다양한 데이터 웨어하우스 옵션
1. 데이터 팀의 역할
신뢰할 수 있는 데이터를 바탕으로 부가 가치 생성
고품질 데이터를 기반으로 의사 결정권자에게 입력 제공
데이터 고려한 결정 vs 데이터 기반 결정
data informed decisions가 더 좋음. 데이터는 기본적으로 과거의 기록, 과거의 기록을 보고
움직인다는 것은 새로운 혁신을 창출하기에는 어려움 결국 informed 와 driven이 섞여야 함.
- decision science
고품질 데이터를 기반으로 사용자 서비스 경험 개선 혹은 프로세스 최적화
머신 러닝과 같은 알고리즘을 통해 사용자의 서비스 경험을 개선
- product science
데이터 인프라 -> 데이터분석(지표 정의, 시각화) -> 데이터 과학 적용(사용자 경험 개선 : 추천, 검색)
데이터 팀의 발전
데이터 인파라의 구축은 데이터 엔지니어가 수행함
가장 유명한 예시는 apache airflow
서비스를 운영하는 데 필요한 디비 - 프로덕션 디비(운영하는데 필요한 최소의 디비)
데이터 분석을 위한 데이터가 저장된 디비 - 데이터 웨어하우스(적재량이 훨씬 큼)
- 고객들이 접근하는 것이 아닌, 내부 직원들의 데이터
프로덕션 데이터베이스 - mysql, postgresql : OLTP Online Transaction Processing
프로덕션 디비 같은 경우는 최소의 서비스를 운영할 정도만 필요함
데이터 웨어하우스 - OLAP Online Analytical Processing
모든 데이터가 저장되어 있기 때문에 속도가 느려도 됌
회사가 작다면 데이터웨어하우스 솔루션을 쓸 필요가 없다.
회사가 커지는 시점에 교체하면 됨
데이터 웨어하우스
회사에 필요한 모든 데이터를 모아놓은 중앙 데이터베이스(SQL 데이터베이스)
Redshift, BigQuery, snowflake, hadoop -> 모두 sql을 지원
중요 포인트는 프로덕션용 데이터베이스와 별개의 데이터베이스여야 한다는 점
데이터 웨어하우스의 구축이 진정한 데이터 조직이 되는 첫 번째 스텝
Extract, Transform, Load - ETL
다른 곳에 존재하는 데이터를 가져다가 데이터 웨어하우스에 로드하는 작업
Extract : 외부 데이터 소스에서 데이터 추출
Transform : 데이터의 포맷을 원하는 형태로 변환
Load : 변환된 데이터를 최종적으로 데이터 웨어하우스로 적재
데이터 파이프라인이라고도 칭함
Airflow framework를 가장 많이 사용
ETL 관련 Saas도 지원 - 데이터 엔지니어가 없거나 일이 많거나 할 때 사용.
데이터 분석 수행
- 데이터 분석가 (Data Analyst)
시각화 대시보드
- 보통 중요한 지표를 시간의 흐름과 함께 보여주는 것이 일반적
지표의 경우 3A(Accessible, ACtionable, Auditable)이 중요
구글 - looker
세일즈포스 - tableau
마이크로소프트 파워 bi - power bi
apache superset
데이터 엔지니어의 역할
기본적으로는 소프트웨어 엔지니어
파이썬 - 자바,scala의 jvm 계열
데이터 웨어하우스 구축
데이터 웨어하우스를 만들고 이를 관리, 클라우드로 가는 것이 추세
redshift, bigquery, snowflake
관련해서 중요한 작업중의 하나는 ETL 코드를 작성하고 주기적으로 실행
ETL 스케쥴러 혹은 프레임웍이 필요
알아야할 기술
Junior
SQL, Hive, Prdsto, SparkSQL
프로그래밍 언어 : 파이썬,스칼라,자바
데이터 웨어하우스 : redshift/snowflake/bigquery
airflow
spark/yarn
알면 좋은 기술
docker/k8s
클라우드 컴퓨팅
머신 러닝 일반
a/b test, 통계
데이터 분석가의 딜레마
보통 많은 수의 긴급한 데이터 관련 질문들에 시달림
좋은 데이터 인프라 없이는 일을 잘 하기 힘듬
많은 경우 현업팀에 소속되기도함
데이터 디스커버리
별도의 직군은 아니지만 데이터 팀이 커지면 꼭 필요한 서비스
데이터가 커지면 테이블과 대시보드의 수도 증가하기 때문에 대시보드 및 테이블에 혼란이 생김
주기적인 테이블과 대시보드 클린업이 필수!
리프트 - 아문센
링크드인 - 데이터 허브
셀렉트 스타
데이터 웨어하우스
데이터 웨어하우스 옵션별 장단점
클라우드가 대세
데이터가 커져도 문제가 없는 확장가능성과 적정한 비용이 중요한 포인트
redshift, bigquery, snowflake
redshift는 고정비용, 서버리스를 사용하면 가변비용으로 사용 가능
bigquery 나 snowflake 는 가변비용
가변비용 웨어하우스가 좀 더 scalable한 것 같다.
데이터 레이크
데이터웨어하우스는 좀 더 비싼 옵션, 기본적으로 sql을 이용한 rdbms
로그파일같은 비구조화된 데이터는 처리하기 어려움.
구조화 데이터 + 비구조화 데이터(로그파일)
보존 기한이 없는 모든 데이터를 원래 형태대로 보존하는 스토리지에 가까움
보통은 데이터웨어하우스보다 몇 배는 더 크고 더 경제적인 스토리지
보통 클라우드 스토리지 ex) aws 에서는 s3
데이터레이크는 대부분 클라우드 스토리지이다.
