

로고 이미지를 클릭하여 Demo로 이동할 수 있습니다.
들어가며
저는 금융 도메인에 관심이 많은데요. 최근에는 ChatGPT와 같은 대화형 LLM을 이용하여 투자 관련 정보를 간단하게 얻곤 합니다. 하지만 ChatGPT의 웹 크롤링 능력이 향상되었음에도 불구하고, 정보의 출처가 명확하지 않은 점이 아쉽습니다. 특히, 잘못된 정보가 투자 손실로 이어질 위험이 있어 치명적일 수 있습니다.
이번 글에서는 이러한 문제를 해결하기 위해 금융 투자 도메인에 최적화된 LLM 서비스를 고안하고 구현한 경험을 소개하려 합니다.
금융 도메인 적합성에 대한 정의
토스증권 김성현님의 금융 도메인에서의 LLM 활용하기를 참고했습니다.
금융 도메인에 적합한 LLM 서비스를 개발하려면 먼저 ‘금융 도메인에 적합한 서비스 제공’의 기준을 정의하는 것이 중요합니다. 제가 참고한 영상에서는 증권 애널리스트처럼 투자 정보와 의견을 제공하는 것을 목표로 삼았습니다.
만약 애널리스트라면?
우리가 애플 투자자라고 가정해볼까요? 그렇다면 최근 핫한 이슈인 미국 관세정책이 기업 전망에 어떤 영향을 미칠지 궁금할 것입니다.
우리에게 최근 미국의 관세 정책이 기업 전망에 어떤 영향을 미칠까요? 라는 질문을 받은 애널리스트는 다음과 같은 4가지 절차를 거쳐 우리에게 의견을 제시합니다.

4가지 절차에 대해서는 아래에서 자세한 예시와 함께 알아보겠습니다.
1. Implicit Memory
먼저 Implicit Memory(암묵적 기억)이란 전문가가 이미 학습해서 가지고 있는 배경 지식 을 떠올리는 단계입니다. 이러한 배경지식에서 중요한 부분들은 특정 종목에 대한 Key factor일 수도 있고, 특정 산업군의 특수한 기질이 될 수도 있습니다.
1-1. 애플은 소비자 전자제품 및 반도체 설계를 주력으로 하는 회사지
1-2. 트럼프 관세정책은 미국으로 수입되는 철강, 알루미늄에 25% 추가 관세를 부과하는 정책
1-3. 글로벌하게 부품을 조달하고 중국에서 제품을 조립하는 애플도 관세로 인한 공급망 비용에 영향을 받을 수 있음
2. Aspect & Knowledge
Aspect & Knowledge란 질문과 관련된 정보를 얻기 위한 인사이트를 추론하는 단계입니다.
최근 미국의 관세 정책이 기업 전망에 어떤 영향을 미칠까요? 라는 질문에 대해서는 미국의 관세 정책을 단순히 이해하는 것 뿐만 아니라 정치, 수출 등 다양한 도메인에 대한 이해가 필요합니다.
이렇듯 단편적으로 질문을 이해하는 것이 아니라 다른 도메인의 관점으로 다양하게 접근하고 배경지식을 연결짓는 것이 중요합니다.
2-1. 관세 정책이 애플이라는 기업에 어떤 영향을 미칠지 찾아봐야겠네.
2-2. 애플의 수입 관련 포트폴리오 매출을 찾아보자.
2-3. 애플의 미국 내 판매 및 관세가 부품 비용에 미치는 영향을 찾아보자.
3. Reasoning step
Reasoning step 은 질문과 정보를 참고하여 답을 도출하는 과정입니다. 여기서는 각 단계별로 타당한 논리적 흐름을 생성하는데요. 주어진 지식 정보를 올바르게 응용하고 활용 및 해석하는지 검증하는 단계입니다.
3-1. 수입 철강과 알루미늄에 각각 25%와 10%의 관세를 부과하지만 특정 수입량까지는 관세를 면제하는 쿼터를 설정했네.
3-2. 애플의 미국 내 판매량 중 중국에서 조달하는 부품의 비율을 확인해야겠어.
3-3. 해당 부품들이 쿼터 내에 포함되는지, 초과 시 관세 비용이 얼마나 증가하는지 분석해야겠네.
3-4. 관세 부과로 인해 애플의 원가가 상승하면, 소비자 가격이나 이익률에 미치는 영향을 고려해야겠어.
3-5. 과거 사례를 참고해보면, 애플은 관세 영향을 줄이기 위해 공급망을 조정하거나 제조지를 다변화했던 적이 있지.
3-6. 그러면 이번에도 유사한 전략을 사용할 가능성이 높겠네.
4. Resolution
마지막으로 Resolution 단계는 지식과 정보의 논리를 종합하여 최종 결론을 도출하는 단계입니다.
4-1. 애플이 중국에서 조달하는 부품 중 일부는 쿼터 내에서 무관세 혜택을 받을 수 있지만, 초과분에 대해서는 25%의 관세가 부과될 가능성이 높다.
4-2. 이에 따라 생산 원가가 상승하면 애플은 제품 가격을 인상하거나, 이익률 감소를 감수해야 하는 상황이 발생할 수 있다.
4-3. 과거 사례를 보면, 애플은 이러한 관세 부담을 완화하기 위해 공급망을 조정하거나 특정 제품의 조립을 인도, 베트남 등 다른 국가로 이전하는 전략을 사용해왔다.
4-4. 이번에도 유사한 방식으로 대응할 가능성이 높으며, 관세 영향이 장기화될 경우 공급망 최적화 전략이 더욱 중요해질 것이다.
