
큐(Queue)
- 자료(data element)를 보관할 수 있는 (선형) 구조
단, 넣을 때에는 한 쪽 끝에서 밀어 넣어야 하고 반대서 뽑아야한다.
선입선출의 구조를 가지고 있다.
큐의 추상적 자료구조 구현
배열, 양방향 연결리스트로 구현
연산의 정의
size() - 현재 큐에 들어 있는 데이터 원소의 수를 구함
isEmpty - 큐가 비어 있는지
enqueue - 데이터 추가
dequeue - 데이터 제거
배열로 구현한 큐의 연산 복잡도
dequeue 같은 경우는 큐의 길이에 비례하는 연산
나머지는 상수 시간복잡도
큐의 활용
- 자료를 생성하는 작업과 그 자료를 이용하는 작업이 비동기적(asynchronously)으로 일어나는 경우
비동기적 : 동시에 일어나지 않는
- 자료를 생성하는 작업이 여러 곳에서 일어나는 경우
- 자료를 이용하는 작업이 여러 곳에서 일어나는 경우
- 다대다 인 경우
Producer and Consumer 구조로 생각하면 됨.
- 자료를 처리하여 새로운 자료를 생성하고, 그 자료를 또 처리해야하는 작업의 경우
환형 큐
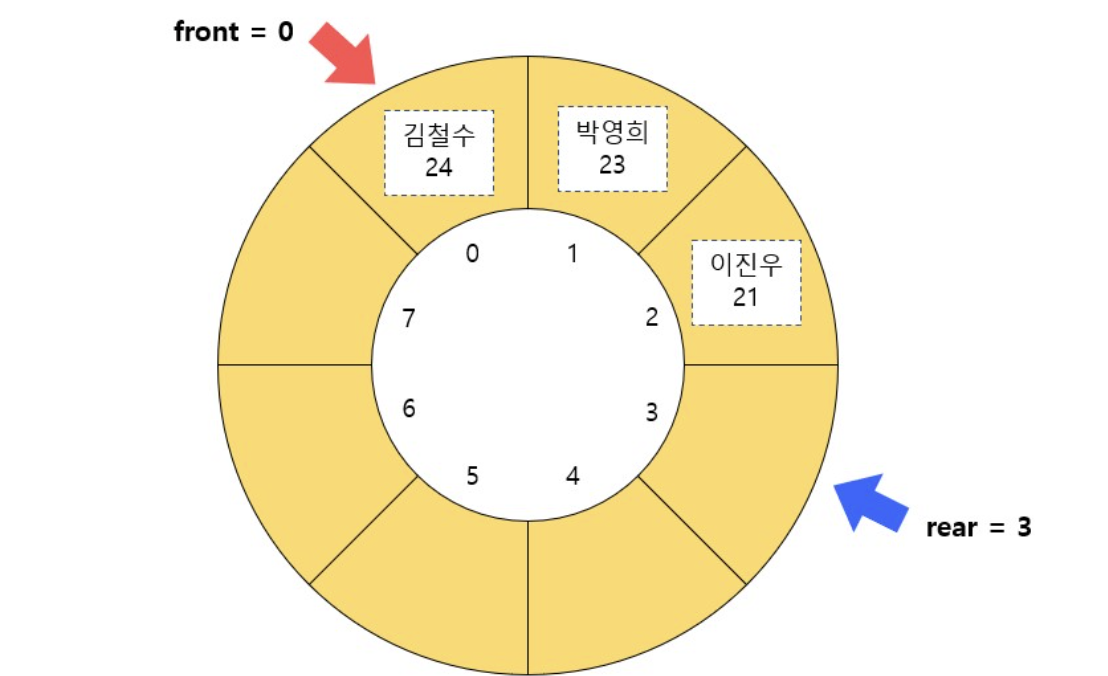
정해진 개수의 저장 공간을 빙 돌려가며 이용
rear - 데이터를 집어 넣는 곳
front - 데이터를 추출 하는 곳
데이터가 가득 차 있는지 확인해야하기에, 큐 길이를 기억해야함
isFull() - (큐가 가득 차면 더 이상 원소가 꽉 차 있는 지를 판단)
rear든 front 든 리스트의 끝에 도달하면 인덱스를 다시 0으로
우선순위 큐(Priority Queue)
큐가 FIFO 방식을 따르지 않고 원소들의 우선순위에 따라 큐에서 빠져나오는 방식
