Token Gradient Descent를 이용한 LLM 글자수 조절

도입 배경
팀에서는 LLM을 이용해서 몇 개의 단어만으로 유저들이 원하는 답변을 생성해주는 서비스를 제공하고 있습니다.
(ex. 용사, 음식 등의 키워드를 입력하면 음식을 먹어야만 싸울 수 있는 용사를 주제로 판타지 소설을 작성)
저희는 서비스 특성상 유저가 필요로 하는 글자수가 고정된 상황입니다. 이러한 글자수에 맞추어 데이터셋을 만들고, 이를 바탕으로 파인튜닝하기로 결정했습니다. 예를 들어 유저가 1000 byte의 결과물을 원한다면 950~1000B 길이의 데이터셋으로 학습된 모델을 연결하는 방식입니다.
오늘은 이렇게 고정된 길이의 데이터셋을 만들기 위해 제가 어떻게 데이터셋의 길이를 LLM으로 조절했는지 설명해보려 합니다.
LLM은 글자수를 세지 못 한다?
LLM은 글자수와 관련된 작업에 취약합니다. 아래 예시를 볼까요?

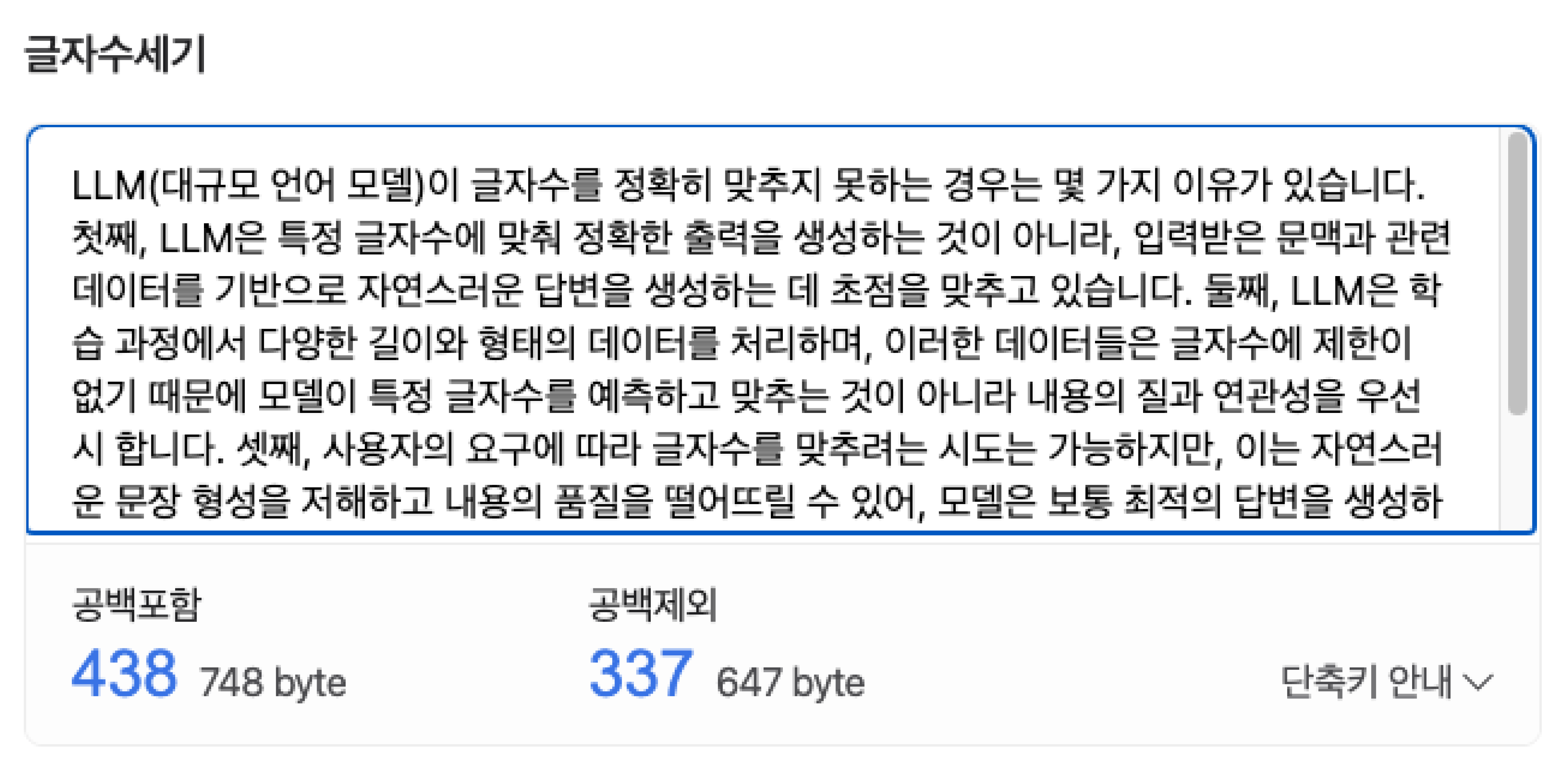
보시다시피 LLM은 글자수를 고려하여 생성하지도, 생성된 텍스트가 실제로 몇 글자인지 구분하지도 못합니다.
