from airflow.operators.python import PythonOperator
load_nps = PythonOperator(
dag=dag, #parent dag
task_id='task_id', #python operator로 실행할 task id
python_callable=python_func, #task가 실행될 때 실행되어야할 python 함수
params={ # 함수로 넘길 인자
'table': 'delighted_nps',
'schema': 'raw_data' },
)
def python_func(**cxt):
table = cxt["params"]["table"] schema = cxt["params"]["schema"] #받을 때 dictionary indexing
ex_date = cxt["execution_date"]
# do what you need to do
...
dag = DAG(
dag_id = "helloWorld", start_date = datetime(2021,8,26), catchup=False,
tags=['example'],
schedule = '0 2 * * *', default_args=default_args
)여기서 스케쥴을 보면 0 2라 적으면 하루에 한번 2시 0분에 적용
task에 순서를 정해놓지 않으면, 독립적으로 태스크들이 실행되어버림
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
dag = DAG(
dag_id = 'HelloWorld',
start_date = datetime(2022,5,5),
catchup=False,
tags=['example'],
schedule = '0 2 * * *')
def print_hello():
print("hello!")
return "hello!"
def print_goodbye():
print("goodbye!")
return "goodbye!"
print_hello = PythonOperator(
task_id = 'print_hello',
#python_callable param points to the function you want to run
python_callable = print_hello,
#dag param points to the DAG that this task is a part of
dag = dag)
print_goodbye = PythonOperator(
task_id = 'print_goodbye',
python_callable = print_goodbye,
dag = dag)
#Assign the order of the tasks in our DAG
print_hello >> print_goodbyedecorator 이용
from airflow import DAG
from airflow.decorators import task
from datetime import datetime
@task
def print_hello():
print("hello!")
return "hello!"
@task
def print_goodbye():
print("goodbye!")
return "goodbye!"
with DAG(
dag_id = 'HelloWorld_v2',
start_date = datetime(2022,5,5),
catchup=False,
tags=['example'],
schedule = '0 2 * * *'
) as dag:
# Assign the tasks to the DAG in order
print_hello() >> print_goodbye()데코레이터를 이용하면 오퍼레이터를 따로 정의하고, 따로 오퍼레이터의 엔트리 함수를 사용했는데 필요 없어짐. 함수 자체가 태스크로 일치화 되어버림. 더 직관적으로 변경
중요한 DAG 파라미터
max_active_runs: # of DAGs instance
● max_active_tasks: # of tasks that can run in parallel
- 동시에 실행이 될 수 있는 데그의 수
만약 내가 backfill을 한다. daily이고 오류로 인해 1년전 부터 가지고와야한다? -> 그럼 365개를 하나씩 실행하면 오래 걸림. max 인자가 30이면 12번이면 끝남.