ex) 운영체제의 CPU 스케쥴러
서로 다른 두 가지 방식이 가능할 듯:
(1) Enqueue 할 때 우선 순위 유지 -> 이게 더 유리
(2) Dequeue 할 때 우선 순위 높은 것을 선택
서로 다른 두 가지 재료를 이용할 수 있음:
1. 선형 배열 이용
2. 양방향 연결 리스트 이용 -> 이게 더 유리
Reason) 우선 순위로 인해 중간에 value를 넣어야할 상황이 생김
양 방향 연결 리스트를 이용하여 빈 큐를 초기화
Trees 트리
2차원 자료 구조
정점(node)과 간선(edge)을 이용하여 데이터의 배치 형태를 추상화한 자료 구조
Root node - 최상단 노드
Leaf node - 최하위 노드
Iternal node - 내부 노드
가지를 쳤을 때, parent node와 child node
가지 내에서, 같은 level의 노드는 sibiling node
root node 의 level은 0, 1로 하는 곳도 있음(간선의 개수로 생각하면 0이 편함)
트리의 높이(height) = 최대 수준(level) + 1, depth 라고도 표현
즉 간선의 개수가 3이면 트리의 height는 4
부분트리(서브트리 - subtree)
자식 = 서브트리의 수
노드로부터 간선의 개수가 2개라면 해당 노드의 degree 즉 차수는 2이다.
leaf node는 degree가 0이 겠죠?
Binary Tree (이진 트리)
모든 노드의 차수가 2 이하인 트리
재귀적으로 정의 할 수 있음:
- 빈 트리 이거나, 루트 노드 + 왼쪽 서브트리 + 오른쪽 서브트리
-> 터미널 조건이 없기 때문에 빈 트리도 이진트리로 판단하는 조건을 추가해야함