LLM은 Token이라는 단위로 텍스트를 이해하기 때문입니다.
Token
컴퓨터는 모든 데이터를 숫자로 표현합니다. 이를 위해, 인간의 자연어를 컴퓨터가 이해할 수 있는 형태로 변환하는 과정이 필요합니다. 일반적인 예로, 각 문자를 숫자에 매핑하는 ASCII 방식이 널리 알려져 있습니다. 이 방식에서는 각 문자가 고유한 숫자 코드로 표현됩니다.
LLM에서는 Token이라는 단위로 데이터를 이해하고 표현합니다. 이 토큰들은 텍스트의 기본적인 의미 단위(예: 단어, 구, 특정 문자 조합)를 나타내며, 각 토큰은 숫자 인덱스에 매핑되어 모델 내부의 벡터로 변환됩니다. 이 과정을 Token Embedding이라고 하며, 각 토큰은 고차원 벡터 공간에서 수치적인 벡터로 표현됩니다. 이 벡터는 해당 토큰의 의미적, 문맥적 특성을 모델이 이해할 수 있는 형태로 인코딩합니다. 이 때 수치 벡터는 토큰의 문맥에 따라 동적으로 조정되어, 문맥에 맞춰 유연하게 저장됩니다.
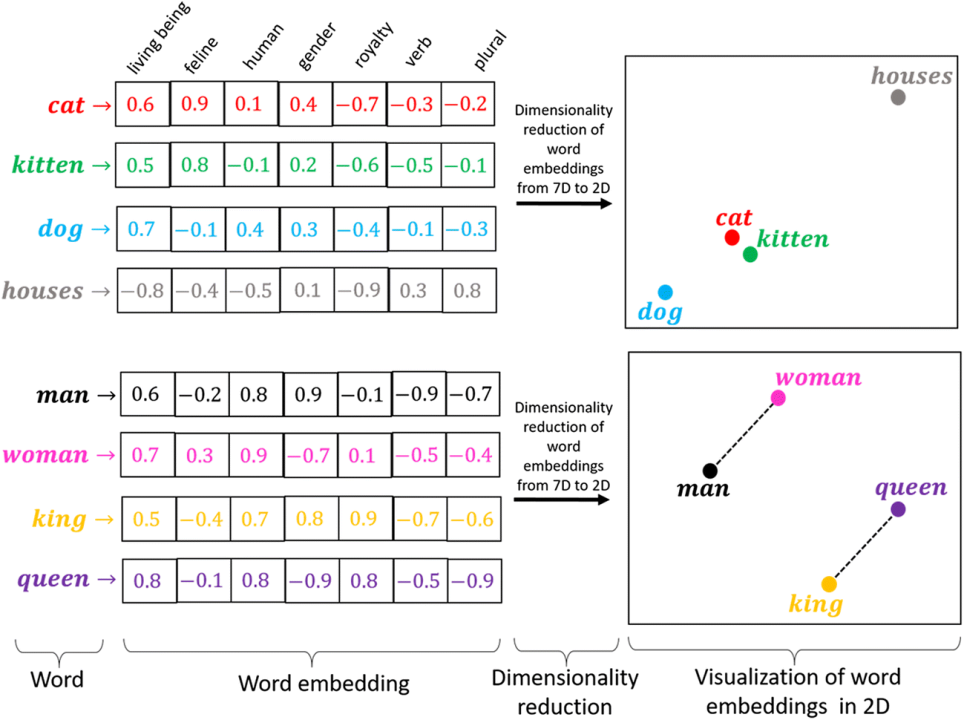
위와 같이 다양한 변수(human, gender 등)마다 다르게 가중치를 부여하여 변수 갯수 만큼의 다차원 공간에서 각자의 영역을 차지한다고 이해하면 됩니다.
Tokenization
LLM에서 사용하는 토큰화(tokenization)는 텍스트를 미리 정의된 작은 조각인 'token'으로 나누는 과정입니다. 이 토큰들은 앞서 말했듯 모델이 학습하고, 텍스트를 생성할 때 사용하는 기본 단위입니다. 예를 들어, "It is raining"라는 문장을 토큰화하면, 각 글자나 음절 또는 단어가 각기 다른 토큰으로 분리될 수 있습니다.

LLM에서 사용하는 토큰화 기준은 언어나 모델에 따라 다를 수 있습니다. 위와 같이 character, word, sub-word 등 다양한 기준에 따라 토큰화 방식은 다르게 적용될 수 있습니다.