LLM Analyst
이제 우리는 LLM Analyst를 만들기 위해 중요한 요소들을 고려해야 합니다.
앞선 추론 단계에서 핵심적인 요소들을 정리해 보면 다음과 같습니다.
1. Reasoning 능력 강화
- 논리적 추론을 단계별로 수행하며 타당한 결론을 도출하는 능력
- 질문을 단순히 이해하는 것이 아니라, 관련된 여러 정보를 종합하여 해석하는 능력
- 다양한 도메인 지식을 연관 지어 활용하는 사고력
2. 데이터 활용 역량
- 정량적 데이터: 매출, 비용, 수익률, 관세율, 공급망 비용 등의 수치 기반 데이터 활용
- 최신 데이터: 시장 변화와 기업 실적 발표를 반영하여 최신 트렌드에 맞춘 분석 수행
- 과거 데이터 비교: 유사한 이슈(예: 과거 관세 부과 시 애플의 대응 전략)와 현재 상황을 비교 분석
3. Contextual Awareness
- 단순히 정보를 나열하는 것이 아니라, 맥락을 이해하고 종합적으로 판단하는 능력
- 예를 들어, 단순히 "관세 부과"라는 이벤트를 보고 영향을 분석하는 것이 아니라,
- 애플이 실제로 관세를 전가할 것인지
- 공급망 조정으로 해결할 가능성이 있는지
- 장기적으로 어떤 전략을 취할지 등의 비즈니스적 맥락까지 고려
Dataset
이제 우리는 위와 같은 정보를 제공하기 위한 데이터셋이 필요합니다. 뉴스, 커뮤니티 등 다양한 정보를 활용할 수 있겠지만, 애널리스트를 대체하기 위해서는 신뢰할 수 있는 데이터가 필요합니다. 또한 기업의 방향성을 파악해야 하는 만큼 제3자의 분석보다는 기업의 이사진 등 리더들의 인사이트 정보가 중요합니다.
이러한 정보를 얻을 수 있는 최적의 데이터를 어닝콜(Earning Call)에서 찾을 수 있었는데요. 어닝콜이란 주식시장에 상장된 기업이 분기별로 실적을 발표하고, 이후 기업 운영의 전망을 내놓는 행사입니다.