아무리 큰 값을 해도 -> 워커 노드의 cpu 개수에 한계됨. upper bound가 있음
● catchup: whether to backfill past runs
dag 의 start date이 과거여서 밀린 날짜를 catch up 할 것인지 말 것인지. full refresh라면 의미 없음. default는 true
● DAG parameters vs. Task parameters의 차이점 이해가 중요
● 위의 파라미터들은 모두 DAG 파라미터로 DAG 객체를 만들 때 지정해주어야함
실제 ETL을 dag에 작성해보자
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import requests
import logging
import psycopg2
def get_Redshift_connection():
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
user = "keeyong" # 본인 ID 사용
password = "..." # 본인 Password 사용
port = 5439
dbname = "dev"
conn = psycopg2.connect(f"dbname={dbname} user={user} host={host} password={password} port={port}")
conn.set_session(autocommit=True)
return conn.cursor()
def extract(url):
logging.info("Extract started")
f = requests.get(url)
logging.info("Extract done")
return (f.text)
def transform(text):
logging.info("Transform started")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(records):
logging.info("load started")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
schema = "keeyong"
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
logging.info("load done")
def etl():
link = "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
data = extract(link)
lines = transform(data)
load(lines)
dag_second_assignment = DAG(
dag_id = 'name_gender',
catchup = False,
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *') # 적당히 조절
task = PythonOperator(
task_id = 'perform_etl',
python_callable = etl,
dag = dag_second_assignment)이걸 조금 더 airflow하게 만들어 보자
1. 일단 보안으로 노출될 위험이 있는 aws 하드코딩들을 숨기기
2. 데코레이터 이용
params를 통해 변수 넘기기
python_callable에 params로 인자를 넘겨보자
execution_date 얻어내기 - 시스템 변수
참고 delete from vs truncate
- delete from -> 트랜잭션 적용
truncate -> x
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
def get_Redshift_connection():
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
redshift_user = "keeyong" # 본인 ID 사용
redshift_pass = "..." # 본인 Password 사용
port = 5439
dbname = "dev"
conn = psycopg2.connect(f"dbname={dbname} user={redshift_user} host={host} password={redshift_pass} port={port}")
conn.set_session(autocommit=True)
return conn.cursor()
def extract(url):
logging.info("Extract started")
f = requests.get(url)
logging.info("Extract done")
return (f.text)
def transform(text):
logging.info("Transform started")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(records):
logging.info("load started")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
schema = "keeyong"
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
logging.info("load done")
def etl(**context):
link = context["params"]["url"]
# task 자체에 대한 정보 (일부는 DAG의 정보가 되기도 함)를 읽고 싶다면 context['task_instance'] 혹은 context['ti']를 통해 가능
# https://airflow.readthedocs.io/en/latest/_api/airflow/models/taskinstance/index.html#airflow.models.TaskInstance
task_instance = context['task_instance']
execution_date = context['execution_date']
logging.info(execution_date)
data = extract(link)
lines = transform(data)
load(lines)
dag = DAG(
dag_id = 'name_gender_v2',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
catchup = False,
max_active_runs = 1,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
task = PythonOperator(
task_id = 'perform_etl',
python_callable = etl,
params = {
'url': "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
},
dag = dag)connections and variables
get redshift connection 이라는 함수에서 중요한 정보가 노출되어 있고
정보가 바뀐다면 들어가서 코드를 바꿔야하는 번거러움이 있다.
이것을 해결해줄 수 있는 것이 connections이다.
csv 파일의 위치가 바뀐다면 코드를 바꿔주어야 하는데, 이것을 airflow 세팅으로 바꾸어 줄 수 있다. 이것이 variable이다.
Xcom을 이용해서 task 를 나누어보자.
여기서 고민되는건 각각의 ouput을 어떻게 넘길 것이냐.
한 오퍼레이터의 출력 값을 다음 오퍼레이터의 입력에 연결되게 설정해주는 것이 Xcom이다.