GPT 모델에서 영어는 공백, 대소문자 등의 넓은 범위로 토큰을 구분하지만, 한글은 형태소 단위로 토큰을 구분합니다. 한글은 음절과 음소로 이루어진 조합형 문자체계이기 때문에 이러한 차이가 발생하며, 특정 글자수를 targeting하기 위해서는 이러한 구조적 차이를 고려해주어야 합니다.
Token Gradient Descent
Idea
다시 문제로 돌아와, 우리 서비스에서 생성하는 답변의 글자수를 맞추기 위한 발상은 다음과 같습니다.
- 한글을 바이트로 환산하여 토큰의 개수를 제한하자.
- 토큰의 limit을 gradient descent로 조정하자.
api로 LLM을 호출하면, token limit을 지정하여 답변을 생성할 수 있습니다. 이에 아이디어를 떠올려, 원하는 byte 길이에 도달할 때까지 토큰의 limit을 증감하는 방식을 시도해보려 합니다.
Gradient Descent
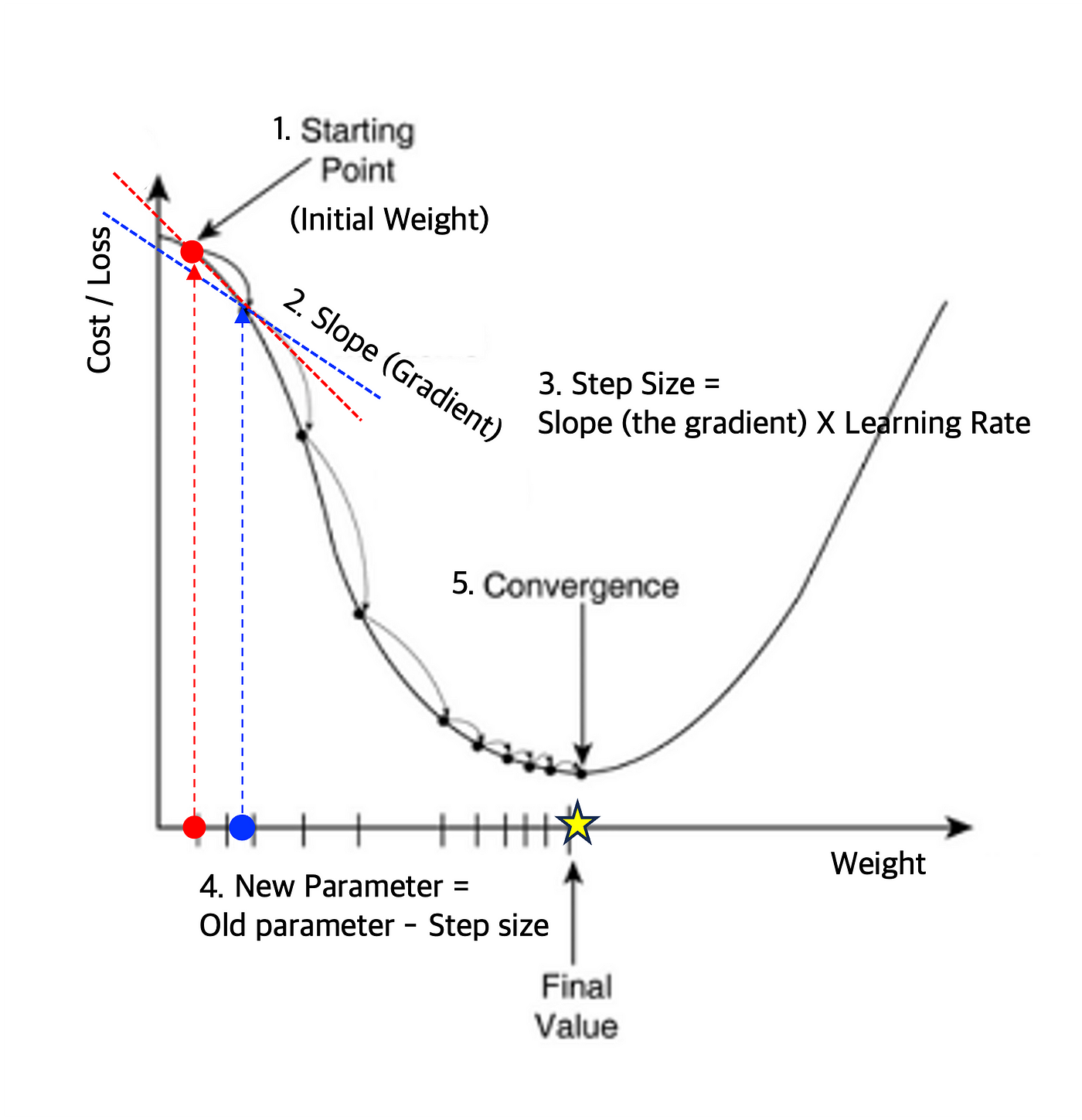
Gradient Descent(경사하강법)은 최적화 문제에서 광범위하게 사용되는 방법 중 하나로, 주로 ML과 DL 모델의 최소 오차를 찾는 기법입니다.
