Airflow Backfill
restcountries.com
airflow cfg
-
DAGs 폴더는 어디에 지정되는가?
기본적으로 airflow가 설치된 디렉토리 밑의 dags 폴더가 되며 dags_folder 키에 저장됨 -
Dags 폴더에 새로운 Dag를 만들면 언제 실제로 Airflow 시스템에서 이를 알게 되나?
이 스캔 주기를 결정해주는 키의 이름이 무엇인가/
dag_dir_list_interval (기본값은 300 = 5분) -
이 파일에서 Airflow를 API 형태로 외부에서 조작하고 싶다면 어느 섹션을 변경해야하는가?
api 섹션의 auth_backend를 airflow.api.auth.basic_auth로 변경
airflow.cfg를 통해서 외부 섹션에서 api를 통해서 받아올 수 있다.
오직 web ui 와 cli만 있는 것이 아님. -
Variable에서 변수의 값이 encrypted가 되려면 변수의 이름에 어떤 단어들이 들어가야하는데 이 단어들은 무엇일까?
password, secret, passwd, authorization, api_key, access_token 단어가 들어가면 encrypted가 된다. -
환경 설정 파일이 수정되어 있다면 이를 실제로 반영하기 위해서 해야하는 일은?
ec2로 설치했다면 웹서버 및 스케쥴러 다시 실행
sudo systemctl restart airflow-webserver
sudo systemctl restart airflow-scheduler
Docker로 설치했다면 airflow cfg 바꾼 후에 도커 엔진에서 중단 후 다시 시작
대부분의 사람들은 airflow.init을 설정
-> 이 것은 메타데이터만 초기화 해주는 것임. 실제적으로 백엔드가 바뀌었을 때, 메타데이터 디비가 바뀌었을 때
- Metadaga DB의 내용을 암호화하는데 사용되는 키는 무엇인가?
fernet_key
Airflow timezone
● airflow.cfg에는 두 종류의 타임존 관련 키가 존재
a. default_timezone
b. default_ui_timezone
- 기본은 utc,
다른 시간으로 바꾸고 싶다면 web에서 수정 혹은 cfg에서 수정
● start_date, end_date, schedule
a. default_timezone에 지정된 타임존을 따름
● execution_date와 로그 시간
a. 항상 UTC를 따름
b. 즉 execution_date를 사용할 때는 타임존을 고려해서 변환후 사용필요
로그가 언제 기록됬는지 시간이 표시가 되어 있다. Log 시간과 execution_date는 두 timezone을 다 배제하고 UTC를 따라감. 그래서 강사님은 무조건 UTC를 사용
현재로 가장 좋은 방법은 UTC를 일관되게 사용하는 것으로 보임
dags 폴더에서 코딩시 작성한다면 주의할 점
● Airflow는 dags 폴더를 주기적으로 스캔함 [core]
dags_folder = /var/lib/airflow/dags
#How often (in seconds) to scan the DAGs directory for new files. Default to 5 minutes. dag_dir_list_interval = 300
● 이때 DAG모듈이 들어있는 모든 파일들의 메인함수가 실행이됨
● 이 경우 본의 아니게 개발중인 테스트코드도 실행될 수 있음
from airflow import DAG
...
cur.execute(“DELETE FROM ....”)
airflow는 어떤게 Dag파일이고 아니고를 잘 모르기 때문에 모든 py파일들이 실행되어짐. 5분마다 Airflow가 dags_folder가 가르키는 키를 Dag_dir_list_interval 주기로 돌아가기 때문에, delete from 같은 코드가 있다면 귀신이 곡할 노릇임.... 조심
primary key의 uniqueness는 데이터 웨어하우스는 제공 x
- 우리가 할 일
DAG를 작성할 때 roll back할 때, DAG에 raise 코드를 작성하자.
cf의 fernet key 파라미터는 메타데이터 디비 암호화 비밀번호를 설정해주는 코드다.
open weathermap api 소개
위도 경도를 기반으로 . 그지역의 기후 정보를 알려주는 서비스
무료 계정으로 api key를 받아서 이를 호출시 사용
Open Weathermap의 one call API를 사용해서 서울의 다음 8일간의
낮/최소/최대 온도를 읽어다가 각자 스키마 밑의 weather_forecast라는
테이블로 저장
○ https://openweathermap.org/api/one-call-api를 호출해서 테이블을 채움
○ weather_forecast라는 테이블이 대상이 됨
■ 여기서 유의할 점은 created_date은 레코드 생성시간으로 자동 채워지는 필드라는 점
CREATE TABLE jg31109.weather_forecast ( date date primary key,
temp float, -- 낮 온도
min_temp float,
max_temp float,
created_date timestamp default GETDATE() );
위의 테이블 형식으로 데이터를 입력할 예정임
현재 primary key 같은 경우는 date 이유는
- 서울만 제공할 예정이기 때문에
만약 서울만이 아니라면 나라 수도 혹은 지역이 primary key가 되지 않을까?
created date는 데이터가 입력된 날짜 인듯
-incremental update를 할 때 사용할 예정
default는 현재시간으로 세팅됨.