위의 사진은 25년 2월 초에 있었던 미국의 빅데이터 프로세싱 기업인 Palantir의 2024 4분기 어닝콜 Webcast 장면인데요. 보시는 것처럼 어닝콜에는 애널리스트와 CEO의 Q&A 세션 등이 포함되어 있어 기업의 중요한 정보와 방향성에 대해 알 수 있습니다.
Palantir(PLTR) 2024 Q4 Earnings Webcast
Earnings Call Transcript
웹에는 이러한 어닝콜 스크립트를 API로 제공하는 서비스가 많습니다. 저는 API Ninjas라는 서비스를 선택했는데, 이곳에서는 금융 데이터뿐만 아니라 대기오염, 인구 통계 등 다양한 정보를 API 형태로 제공합니다. 일반적으로 많은 서비스가 API 호출 횟수에 따라 과금하며 유료로 운영되지만, API Ninjas는 월 10,000건의 호출을 무료로 제공해 간단한 서비스 데모에 필요한 데이터를 충분히 확보할 수 있었습니다.
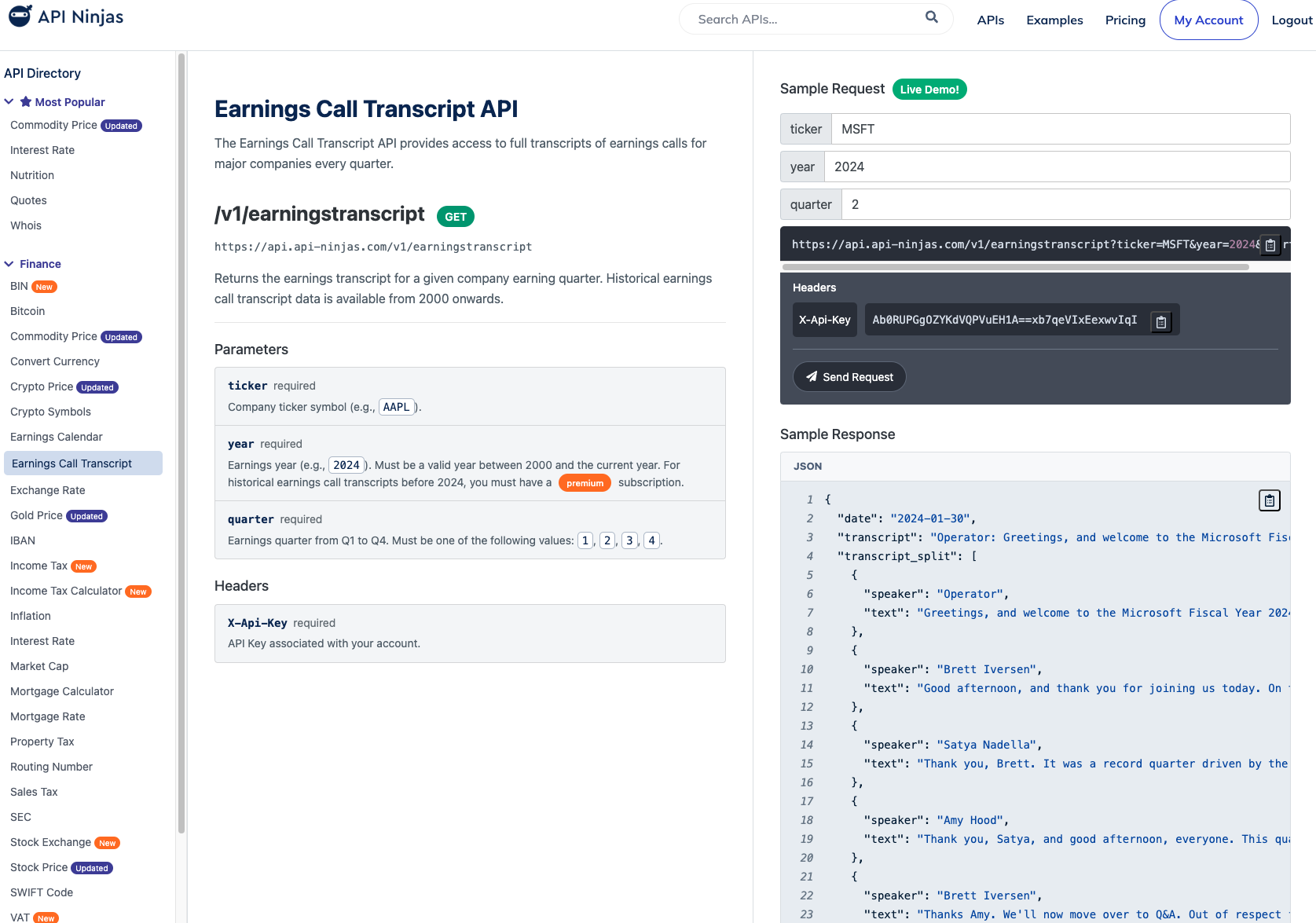
무료 API는 2024년의 어닝콜 스크립트만 제공하기 때문에, 저는 2024년의 시가총액 상위 500개 기업의 4개 분기 데이터 총 2,000개의 스크립트를 모았습니다.
500개 기업 * 1년 * 4분기 = 2,000개 데이터셋물론 각 데이터셋은 30~100개의 대화로 구성되기 때문에, 충분히 많은 데이터를 구할 수 있습니다.
Dataset preparation
Top Ticker list
종목 이름이 있어야 API를 호출할 수 있으니, 이제 시가총액 상위 500개 기업을 리스팅할 차례입니다.
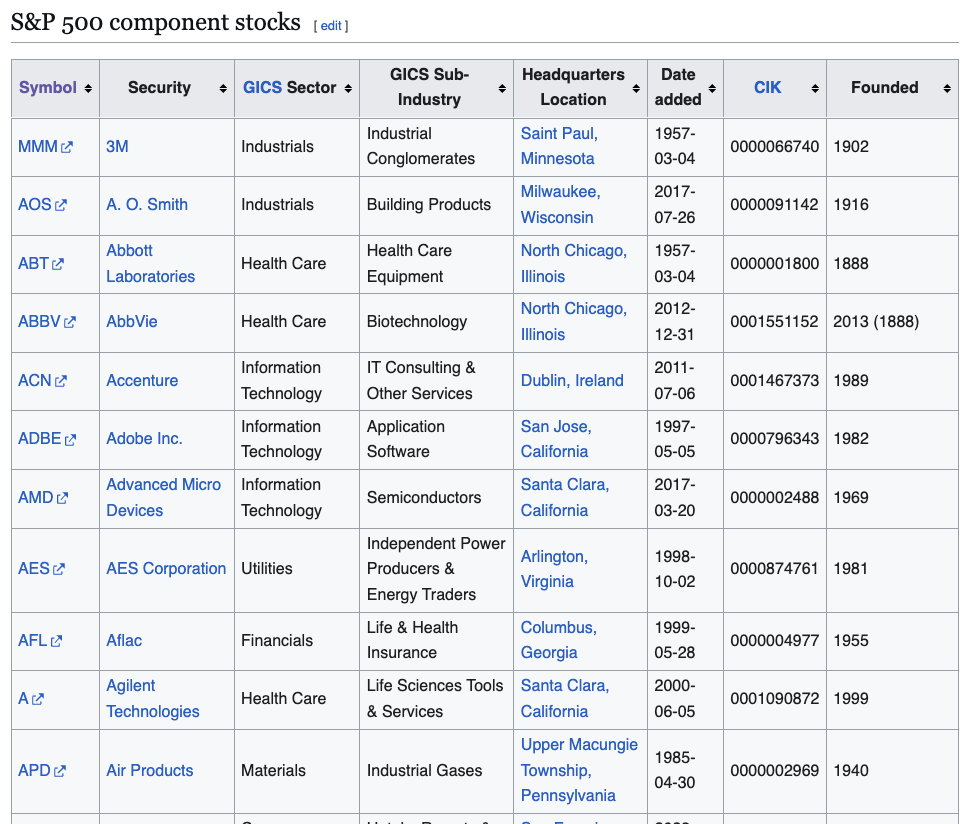
Ticker 란 주식에 부여되는 Symbol입니다. 한국에서는 종목코드를 사용하지만 미국 주식의 경우에는 Ticker로 주식을 구분합니다.