함수의 gradent(기울기 벡터)를 계산하고 그 그래디언트가 가리키는 방향(즉, 함수가 가장 빠르게 증가하는 방향)의 반대 방향으로 일정 크기 만큼 이동하는 과정을 반복하여 함수의 local minimum을 찾습니다. 이 때 이동 거리는 LR(Learing Rate)라고 하는 파라미터로 조정됩니다.
Consideration
- 한글을 바이트로 환산하여 토큰의 개수를 제한하자.
- 토큰의 limit을 gradient descent로 조정하자.
앞서 말했던 2가지 발상에는 다음과 같은 단점 및 고려사항이 있습니다.
먼저, 바이트 기반 처리는 언어적 맥락을 무시하여, 단어나 문장이 중간에 잘리는 현상이 발생할 수 있습니다. 하지만 저희 팀의 서비스는 상호결합도가 낮은 짧은 문장 여러개로 이루어진 output을 생성해주기 때문에, 마지막 방점을 기준으로 잘린 문장은 절삭하는 방법을 채택했습니다.
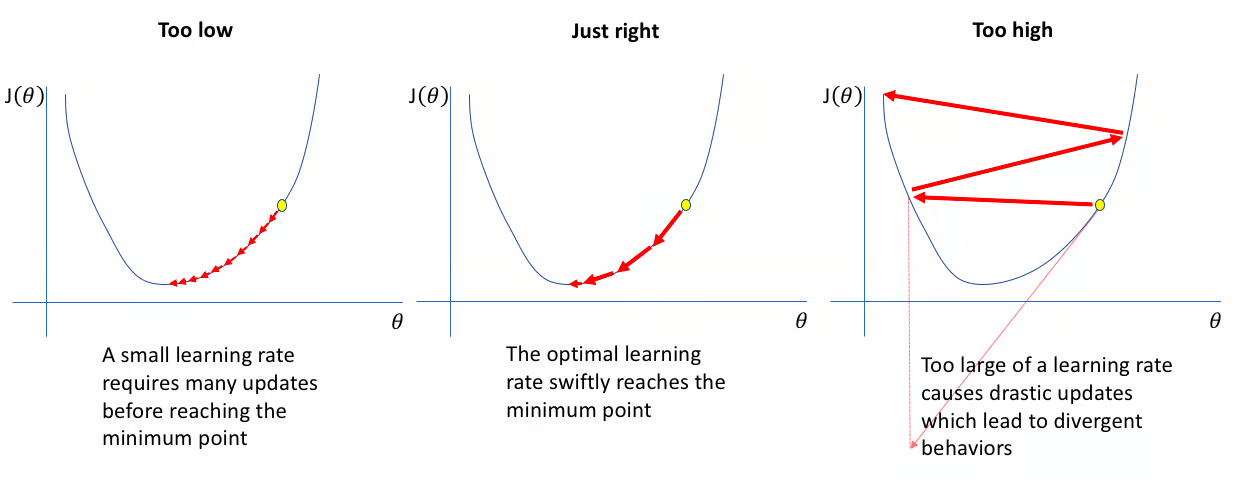
또한 gradient descent의 경우 LR 선택의 문제가 있습니다.
먼저 위 사진의 Too low 같이 학습률이 너무 낮을 때, 매개변수 업데이트 속도가 느려져, 최적화 과정이 길어질 수 있습니다. 반면 Too high 경우와 같이 학습률이 과도하게 높으면, 매개변수가 최소값을 지나칠 수 있습니다.
저는 2~3번의 API call 안에 적합한 글자수를 맞출 수 있도록 적절한 LR을 선택해야 했습니다.
구현
Preperation
환경변수 설정
OPENAI_API_KEY="openai_api_key"
INPUT_FILE_PATH="path/to/input.jsonl"
OUTPUT_FILE_PATH="path/to/output.csv"
# 목표 글자수
START_INDEX=1
TARGET_BYTES_MIN=1000
TARGET_BYTES_MAX=1500
TARGET_BYTES_STEP=100
# 병렬처리
MAX_WORKERS=50
BATCH_SIZE=50dotenv 라이브러리를 사용하여, .env 파일에서 환경 변수를 관리합니다.
한글-byte 변환
def analyze_utf8_byte_length(text):
results = {'1bytes': 0, '2bytes': 0, '3bytes': 0, '4bytes': 0}
for char in text:
byte_length = len(char.encode('utf-8'))
results[f'{byte_length}bytes'] += 1
return results
def calculate_total_bytes(byte_dict):
return sum([byte_dict[key] * int(re.search(r'\d+', key).group()) for key in byte_dict])utf-8 유니코드로 인코딩하여 각 bytes 수를 계산하고 sum하여 text의 total_bytes를 구합니다.
