
🌈 정규 표현식
1. 정규 표현식이란?
1) 메타 문자
- 특정한 규칙을 가진 문자열을 처리하는데 사용하는 기법임
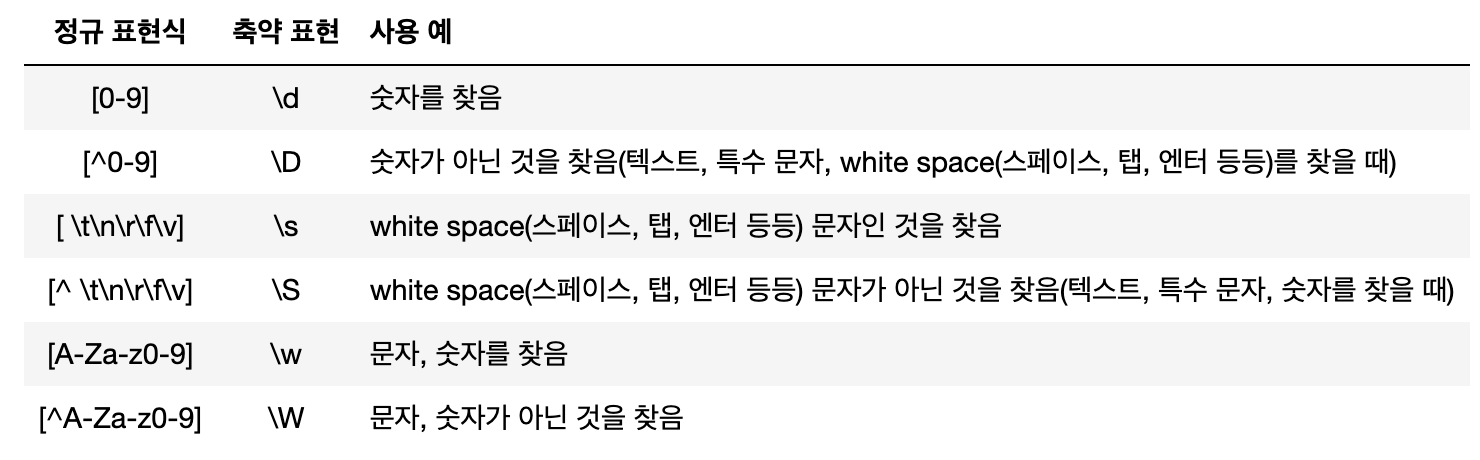
- re 라이브러리는 pyhton에서 정규표현식을 지원함
- re 라이브러리에 sub() 함수는 파라미터를 3개 받는데, 첫번째는 정규표현식 두번째는 대체하고 싶은 것, 세번째는 타켓이될 대상(문자열이나 변수)가 들어감
- 즉, sub() 함수는 특정 패턴이 매칭되는 것을 찾아서, 다른 문자열로 바꿔꾸는 기능임
✍🏻 python
# 문자, 숫자가 아닌 데이터를 찾아 없애기 import re # python에서 지원하는 정규지원식 라이브러리 string = '(!#!@#Dave!@#!@#!)' print(re.sub('[^A-Za-z0-9]', '', string)) # Dave
2) Dot(.) 규칙
- Dot(.)은 정규표혀닉에서 줄바꿈 문자인 \n을 제외한 모든 문자(1개)를 의미함
- ex) D.A = D + 모든문자 중 1개 + A => DAA, DvA, D9A 등..
✍🏻 python
# string의 문자열 중 'D.A'에 해당하는 것을 찾아 'Dave'로 바꿔라 import re string = 'DDA DP DPA DA D2A' re.sub('D.A', 'Dave', string) # Dave DP Dave DA Dave
2) 반복 규칙 : ?, *, +
- ?는 ?기준으로 왼쪽 문자가 0번 또는 1번 표시되는 패턴(없어도 되고, 한번 까지 있어도 되는 패턴)
- 변수.serach() : ()안에 문자가 변수에서 일치하는 하는지 확인
- 일치하는 index부분과 문자열을 반환, 일치하지 않으면 None 반환
✍🏻 python
# ? 앞 문자가 0번 또는 1번 표시되는 패턴(없어도되고, 있어도 됨) import re pattern = re.compile('D?A') print(pattern.search("A")) # <re.Match object; span=(0, 1), match='A'> print(pattern.search("DA")) # <re.Match object; span=(0, 2), match='DA'> print(pattern.search("DDDDDDA")) # <re.Match object; span=(5, 7), match='DA'> *는*기준으로 왼쪽 문자가 0번 또는 그 이상 반복되는 패턴✍🏻 python
# ? 앞 문자가 0번 또는 1번 이상 반복되는 패턴 import re pattern = re.compile('D*A') # * 왼쪽 문자에 D가 없거나, 여러번 반복 print(pattern.search("A")) # <re.Match object; span=(0, 1), match='A'> print(pattern.search("DA")) # <re.Match object; span=(0, 2), match='DA'> print(pattern.search("DDDDDDDDDDDDDDDDDDDDDDDDDDDDA")) # <re.Match object; span=(0, 29), match='DDDDDDDDDDDDDDDDDDDDDDDDDDDDA'>```
- +는 +기준으로 왼쪽 문자가 1번 또는 그 이상 반복되는 패턴
✍🏻 python
# ? 앞 문자가 1번 또는 그 이상 반복되는 패턴 import re pattern = re.compile('D+A') print(pattern.search("A")) # None print(pattern.search("DA")) # <re.Match object; span=(0, 2), match='DA'> print(pattern.search("DDDDDDDDDDDDDDDDDDDDDDDDDDDDA")) # <re.Match object; span=(0, 29), match='DDDDDDDDDDDDDDDDDDDDDDDDDDDDA'>
3) {n}, {m,n} 표현
- {n} 기준 왼쪽 문자열이 n번 반복되는 패턴
- {m,n} 기준 왼쪽 문자열이 m번 반복되는 패턴부터 n번 반복되는 패턴
✍🏻 python
