
들어가며
제가 속한 스타트업의 서버는 월간 활성 사용자(MAU) 1,000만 명 규모의 트래픽을 감당하고 있습니다. 이 정도 규모에서는 평소에는 문제없이 동작하던 서비스가 어느 순간 이유 없이 느려지거나 병목이 발생하는 일이 자주 생깁니다. 이를 해결하기 위해 회사는 성능 병목을 사전에 파악하고, 예방 및 개선하는 전담 팀을 신설했습니다.
저는 이 팀에 합류하면서, 실제 트래픽이 몰리는 상황에서 시스템이 어떻게 반응하는지, 그리고 데이터베이스 쿼리를 어떻게 최적화해야 하는지에 대한 전문적인 이해가 필수라는 것을 실감하고 있습니다. 아직 실무 경험은 부족하지만, 온보딩 과정을 거치며 어떤 부분에 집중해야 할지 고민한 내용을 공유하고자 합니다.
언제 쿼리를 최적화해야 할까?
쿼리 최적화는 타이밍이 전부다.
불필요한 최적화는 개발 리소스를 낭비하고, 시스템을 과도하게 복잡하게 만들 수 있습니다. 반면, 최적화 타이밍을 놓치면 사용자 경험이 나빠지고 장애로 이어질 위험이 있습니다. 그렇다면 언제 최적화를 해야 할까요?
최적화가 필요한 시점은 언제일까?
가장 명확한 신호는 평소 모니터링하던 주요 지표가 비정상적으로 변화했을 때입니다.
예를 들어, 특정 시간대에 API 평균 응답 시간이 평소 200ms에서 500ms로 증가했다면, 트래픽이 몰리는 시간에 병목이 발생했을 가능성을 의심해볼 수 있습니다. 트래픽 자체가 늘어서 생긴 현상인지, 특정 쿼리에 문제가 생긴 것인지 확인한 후, 실행 계획을 점검하고 인덱스나 조인 방식 등을 검토하는 것이 좋습니다.
TPS(Transactions Per Second)가 감소하는 경우도 주의해야 합니다. 초당 트랜잭션 처리량이 줄어드는 현상은 데이터 증가에 따라 풀 스캔이 발생했거나, 락 경합으로 인해 처리량이 떨어졌을 가능성을 보여줍니다. 예를 들어, 처음에는 몇 만 건이던 테이블이 시간이 지나 수백만 건으로 커지면서 기존 인덱스로는 효율적인 조회가 어려워지는 경우입니다.
슬로우 쿼리 로그도 중요한 기준이 됩니다. 슬로우 쿼리 비율이 높아지면 기존에는 문제가 되지 않던 쿼리가, 데이터 양이 많아지거나 호출 빈도가 증가하면서 병목이 될 가능성이 높습니다. 과거에는 주로 월간 통계용으로만 실행되던 쿼리가, 새로운 기능이 추가된 이후 매일 수천 번 호출되기 시작했다면 더는 그대로 둘 수 없는 상황이 된 것입니다.