Main
def main():
# 환경 변수에서 파라미터 로드
input_file_path = os.getenv('INPUT_FILE_PATH')
output_file_path = os.getenv('OUTPUT_FILE_PATH')
start_index = int(os.getenv('START_INDEX'))
target_bytes_min = int(os.getenv('TARGET_BYTES_MIN'))
target_bytes_max = int(os.getenv('TARGET_BYTES_MAX'))
target_bytes_step = int(os.getenv('TARGET_BYTES_STEP'))
max_workers = int(os.getenv('MAX_WORKERS', 50)) # 기본값 50
batch_size = int(os.getenv('BATCH_SIZE', 50)) # 기본값 50
target_bytes_range = range(target_bytes_min, target_bytes_max, target_bytes_step)
for target_bytes in target_bytes_range:
print(f"\n{'='*80}")
print(f"Processing for target bytes: {target_bytes} (starting from index {start_index})")
print(f"{'='*80}\n")
output_csv_path = output_file_path
try:
process_json_file_to_csv(input_file_path, output_csv_path, target_bytes,
start_index=start_index,
max_workers=max_workers,
batch_size=batch_size)
print(f"\nCompleted processing for {target_bytes} bytes. Output saved to {output_csv_path}")
except Exception as e:
print(f"Error processing {target_bytes} bytes: {e}")
if __name__ == "__main__":
main()
프로그램을 실행하게 되면, main에서 환경변수를 불러오고 이후 process_json_file_to_csv 를 실행합니다. process_json_file_to_csv 는 json 형태의 raw-dataset을 cleaning하고 병렬로 Openai API call을 날리는 작업을 수행합니다.
Multi-threading vs Asyncronous
지금 알고리즘은 타겟 글자수를 향해 2~3번 loop를 돌려 글자수를 조정하는 api를 보낸다 입니다. 이러한 방식을 하나의 input에 대해서 실행하면 평균 15초의 시간을 소요합니다. 저희는 매우 많은 경우에 대해서 각각 2,000건의 데이터셋을 작업해야 했는데, 순차적으로 실행하게 되면 하나의 경우에만 7~10 시간이 소요됩니다. 때문에 성능 개선을 고려해야 할 때였습니다.
현재 알고리즘은 Oepnai API call이 main인 I/O bound Job입니다. 때문에 CPU가 처리하는 작업은 상대적으로 매우 가볍기 때문에, 이를 효율적으로 처리하고자 Non-blocking I/O 방식을 적용하려 했습니다.
보통 Non-blocking I/O를 구현할 때, Multi-threading 과 Asynchronous Programming 방식을 고려하게 됩니다.
보통 대규모 분량을 처리할 때는 비동기가 적합하지만, 저는 다음과 같은 이유로 Multi-threading을 선택했습니다.
- API Rate Limit이 있어, 분당 처리율은 상한이 있었다.
- 빠르게 구현하고 직관적으로 코드를 구성해야 한다.
저는 멀티스레딩 환경에서 Lock 등의 동시성 처리 경험이 있었기에, 분당 처리율 상한이 고정된 상황에서 더 빠르고 직관적으로 구현할 수 있는 방법을 선택했습니다.
GIL
파이썬에는 GIL(Global Interpreter Lock)이라는 특징이 존재합니다. GIL은 파이썬이 실행될 때 여러개의 스레드 중 하나의 스레드만 실행될 수 있도록 하는 mutex 인데요. mutex는 공유자원에 대한 lock이 때문에, 당장은 멀티스레딩이 무의미하다고 느껴질 수 있습니다.
그러나 GIL은 cpu 동작에서만 적용되기 때문에, I/O bound인 외부 API 호출은 GIL의 영향이 미미하다고 판단했습니다.
Multi-threading
제 개인 맥북인 M2 Pro 애플실리콘에서 최대로 실행 가능한 스레드 개수는 수만개(M1 기준 25,000 개)입니다. 하지만 저희 API의 TPM(Tokens Per Minute)이 3백만 정도였기 때문에, 스레드를 150~200개 설정하는 것이 적합했습니다.
스레드 수가 250개를 넘어가면 target_output이 작은 경우, TPM limit을 넘어가는 경우가 있었습니다.
