
들어가며
소프트웨어를 사용하고, 서비스하는 곳이라면 장애는 언젠가 반드시 맞닥뜨릴 위기입니다. 트래픽 규모가 크고 연관 서비스가 많은 복잡한 서비스일수록 장애는 여러 포인트에서 발생합니다. 이번 글에서는 팀에서 장애를 파악하고 이를 어떻게 대응했는지와, 재발 방지를 위해 장애 회고를 도입한 경험을 공유합니다.
사례로 보는 장애 처리 프로세스
장애 탐지
팀에서는 Slack Alert나 Grafana 등의 모니터링 툴로 장애를 탐지하고 있습니다. 아직 초기 팀인지라 모든 장애 포인트를 관리할 수는 없어서 User Request로 장애 보고를 파악하는 경우도 많습니다.
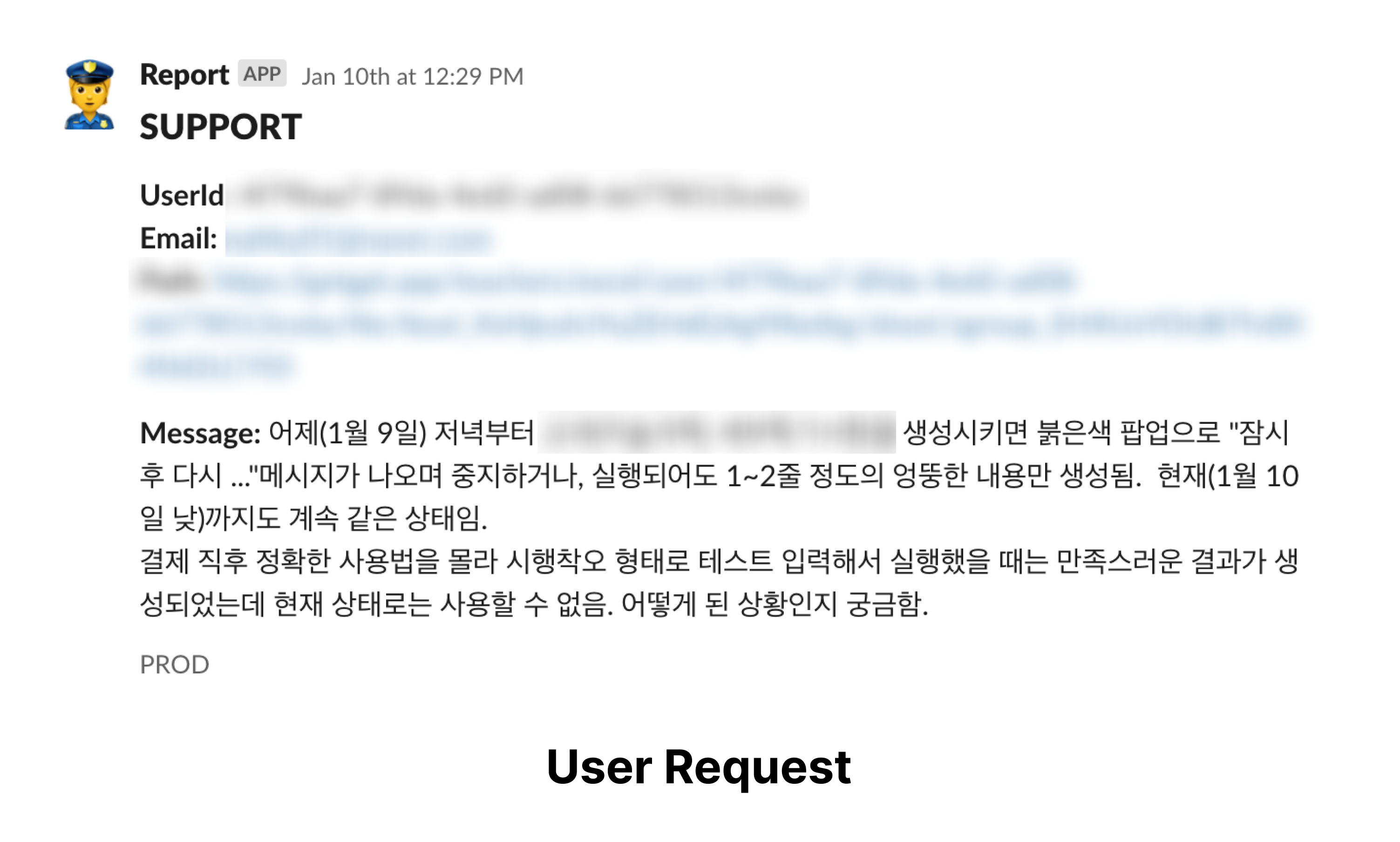
저희 팀은 User Request로 장애를 파악했습니다. 다행히 서비스 특성상 비수기였지만 전체 서비스에 있어서 중요한 기능의 장애인지라 급하게 대응을 시작했습니다.