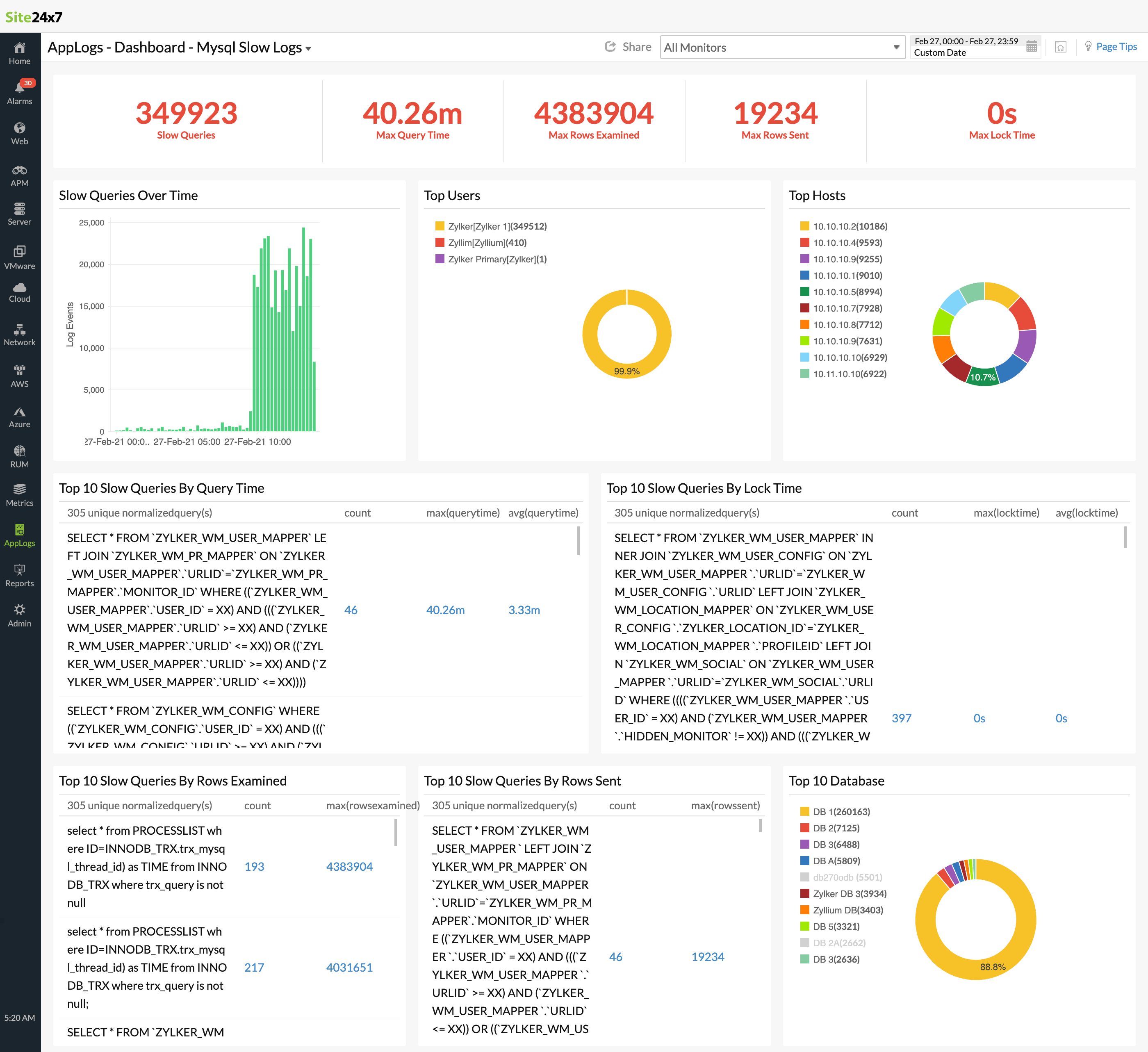
SLO를 초과했을 때 바로 점검합니다
SLO(Service Level Objective)는 서비스가 사용자와 약속한 품질 기준입니다. 이를 초과하면 즉각적인 대응이 필요합니다.
예를 들어, 회원가입 API의 응답 시간을 300ms 이내로 유지하기로 했는데, 이벤트 시즌에 가입자가 몰리면서 이 기준을 넘었다면 그 즉시 원인을 분석하고 조치해야 합니다. 예시로 외부 인증 서버와의 동기 호출이 지연되면서 전체 응답 시간이 늘어났다면, 비동기 처리 방식으로 개선하여 다시 SLO를 만족시키는 시나리오도 있을 수 있겠네요.
사용자 경험이 나빠졌다는 피드백이 들어올 때도 신호입니다
지표상으로는 별다른 문제가 없어 보여도, 사용자의 체감 성능이 나빠지면 대응이 필요합니다.
예를 들어, 상품 목록 조회 API가 평균 응답 시간 기준으로는 정상인데, 특정 카테고리에서 필터를 적용할 때만 로딩 시간이 길어진다면 이는 명확한 병목 신호입니다. 실제로 데이터 패턴이 바뀌거나, 기존에 사용하지 않던 필터 조합이 자주 사용되면서 쿼리 성능이 저하된 경우가 있습니다. 이런 문제는 기존 실행 계획을 다시 분석하고, 필요한 인덱스를 추가하거나 파티셔닝을 도입하는 방식으로 해결할 수 있습니다.
정말 DB가 병목일까?
응답 속도가 느려졌다고 해서 무조건 DB를 의심하는 것은 위험합니다.
실제로는 다른 원인에서 비롯되는 경우가 더 많습니다.
예를 들어 전체적인 시스템 응답이 느려졌던 적이 있는데, 알고 보니 특정 리전의 트래픽이 급증하면서 글로벌 로드 밸런서가 일부 서버에만 요청을 집중시키는 경우도 있을 수 있습니다. 이 경우 로드 밸런서의 트래픽 분산 정책을 수정하여 문제를 해결할 수 있습니다.
앞서 소개했던 것처럼 Cache-hit 또한 신경써야 합니다. Redis 캐시의 TTL이 너무 짧게 설정되어 있다면 캐시는 자주 무효화됩니다.
특정 기능에서는 데이터 변경이 자주 일어나지 않기 때문에 캐시 만료 시간을 늘려주는 것만으로도 DB에 대한 접근을 크게 줄일 수 있습니다. 예를 들어 커머스 홈화면에서 자주 보는 메인 배너가 있다면, 메인 배너 데이터를 캐시에 저장하고 데이터 변경 시점에만 캐시를 무효화하는 방식으로 트래픽이 몰리는 경우에도 안정적인 응답속도를 유지할 수 있습니다.