연산의 정의
size() - 현재 트리에 포함되어 있는 노드의 수를 구함
depth() - 현재 트리의 깊이를 구함
순회 (traversal)
-
깊이 우선 순회 (depth first traversal)
-
중위 순회(in-order traversal) -> Left - me - right
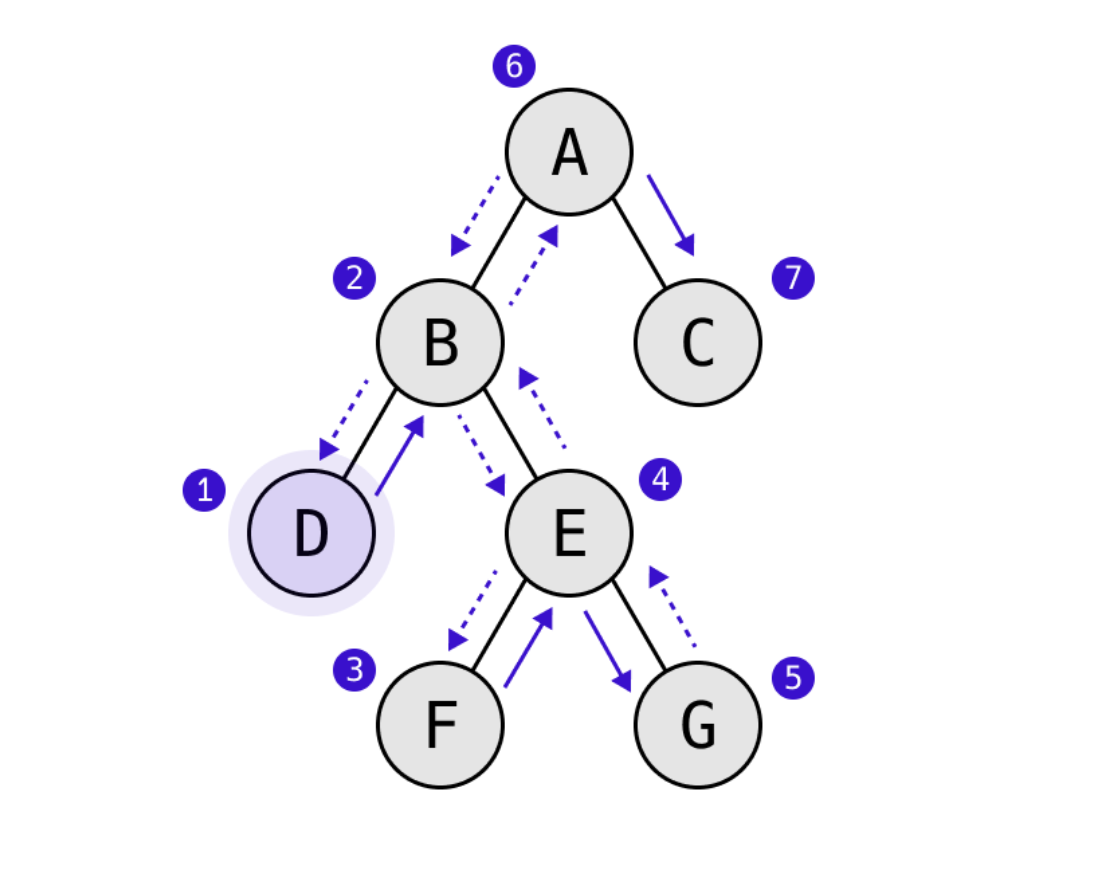
-
전위 순회(pre-order traversal) -> 자기 자신 먼저
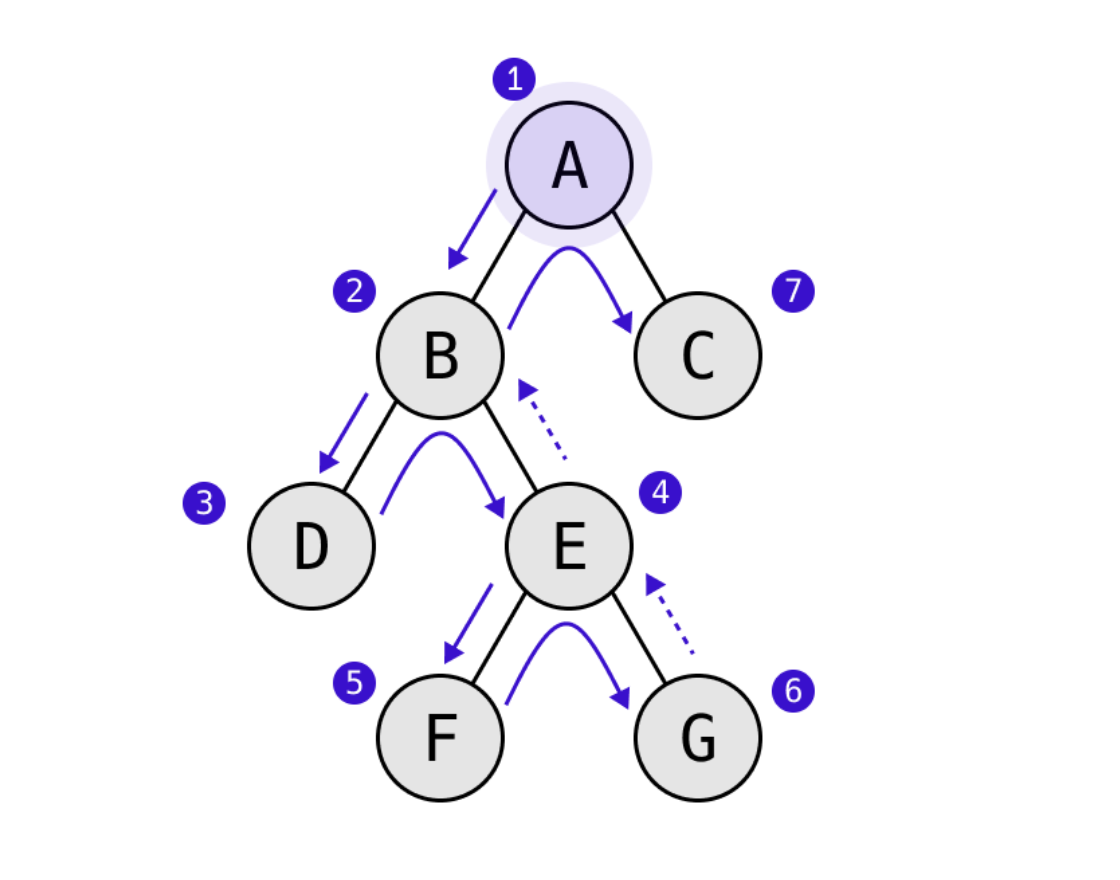
-
후위 순회(post-order traversal) -> 마지막에 자기 자신
-
-
넓이 우선 순회 (breadth first traversal)
-
level 이 낮은 노드를 우선으로 방문
-
같은 수준의 노드들 사이에는, 부모 노드의 방문 순서에 따라 방문
-
왼쪽 자식 노드를 오른쪽 자식보다 먼저 방문
재귀는 적합하지 않음
-
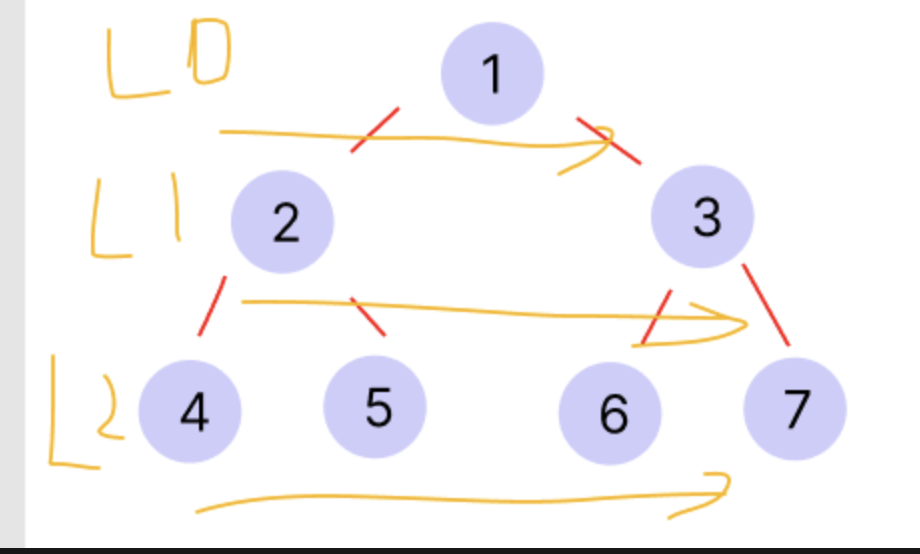
강의 예시로 따졌을 때의 순서는 A - B - C 순서로 가게 됨.(왼쪽부터)
한 노드를 방문했을 때, 나중에 방문할 노드들을 순서대로 기록해 두어야함.
-> Queue가 적합
순회 방식
- A 큐에 넣고 추출
- BC 큐에 넣기
- B 추출 후 자식 노드를 큐에 집어 넣기
- ....
- 큐가 비어 있다면 모든 노드를 순회하였다.(알고리즘 종료)
포화 이진 트리 (Full Binary Tree)
모든 레벨에서 노드들이 모두 채워져 있는 이진 트리
높이가 k라면 노드의 개수가 2^k -1인 이진 트리