데이터 레이크가 있는 환경에서 ETL과 ELT
데이터 레이크와 데이터 웨어하우스 바깥에서 안으로 데이터를 가져오는 것 : ETL
데이터 레이크와 데이터 웨어하우스 안에 있는 데이터를 처리하는 것 : ELT
정말 잘 정제된 데이터 같은 경우는 레이크를 거칠 필요 없이 데이터 웨어하우스에 바로 적재
ETL은 airflow
ELT는 airflow로 스케쥴링은 하지만 DBT를 이용
대용량의 로그 파일들을 데이터 레이크에 저장 (ETL)
데이터 레이크에서 데이터 웨어하우스에 저장 (ELT)
ETL은 회사가 다루는 데이터 크기가 커지면 많아짐
ETL이 fail 했을 때, 빨리 고쳐서 다시 실행하는 것이 중요
데이터 요약을 위한 ETL도 필요해짐 -> ELT라고 부름
앞에서 설명한 ETL은 다양한 데이터 소스에 있는 데이터를 읽어오는 일을 수행
하지만 이를 모두 이해해서 조인해서 사용하는 것은 데이터가 다양해지고 커지면서 거의 불가능해짐
주기적으로 요약 데이터를 만들어 사용하는 것이 더 효율적 -> dbt
다양한 데이터 소스의 예
- 프로덕션 데이터베이스의 데이터 보통 mysql, postgres
- 이메일 마케팅, 크레딧 카드, 서포트 티켓, 서포트 콜, 세일즈 데이터, 사용자 이벤트 로그
Airflow (ETL 스케쥴러) 소개
-
ETL 관리 및 운영 프레임웍의 필요성
다수의 ETL이 존재할 경우 이를 스케쥴하고 이들간의 의존관계 dependency를 정의해주는 기능 필요
특정 ETL이 실패할 경우 이에 관한 에러 메세지를 받고 재실행해주는 기능도 중요해짐 (backfill) -
가장 많이 사용되는 프레임웍은 airflow
airflow는 3개의 클라우드 회사에서 모두 지원
3가지 컴포넌트로 구성됨 : 스케쥴러,웹서버,워커
ELT
ETL : 데이터를 데이터 웨어하우스 외부에서 내부로 가져오는 프로세스
- 보통의 데이터 엔지니어가 이를 수행함
ELT : 데이터 웨어하우스 내부 데이터를 조작해서 새로운 데이터를 만드는 프로세스
- 보통 데이터 분석가
데이터 레이크에서 데이터 웨어하우스로 ELT를 진행할 때, spark등을 사용함.
대표적 빅데이터 프로세싱 시스템
- 1세대 -> 하둡 기반의 mapreduce, hive/presto
- 2세대 -> spark(sql, dataframe, streaming, ml, graph)
빅데이터 처리 framework
-
분산 환경 기반
분산 파일 시스템과 분산 컴퓨팅 시스템이 필요 -
Fault Tolerance
소수의 서버가 고장나도 동작해야함 -
확장이 용이해야함
scale out이 되어야함
용량을 증대하기 위해서 서버 추가
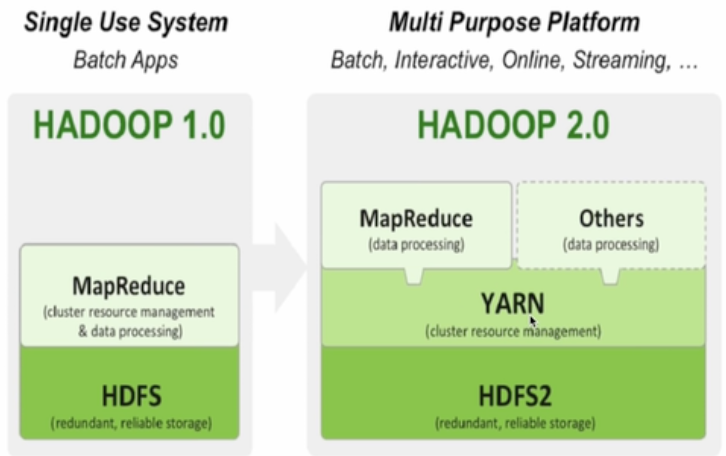
hadoop 분산 파일 시스템
mapreduce, spark - 분산 컴퓨팅 시스템
클라우드 스토리지, s3 가 spark의 입출력이 보관되는 곳
데이터 웨어하우스 옵션들
AWS Redshift
snowflake
bigquery
hive
presto
Iceberg + spark
Iceberg를 제외하고 sql 기반의 빅데이터 기반
AWS REDSHIFT
postgresql과 호환되는 sql로 처리 가능
python udf로 기능 확장 가능
2 펩타바이트까지 저장 가능
csv, json, avro, parguet과 같은 데이터 포멧 지원
snowflake
data sharing/ marketplace 데이터 판매를 가능하게 해줌
빅쿼리
bigquery sql로 nested fields, repeated fields 지원
HIVE
HIVE는 yarn 위의 apache tex를 실행 엔진으로 동작
예전엔 mapreduce 위에서 동작 -> 처리하는 양에 집중 (디스크 중심)
presto는 hive보다 처리 속도가 빠름 (메모리 중심)
Apache iceberg
데이터 웨어하우스 기술이 아님
실시간 클라우드 위에서 동작하고 대용량 scd데이터를 다룰 수 있는 테이블 포맷
spark
판다스처럼 대용량 데이터 프레임 처리해보자
kinessis, kafka 처럼 메세징 큐에도 적용 가능