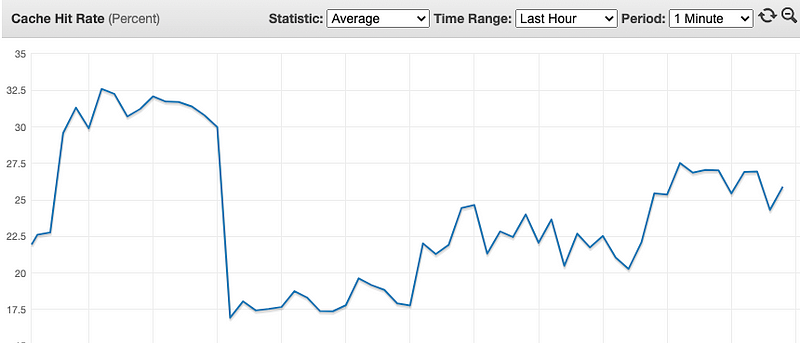
이처럼 다양한 레이어를 점검하고 나서도 문제가 DB 쿼리에 있다면, 그때 최적화를 진행하는 것이 맞습니다.
최적화 외에 고려해야 할 대안도 있습니다
모든 상황이 쿼리 튜닝으로 해결되지는 않습니다. 때로는 시스템 구조 자체를 바꿔야 할 필요가 있습니다.
예를 들어, 읽기 트래픽이 급증한 서비스라면 CQRS 패턴을 도입해 읽기와 쓰기를 분리하는 방법을 생각해볼 수 있습니다. 주문 데이터가 급격히 증가한다면 읽기 전용 DB를 따로 두고 처리하여 메인 DB(Write)의 부하를 크게 감소시킬 수 있겠죠?
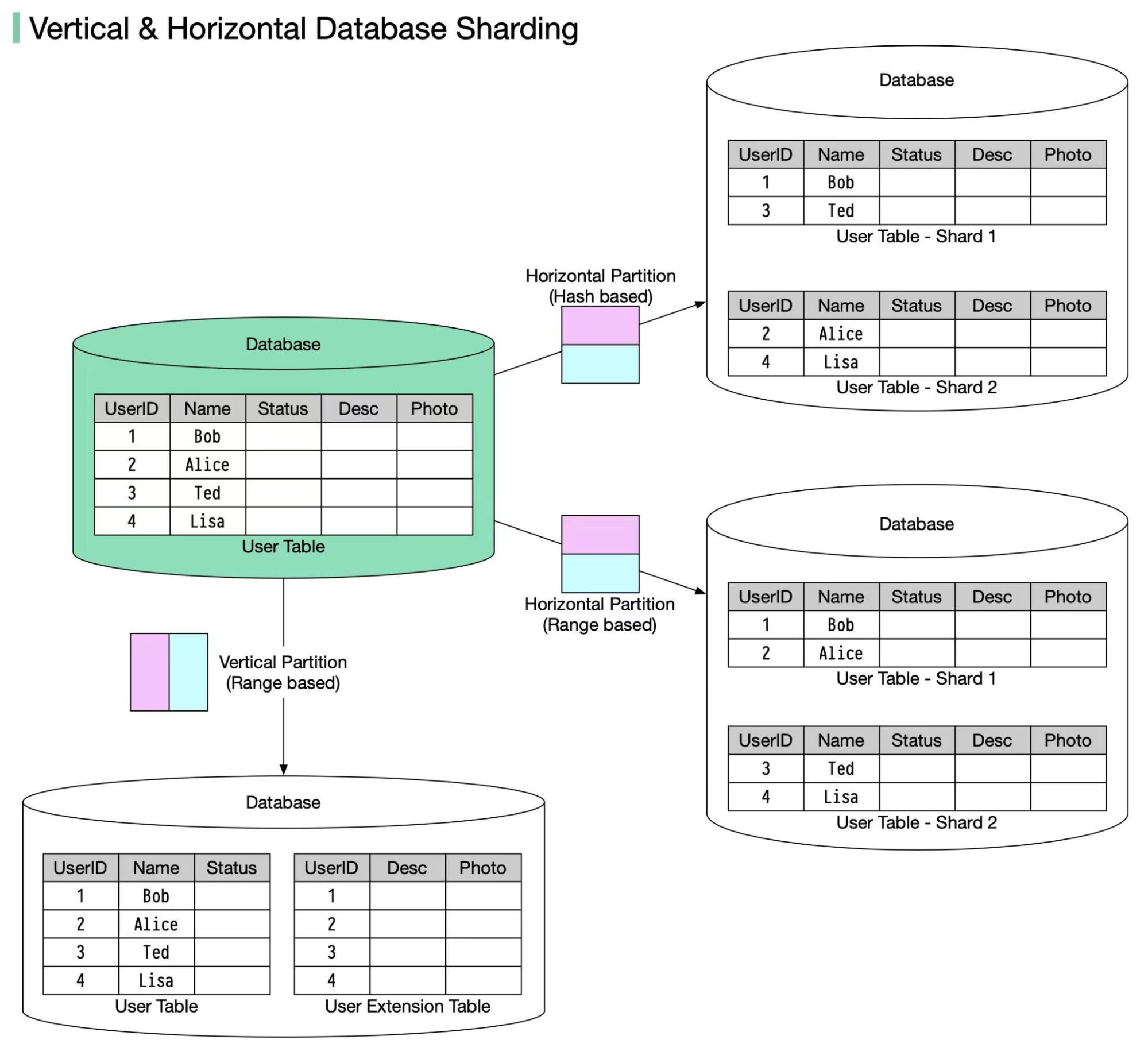
테이블이 너무 커지면서 인덱스 관리가 어려워졌다면, 테이블 파티셔닝이나 샤딩도 좋은 선택이 될 수 있습니다. 수억 건의 로그 데이터를 월별 파티셔닝으로 분할하는 것도 좋은 예시입니다.