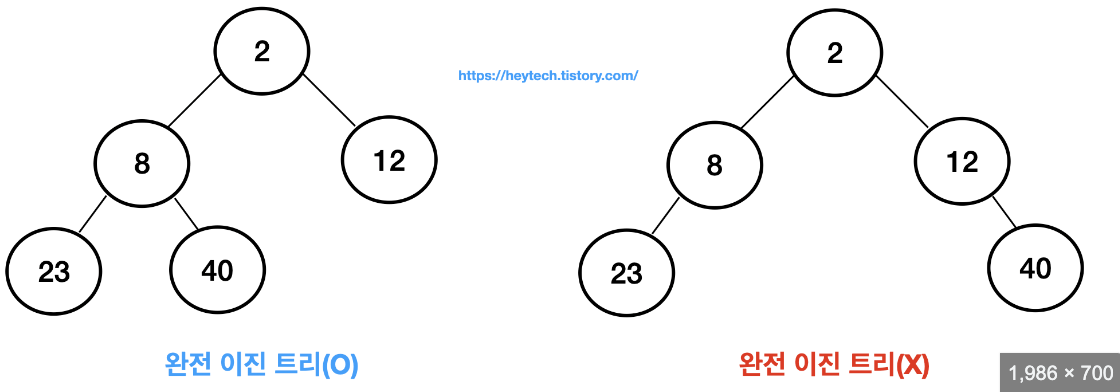
완전 이진 트리 (Complete Binary Tree)
높이가 k인 완전 이진 트리
레벨 k-2 까지는 모든 노드가 2 개의 자식을 가진 포화 이진 트리
레벨 k-1 에서는 왼쪽부터 노드가 순차적으로 채워져 있는 이진 트리
이진 탐색 트리(Binary Search Trees)
모든 노드에 대해서,
- 왼쪽 서브트리에 있는 데이터는 모두 현재 노드의 값보다 작고
- 오른쪽 서브트리에 있는 데이터는 모두 현재 노드의 값보다 큰
성질을 만족하는 이진트리 (중복된 데이터 값은 없다는 가정)
(장점) - 데이터 원소의 추가, 삭제가 용의
(단점) - 공간 소요가 큼
절반씩 탐색한다고, 항상 O(logn)의 탐색 복잡도는 아니다
이진 탐색 트리의 추상적 자료구조
데이터 표현 - 각 노드는 (key,value)의 쌍으로
키를 이용해서 데이터 레코드를 찾을 수 있는 보다 복잡한 구조를 이용할 수 있음
Heap 힙
이진 트리의 한 종류 (이진 힙- binary heap)
1. 루트 노드가 최댓값 또는 최솟값을 가짐
- 최대 힙(max heap), 최소 힙(min heap)
- 완전 이진 트리여야 함.
max heap 에서)
모든 노드에서 자기 자식 보다 큰지 확인해 봅시다.
재귀적으로도 정의 됨
(어느 노드를 루트로 하는 서브트리도 모두 최대 힙)
이진 탐색 트리와의 비교
1. 원소들은 완전히 크기 순으로 정렬되어 있는가?
이진 탐색 트리는 o, max min heap에서는 느슨하게
2. 특정 키 값을 가지는 원소를 빠르게 검색할 수 있는가?
heap 에서는 좋은 방법이 없다.
3. 부가 제약 조건