Apple(AAPL)
삼성전자(005930)먼저 위키피디아의 S&P 500 기업 목록에서 Ticker들을 받아왔습니다.
def get_top_tickers(top_count):
"""
Get top 500 US stocks by market cap using yfinance
"""
# Download ^SPX (S&P 500) components
sp500 = pd.read_html('https://en.wikipedia.org/wiki/List_of_S%26P_500_companies')[0]
print(sp500)
tickers = sp500['Symbol'].tolist()
# return top tickers
return tickers[:top_count]
Fetch Ticker Info
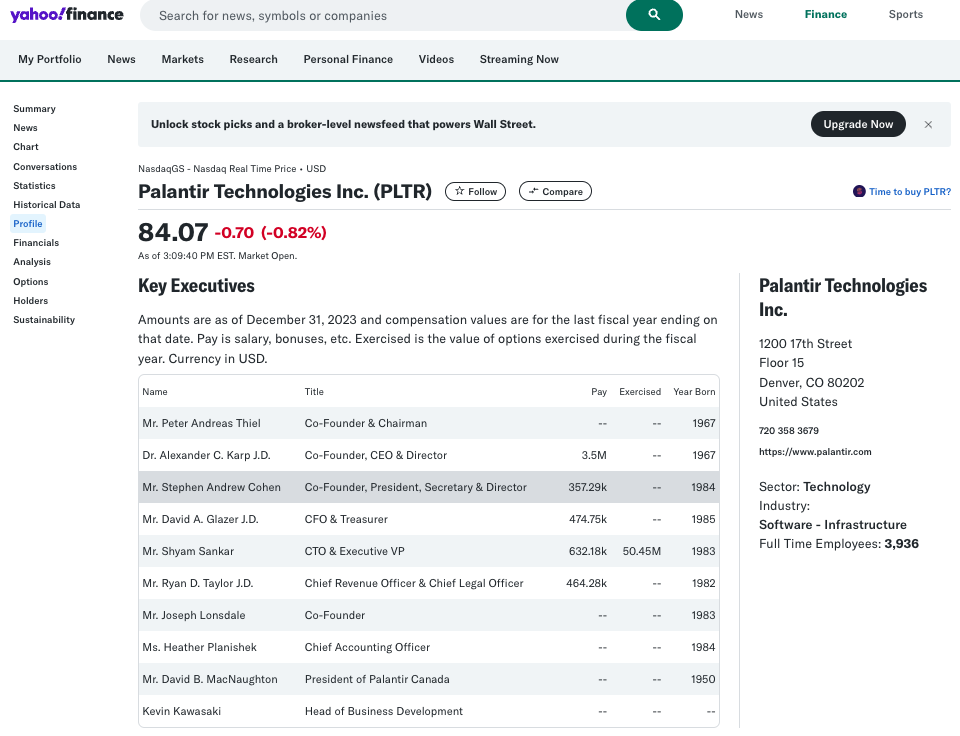
이후 해당 Ticker들을 바탕으로 Yahoo Finance에서 Sector, Industry 등 해당 기업들의 정보를 받아옵니다.
def get_company_info():
tickers = load_tickers()
results = []
# Show progress with tqdm
for ticker in tqdm(tickers, desc="Fetching company info"):
try:
# Handle special tickers like BRK.B
ticker_formatted = ticker.replace('.', '-')
stock = yf.Ticker(ticker_formatted)
info = stock.info
results.append({
'Ticker': ticker,
'Company': info.get('longName', 'N/A'),
'Country': info.get('country', 'N/A'),
'Sector': info.get('sector', 'N/A'),
'Industry': info.get('industry', 'N/A')
})
except Exception as e:
print(f"Error processing {ticker}: {str(e)}")
continue
# Convert to DataFrame for clean output
df = pd.DataFrame(results)
return df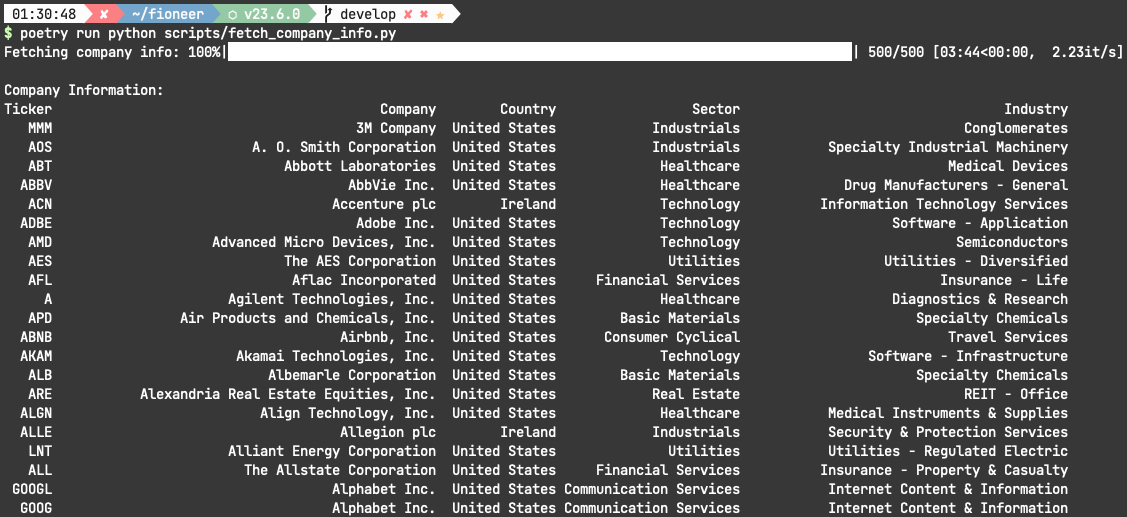
Preprocessing
Fetch Eearnigs call Transcript
이제 Ticker, Year, Quater 3가지 정보로 아래와 같이 API를 호출할 수 있는데요.
Response로 정확한 어닝콜 Date와 Transcript를 json 형태로 제공해줍니다. 저는 Dataframe으로 한 차례 가공을 해서 터미널에 출력해보았습니다.