North Star(핵심 지표)
우리는 "느리다"는 사용자 피드백이나 개발자의 직감으로 쿼리 튜닝을 시작하곤 합니다. 그러나 이 방식은 오히려 잘못된 방향으로 자원을 낭비할 위험이 있습니다. 데이터를 기반으로 한 명확한 판단이 필요하며, 그 중심에 핵심 지표(North Star)가 존재합니다.
핵심 지표는 단순히 수집한 메트릭이 아닌, 우리가 집중해야 할 가장 중요한 시스템의 건강 지표입니다. 이 지표가 최적화의 나침반이 되어야 하고, 이 지표가 개선되지 않는다면 그 최적화는 실패라고 판단해야 합니다.
1. North Star 지표를 선정하는 기준
핵심 지표는 아래 세 가지 기준을 반드시 충족해야 합니다.
-
비즈니스 목표와 연결되어야 합니다
단순히 DB 내부 성능 수치가 아닌, 사용자 경험과 서비스 품질로 이어지는 지표여야 합니다.
예를 들어, 쇼핑몰의 경우 "결제 완료까지의 전체 처리 시간"이 핵심 지표가 될 수 있습니다. 단순한 DB 쿼리 속도가 아니라, 최종 사용자 경험과 직결되는 지표입니다. -
정량적이고 객관적이어야 합니다
누가 보더라도 같은 결론을 내릴 수 있어야 합니다.
"느린 것 같다"가 아니라 "P99 응답 시간이 800ms를 넘었다"처럼 수치 기반으로 명확하게 정의되어야 합니다. -
시간에 따른 추이와 인과관계를 보여줄 수 있어야 합니다
단일 시점 스냅샷이 아닌, 시간 흐름에 따라 악화 혹은 개선이 확인 가능해야 합니다.