장애 전파
장애를 탐지하게 되면, 장애 사실을 먼저 전사적(스타트업 규모)으로 공유합니다. 장애 전파는 장애를 해결하기 위해서 매우 중요한 일입니다. 가용 인력이 함께 대응 할 수 있고, 기술적인 해결 뿐만 아니라 운영적인 대응으로도 충격을 완화할 수 있기 때문입니다. 장애를 마주하면 자체적으로 해결하려다 전파도, 해결도 늦어지는 경우가 있을 수 있으므로 장애 전파의 중요성은 아무리 강조해도 지나치지 않습니다.
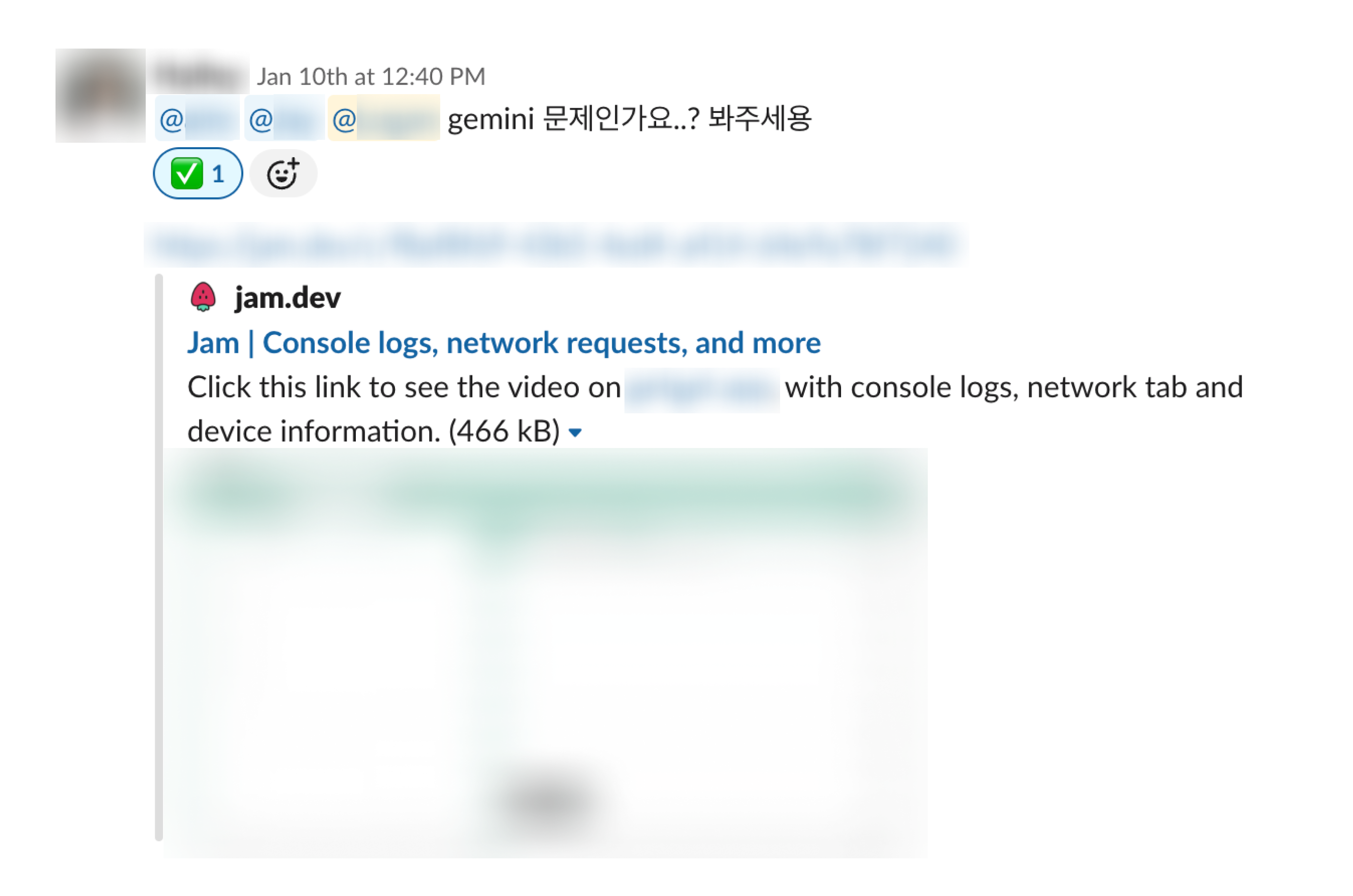
저희는 PM께서 User Request에서 장애를 확인하고, 유관 엔지니어들을 mention하여 문제를 인지했습니다.
저희는 Jam이라는 캡처 Extension으로 장애를 재현하고 공유하는데요. Network와 Console 정보까지 함께 저장해주어 엔지니어들이 정보를 파악하기에 유리합니다.
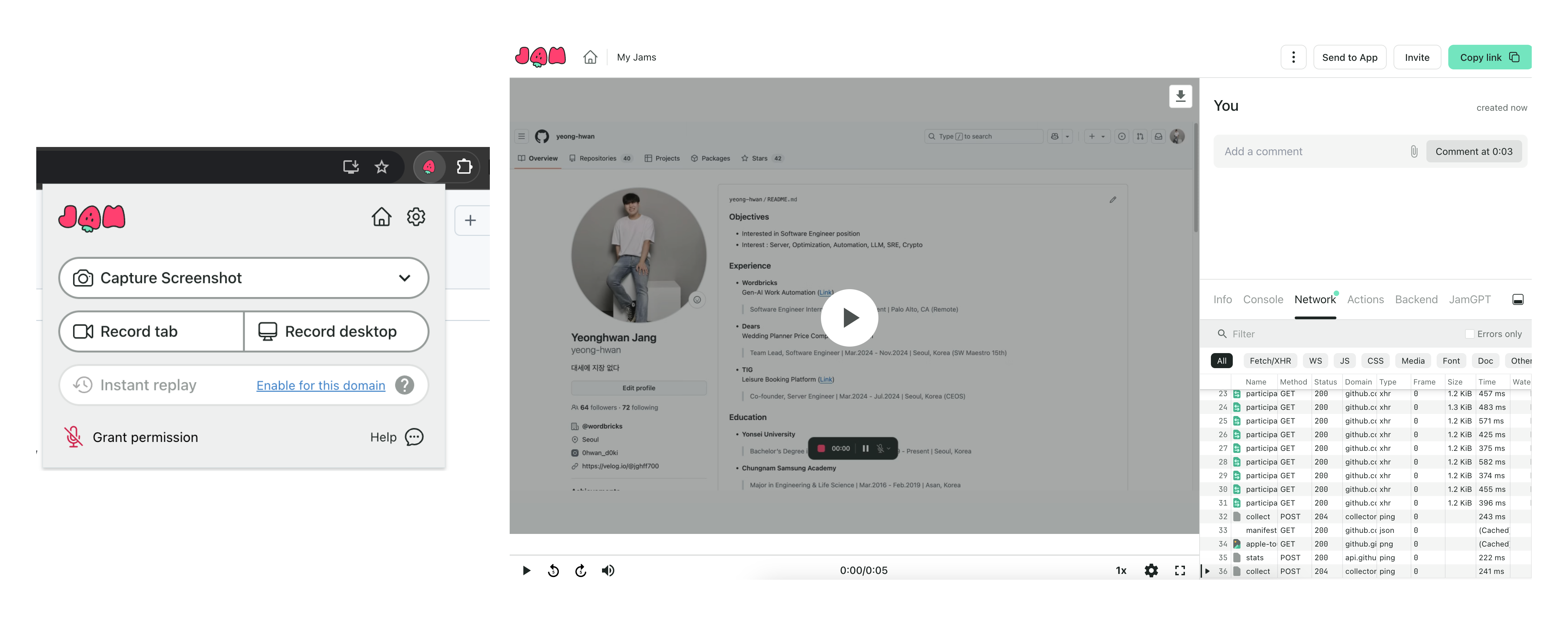