One-Call API는 결과를 JSON 형태로 리턴해줌
○ 이를 읽어들이려면 requests.get 결과의 text를 JSON으로 변환해 주어야함
○ 아니면 requests.get 결과 오브젝트가 제공해주는 .json()이란 함수 사용
■ f = requests.get(link)
■ f_js = f.json()
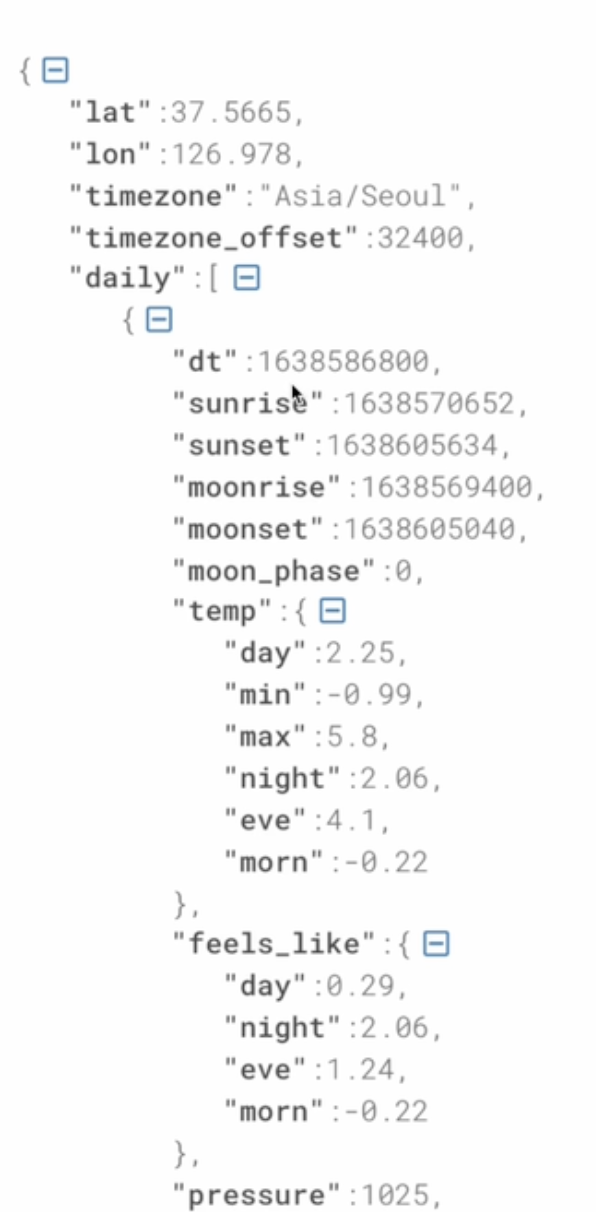
● 결과 JSON에서 daily라는 필드에 앞으로 8일간 날씨 정보가 들어감 있음
○ daily 필드는 리스트이며 각 레코드가 하나의 날짜에 해당
○ 날짜 정보는 “dt”라는 필드에 들어 있음. 이는 epoch이라고 해서 1970년 1월 1일 이후
밀리세컨드로 시간을 표시. 이는 아래와 같은 코드로 읽을 수 있는 날짜로 변경 가능
epoch 같은 경우 밀리세컨드라서 사람이 이해하기 힘듬
- 아래와 같은 형태로 작성하면 사람이 이해할 수 있는 string으로 바꿀 수 있다는 것이다.
■ datetime.fromtimestamp(d["dt"]).strftime('%Y-%m-%d')
-> 2021-10-09
● Airflow Connections를 통해 만들어진 Redshift connection ○ 기본 autocommit의 값은 False인 점을 유의!!
● 두 가지 방식의 Full Refresh 구현 방식
○ Full Refresh와 INSERT INTO를 사용
- 테이블을 날리고 새로 만들거나, 테이블을 남겨두고 레코드들을 다 날리거나
그리고 건바이건으로 insert
○ Full Refresh와 COPY를 사용 -> 나중에 사용해볼 예정
redshift의 벌크 없데이트 -> copy
이것을 이용하려면 s3에 binary파일 형태로 먼저 업로드 후 redshift로 copy
Primary uniqueness
테이블에서 하나의 레코드를 유일하게 지칭할 수 있는 필드(들)
○ 하나의 필드가 일반적이지만 다수의 필드를 사용할 수도 있음
○ 이를 CREATE TABLE 사용시 지정
● 관계형 데이터베이스 시스템이 Primary key의 값이 중복 존재하는 것을 막아줌
● 예 1) Users 테이블에서 email 필드
● 예 2) Products 테이블에서 product_id 필드
빅데이터 기반 데이터 웨어하우스들은 Primary Key를
지켜주지 않음
● Primary key를 기준으로 유일성 보장을 해주지 않음 ○ 이를 보장하는 것은 데이터 인력의 책임
● Primary key 유일성을 보장해주지 않는 이유는?