또한, 특정 지표가 악화되었을 때 다른 지표와의 인과관계를 설명할 수 있어야 원인 분석과 개선이 가능합니다.
2. 실전에서 사용하는 핵심 DB 지표
핵심 지표는 서비스 특성과 트래픽 패턴에 따라 달라질 수 있지만, 대부분의 시스템에서 공통적으로 모니터링하는 기본적인 DB 지표는 다음과 같습니다.
QPS / TPS (Query Per Second / Transactions Per Second)
초당 몇 개의 쿼리와 트랜잭션이 처리되고 있는지 측정하는 지표입니다.
시스템 전체 부하를 가늠하는 기본적인 척도입니다.
예를 들어, 평소보다 TPS가 급격히 증가했는데도 응답 시간이 유지된다면 시스템이 안정적으로 확장되고 있다는 뜻입니다. 반대로 TPS가 줄었는데도 응답 시간이 길어지면 병목이 발생하고 있을 가능성이 있습니다.
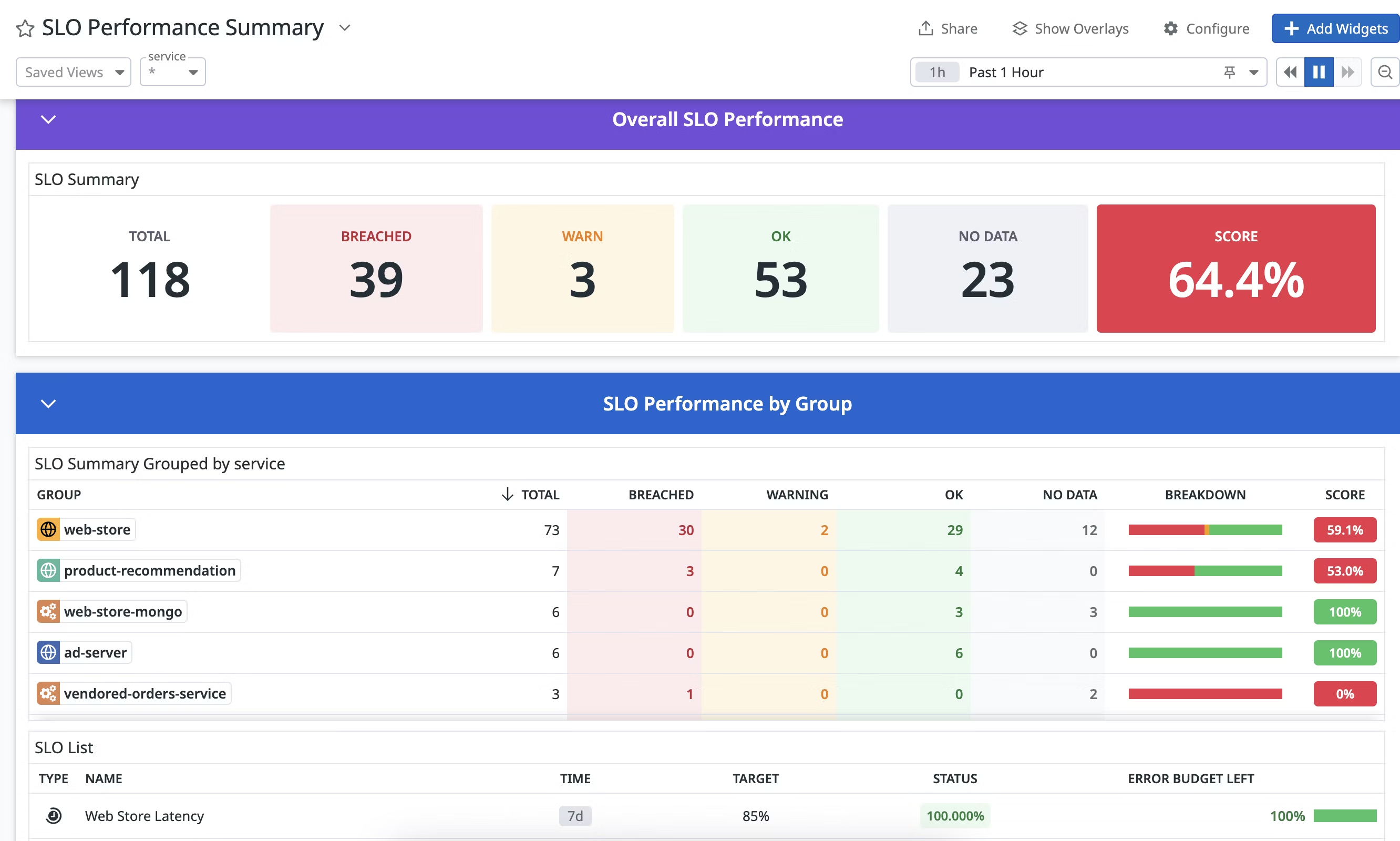
P99 응답 시간
- 평균 응답 시간은 왜곡되기 쉽습니다. 대부분의 성능 문제는 상위 1~5% 사용자에게 집중되기 때문입니다.
P99응답 시간은 상위 1% 요청 중 가장 느린 요청의 성능을 보여줍니다.
예를 들어, P99가 500ms라면 상위 1% 사용자는 응답을 받기까지 최소 500ms가 걸리고 있다는 뜻입니다.- 실시간 거래 서비스라면 이 수치가 SLO 위반으로 직결될 수 있습니다.
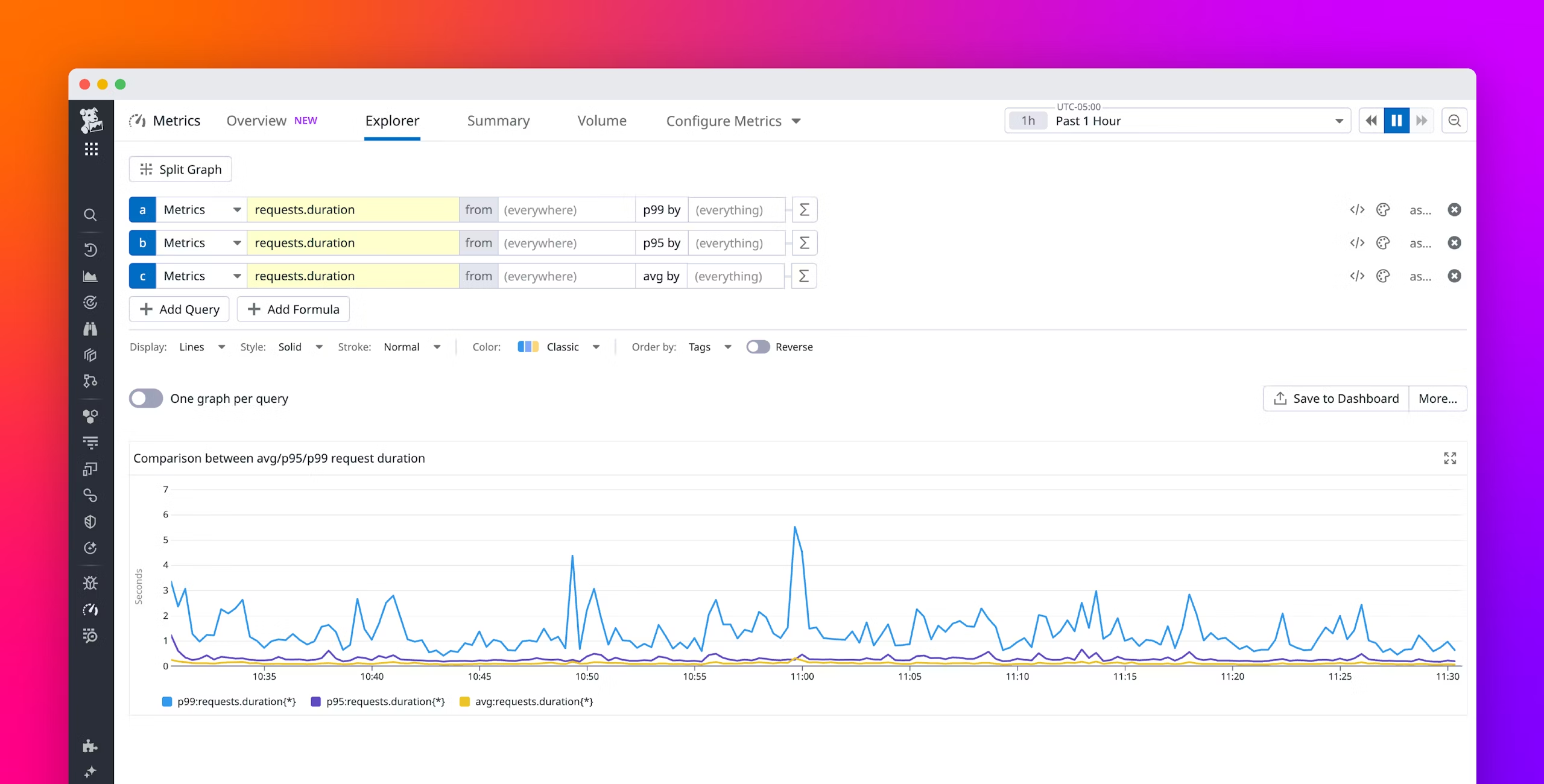
위의 예시를 보면 AVG, P95 수치는 안정적이지만 P99가 급격히 튀어오르는 것을 볼 수 있습니다.
