Redshift
AWS에서 지원하는 데이터 웨어하우스 서비스
2 펩타바이트 데이터 까지 처리 가능
최소 160gb(고정비용 ssd사용 - 처리속도가 더 빠름)
still olap - 응답속도가 빠르지 않기 때문에 프로덕션 데이터베이스로 사용불가
칼럼 기반 스토리지
레코드 별로 저장하는 것이 아니라 컬럼별로 저장함
컬럼별로 압축이 가능하며 컬럼을 추가하거나 삭제하는 것이 아주 빠름
특징 2
벌크 업데이트 지원
- 레코드가 들어있는 파일을 s3로 복사 후 copy 커맨드로 redshift로 일괄 복사
고정 용량/비용 sql 엔진 - 현재 redshift serverless로 가변 비용도 가능
데이터 공유 기능 - snowflake
다른 데이터 웨어하우스처럼 Primary key uniqueness를 보장하지 않음
- 프로덕션 데이터베이스들은 보장함
redshift는 sql이 메인 언어이다.
postgresql 툴이나 라이브러리로 액세스 가능, sql이 호환
Redshift 스케일링 방식
- 용량이 부족해질 때마다 새로운 노드를 추가하는 방식으로 스케일링
scale out방식과 scale up 방식
dc2.large -> 0.16tb 를 2개 놓아서 0.32tb로 scale out
더 좋은 사양으로 업그레이드 scale up
이를 resizing이라 부르며 auto scaling 옵션을 설정하면 자동으로 이뤄짐
(Dense compute 와 manage storage에서만 가능)
snowflake나 bigquery의 방식과는 굉장히 다름
위의 데이터웨어하우스가 좀 더 scalable but) financing하기가 어려움
Redshift 최적화는 굉장히 복잡
redshift가 두대 이상의 노드로 구성되면 한 테이블의 레코드들의 저장 방식은?
빅쿼리나 snowflake은 분산된 노드에 레코드를 어떻게 저장할 건지 고민할 필요도 알 방법도 없다. redshift는 정해줘야함.
Redshift의 레코드 분배와 저장 방식
Redshift가 두 대 이상의 노드로 구성되면 그시점부터 테이블 최적화가 중요
한 테이블의 레코드들을 어떻게 다수의 노드로 분배할 것이냐?
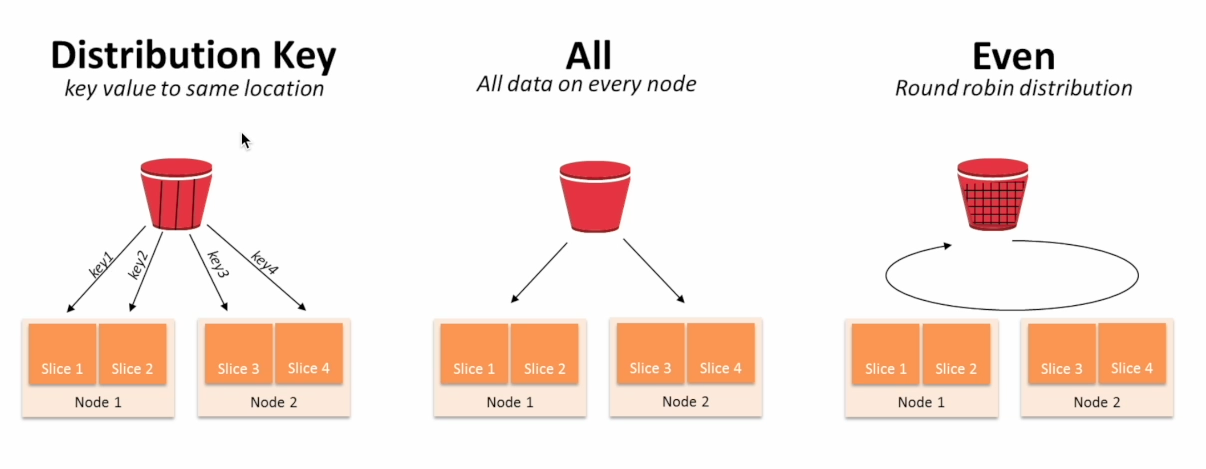
Distkey, Diststyle, Sortkey 세 개의 키워드를 알아야함
Diststyle은 레코드 분배가 어떻게 이뤄지는지를 결정
- all(모든 레코드 복제, 노드가 몇개 없을 때), even(노드별로 round robin), key(default는 "even")
Distkey는 레코드가 어떤 컬럼을 기준으로 배포되는지 나타냄(diststyle이 key 인 경우만 의미 있음)
SortKey 레코드가 어떤 커럼을 기준으로 배포되는지 나타냄 - 이는 보통 타임스탬프 필드가 됨
Distyle이 key인 경우 컬럼 선택이 잘못되면?