heap은 완전 이진 트리여야 한다는 조건이 있어야함
데이터 표현의 설계
배열을 이용한 이진 트리의 표현
노드 번호 m을 기준으로
왼쪽 자식의 번호 : m 2
오른쪽 자식의 번호 : 2 m + 1
부모 노드의 번호 : m//2
완전 이진 트리이므로 노드의 추가/삭제는 마지막 노드에서만
최대 힙에서 원소의 삭제
1. 루트 노드의 제거 - 이것이 원소들 중 최댓값
2. 트리 마지막 자리 노드를 임시로 루트 노드의 자리에 배치
3. 자식 노드들과의 값 비교와 아래로, 아래로 이동
- 자식은 둘 있을 수도 있는데, 어느쪽으로 이동
강사진님의 피드백 중 읽어보면 좋을 것
x in L 을 판단하는 데에는, 리스트 L 의 원소들의 순서에 대하여 아무 것도 가정하지 않는다면, 리스트 L 의 길이에 비례하는 시간을 소요합니다 (그보다 더 낫게 할 수 있는 방법이 없습니다). 이진탐색의 기본 아이디어는, 탐색 대상인 리스트 L 이 이미 원소의 대소 관계에 의하여 정렬되어 있다는 성질을 이용해서, 리스트 L 의 길이 (원소의 개수) 를 n 이라고 할 때 log(n) 에 비례하는 시간에 찾고자 하는 원소가 있는지, 있다면 어디에 있는지를 판단할 수 있다는 것입니다. if not x in L[l:u + 1] 과 같은 Python 표현이 한 줄에 쓰일 수 있어서 마치 순간적으로 주어진 리스트 내에 주어진 원소 (와 같은 값) 가 있는지를 판단할 수 있을 것처럼 잘못 생각될 수 있으나 그렇지 않습니다. (Python 내부적으로는 순환문을 이용해서 리스트 원소들과 x 의 값을 비교해서 판단합니다. 다시 강조하면, "그보다 낫게" 할 수 있는 방법이 존재하지 않습니다.)