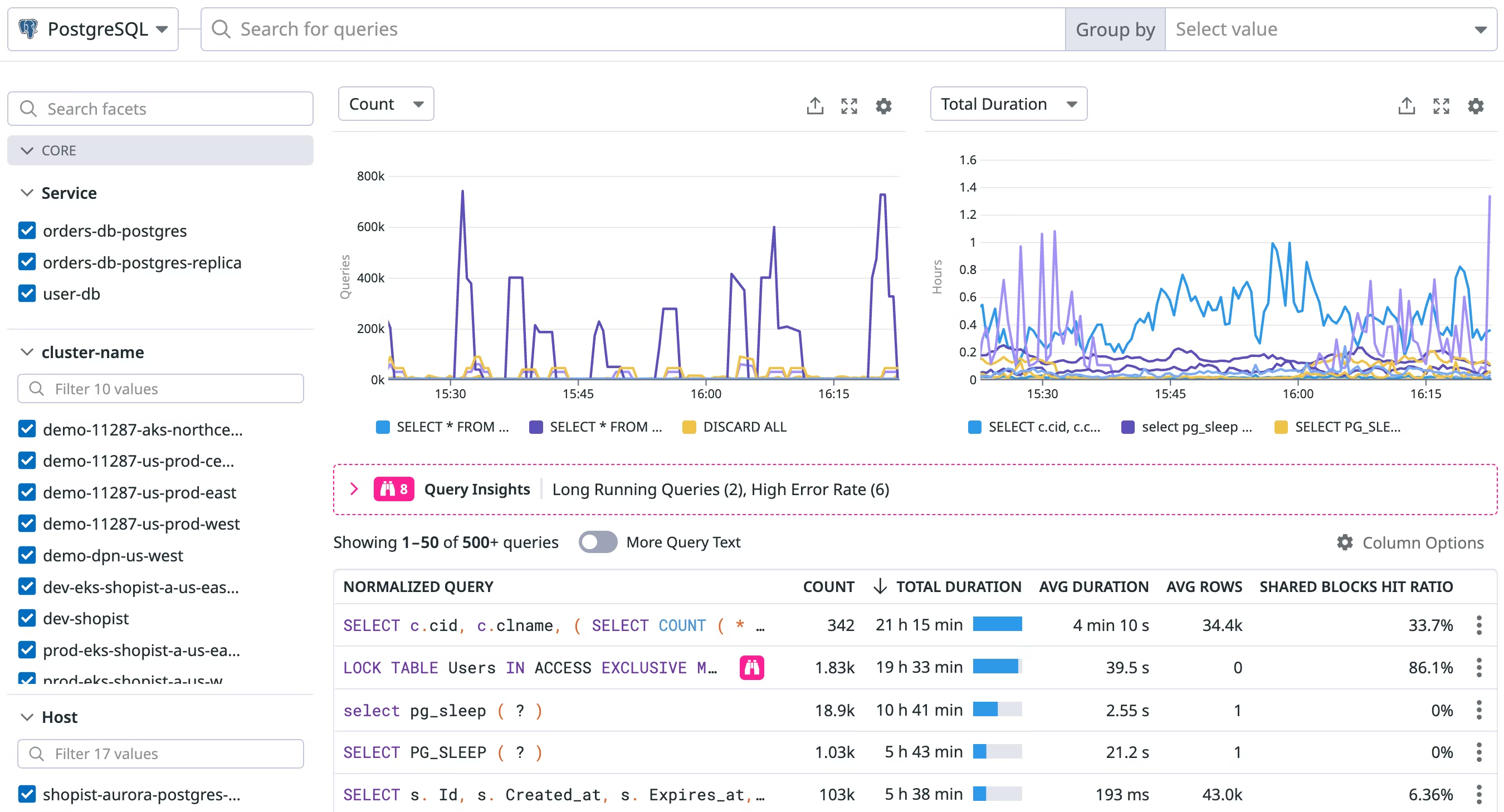
슬로우 쿼리 비율
- 전체 쿼리 중 슬로우 쿼리에 해당하는 비율이 1%를 넘는다면 병목이 발생하고 있다는 신호입니다.
