
Web
두 컴퓨터를 연결하는 네트워크(network)의 탄생
네트워크를 묶어 근거리 지역 네트워크(local area network, LAN) 탄생
(학교나 회사에서 랜으로 잘 구성되어 있음)
랜이 모여서 범지구적으로 연결된 네트워크 Inter Network 인터넷의 탄생
web이란
이 인터넷에서 정보를 교환할 수 있는 환경을 만들어볼까?
WWW world wide web -> web 탄생
인터넷은 여러 컴퓨터 끼리 네트워크를 연결한 것
web은 인터넷 상에서 정보를 교환하기 위한 시스템
web상에서는 정보를 어떻게 주고 받을까?
웹에서 정보 주고 받기
정보를 요청하는 컴퓨터를 클라이언트
정보를 제공하는 컴퓨터를 서버라고 한다.
- 클라이언트가 서버에게 정보를 요청
- 요청에 대해서 서버가 작업을 수행
- 수행한 작업의 결과를 클라이언트에게 응답
HTTP의 구조
Hyper Text Tansfer Protocol
웹 상에서 정보를 주고받기 위한 약속
클라이언트에서 서버로 정보를 요청하는 것은 HTTP 요청(Request)라고 한다.
요청된 정보에 대해 서버가 클라이언트에게 응답하는 것을 HTTP 응답(Response)라고 한다.
쉽게 택배로 예를 들어보자)
내가 쇼핑으로 구매한 상품을 배송받으려고 한다. 어떤 정보를 작성해야할까?
받는 사람 이름, 받는 사람 주소, 배송 방법 -> 이런 정보를 적을 것이다
HTTP도 마찬가지다. Host, Resource, Method
택배를 크게 2개로 나누면? 송장과 내용물
HTTP 직관적으로 이해하기
HTTP response
Head 보내는 사람, 받는 사람
Body 내용물
HTTP도 요청/응답에 대한 정보를 담는 Head와 내용물인 Body로 나뉜다.
GET / HTTP 1.1 -> get : 요청 / : 정보(루트)
Host: www.programmers.com 주소: 여기로 부터 정보를 줘
user-Agent : Mozilla/5.0 : 나를 명시해주는 키워드
HTTP response
200 OK 라는 signal
http의 body에는 우리가 요청한 정보가 담겨 있다.
아닌 경우 503 server error, 404 not found
Web scrapping
웹 페이지 vs 웹 사이트
웹 속에 있는 문서 하나는 웹 페이지
웹 페이지의 모음은 웹사이트
web page는 어떻게 만들까?
웹 페이지는 엄청 복잡한 줄글로 되어있다.
http response는 html의 body 이다.
웹 브라우저는 html 요청을 보내고, http 응답에 담긴 html 문서를 우리가 보기 쉬운 형태로 화면을 그려주는 역할을 담당
웹 페이지는 HTML 형식으로 되어있고, 웹브라우저는 우리가 HTTP 요청을 보내고, 응답 받은 HTML 코드를 렌더링 해준다.
지금부터 이 웹 브라우저의 역할을 코드로 대신 해보려고 한다.
HTML의 구조
HTML - HyperText Markup Language
!DOCTYPE html -> HTML 5 라는 것을 명시
HTML의 특징
가장 바깥에 html 태그로 감싸져있다. (여는 태그와 닫는 태그)
HTML 코드는 크게 head와 body로 이루어져 있다.
head는 문서에 대한 정보(제목,언어 등)을 작성한다.
body는 문서의 내용(글, 이미지, 동영상)등을 작성한다.
이렇게 HTML은 여러 태그로 감싼 요소의 집합으로 이루어져있다.
태그로 내용을 묶어 글의 형식을 지정
태그는 그에 맞는 속성(attribute)를 가지기도 한다.
참고) 웹 브라우저마다 지원하는 태그와 속성이 다르다...
우리가 원하는 내용이 HTML 문서의 어디에 있지? 어떤 태그로 묶여있지?를
관찰해야 한다.
get은 정보를 요청할때
Post는 정보를 갱신하려할 때, 서버에게 클라이언트가 정보를 제공해야할 때
body에 정보를 담아 전송
윤리적으로 웹스크래핑 하기
웹 크롤링과 웹 스크래핑
scrapping - 웹페이지들로부터 우리가 원하는 정보 추출
- 특정한 목적으로 특정 웹페이지에서 데이터를 추출하는 것 - 데이터 추출
ex) 날씨 데이터 가져오기, 주식 데이터 가져오기
crawling - crawler를 이용해서 웹 페이지의 정보를 인덱싱
- url을 타고다니며 반복적으로 데이터를 가져오는 과정 - 데이터 색인
ex) 검색 엔진의 web crawler
올바르게 HTTP 요청하기
- 웹 스크래핑/ 크롤링을 통해 어떤 목적을 달성하고자 하는가?