장애 해결
장애 전파와 동시에 장애의 지속/확산을 막기 시작합니다. 이 때 장애를 전파하는 사람과 장애를 해결하는 사람이 가능하면 나누어져 있는 것이 좋다고 합니다. 장애를 전파하는 것과 장애의 원인을 파악하고 분석하는 작업을 한 사람이 수행하는 것이 매우 힘들고, 대응 골든타임을 놓치기 때문입니다.
아래는 빠르게 장애를 해결하기 위한 대표적인 대응법들 입니다.
1. Rollback
보통 가장 널리 쓰이는 방법입니다. 이 때 롤백 가능여부와 적절한 moment to rollback 을 판단하는 것이 중요한데요. 릴리즈 된 내용에 ERD 스키마 변경이 있거나 실시간 트랜잭션이 포함된 경우는 롤백이 어렵거나 더 큰 문제가 발생할 수 있습니다. 제가 참고한 LINE의 장애 문화 소개 문서에서는, 스키마 변경 등 중요 변경사항이 포함된 PR에는 아래와 같이 can not rollbackable label을 붙인다고 합니다.

2. Reboot
순간적으로 트래픽이 튀어서 메모리, 스레드, 네트워크 등 리소스가 부족한 경우에 주로 사용하는 방법입니다. 임시방편이기도 하고, 대규모 서비스에는 적합하지 않은 방식입니다.
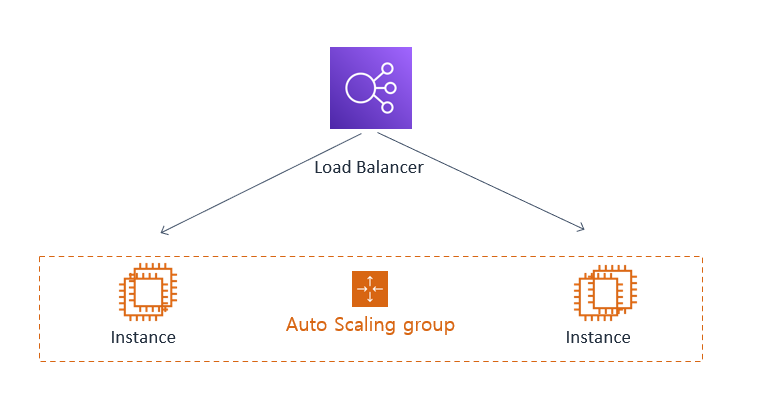
3. Scale-Out
트래픽이 예상보다 많이 발생하는 경우에 필요한 대응책입니다. 사전에 scale-out이 쉬운 구조를 만들어 놓아야 하며, 자동화해두는 것이 좋습니다. 코드를 수정해서 배포하는 방식으로 증설이 된다면, 휴먼 에러로 인해 연쇄 장애가 발생할 수 있기 때문입니다. 클라우드 서비스의 Auto-Scaling이 자동화 scale-out의 좋은 예시일 수 있습니다.
4. Hot-fix
문제를 수정한 버전을 배포하는 방법입니다. Rollback과 Reboot가 쉽지않은 클라이언트에서 문제가 발생했을 때 많이 사용하며, 서버의 경우에도 소규모 팀에서는 빠르게 대응하기 위해 자주 채택하곤 합니다.