- 슬로우 쿼리 로그나 Performance Schema(MySQL 기준)를 활용해 지속적으로 추적해야 합니다.
- 예를 들어, 슬로우 쿼리 비율이 급격히 상승하고, 특정 쿼리에서 Table Scan이 지속적으로 발생하고 있다면 인덱스 튜닝 또는 파티셔닝을 검토할 시점입니다.
Connection Pool 사용량 및 대기 시간
- DB 커넥션 풀의 사용량이 포화 상태라면 앱 서버가 커넥션을 얻기 위해 대기하게 되고, 이로 인해 전체 응답 지연이 발생합니다.
- 대기 시간이 길어진다면 커넥션 풀 크기를 늘리거나, 쿼리를 최적화하여 커넥션 점유 시간을 줄이는 개선이 필요합니다.
- 예를 들어, 외부 API 응답을 기다리는 동안 DB 커넥션을 점유하고 있다면 비동기 처리로 전환하는 것이 효과적일 수 있습니다.
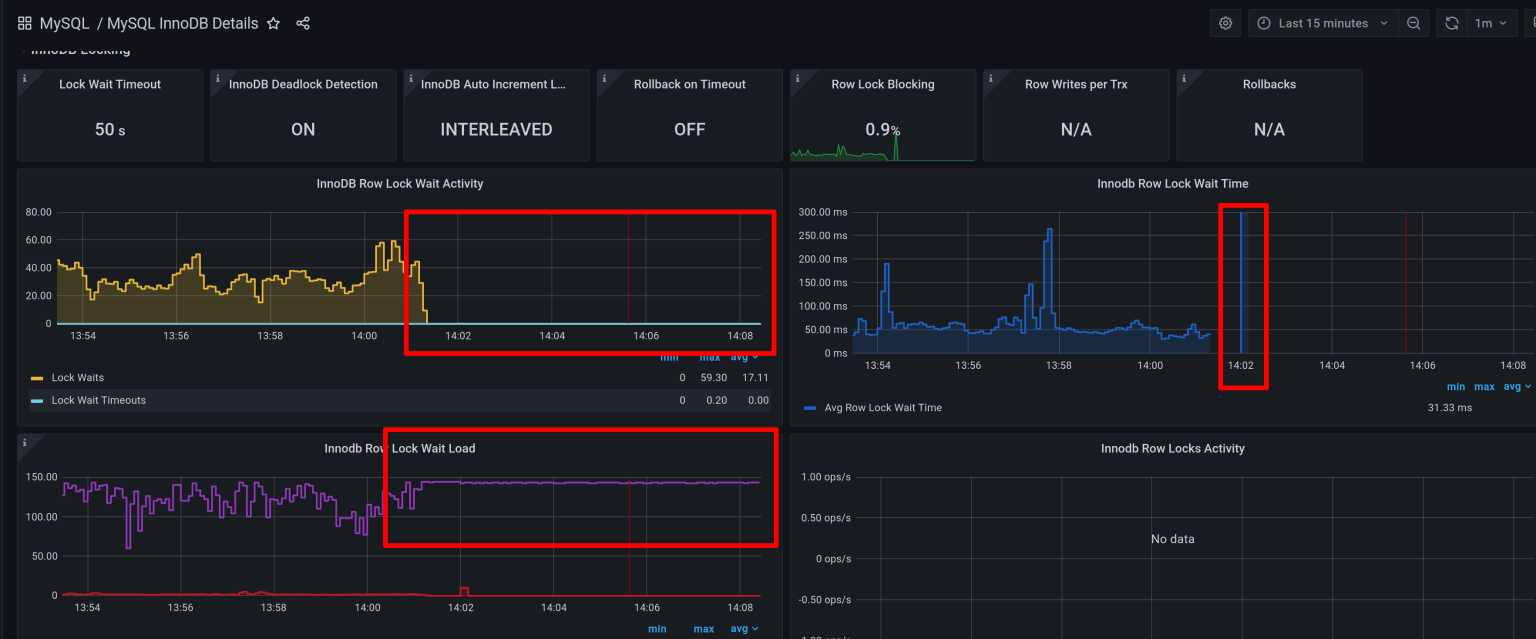
락 경합 및 Deadlock 발생 수
- InnoDB Row Lock Waits가 과도하게 발생하면 동시성 제어에 문제가 있음을 의미합니다.
- 락이 많이 걸리는 경우 인덱스 설계를 다시 검토하거나, 트랜잭션을 더 작은 단위로 나눠야 할 수도 있습니다.
- 예를 들어, 재고 수량 업데이트 쿼리에서 Deadlock이 반복된다면, 재고 테이블을 별도로 분리하고, 업데이트를 큐로 비동기 처리하는 방식이 해결책이 될 수 있습니다.
3. 핵심 지표 기반 최적화 프로세스
이제 지표를 바탕으로 한 최적화 프로세스를 다시 정리해보겠습니다.