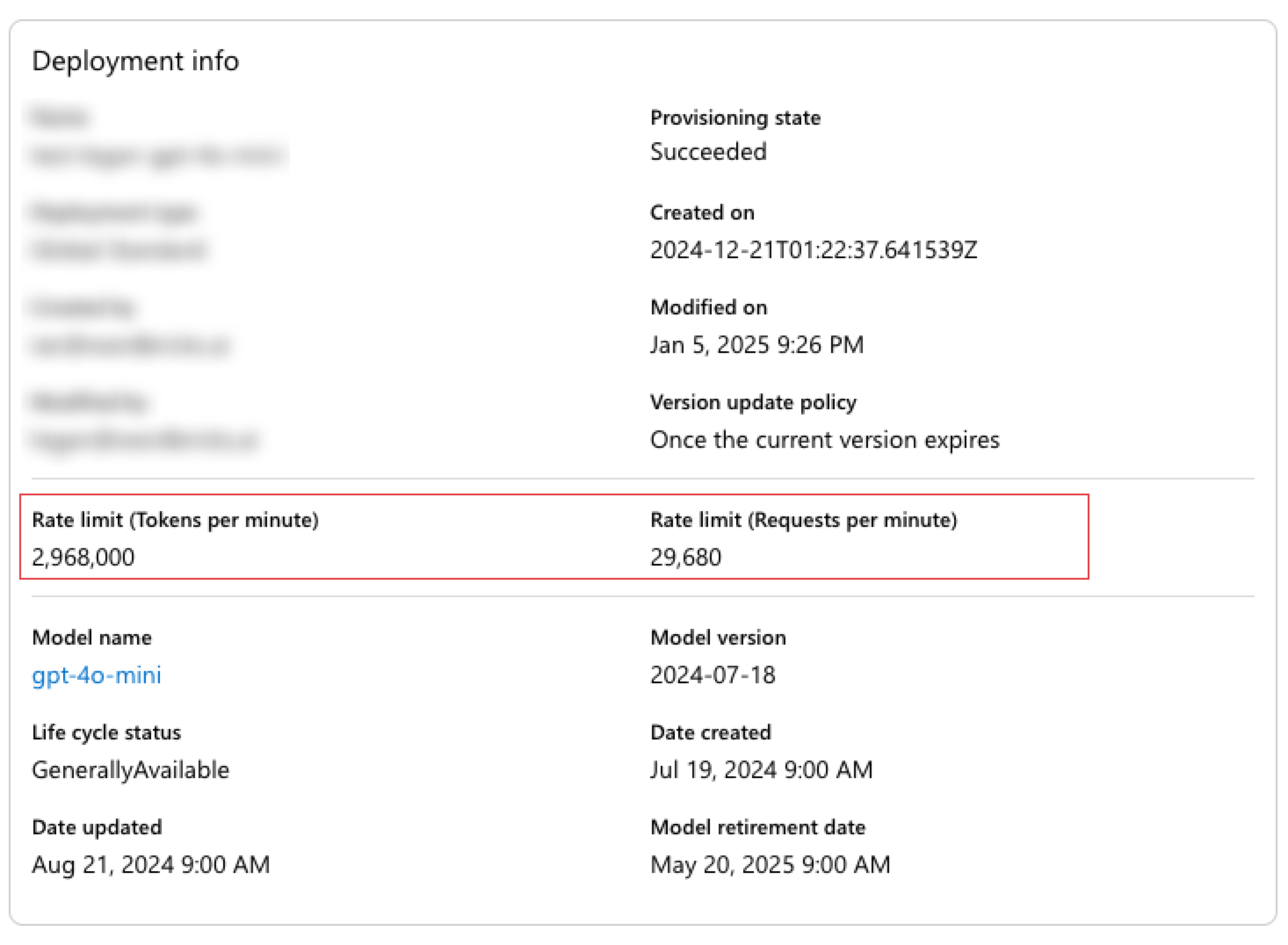
ThreadPool Worker 설정
보통 일반적인 경우는 워커 수가 스레드 수보다 적거나 같습니다. 워커는 하나의 스레드를 점유하거나 스레드풀 내에서 스레드를 요청해 작업을 처리하기 때문인데요.
Non-blocking I/O 상황에서는 한 스레드가 여러 워커의 작업 요청을 관리할 수 있습니다. 예를 들어, 하나의 스레드가 하는 2가지 작업(API call, DB I/O)을 2개의 워커가 분담하는 방식입니다.
보통 워커는 아래 기준을 참고하여 설정하는데요.
CPU-Bound 작업: CPU 코어 수와 비슷하게 설정 (코어 수 + 1).
I/O-Bound 작업: CPU 코어 수의 2~4배 이상.
Non-blocking I/O 기반: 더 많은 워커를 설정해도 괜찮으나, 부하 테스트 필요.
저는 2배 이후에는 성능 향상을 확인하지 못 하여, 200개의 스레드에 대해서 2 * 스레드수 + 예비 1개를 계산하여 401개의 워커를 설정했습니다.
Batch
process_json_file_to_csv 메소드는 병렬로 process_single_item을 실행함과 동시에 로그를 쌓아서 출력하는 함수입니다.
def process_json_file_to_csv(file_path, output_csv_path, target_bytes, start_index=1, max_workers=50, batch_size=50):
global print_lock, csv_lock
print_lock = Lock()
csv_lock = Lock()
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
all_results = []
log_messages = {}
# start_index부터 시작하도록 데이터 슬라이싱
data = data[start_index-1:]먼저 병렬 처리를 위한 lock을 설정해줍니다. print lock은 한 번의 batch job을 수행하고 print 로그를 정렬해서 출력하기 위함이고, csv lock은 api로 수신한 output을 호출 순서대로 csv 파일에 저장하기 위해 존재합니다.