장애 보고 및 회고
장애 대응이 어느 정도 완료되면, 장애 보고 템플릿을 이용해서 장애 보고서를 작성합니다.
장애 회고는 특히 문서화가 매우 중요하다고 생각합니다. (운영)매니저 레벨에서는 상황을 정확히 파악하기 위해 추가적인 확인 요청이 있을 가능성이 높은데요. 그럴 때일수록 문서를 통해 현재 상황을 알리되, 최대한 사실을 기반으로 보고하는 것이 중요하다고 생각합니다.
장애 대응이 완전히 마무리되지 않은 상황에서 개인이 이해관계자들을 대변하여 원인과 책임을 말하기도 어렵기 때문에, 장애 회고를 통한 사실 기반의 보고가 중요한 것 같습니다.
장애 회고 문서화
구조
- Iron rule
- Summary
- Troubleshooting
- Review
이번에 팀의 장애회고 문서를 만들며, 큰 구조는 위와 같이 구분했습니다. 순서대로 자세한 섹션을 설명해보겠습니다.
Iron Rule

먼저 회고 문서 최상단에는 Iron Rule을 명시해두었는데요. 문제의 본질을 해결하기 위한 하나의 가이드라인이라고 보시면 될 것 같습니다. 성숙하게 장애를 해결하고 재발을 방지하기 위해서 중요하다고 생각되는 가치들을 넣어두었습니다.
Summary
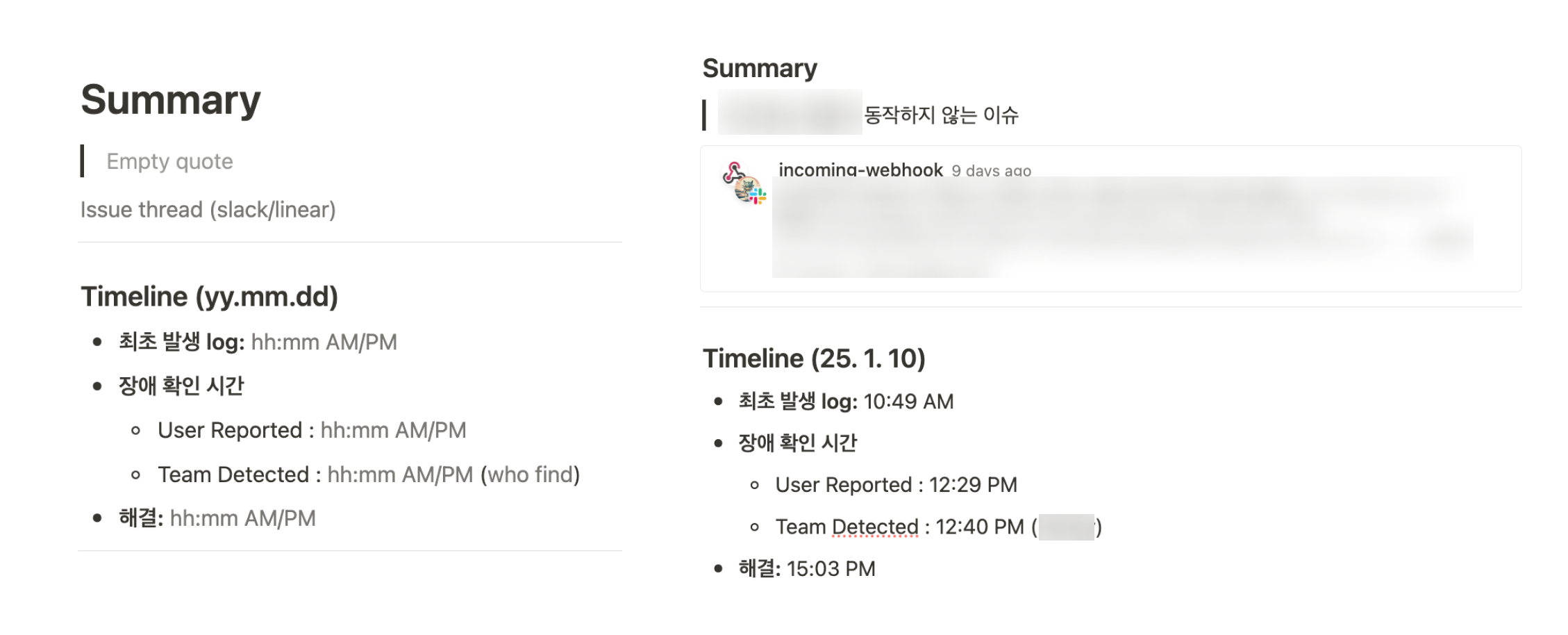
Summary Section에서는 간단하게 어떤 장애가 발생했는지와, 관련된 Timeline을 적습니다. 또한 이슈 스레드란을 만들어서 어떤 문제가 발생했는지 일일이 적기 보다는, 빠르게 관련 스레드를 embed하도록 유도했습니다.