- 나의 웹 스크래핑/크롤링이 서버에 영향을 미치지 않는가?
절대 상업적인 문제로 이용하면 안된다...
무턱대고 모든 사이트에 대한 모든 정보를 취득하는 것이 정당할까?
-> REP(Robot Exclusion Protocol)의 탄생
웹 크롤러들은 이 규칙을 지키면서 크롤링을 진행
-> robot.txt
Disallow
User-agent : * #모든 user-agent에 대해서 접근을 거부
Disallow: /이 키워드는 모든 user-agent에 대해서 접근을 거부
user-agent는 나를 대표하는 프로그램
disallow: / -> /(root)부터 * (모든 것)을 거부
User-agent : * #모든 user-agent에 대해서 접근 허용
Allow: /Allow
이 키워드는 모든 user-agent에 대해서 접근 허용
Allow: / -> /(root)부터 * (모든 것)을 허용
특정 user-agent
User-agent : MussgBot
Disallow: /이 키워드는 MussgBot 특정 user-agent에 대해서 접근을 불허

모든 유저에 대해서 모든 것을 금지할 꺼야. 하지만 슬래쉬로 끝나는 웹페이지를 허용할 꺼야.(e.g)naver.com/만 허용할꺼야)
웹 브라우저가 HTML을 다루는 방식
DOM(Document Object Model)
브라우저는 어떻게 이 문서를 오른쪽과 같은 예쁜 페이지로 만들 수 있을까?
html -> browser -> page
브라우저의 렌더링 엔진은 웹 문서를 로드한 후, parsing을 진행
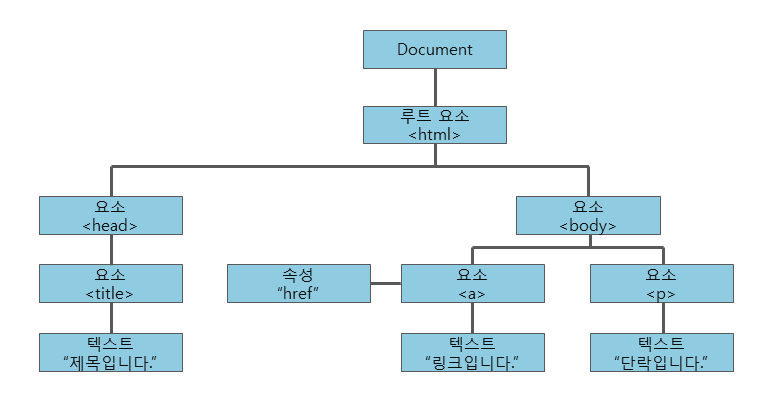
- 위와 같이 트리를 제작(parsing)
head 와 body에 어떤 것이 들어갔는지 알 수 있고, body에 어떤 위치에 무엇이 있는지 알 수 있다.
-> DOM이라고 한다.
왜 브라우저는 DOM을 만들려고 할까?
DOM은 실제로 복잡하다. DOM의 핵심 개념은 각각의 네모, 즉 노드를 객체로 생각한다는 것이다. 객체로 정의하게 되면 문서를 더욱 편리하게 관리할 수 있다.
브라우저는 렌더링을 해서 Dom 생성 이후 DOM manipulation을 시행한다.
우리가 쓰는 웹사이트는 동적 웹사이트이다. 브라우저에는 js가 내장되어 있어서 객체의 모음으로 된 DOM을 조작할 수 있는 필드를 조정하거나,method를 실행하거나 등으로 html을 실행할 수 있다.
DOM Tree를 순회해서 특정 원소를 추가할 수 있다.
document.getElementsByTagNAme("h2)h2원소를 찾아줘
브라우저는 왜 HTML을 DOM으로 바꿀까
- 원하는 요소를 동적으로 변경해줄 수 있다.(삭제,변경 등)
- 원하는 요소를 쉽게 찾을 수 있다.
웹 브라우저가 어떤 요소를 파싱해서 DOM을 만들어 놓으면 쓰기 편하다
-> 이미 가지고 왔던 html file을 parsing해서 다루자
Scrapping 관점에서 어떤 인사이트를 얻을 수 있을까?
브라우저는 HTML을 parsing해서 DOM을 생성한다.
이를 바탕으로 요소를 변경하거나 찾을 수 있었다.
파이썬으로 HTML을 분석하는 HTML Parser가 필요하다.
HTML_Parser + request => scrapping