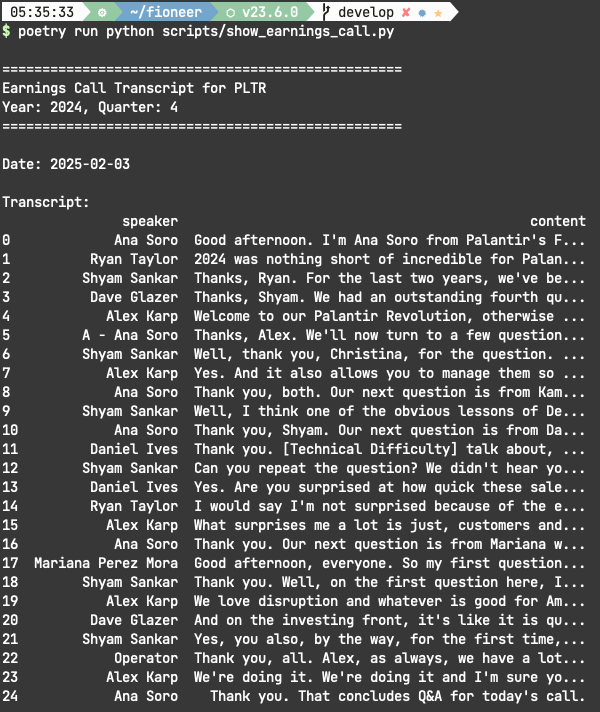
이제 번거로운 과정들을 LLM을 이용해 자동화하여 데이터셋 전처리를 마무리해보겠습니다.
QA Section 구분
어닝콜 Q&A 파트는 보통 여러개의 질의응답 섹션으로 구분됩니다.
아래의 예시를 볼까요?
Daniel Ives(Analyst): 2024 4분기 실적은 어땠나요?
Alex Karp(CEO): 굉장히 뛰어났죠. 이미 올해 목표 실적을 3분기에 달성했으니까요.
Shyam Sankar(CTO): 덧붙이자면, 3분기 실적의 2배를 4분기에 달성했습니다.
Ana Soro(Operator): 좋습니다. 다음 질문으로 넘어갈까요?제가 편의상 직책을 달아두었지만, API Response 데이터만으로는 누가 애널리스트고 누가 이사진인지 알 수 없습니다. 또한 하나의 질문에 대해 여러명의 유관자가 답변하는 경우도 있어서, 어디까지가 유효한 하나의 질의응답 섹션인지 일일이 확인하고 구분하기엔 매우 번거롭습니다.
때문에 저는 아래와 같은 로직으로 LLM을 이용해서 QA pair를 구분해보았습니다.
async def _extract_qa_structure(self, content: str) -> Dict:
"""Extract question and answer structure using LLM"""
prompt = [
{"role": "system", "content": """Given a section of an earnings call transcript, identify and separate the question and answer.
If there are multiple distinct questions or points within the same section, split them into separate Q&A pairs.
Return in JSON format as a list of Q&A pairs, where each pair has:
- 'question': the full question text
- 'answer': the full answer text
- 'q_speaker': the EXACT full name of the person asking the question
- 'a_speaker': the EXACT full name of the person answering
You must include the FULL NAME of speakers. If a speaker's full name is not provided, mark as 'Analyst'.
Format: {"qa_pairs": [{"question": "...", "answer": "...", "q_speaker": "...", "a_speaker": "..."}]}
If there's no clear Q&A structure, return 'NO_QA'."""},
{"role": "user", "content": content}
]
result = await chat_completion(messages=prompt)
try:
if result == "NO_QA":
return None
qa_dict = json.loads(result)
qa_pairs = qa_dict.get('qa_pairs', [])
# Validate speaker names
for qa in qa_pairs:
if not qa.get('a_speaker'):
qa['a_speaker'] = 'UNKNOWN_SPEAKER'
return qa_pairs
except:QA 요약
이제 앞서 나눠둔 QA Pair들로 질문과 답변을 요약합니다.
async def _summarize_question(self, question: str) -> str:
"""Summarize the question into a concise form"""
prompt = [
{"role": "system", "content": "Summarize this earnings call question into a brief, clear form while maintaining the key points. Return only the summarized question."},
{"role": "user", "content": question}
]
async def _summarize_answer(self, answer: str) -> str:
"""Summarize the answer into a concise form"""
prompt = [
{"role": "system", "content": "Summarize this earnings call answer into a brief, clear form while maintaining the key points. Return only the summarized answer."},
{"role": "user", "content": answer}
]
return await chat_completion(messages=prompt)Insight & Reasoning Steps 추출
이후 같은 QA Pair들로 각 QA 섹션의 Key Insight 를 도출하고, 해당 Insight를 도출하는 과정을 Reasoning Steps로 정리하여 리턴합니다.
async def _extract_insight(self, question: str, answer: str) -> Dict:
"""Extract key insight and reasoning steps from Q&A using OpenAI"""
content = f"Question: {question}\nAnswer: {answer}"
prompt = [
{"role": "system", "content": """Analyze this Q&A from an earnings call.
First, provide your step-by-step factual reasoning process, focusing on the key business facts and numbers mentioned.
Exclude any speaker information or subjective interpretations.
Number each reasoning step (1., 2., etc.).
Then, extract the key business insight.
Return in JSON format:
{
"reasoning_steps": ["1. fact1", "2. fact2", "3. fact3"],
"insight": "final insight"
}
If no meaningful insight can be extracted, return 'NO_INSIGHT'."""},
{"role": "user", "content": content}
]
result = await chat_completion(messages=prompt)
if result == self.NO_INSIGHT:
return None
try:
result_dict = json.loads(result)
return result_dict
except:
return NoneMetadata
드디어 앞서 준비한 데이터들을 조합하여 메타데이터를 정리할 차례입니다.