Troubleshooting

Troubleshooting 파트는 제가 생각하기에 장애 회고의 문서에서 가장 중요한 문단인데요. 발생한 장애의 이유, 해결책, 배운 점들을 기록하는 파트입니다.
원인과 해결책은 직관적으로 작성하면 되지만, Lessons Learned 파트에서는 이 문제가 발생한 근원적인 문제가 있었는지를 파악하는 것이 중요합니다. 잘 해결하는 것도 좋지만, 문제가 발생하지 않는 것이 가장 이상적이니까요. 그래서 장애 원인이 휴먼에러일지라도, 시스템 상으로 휴먼에러를 방지할 수 있는 방법을 함께 고민하는 것이 중요합니다.
저희 팀의 경우, 에러 노티 웹훅이 무분별하게 발송되는 문제가 있었습니다. 이는 특정 서비스의 critical한 에러와 일반적인 에러를 함께 로깅하면서, 사전에 장애를 파악하지 못했던 것이 원인이었습니다.
이에 따라, 에러를 레벨별로 분리하고 웹훅 채널도 각각 분리하는 방식으로 장애 재발을 방지하기로 논의했습니다.
Review

Review 파트에서는 좋았던 점과 아쉬웠던 점을 적었는데요. 이해관계자들이 솔직하게 적어주는 것이 팀을 위한 일이기 때문에, 최대한 나이브하게 개선 포인트를 논의하는 것이 좋은 방향인 것 같습니다.
마치며
장애는 발생했다는 사실보다, 장애에 어떻게 대응하고 그 후속 처리를 어떻게 하느냐가 더 중요하다고 생각합니다. 엔지니어가 계속 새로운 일을 시도하고 작업을 진행하는 한, 장애는 발생할 수밖에 없습니다. 장애가 전혀 발생하지 않는다면, 이는 오히려 아무것도 시도하지 않고 있다는 뜻일지도 모릅니다. 하지만 장애가 발생했을 때 책임을 추궁하는 문화가 자리 잡으면, 사람들은 새로운 기술을 도입하거나 도전적인 시도를 꺼리게 되고, 이는 위축된 운영과 혁신의 부재로 이어질 수 있습니다.
특히 장애가 인재로 인해 발생하는 경우도 적지 않은데요. 사람의 실수를 사전에 방지할 수 있는 시스템적 방법을 고민하거나, 새로운 사람이 같은 실수를 반복하지 않도록 개선하는 것이 중요합니다. 또한, 장애를 숨기지 않고 적극적으로 드러내어 공유하고 회고하는 문화는 큰 장점으로 작용합니다. 이를 통해 팀원들 간에 상호 협력이 이루어지고, 다른 팀의 시니어 엔지니어로부터 아이디어나 직접적인 도움을 받아 문제를 해결할 수 있는 기회가 생깁니다. 때로는 이 과정에서 획기적인 아이디어가 나와 장애 해결에 큰 도움이 되기도 합니다. 이러한 문화는 장애를 단순히 문제로 여기기보다 성장과 개선의 기회로 전환시킬 수 있다는 점에서 매우 가치 있다고 생각합니다.
References

장애 보고서 템플릿 잘 사용해보겠습니다. 감사합니다~