1. 지표 수집 및 시각화
- Prometheus + Grafana, CloudWatch, Datadog, NewRelic 등 모니터링 도구를 활용합니다.
- DB 내부 메트릭도 반드시 연동합니다.
- MySQL: Performance Schema
- PostgreSQL: pg_stat_statements
- 수집된 지표는 대시보드로 시각화하여 팀 전체가 동일한 상황을 인지할 수 있도록 합니다.
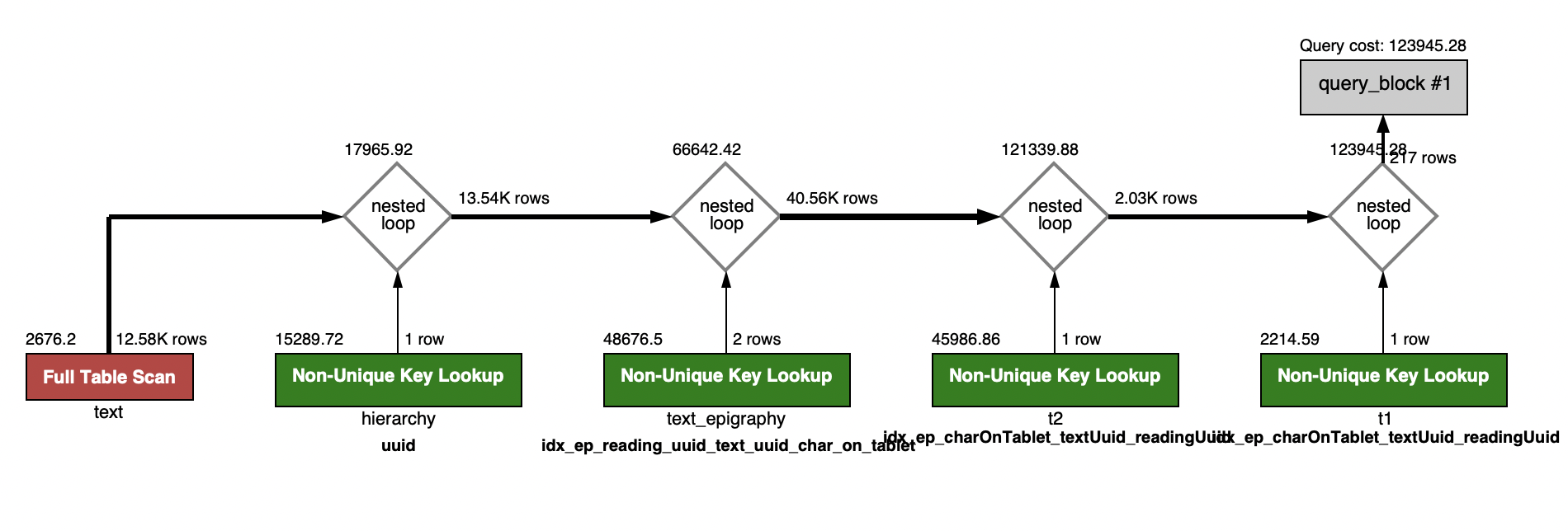
2. 병목 진단 및 인과 분석
- 어떤 지표가 악화되었는지 파악하고, 그 원인을 분석합니다.
- 예를 들어, TPS가 증가했지만 P99 응답 시간이 급격히 나빠졌다면 인덱스를 타지 않는 쿼리가 다수 발생하고 있을 가능성이 있습니다.
EXPLAIN명령어를 이용하여 쿼리 실행 계획을 생성하고 어떤 쿼리가 어떤 인덱스를 사용하여 탐색되는지를 파악합니다.
3. 개선 액션 정의 및 실행
- 원인을 확인한 후 구체적인 개선 방법을 정리합니다.
- 인덱스 추가
- 쿼리 리팩토링
- 테이블 파티셔닝
- 캐시 구조 변경
4. 지표 개선 여부 검증
- 최적화 작업 이후 핵심 지표가 실제로 개선되었는지 검증합니다.
- North Star 지표가 개선되지 않았다면, 튜닝은 실패한 것으로 간주하고 원인 재분석이 필요합니다.
마치며
아직 저는 실무에서 직접 쿼리 튜닝을 수행해본 경험이 많지 않고, 쿼리 최적화에 대한 이해도 역시 부족한 편입니다. 그럼에도 이번에 정리한 내용을 통해 쿼리 튜닝을 언제, 어떤 기준으로 실행해야 하는지에 대한 원칙과, 최적화 과정에서 집중해야 할 핵심 지표들을 명확히 이해하게 되었다는 점에서 큰 의미가 있었다고 생각합니다.
다음에는 실제 트래픽 환경에서 발생한 문제와, 그것을 어떻게 진단하고 해결했는지에 대한 구체적인 사례를 바탕으로 이야기를 풀어보고 싶습니다. 실무 경험을 통해 쌓은 인사이트를 더해, 보다 현실적이고 깊이 있는 내용을 전달할 수 있기를 기대하고 있습니다.
References

재미있는 글 잘 읽었습니다.