
📌 이 포스팅에서는 웹브라우저에서 "google.com"을 입력하면 일어나는 일에 대해 정리하였습니다.
🌈 웹브라우저에서 "google.com"을 입력하면 일어나는 일
1. 웹 브라우저가 URI을 해석한다.
2. HSTS(HTTP Strict Transport Security) 목록을 조회한다.
3. Cache를 뒤져, URL(maps.google.com)에 대한 IP주소를 요청한다.
4. Cache에 존재하지 않다면, DNS 질의하여 IP주소를 요청한다.
5. IP주소를 확인했다면, Browser가 서버와 TCP connection을 한다
6. 웹 브라우저가 서버로 Request를 전송한다.
7. 서버가 요청을 처리하고 response를 생성한다.
8. 서버가 HTTP response를 보낸다.
9. Browser가 HTML content를 보여준다
🤔 웹 브라우저가 URI을 해석한다.
✔️ URI 파싱이란 웹 브라우저에서 어떤 protocal, domain, port, path로 요청할 것인지 입력한 정보를 바탕으로 해석 및 분석하는 과정을 의미한다.
✔️ 명시적으로 port를 선언하지 않았다면, HTTP는 80, HTTPS 443의 기본값으로 요청이 이뤄진다.
✔️ URI 문법에 맞지 않는 검색어가 주소창에 입력되었다면 기본 검색엔진으로 검색이 이뤄지고, host 부분이 한글, 이모지 등으로 입력되었다면 허용된 ASCII 문자열로 변환하기 위해 host 부분에 대하여 퓨니코드(punycode) 인코딩 작업이 이뤄진다.
✔️ 퓨니코드(punycode) 인코딩은 웹브라우저에서 이뤄지며, "XN--" 문자로 시작하는 영어, 숫자, 하이픈(-)의 형태로 변환된다.
🤔 HSTS(HTTP Strict Transport Security) 목록을 조회한다.