# process_json_file_to_csv
# ... continue
for i in range(0, len(data), batch_size):
batch = data[i:i+batch_size]
batch_results = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_item = {
executor.submit(process_with_retry, item, target_bytes, idx): (idx, item)
for idx, item in enumerate(batch, start=start_index+i) # 시작 인덱스 조정
}
for future in as_completed(future_to_item):
try:
result = future.result()
batch_results.append(result)
# 로그 메시지를 딕셔너리에 저장
index = int(result['index'])
log_msg = (
f"Item #{index:03d} | "
f"Target: {target_bytes:4d}B | "
f"Original: {result['original_bytes']:4d}B | "
f"Final: {result['final_bytes']:4d}B | "
f"Time: {result['elapsed_time']:.2f}s"
)
log_messages[index] = log_msg
except Exception as e:
with print_lock:
print(f"작업 처리 중 오류 발생: {e}")
이후 batch_size를 step으로 데이터를 순회하며 병렬로 process_with_retry를 실행합니다. 이 때 process_with_retry는 api rate limit이나 call fail case에 대응하기 위해 성공할 때까지 반복하는 메소드입니다.
# process_json_file_to_csv
# ... continue
# 배치 결과 정렬
batch_results.sort(key=lambda x: int(x['index']))
# 배치 단위로 CSV 파일에 추가
with open(output_csv_path, 'a', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
for result in batch_results:
csvwriter.writerow([result['original'], result['summary']])
# 현재까지 처리된 모든 로그를 정렬하여 출력
with print_lock:
# 이전 출력 지우기
print("\033[2J\033[H") # 화면 지우기
print("\n" + "=" * 80)
print(f"Processing for target bytes: {target_bytes}")
print("=" * 80 + "\n")
# 정렬된 순서로 출력
for idx in sorted(log_messages.keys()):
print(log_messages[idx])
print("-" * 60)
time.sleep(2)작업이 완료되면 lock을 이용하여 정렬된 배치 결과를 쌓아주고 csv파일에 저장 및 출력합니다.
Exponential Backoff
def process_with_retry(item, target_bytes, index, max_retries=3, base_delay=1):
for attempt in range(max_retries):
try:
return process_single_item(item, target_bytes, index)
except Exception as e:
if "rate_limit" in str(e).lower():
# rate limit 오류일 경우 더 긴 대기 시간 적용
delay = base_delay * (4 ** attempt) + random.uniform(0, 2)
with print_lock:
print(f"Rate limit hit on item #{index}. Waiting {delay:.2f}s before retry...")
time.sleep(delay)
else:
delay = base_delay * (2 ** attempt) + random.uniform(0, 1)
time.sleep(delay)
if attempt == max_retries - 1:
with print_lock:
print(f"Failed after {max_retries} attempts for item #{index}: {e}")
raise e앞서 소개했듯, process_with_retry는 api rate limit이나 call fail case에 대응하기 위해 try-catch로 process_single_item을 감싼 메소드입니다.
delay를 재산정 하는 부분을 보시면 2 ** attempt, 4 ** attempt 등을 사용하여 대기시간을 조정하는 방식으로 코드레벨에서 구현되어 있는데, 이를 지수 백오프(exponential backoff) 전략 이라고 합니다. 지수 백오프 전략은 네트워크 요청이나 API 호출 시 일시적인 오류나 과부하 문제를 효과적으로 처리할 수 있는 방법으로, 다음과 같은 이점을 가집니다.
-
서버 회복 시간 유예: 첫 번째 재시도 실패 후 짧은 대기 시간을 가지고, 실패가 계속될 경우 대기 시간을 지수적으로 증가시킵니다. 이렇게 함으로써 서버에 대한 부하를 점차적으로 줄이고, 서버가 회복할 수 있는 시간을 제공합니다.
-
네트워크 트래픽 분산: 여러 클라이언트 또는 애플리케이션이 서버에 접근할 때, 각각의 클라이언트가 실패 후 재시도하는 시간이 다르게 설정되어 네트워크 트래픽이 일시에 집중되는 것을 방지합니다.
-
서버의 잠재적 오류 대응: 서버가 일시적으로 응답하지 않거나 요청 처리에 실패할 경우, 즉시 재시도하는 대신 점차적으로 시간 간격을 늘려가며 재시도하여 서버에 계속되는 고부하를 주지 않습니다.
if "rate_limit" in str(e).lower():
# rate limit 오류일 경우 더 긴 대기 시간 적용
delay = base_delay * (4 ** attempt) + random.uniform(0, 2) 해당 code block에서 보듯, API가 rate_limit으로 인해 오류가 발생하면, 재시도 간 대기시간을 지수적으로 증가시키며 random 함수로 대기 시간에 작은 무작위성을 추가하여 client 간의 재시도 간격을 분산시킵니다.