XCOM
태스크(Operator)들간에 데이터를 주고 받기 위한 방식
● 보통 한 Operator의 리턴값을 다른 Operator에서 읽어가는 형태가 됨
- 태스크의 id를 통해 하는 듯
● 이 값들은 Airflow 메타 데이터 DB에 저장이 되기에 큰 데이터를 주고받는데는 사용불가
- id 와 함께 저장 // 그러므로 데이터가 크면 저장 x
데이터가 크다면 메타데이터 디비가 아닌 s3와 같은 값 싼 저장소
○ 보통큰데이터는S3등에로드하고그위치를넘기는것이 일반적
태스크 하나로 구성이 된 경우
data = extract(link)
lines = transform(data)
load(lines)
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
# airflow variable은 키 벨류 스토리를 액세스할 때 사용되는 모듈
# get, set을 사용 get은 키를 주고 벨류 읽기, set은 키 벨류 세팅
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
def get_Redshift_connection():
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
redshift_user = "keeyong" # 본인 ID 사용
redshift_pass = "..." # 본인 Password 사용
port = 5439
dbname = "dev"
conn = psycopg2.connect(f"dbname={dbname} user={redshift_user} host={host} password={redshift_pass} port={port}")
conn.set_session(autocommit=True)
return conn.cursor()
def extract(**context):
link = context["params"]["url"]
task_instance = context['task_instance']
execution_date = context['execution_date']
logging.info(execution_date)
f = requests.get(link)
return (f.text)
def transform(**context):
logging.info("Transform started")
text = context["task_instance"].xcom_pull(key="return_value", task_ids="extract")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(**context):
logging.info("load started")
schema = context["params"]["schema"]
table = context["params"]["table"]
lines = context["task_instance"].xcom_pull(key="return_value", task_ids="transform")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
logging.info("load done")
dag = DAG(
dag_id = 'name_gender_v3',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
catchup = False,
max_active_runs = 1,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
extract = PythonOperator(
task_id = 'extract',
python_callable = extract,
params = {
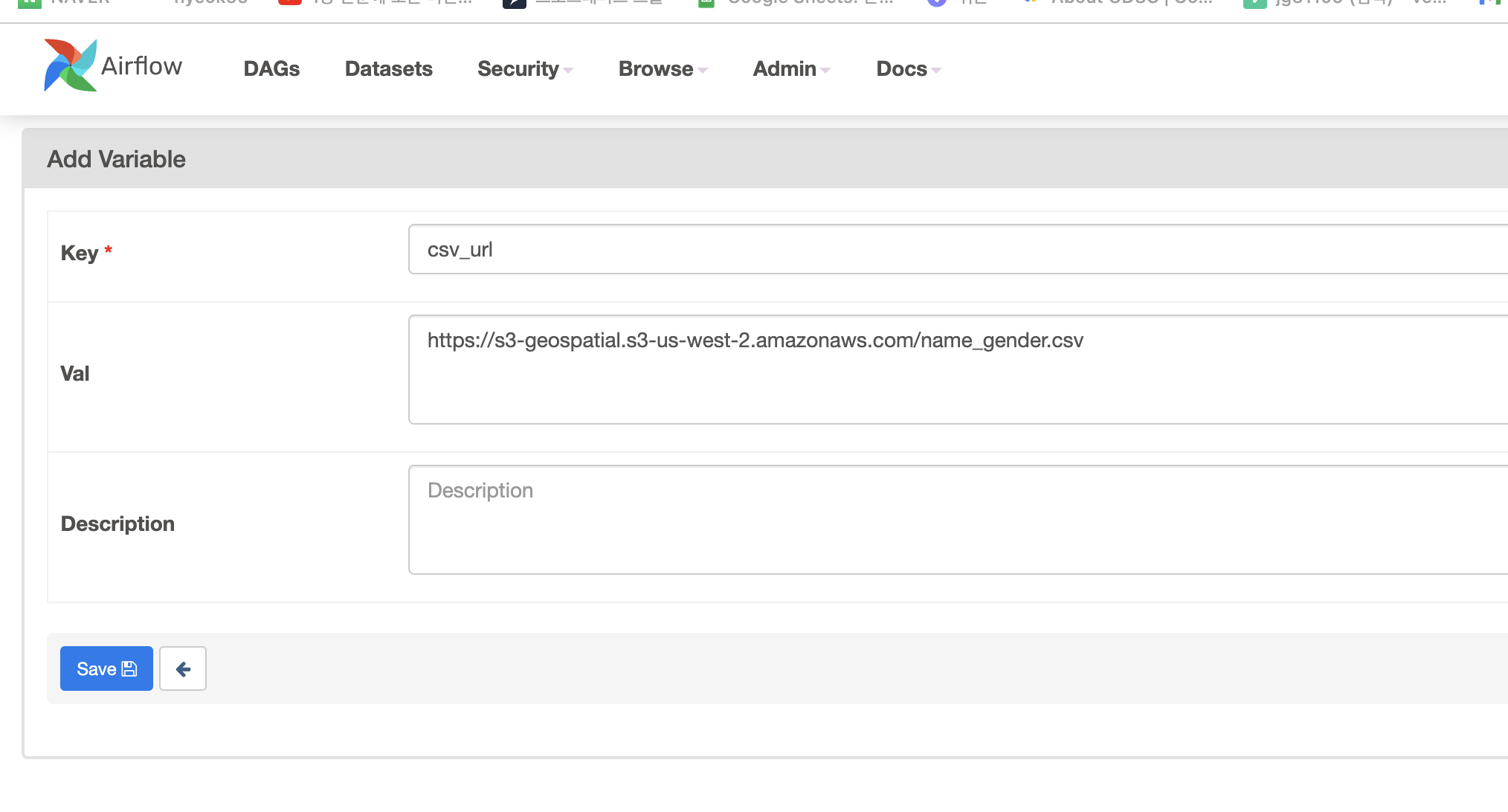
'url': Variable.get("csv_url")
},
dag = dag)
transform = PythonOperator(
task_id = 'transform',
python_callable = transform,
params = {
},
dag = dag)
load = PythonOperator(
task_id = 'load',
python_callable = load,
params = {
'schema': 'keeyong',
'table': 'name_gender'
},
dag = dag)
extract >> transform >> load보면 인자들 내의 params 값이 달라졌고 python operator가 한 개가 아닌 3개로 되어짐. 태스크가 즉 3개로 나누어지고 마지막 보면 순서가 나오게됨.
xcom_pull은 metadata db에서 가져오게 된다.
Connections
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from airflow.providers.postgres.hooks.postgres import PostgresHook
from datetime import datetime
from datetime import timedelta
# from plugins import slack
import requests
import logging
import psycopg2
