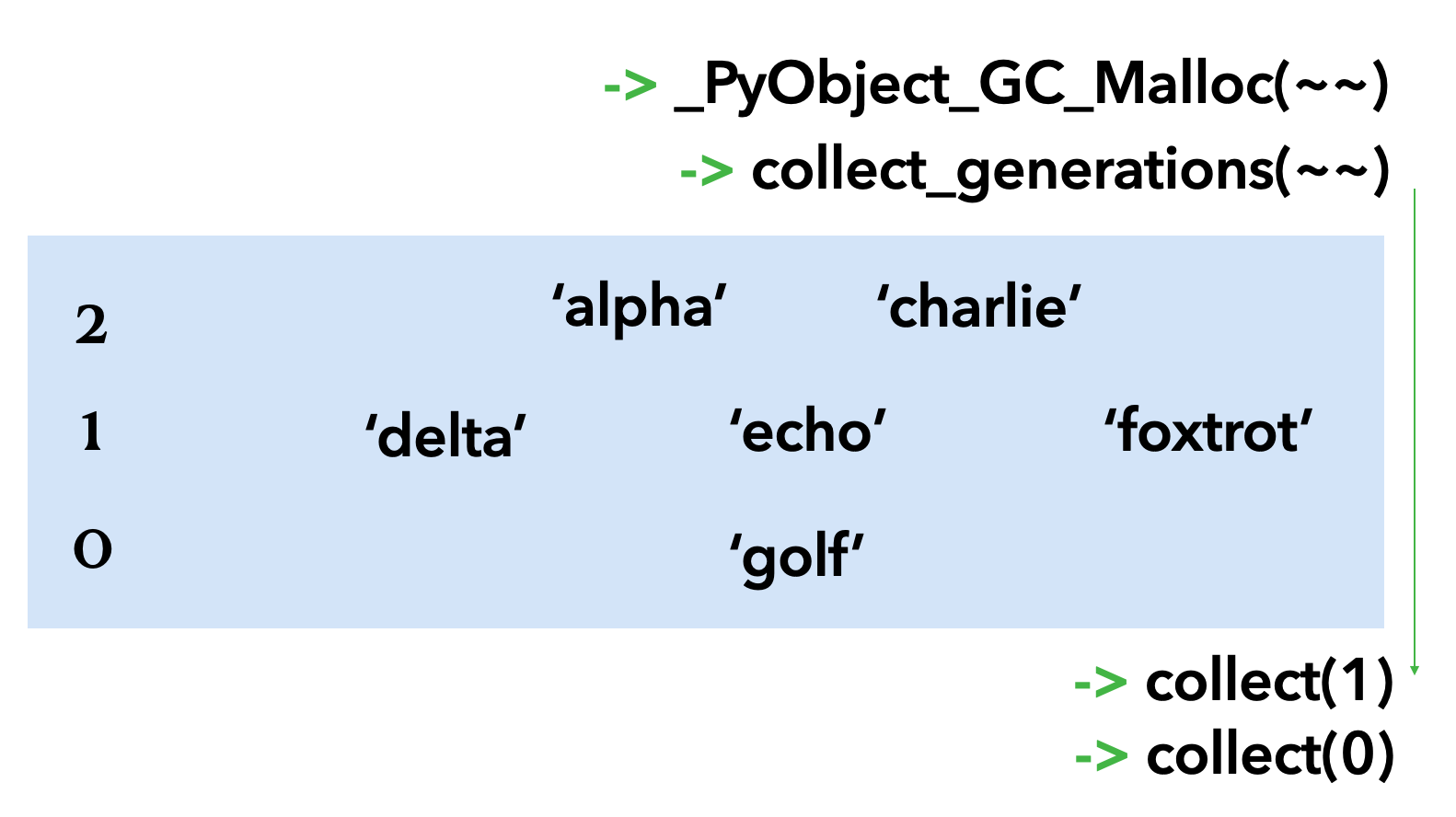
collect가 한번 더 시행이 되고 refcount가 0인 bravo는 영영 삭제가 되었다. 그리고 2세대까지 올라가게 되었다.
예시에서는 쉬운 설명을 위해 threshold를 3으로 설정했지만 실제로는
In[1] : import gc
In[2] : print(gc.get_threshold())
Out[1] : (700, 10, 10) # 0, 1, 2 generaion의 threshold가 튜플형태로 출력output의 (700, 10, 10) 의 뜻을 알아보자
1 . 700
할당한 메모리의 수가 해제한 수보다 700이 더 많을 때 == 할당한 메모리 - 해제한 메모리 수
이때 gc가 자동으로 실행된다. (수동으로도 실행시킬 수 있음.)