✔️ HSTS는 HTTPS protocal을 권장하기 위해 브라우저에 알리는 보안기능으로 HSTS 목록에 있으면 첫 요청을 HTTPS로 보내고, 아닌 경우 HTTP로 보낸다.
✔️ 이에 웹 브라우저에서는 HSTS 목록 조회를 통해 해당 요청을 HTTPS로 보낼지 판단하고, HSTS 목록에 해당 URI가 존재한다면 명시적으로 HTTP로 요청한다 할지라도 웹 브라우저에 의해 HTTPS 요청된다.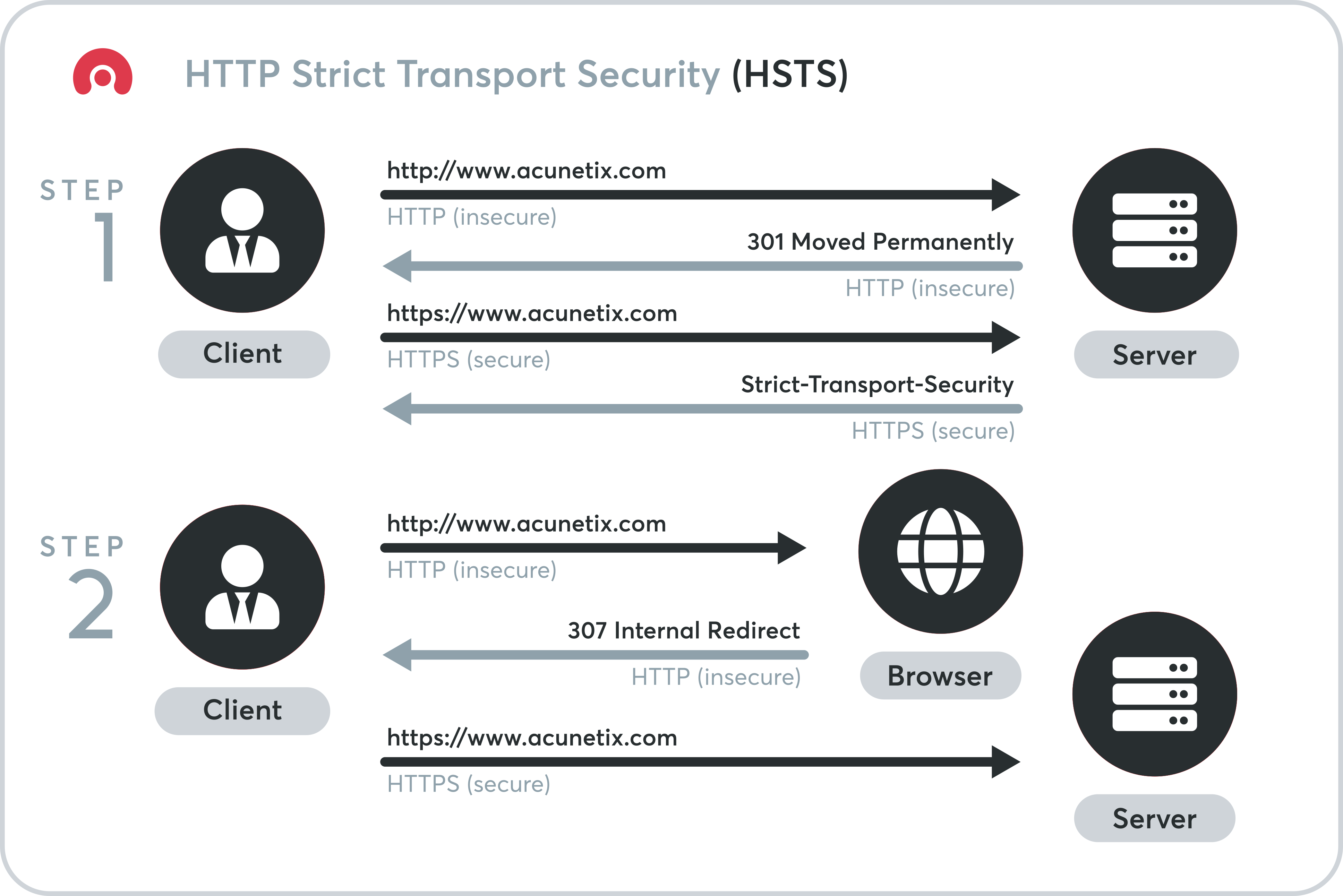
🤔 Cache를 뒤져, URL(maps.google.com)에 대한 IP주소를 요청한다.
✔️ domain 주소로는 서버와 통신할 수 없기 때문에 이를 컴퓨터가 읽을 수 있는 IP 주소로 변환해야 서로 통신이 가능하다.
✔️ naver.com, google.com 등 doamin 주소가 IP주소와 매핑되어 별도로 존재하는 이유는 숫자로된 주소를 외우기가 힘들기 때문이다.
👏 참고 :
nslookup google.com를 터미널에서 입력하면, google.com의 IP 주소를 확인 가능하다.
✔️ domian 주소에 해당하는 IP주소를 찾기 위해 아래 4가지 캐쉬 기록 순차적으로 확인한다.
- Browser cache : 웹브라우저를 통해 방문했던 DNS record 기록을 일정 기간 동안 저장하고 있는 곳 중 가장 먼저 접근하여 탐색되는 곳이다. 이곳에 해당 domain에 대한 ip주소 확인하기 위해 query를 보낸다.
- OS cache : Browser cache에 존재하지 않다면, systemcall을 통해서 운영체제가 저장하고 있는 DNS 기록(hosts 파일)들에 접근한다
- Router cache : OS에도 DNS cache 기록이 없다면, router에 요청하여 참조할 수 있는 DNS 기록이 있는지 요청한다.