우리는 앞서 Company Info와 Earnings Call Transcripts 데이터를 준비했는데요. 이러한 정보들을 그대로 사용하기도 하고, 가공이 필요한 데이터들은 LLM을 이용하여 처리 후 통합했습니다.
Metadata Example (AAPL_2024_Q2.json)
[
{
"company": "Apple Inc.",
"country": "United States",
"ticker": "AAPL",
"date": "2024-05-02",
"year": 2024,
"q": 2,
"sector": "Technology",
"industry": "Consumer Electronics",
"q_speaker": "Richard Kramer",
"a_speaker": "Luca Maestri",
"question_summary": "Are you prioritizing maintaining high margins or focusing on spurring growth to reach a net neutral cash position?",
"answer_summary": "The company has experienced a strong dollar over a long period, impacting reported results as over 60% of revenue comes from abroad. Despite this, demand for products in international markets is robust due to currency translation. The company continues to invest in innovations, financing solutions, and trading programs to support its growth.",
"insight": "Despite facing challenges with a strong dollar impacting reported results, the company's focus on innovation, financing solutions, and trading programs remains strong to support continued growth and investments.",
"reasoning_steps": [
"1. Company sells more than 60% of its revenue outside the United States.",
"2. The company has been impacted by a long period of a strong dollar.",
"3. Despite strong demand for products in international markets, results in dollars may not fully reflect this due to currency translation effects."
]
},
{
"company": "Apple Inc.",
"country": "United States",
"ticker": "AAPL",
"date": "2024-05-02",
"year": 2024,
"q": 2,
"sector": "Technology",
"industry": "Consumer Electronics",
"q_speaker": "Atif Malik",
"a_speaker": "Tim Cook",
"question_summary": "What are the top two or three use cases generating the most excitement for Vision Pro in the enterprise segment?",
"answer_summary": "The company is experiencing a wide range of use cases with its product across various industries, including field service, training, healthcare, control centers, and more. They are focused on growing their ecosystem, increasing the number of apps, and engaging more enterprises. The recent event showcased significant enthusiasm for their enterprise solutions.",
"insight": "Vision Pro has a wide range of use cases across different industries in enterprise, and there is significant enthusiasm and engagement from enterprises during recent events.",
"reasoning_steps": [
"1. Vision Pro is being used across various verticals in enterprise.",
"2. Use cases include field service, training, healthcare (such as preparing doctors for surgeries), and advanced imaging.",
"3. The focus is on growing the ecosystem, getting more apps, and engaging more enterprises."
]
}
]메타데이터를 추출하는 자세한 소스코드는 metadata_extractor.py 에서 확인할 수 있습니다.
Shared Dataset
제가 정리한 데이터셋은 Hugging Face에 업로드해두었습니다.
Finetuning vs RAG
이제 메타데이터를 어떻게 LLM에 사용할지 고민해야 합니다.
특정 도메인에 적합한 LLM 서비스를 만드려면 어떻게 해야 할까요?
보통 방법은 아래와 같은 2가지로 나뉩니다.
- Fine-tuning : LLM에 Domain Knowledge를 학습시킨다.
- RAG : LLM에 Domain Knowledge를 제공한다.
LLM의 유행 초창기부터 파인튜닝은 도메인 최적화 수단으로 각광받아 왔고 여전히 좋은 방법입니다. 하지만 파인튜닝은 모델 학습에 대한 시간 및 비용의 문제가 있고, 최신의 데이터를 반영하는 것에 어려움이 있습니다.
RAG(Retrieval-Augmented Generation)
RAG는 이러한 파인튜닝의 대안으로 모델-도메인 최적화 분야에서 떠오르는 방식인데요.
LLM에게 질문을 하기 전에, 추가적인 정보를 제공하여 응답을 생성하는 기술입니다.
Example Prompt
사용자 질문: RAG가 무엇인가요?
아래 질문을 참고해서 알려줘.
- RAG(Retrieval-Augmented Generation)는 사전 학습된 LLM이 외부 지식 소스를 검색하여 답변을 생성하는 기술입니다.
- 이 방식은 파인튜닝 없이도 최신 정보를 활용할 수 있도록 도와줍니다.
RAG는 위와 같이 프롬프트를 작성할 때, 추가적인 정보를 DB에서 가져와서 프롬프트에 넣어주는 방식으로 구현할 수 있습니다.
이렇게 구현한다면, 모델을 새로 학습할 필요 없이 최신 데이터만 DB에 갱신하고 프롬프트에 적절히 넣어주는 방식으로 최신화가 가능합니다.