2 . 첫번째 10
0제네레이션의 gc 실행횟수가 10이 되면 1제네레이션에서도 gc를 실행한다.
3 . 두번째 10
1제네레이션에서 gc 실행횟수의 10이 되면 2제네레이션에서도 gc를 실행한다.
이런 식으로 세대차이를 두었다는 것을 알 수 있다. threshold를 바꿀 수도 있다.
threshold 바꾸기
In[1] : import gc
In[2] : gc.set_threshold(800, 20, 20)💁🏻♂️ weakref module
말그대로 약한 참조를 할 수 있는 모듈이다. refcount가 증가하지 않으면서 특정 객체를 참조가능하다. 메모리를 많이 쓰지만 필수적이지는 않은 이미지 캐싱같은 경우에 사용한다.(메모리를 계속 잡아먹지 않는다.)
- weakref.ref(obj, callback = None)
이런 식으로 사용한다. 해당 객체의 weakref를 생성하고 반환한다. 해당 weakref를 호출함으로서 원본 객체를 가져오고 참조하는 객체가 없을 시에 에러가 아닌 None을 반환한다.(gc될때)
class weakref 참조 예시
import weakref
class SomeClass(object):
def __init__(self, *args):
super(SomeClass, self).__init__(*args)
a = SomeClass()
b = weakref.ref(a)
print(b())
Out : <__main__.SomeClass object at 0x7fae6c2c04c0>
del a
print(b())
Out : Noneimage caching 사용예시
cache = None
def get_image():
if cache is None:
image = Image(file('image.png', 'rb').read())
cache = weakref.ref(image)
return cache
show(get_image())
...
# other codes
...
show(get_image())💁🏻♂️ 메모리 관리 관련 소소한 팁들
1 . string concating 문자열 결합을 피하자.
나쁜 예
s = ''
for x in somelist:
s += some_function(x)좋은 예
''.join(map(some_fuction, somelist))나쁜 예
s = 'Hello!' + first_name + ' ' + last_name + '!'좋은 예
s = 'Hello! {} {}'.format(first_name, last_name)이유는 + 로 concat을 할 때 메모리 재할당을 하니 성능이 저하가 된다. python에서 제공하는 join, format 등의 함수로 극복하자.
2 . Iterating over list
iterate 도중 변경되는 객체의 경우 복사해서 사용하자.
나쁜 예
for k, v in somedict.items():
somedict[k] = v * 2 # 딕셔너리의 value 값을 두배씩해준다.좋은 예
for k, v in somedict.copy().items():
somedict[k] = v * 23 . Use a little scope as possible
나쁜 예
f = file('test.pak', 'rb')
data = f.read()
print(data) # data를 읽은 뒤에도 계속 메모리를 점유하고 있는다.좋은 예
with file('test.pak', 'rb') as f:
data = f.read()
print(data) # with scope 안에서만 점유한다.참조한 영상
유튜브 영상 '배준현: 파이썬 메모리 이모저모 - PyCon Korea 2015
'을 많이 참조하여 글을 작성해보았습니다. 바뀐 내용이나 틀린 내용은 댓글, 이메일로 피드백 부탁드립니다.
💁🏻♂️ 결론
편리함만 바라보면 100점짜리 프로그래머가 될 수 없다고 생각했습니다. 편리함 안에는 보이지 않게 작동하는 많은 동작들이 있습니다. 그 동작들을 알고 사용할 때 진정으로 잘 사용할 줄 아는 프로그래머가 되지 않을까 생각합니다. 더 깊은 공부를 해봅시다! 👍

4개의 댓글

문자열 결합은 + 그냥 쓰던건데 메모리를 계속 할당한다니 충격이군요. 그리고 Iterating 중에 값을 변경해야 하는 경우도 많은데 여기서 다시한번 언급해주니 좋네요
GC의 개념을 설명하기 위해 python에서의 variable, memory addresss 등의 대한 설명을 시작으로 간단한 예제가 이해하기 정말 좋네요.
정성들인 포스팅 덕에 머리에 쏙쏙 들어오네요. 많은 배움 얻어갑니다 ~! 감사합니다