- ISP(Internet Search Provider) cache : 마지막으로 ISP에서 DNS 기록을 확인한다. ISP는 서비스 공급자의 약자로 SK, LG, KT 등을 의미하고, ISP에는 각 자의 DNS 서버를 보유하기 때문에 이 곳에서 마지막으로 확인한다.
✔️ 4개의 영역에서 DNS record를 cache로 가지고 있는 이유는 네트워크 트래픽을 낮추고 데이터 전송 시간을 개선하는데 도움을 주기 때문이다.
🤔 Cache에 존재하지 않다면, DNS 질의하여 IP주소를 요청한다.
✔️ DNS(Domain Name Server) 서버는 할당된 domain에 대한 정보를 가지고 있는 서버로, domain을 IP주소로 변환하는 역할을 한다.
✔️ 만약 요청한 URL이 위 4곳의 캐쉬에 없다면, ISP의 DNS 서버가 DNS query로 서버의 IP 주소를 요청한다.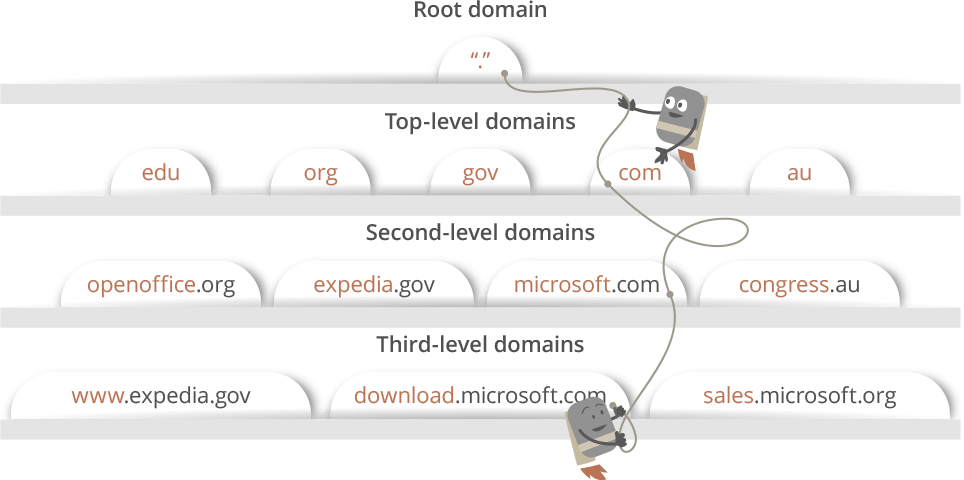
✔️ DNS query의 목적은 여러 다른 DNS 서버들을 검색해서 해당 URL의 IP주소를 찾는 것이다.
✔️ Root DNS 서버에서 Third-level DNS 서버까지 redirect하여 해당하는 URL의 IP주소를 반환받거나, Error를 발생시킬 때 까지 탐색을 거친다. 이러한 검색 방식은 recursive search라 부른다.
🤔 IP주소를 확인했다면, Browser가 서버와 TCP connection을 한다
✔️ Cashe에서 URL에 대한 IP주소를 확인했거나, DNS 요청에 의해 IP 주소를 알아냈다면 Browser가 해당 URL을 호스팅하는 서버에서 TCP 연결을 맺는다.
✔️ 이 과정에서 HTTP 요청이 이뤄졌다면, TCP(Transmission Control Protocol) 소켓을 열고 3-way handshake로 연결을 설정하고, HTTPS 요청이 이뤄졌다면, TLS(Transport Layer Security) handshake 과정을 통해 세션키를 생성한다.
✔️ 3-way handshake란, 본 요청을 보내기 전 클라이언트와 서버가 통신을 하여 서로 연결을 확인하기 절차이다. 이를 통해 서버가 현재 불능 상태가 아닌지 확인할 수 있다.
- 클라이언트에서 서버에 연결 요청(SYN), 이 때 클라이언트는 Closed, 서버는 LISTEN 상태이다(연결 가능한지 묻는 과정).