○ 보장하는데 메모리와 시간이 더 들기 때문에 대용량 데이터의 적재가 걸림돌이 됨
레코드가 추가될 때마다 b+tree 처럼 계속 확인해야함. 메모리의 리소스를 더 잡아 먹게 됨.
primary key로 지정한 컬럼이 중복되도 성공함 -> 데이터 웨어하우스에서는
weather forecast 같은 경우는 중복데이터가 생길 수 밖에 없음. created date field로 더 가까운 날씨가 정확하기에 더 좋은 데이터를 가지고 오자. create date 로 멱등성이 유지된 incremental update를 가지고와보자.
이런 방식으로 중복 제거 -> primary key
여기서 필요한 sql이 rownum
date 별로 레코드를 모으고 그 안에서 created_date의 역순으로 sorting한 후 1 번부터 seq를 붙임
ROW_NUMBER() OVER(PARTITION BY DATE ORDER BY CREATED_DATE DESC) seq
Primary Key 유지 방법 (3)
● 임시 테이블(스테이징 테이블)을 만들고 거기로 현재 모든 레코드를 복사
● 임시 테이블에 새로 데이터소스에서 읽어들인 레코드들을 복사
○ 이때중복존재가능
● 중복을 걸러주는 SQL 작성:
○ 최신 레코드를 우선 순위로 선택
○ ROW_NUMBER를 이용해서 primary key로 partition을 잡고 적당한 다른 필드(보통
타임스탬프 필드)로 ordering(역순 DESC)을 수행해 primary key별로 하나의 레코드를 잡아냄
● 위의 SQL을 바탕으로 최종 원본 테이블로 복사
○ 이때 원본 테이블에서 레코드들을 삭제
○ 임시 temp 테이블을 원본 테이블로 복사
이를 Upsert라고도 함
Primary Key를 기준으로 존재하는 레코드라면 새 정보로 수정
● 존재하지 않는 레코드라면 새 레코드로 적재
● 보통 데이터 웨어하우스마다 UPSERT를 효율적으로 해주는 문법을 지원해줌
a. 뒤에서 MySQL to Redshift DAG를 구현할 때 살펴볼 예정
Backfill과 Airflow
Incremental Update가 실패하면
하루에 한번 동작하고 Incremental하게 업데이트하는 파이프라인이라면?
실패하는 부분을 재실행하는 것이 얼마나 중요한가?
이제부터 할 이야기는 Incremental Update시에만 의미가 있음
● 다시 한번 가능하면 Full Refresh를 사용하는 것이 좋음 ○ 문제가 생겨도 다시 실행하면 됨
● Incremental Update는 효율성이 더 좋을 수 있지만 운영/유지보수의 난이도가
올라감
○ 실수등으로 데이터가 빠지는 일이 생길 수 있음
○ 과거 데이터를 다시 다 읽어와야하는 경우 다시 모두 재실행을 해주어야함
Backfill
실패한 데이터 파이프라인을 재실행 혹은 읽어온 데이터들의 문제로 다시 다 읽어와야하는 경우를 의미
backfill 해결은 incremental update에서 복잡해짐
full refresh에서는 간단. 그냥 다시 실행하면 됨
즉 실패한 데이터 파이프라인의 재실행이 얼마나 용이한 구조인가?
이게 잘 디자인된 것이 바로 airflow
어떻게 ETL을 구현해놓으면 이런 일이 편해질까?
●시스템적으로 이걸 쉽게 해주는 방법을 구현한다
○ 날짜별로 backfill 결과를 기록하고 성공 여부 기록: 나중에 결과를 쉽게 확인
○ 이 날짜를 시스템에서 ETL의 인자로 제공
○ 데이터 엔지니어는 읽어와야하는 데이터의 날짜를 계산하지 않고 시스템이 지정해준 날짜를
사용
Airflow의 접근방식
○ ETL 별로 실행날짜와 결과를 메타데이터 데이터베이스에 기록
○ 모든 DAG 실행에는 “execution_date”이 지정되어 있음
■ execution_date으로 채워야하는 날짜와 시간이 넘어옴
○ 이를 바탕으로 데이터를
○ 잇점: backfill이 쉬워짐
dag가 돌면 그 전 시간을 기록해둠.
-> 이것을 이용하면 될 것 같음.
내가 읽어와야할 데이터의 시간을 airflow가 알고 있기 때문에 airflow가 execution date라는 시스템 변수를 가지고 와서 backfill을 하면 된다.
!! 중요한 것은 airflow는 파이프라인 성공 실패 여부, 실패한 dag의 execution date를 알고 있다. airflow는 incremental update로 전부 알고 있음
dag가 실패해서 grid에서 bad일 때 다시 재실행 해주면 된다..
중요한 점
start_date + dag가 실행주기다
execution date는 dag가 읽어와야하는 데이터의 날짜와 시간
catchup은 실행한된 것들을 다 가지고오기.. default는 true