Data Flow
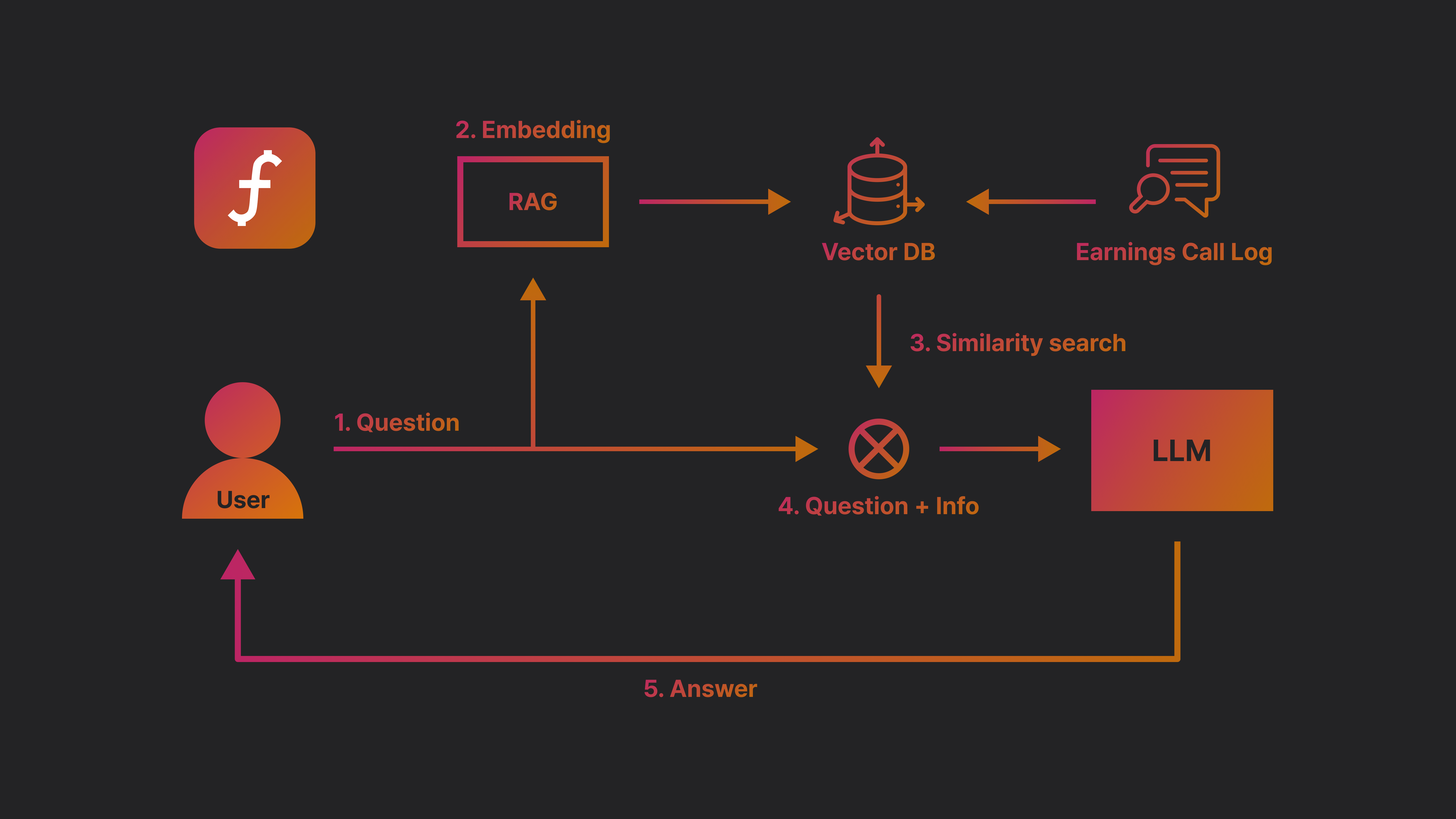
때문에 빠르게 DB에 접근해서 유사한 정보를 가지고 오는 것이 중요하겠죠? 빠르게, 유사한 정보를 조회할 때는 Vector Database를 사용하는 것이 Best Practice입니다.
Implement
FAISS
Vector DB로는 FAISS라는 오픈소스를 선택했습니다. FAISS는 Facebook AI Similarity Search의 약자로, Meta(Facebook)에서 만든 Vector DB 라이브러리입니다.
서비스에서 벡터 DB를 설계할 때는 Pinecone 등의 클라우드 기반 SaaS를 사용하는 경우가 있는데요. Pinecone은 스케일링이 가능하기 때문에 트래픽이 많은 실서비스에 적합합니다. 반면 FAISS는 무료로 사용가능한 오픈소스이며, CPU/GPU 가속을 지원하여 로컬에서 매우 빠르게 데이터를 조회할 수 있습니다.
위에서 전처리된 데이터셋은 company, ticker, sector 등 다양한 정보를 가지고 있는데요. 이러한 각각의 정보들을 하나의 축(axis)으로 생각한다면, 우리는 하나의 데이터를 Vector로 생각할 수 있습니다.
예를 들어 위의 데이터셋은 14개의 정보를 담고 있으니 14차원 벡터라고 생각할 수 있겠네요. 벡터는 내적 등의 수학적인 방식으로 유사도를 판단할 수 있는데요. FAISS는 이러한 유사도 검색에 적합한 Vector DB입니다.
Embeddings
다시 Data Flow를 가져왔습니다. 우리는 메타데이터를 Vector로 변환하는 작업이 필요하며, 이러한 작업을 Embedding 이라고 합니다
Embedding은 Vector : Metadata KV를 데이터베이스에 넣어줄 때 필요하며, 또한 서비스에서 질의한 Query를 벡터로 바꿔줄 때에도 필요합니다.
흐름이 이해된 상태에서 RAG를 다시 한 번 정리하자면, RAG란 질문을 벡터로 바꾸고 유사한 벡터의 정보를 가져와서 이를 부가정보로 프롬프트에 넣어주는 기술입니다.