# {n} 기준 왼쪽 문자열이 n번 반복되는 패턴 import re pattern = re.compile('AD{2}A') # => A + {}왼쪽 문자인 D가 2번 반복 + A print(pattern.search("ADA")) # None print(pattern.search("ADDA")) # <re.Match object; span=(0, 4), match='ADDA'> print(pattern.search("ADDDA")) # None# {m,n} 기준 왼쪽 문자열이 m번에서 n번까지 반복되는 패턴 import re pattern = re.compile('AD{2,6}A') # {m,n} 은 붙여 써야 함 {m, n} 으로 쓰면 안됨 print(pattern.search("ADDA")) # <re.Match object; span=(0, 4), match='ADDA'> print(pattern.search("ADDDA")) # <re.Match object; span=(0, 5), match='ADDDA'> print(pattern.search("ADDDDDDDDDA")) # None
4) []괄호 : 괄호 안에 들어가는 문자가 들어 있는 패턴
- [] 는 []안에 들어있는 문자가 존재하는지 확인
✍🏻 python
import re pattern = re.compile('[abcdefgABCDEFG]') print(pattern.search("a1234")) # <re.Match object; span=(0, 1), match='a'> print(pattern.search("z1234")) # None
5) 하이픈(-)을 이용하면 알파벳 범위 전체를 나타낼 수 있음
- []패턴에서 모든 문자를 입력하면 번거롭기 때문에 하이픈과 같이 활용함
- 예를 들어 알파벳 소문자가 들어있는지 확인하거나 알파벳 어디서부터 어디까지 포함되있는지 확인할 때
✍🏻 python
import re pattern = re.compile('[a-z]') # a부터 z까지 표현하는 정규식 print(pattern.search("k1234")) # <re.Match object; span=(0, 1), match='k'> print(pattern.search("Z1234")) # Nonepattern = re.compile('[a-zA-Z]') # a~z, A~Z까지 표현하는 정규식 print(pattern.search("Z1234")) # <re.Match object; span=(0, 1), match='Z'>pattern = re.compile('[a-zA-Z0-9]') # a~z, A~Z, 0~10 까지 표현하는 정규식 print(pattern.search("1234---")) # <re.Match object; span=(0, 1), match='1'> print(pattern.search("---------------!@#!@$!$%#%%%#%%@$!$!---")) # Noneimport re pattern = re.compile('[가-힣]') 모든 한글 print(pattern.search("안")) # <re.Match object; span=(0, 1), match='안'>
2. 정규 표현식 함수 사용법
- match 함수 : 문자열 처음부터 정규식과 매칭되는 패턴을 찾아 리턴
- search 함수 : 문자열 전체를 검색해서 정규식과 매칭되는 패턴을 찾아서 리턴
- findall 함수: 정규표현식과 매칭되는 모든 문자열을 리스트 객체로 리턴함
1) match() 와 search() 함수
- match()는 문자열을 정규표현식과 일치하는지 앞에서부터 찾고 처음부터 다르면 비교 진행 안함
- serch()는 문자열 전체에서 찾아주기 때문에 어디서에서든 포함되어있으면 일치하는 부분을 반환해줌
✍🏻 pythonimport re pattern = re.compile('[a-z]+') # 소문자 a~z까지 print(pattern.match('Dave')) # None print(pattern.search("Dave")) # <re.Match object; span=(1, 4), match='ave'>
2) findall() 함수
- 어떤 문자열과 정규식을 비교해서 리스트 형식으로 반환함
✍🏻 python
# 정규표현식과 매칭되는 모든 문자열을 리스트로 반환 import re pattern = re.compile('[a-z]+') findalled = pattern.findall('Game of Life in Python') print (findalled) # ['ame', 'of', 'ife', 'in', 'ython']pattern2 = re.compile('[A-Za-z]+') findalled2 = pattern2.findall('Game of Life in Python') print (findalled2) # ['Game', 'of', 'Life', 'in', 'Python']

Keep Going, Keep Coding!