- 서버에 새 연결을 수락할 수 있는 열린 포트가 있는 경우, SYN/ACK 패킷을 사용하여 SYN 패킷의 ACK(승인)으로 응답한다(연결 가능하다 답하는 과정).
- 클라이언트는 서버로부터 SYN/ACK 패킷을 수신하고 ACK 패킷을 전송하여 승인한다(확인했다는 응답 과정).
🤔 웹 브라우저가 서버로 Request를 전송한다.
✔️ 3-way handshake로 연결이 확인되었다면, 클라이언트에서 본 요청을 전송한다.
✔️ 이 때, 클라이언트의 웹 브라우저는 GET 요청 사용해 서버에게 www.google.com의 index.html를 요구한다.
✔️ 요청을 할 때 브라우저 식별 정보(User-Agent), 수락할 요청 유형(Accept) 등 여러 header 정보도 포함되고, 일반적으로 서버에 항상 보내지는 쿠기 정보도 함께 담아 전송된다.
🤔 서버가 요청을 처리하고 response를 생성한다.
✔️ 서버는 앞 단에 웹서버를 가지고 있다. 이 웹서버는 Apache, Microsoft(IIS), Sun, nginx 등이 있고, html,css,이미지 파일 등 정적 처리를 웹서버에서 맡는다.
✔️ 만일 동적 처리가 필요하다면, WSGI와 같은 미들웨어를 거쳐 서버로 요청이 전달된다. 미들웨어를 거치는 이유는 Web server에서 python 등 코드를 호출하는 방법을 알지 못하기 때문이다.
✔️ 이후 서버에서 해당 url conf를 통해 요청은 파싱하고, 요청에 따른 함수를 작동시켜 response를 특정한 포맷(JSON, XML, HTML)으로 작성한다.
🤔 서버가 HTTP response를 보낸다
✔️ 서버 응답은 요청에 대한 page, status code, encoding type, cache control, cookie set, privacy info 등을 정보를 함께 반환한다.
✔️ reponse의 맨 상단에는 status code가 존재하는데, 응답 상태를 다음의 5가지 형태로 명시한다.
- 1xx(Informational) : 클라이언트의 요청이 수신되어 처리 중, 실제 거의 사용되지 않음
- 2xx(Successful) : 클라이언트의 요청 정상 처리
- 3xx(Redirection) : 클라이언트의 요청을 완료하려면 추가 행동이 필요
- 4xx(Client Error) : 잘못된 문법 등으로 서버가 요청을 수행할 수 없음 👈 클라이언트 오류
- 5xx(Server Error) : 서버 내부의 문제로 서버가 요청을 처리하지 못함 👈 서버 오류
✔️ header의 field 속성은 이미 정리(Header의 field 속성, 쿠키와 캐쉬 관련 Header)해두었다.
🤔 Browser가 HTML 컨텐츠를 보여준다
✔️ 웹 브라우저는 응답 받은 HTML을 단계별로 표시한다.
✔️ 처음은 HTML 스켈레톤(기본틀)을 렌더링한다. 그 다음에는 HTML tag들을 체크하고나서 추가적으로 필요한 요소들(이미지, CSS, Javascript 등)을 통해 세부사항을 상세하게 다룬다.
✔️ 이 중 정적 파일들은 브라우저에서 자동으로 캐싱하는데, 다음에 다시 가져오지 않기 위해서이다. 왜냐하면 통신의 비용을 절감하기 위해서이다.
✔️ 이 때문에 서버 request를 보낼 때, 해당 도메인에 대한 캐쉬 정보(유효기간, 검증 헤더와 조건부 요청, Etag등)가 자동으로 전송되는 것이다. 이 정보를 통해 해당 정적 파일을 다시 응답받아야할지, 이미 받은 파일을 사용하면될지 판단할 수 있다.

이해가 쏙쏙 돼요! 잘 읽었습니다 👏️👏️👏️