Prompt
context = f"""
Company: {metadata['company']} ({metadata['ticker']})
Date: {metadata['date']} (Q{metadata['q']} {metadata['year']})
Speaker: {metadata['a_speaker']}
Question: {metadata['question_summary']}
Answer: {metadata['answer_summary']}
Key Insight: {metadata['insight']}
Reasoning Steps: {metadata['reasoning_steps']}
"""
# Prepare prompt for LLM
prompt = f"""
Based on the following earnings call information, please answer the question: "{query}"
Context:
{context}
Please provide a comprehensive answer."""그렇다면 Prompt는 위와 같이 Query에 대한 답변을 Vector DB에서 조회한 Context를 참고해서 생성하도록 작성할 수 있습니다.
Result
로고 이미지를 클릭하여 Demo로 이동할 수 있습니다.
엔비디아, 구글 등 평소 관심 있었던 다양한 기업에 대해 질문해보세요!
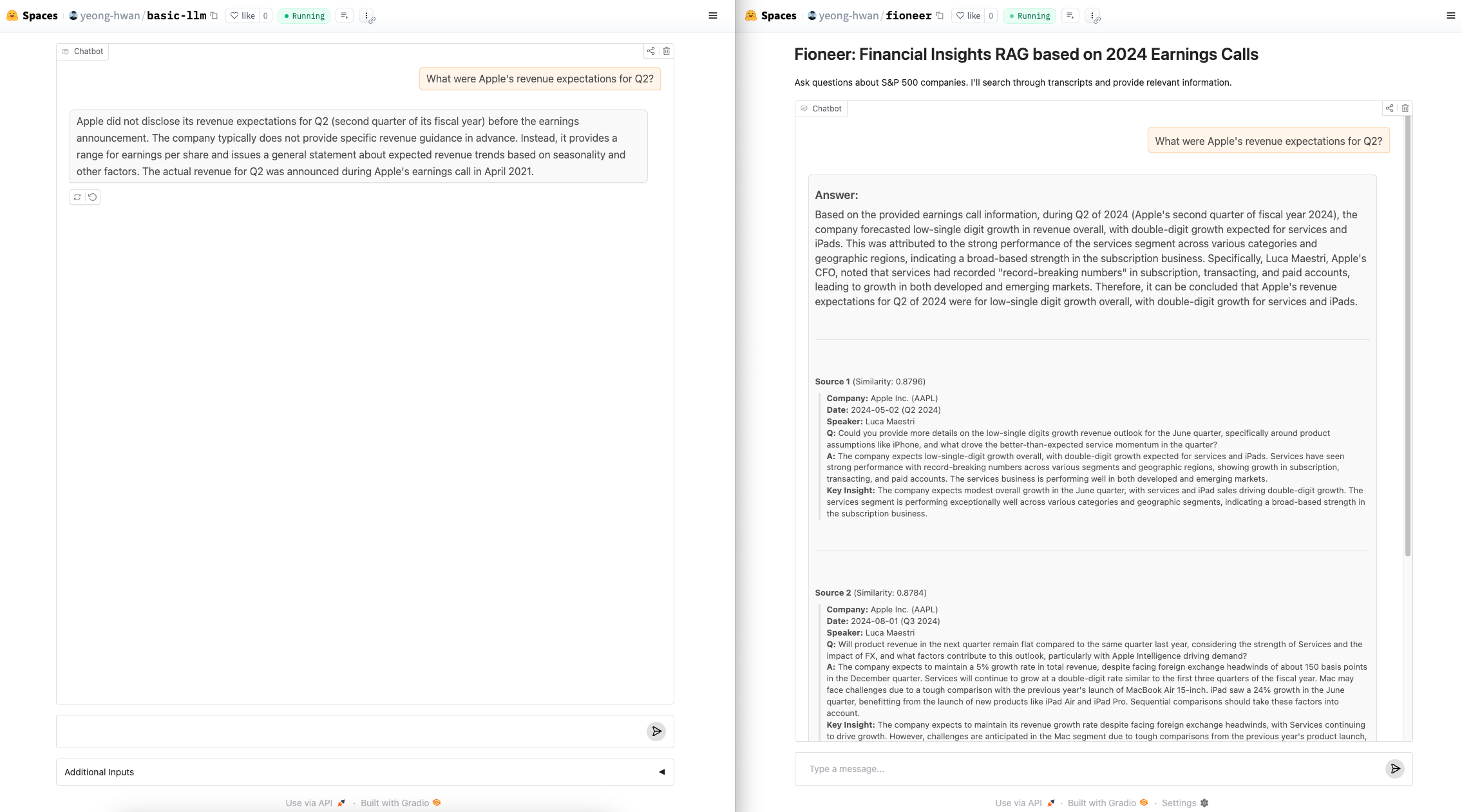
좌우는 모두 허깅페이스의 기본 LLM 모델인 zephyr-7b-beta를 이용했습니다.
좌측은 순수한 zephyr 모델이고, 우측은 zephyr 모델에 RAG로 추가적인 정보를 제공한 경우입니다.
좌측은 모델이 기존에 학습한대로 Apple의 2분기 실적 예상에 대해 2021년 자료를 바탕으로 응답을 생성합니다. 반면 우측은 메타데이터의 어닝콜 정보와 Reasoning Steps의 정보를 바탕으로 자체적인 의견을 추론하고 생성합니다.
답변할 수 있는 Time Range는 2024년에 한정되지만, 2024년도에 관련된 데이터는 모두 매우 뛰어나게 답변하는 것을 확인할 수 있습니다. 이러한 데이터가 2024년 전후로 계속 쌓인다면, 과거의 정보에 대해서도 더 잘 대답할 수 있으며, 과거의 정보를 바탕으로 미래의 예측도 더 잘 할 수 있을거라 기대합니다.
References

좋은 글 감사합니다. 잘 읽었습니다.