def get_Redshift_connection(autocommit=True):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()
def extract(**context):
link = context["params"]["url"]
task_instance = context['task_instance']
execution_date = context['execution_date']
logging.info(execution_date)
f = requests.get(link)
return (f.text)
def transform(**context):
logging.info("Transform started")
text = context["task_instance"].xcom_pull(key="return_value", task_ids="extract")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(**context):
logging.info("load started")
schema = context["params"]["schema"]
table = context["params"]["table"]
records = context["task_instance"].xcom_pull(key="return_value", task_ids="transform")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
raise
logging.info("load done")
dag = DAG(
dag_id = 'name_gender_v4',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
# 'on_failure_callback': slack.on_failure_callback,
}
)
extract = PythonOperator(
task_id = 'extract',
python_callable = extract,
params = {
'url': Variable.get("csv_url")
},
dag = dag)
transform = PythonOperator(
task_id = 'transform',
python_callable = transform,
params = {
},
dag = dag)
load = PythonOperator(
task_id = 'load',
python_callable = load,
params = {
'schema': 'keeyong', ## 자신의 스키마로 변경
'table': 'name_gender'
},
dag = dag)
extract >> transform >> loadpostgreshook 모듈을 새로 불러옴
커넥션에 Redshift 정보를 저장한 후에 코드에서는 없애고 connection을 이용해서 연결
마지막 decorator
from airflow import DAG
from airflow.models import Variable
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.decorators import task
from datetime import datetime
from datetime import timedelta
import requests
import logging
def get_Redshift_connection(autocommit=True):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()
@task
def extract(url):
logging.info(datetime.utcnow())
f = requests.get(url)
return f.text
@task
def transform(text):
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
@task
def load(schema, table, records):
logging.info("load started")
cur = get_Redshift_connection()
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
logging.info("load done")
with DAG(
dag_id='namegender_v5',
start_date=datetime(2022, 10, 6), # 날짜가 미래인 경우 실행이 안됨
schedule='0 2 * * *', # 적당히 조절
max_active_runs=1,
catchup=False,
default_args={
'retries': 1,
'retry_delay': timedelta(minutes=3),
# 'on_failure_callback': slack.on_failure_callback,
}
) as dag:
url = Variable.get("csv_url")
schema = 'keeyong' ## 자신의 스키마로 변경
table = 'name_gender'
lines = transform(extract(url))
load(schema, table, lines)함수 인자들이 바뀜
task decorator를 사용
xcom을 사용 -> 테스트들간에 데이터를 사용할 필요가 없다.