Reduction Ratio Recalculation
드디어 gradient descent에서 착안한, 증감량을 조정하는 부분입니다.
def summarize_to_target_bytes(input_text, target_bytes, max_retries=2):
adjusted_text = input_text
retries = 0
start_time = time.time()
byte_dict = analyze_utf8_byte_length(adjusted_text)
current_length = calculate_total_bytes(byte_dict)
reduction_ratio = target_bytes / current_length
while retries < max_retries:
byte_dict = analyze_utf8_byte_length(adjusted_text)
current_length = calculate_total_bytes(byte_dict)
if retries == 0:
pass
elif current_length > target_bytes:
reduction_ratio *= 0.9 # 목표보다 길 때는 10% 감소
elif current_length < target_bytes:
reduction_ratio *= 1.1 # 목표보다 짧을 때는 10% 증가
try:
adjusted_prompt = (
f"""
이전에 생성된 요약문은 {current_length}자임. 다시 작성해.
반드시 {target_bytes-10}자에서 {target_bytes}자 사이가 되어야 함.
필요하다면 중요도가 낮은 문장은 제거해.
마지막 문장이 중간에 끊기지 않도록 완결된 형태로 작성해.
글자수를 맞추기 위해 마지막 문장을 조정해.
모든 문장의 종결어미는 음슴체로 작성해.
이전 요약문:\n{adjusted_text}
"""
)
adjusted_text = call_openai_api(adjusted_prompt, target_bytes, reduction_ratio)
adjusted_text = trim_at_last_period(adjusted_text)
except Exception as e:
print(f"Error during API call: {e}")
break
retries += 1
elapsed_time = time.time() - start_time
return adjusted_text, elapsed_time먼저 current_length 를 계산하고, target_bytes로 이를 나누어 reduction ratio를 구합니다.
이후 retries 횟수에 따라 branching 되는데, 첫 시도라면 우선 api call을 날려보고 이후부터 비율을 조정하는 과정을 거칩니다. 저희 서비스의 경우 LR을 10% 정도로 조정해주는 것이 적합했으며, 이 경우 평균 3번의 api call로 target range(target bytes ± 50 bytes)에 안착하게 됩니다.
최대 api retry 횟수는 4회로 제한되어 있지만, 보통 아래와 같은 순서로 2-3회 정도로 분량 조절이 마무리됩니다.
- 쌩으로 api 콜을 날려본다.
- 1차로 reduction ratio를 적용시켜 분량을 증감한다.
- 2차로 reduction ratio를 적용시켜 분량을 세부 조정한다.
실제로 api call할 때 지정하는 token limit(max_tokens)은 아래와 같이 조절해주었습니다. 보통 한국어가 영어에 비해 2.36배의 토큰을 더 소모하는 한국어의 정보량을 고려한 방식입니다.
max_tokens=int(target_length // 2 * reduction_ratio)
Result
위와 같이 thread 개수를 10으로 설정했을 때, 10개 단위로 실행되고 정렬되어 로그에 쌓이는 것을 확인할 수 있습니다.
2000 바이트가 넘는 original text도 평균적으로 12초 안팎으로 target인 1000B에 도달하는 것을 확인할 수 있습니다.
CV 측정 및 비교
또한 CV(Coefficient of Variation)를 측정해보았는데요. CV란 평균을 표준편차로 나눈 비율입니다. 직관적인 이해를 위해 100을 곱하여 퍼센테이지로 확인해보겠습니다.
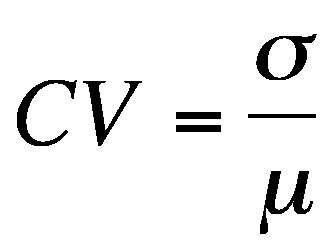
통상적으로 CV는 아래와 같이 판단됩니다. 보통 신뢰할만한 연구는 데이터셋 CV를 10% 이하로 타겟하는 경우가 많습니다.
- Acceptable : ~20%
- Outstanding : ~10%
- Superior : ~5%
대조군은 파인튜닝 없이 스크립트로만 글자수를 맞추려 한 기존 모델이고, 실험군은 제가 바이트 수를 맞추어 cleaning한 데이터셋으로 파인튜닝한 모델입니다.
기존 모델
총 스무건을 무작위로 생성하고 이에 대한 평균, 표준편차, CV를 측정했을 때 아래와 같았습니다.

- 평균 : 1424.35
- 표준편차 : 273.75
- CV : 19.21
파인튜닝 모델

- 평균 : 1498.05
- 표준편차 : 17.65
- CV : 1.17
다음과 같이 매우 뛰어난 품질의 파인튜닝 모델이 완성된 것을 확인할 수 있습니다.
References

엄청 어려울수도 있는 개념을 차근차근 쉽게 설명한 글이네요! 너무 잘 읽었습니다!