레코드 분포에 skew가 발생 -> 분산처리의 효율성이 사라짐 - 데이터 적재의 불균형
bigquery나 snowflake는 이러한 속성을 고민할 필요가 없음
create table my_table(
column1 int,
column2
...
) diststyle key distkey(column1) sortkey(column3)column1의 값이 같은 레코드 끼리 같은 노드로 뭉침. my_table의 레코드들은 컬럼1의 값을 기준으로 분배되고 같은 노드 안에서는 column3의 값을 기준으로 소팅이됨.
sortkey는 timestamp가 default. 해당 key를 가지고 join을 하거나 groupby를 한다면 -> distribution key가 좋고, 만약 skew가 너무 심하다. 그렇다면 even이나 all이 좋음.
Redshift의 벌크 업데이트 방식 - copy sql
- 소스로부터 데이터 추출 -> 데이터 파이프라인 프레임웍(airflow , scheduling) 압축률이 좋은 바이너리 타입 선호
- s3에 업로드(보통 parquet 포맷을 선호)
- copy sql로 s3에서 redshift테이블로 한번에 복사
redshift data type
프로덕션 db와 비슷
차이점은?
- production db에서는 영문 이든 한글 이든 중국어든 한글자는 한 character로 지정
- redshift에서는 byte type으로 (utf-8은 3byte) -> 언어에 따라서 byte 수가 다르기에 character로 잡는 기준이 달라짐
redshift의 고급 데이터 타입
- geometry
- geography
- hllsketch
- super
레드시프트는 json을 native한 타입으로 지원x. 즉 character type으로 받아와서 json 함수로 Parsing 하는 것
참고로 서울 리전은 비싸다..
Redshift
먼저 public access를 on gownwk
vpc 설정에서 인바운드 규칙에 포트번호 5439를 0.0.0.0/0에 오픈
!pip install SQLAlchemy==1.4.49
!pip install ipython-sql==0.4.1SQLAlchemy의 업그레이드로 해당 코드를 꼭 작성해줘야함
Redshift Schema : 다른 기타 관계형 데이터베이스와 동일한 구조
DEV
- raw_data : ETL 결과가 들어감
- analytics : ELT 결과가 들어감
- adhoc : 테스트용 테이블이 들어감
- pii : 개인정보가 들어감
Schema 설정
스키마를 설정하고 싶다면 -> admin권한이 필요함
그룹(group) 생성/설정(1)
- 한 사용자는 다수의 그룹에 속할 수 있음
- 그룹의 문제는 계승이 안된다는 점
- 즉 너무 많은 그룹을 만들게 되고 관리가 힘들어짐 - 예를 들어 다음과 같은 그룹이 존재
- 어드민을 위한 pii_users- 데이터 분석가를 위한 analytics_authors
- 데이터 활용을 하는 개인을 위한 analytics_users
analytics_users > analytics_authors > pii_users
그룹의 문제는 analytics_user 권한을 authors에서도 일부분 적용하게끔 하면 좋겠지만 (oop 하듯이) but) redshift는 안됨.
참고)
데이터베이스 스키마는 관계형 데이터베이스에서 데이터가 구조화되는 방식을 정의합니다. 여기에는 테이블 이름, 필드, 데이터 유형, 그리고 이러한 엔티티 간의 관계
Amazon Redshift에서 스키마는 테이블을 그룹화하고 조직화하기 위한 개체를 나타냅니다.
역할(Role) 생성/설정
역할은 그룹과 달리 계승 구조를 만들 수 있음
역할은 사용자에게 부여될 수도 있고 다른 역할에 부여될 수 도 있음.
한 사용자는 다수의 역할에 소속가능함.
COPY & aws IAM
copy 명령을 사용해 raw_data 스키마 밑 3개의 테이블에 레코드를 적재해볼 예정
각 테이블을 create table 명령으로 raw_data 스키마 밑에 생성
이때 각 테이블의 입력이 되는 csv 파일을 s3로 복사
s3에서 해당 테이블로 복사를 하려면 redshif가 s3접근 권한을 가져야함
먼저 redshift가 s3를 접근할 수 있는 역할을 만들고
이역할을 redshift클러스터에 지정하자
s3가 redshift에 접근할 수 있도록 iam을 설정해주자.
csv 파일을 rawdata schema 밑 테이블로 복사할 때
csv 파일이기에 ddelimiter로는 콤마(,)로 지정
csv 파일에서 문자열이 따옴표로 둘러싸인 경우 제거하기 위해 removequotes 지정
csv 파일의 첫번째 라인을 무시하기위해 ignoreheader 1을 지정
credentials에 앞서 redshift 지정한 role을 지정하고 arn을 읽어와야한다
만약 테이블을 copy명령을 사용해 앞서 csv 파일들을 테이블로 복사하는데 오류가 난다면?
aksdlf copy 명령 실행 중에 에러가 나면 stl_load_errors 테이블 내용을 보고 확인
SELECT * FROM stl_load_errors ORDER BY startime DESC;