기본적으로 python operator 대신에 airflow.decorators.task를 사용
참고)
cp -r 복사할 경로 붙일 경로
r은 recursive 상세 폴더까지 다 가지고 와라
connection and variable
위 두개를 등록해주지 않는다면, 대그를 import하는 과정에서 오류가 난다. 그래서 설정해 주도록 하자. airflow는 5분마다 대그를 스캔 -> 정상적으로 등록하였다면 대그가 import 될 것이다.
postgresHook의 autocommit 파라미터
Default 는 false 자동으로 commit x
이 경우 begin은 아무런 영향이 없다. no - operation false일 때
redshift 커넥션 정보를 airflow 커네션스 오브젝트로 만들고 환경설정으로 바꾼다음에, 모듈의 인스턴스를 사용해서 redshift에 접근
Dag에서 task를 어느 정도로 분리하는 것이 좋을까?
task 123중 3에서 실패하면 처음이 아닌 3에서 다시시작 -> 장점
코드의 읽기 수행 능력이 증가됨!
task를 많이 만들면 전체 DAG이 실행되는데 오래 걸리고 스케쥴러에 부하가 감
task를 너무 적게 만들면 모듈화가 안되고 실패시 재실행을 시간이 오래 걸림
오래 걸리는 Dag가 실패시 재실행이 쉽게 다수의 task로 나누는 것이 좋음
적절히 나누자!
Airflow의 variable 관리 vs 코드관리
장점 : 코드 푸시의 필요성이 없음
단점 : 관리나 테스트가 안되어서 사고로 이어질 가능성이 있음.
중요한 sql이라면 테스트를 하고 variable로 하자
코드로 관리하게 된다면/ 기록과 수정 내역이 git에 남게됨
강사님은 중요한 sql은 variable에 저장되지 않는다.
yahoo finance를 이용해서 애플 주식을 full refresh로 가지고 와보자
참고)
CLI로 airflow를 실행시켜보자
docker ps로 컨테이너 아이디를 확인해 보자
airflow scheduler의 id를 복사해서
docker exec -it 아이디 로 실행
root user로 로그인
docker exec --user root -it 컨테이너 id sh
airflow variables list/get 이름
- 뭐가 있는지/ 실제 path를 얻을 수 있다.
(airflow)airflow dags list-import-errors
dag import 오류
redshift의 테이블을 업데이트
Incremental Update로 구현
임시 테이블 생성하면서 현재 테이블의 레코드를 복사 CTAS 사용
임시 테이블로 yf api로 읽어온 레코드를 적재
원본 테이블을 삭제하고 새로 생성
원본 테이블에 임시 테이블의 내용을 복사 select distinct를 사용하여 중복제거
트랜잭션 형태로 구성
후기
터미널 내 dag test로는 가능했다. 하지만 web ui에서는 작동하지 않았다. setup log에서 log를 확인할 수 있다는 것을 듣고 확인했더니 yfinance를 설치 했음에도 불구하고 작동하지 않은 것을 알 수 있었다. 그래서 docker compose yaml파일에서
_PIP_ADDITIONAL_REQUIREMENTS
_PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:- pymysql yfinance}
을 이렇게 수정했더니 작동 하였다.
참고) 디렉토리 권한은 소유자 그룹 사용자가 읽기쓰기실행 권한을 확인하는 것이다.
ls -tl로 확인할 수 있고
chmod로 수정할 수 있다.
