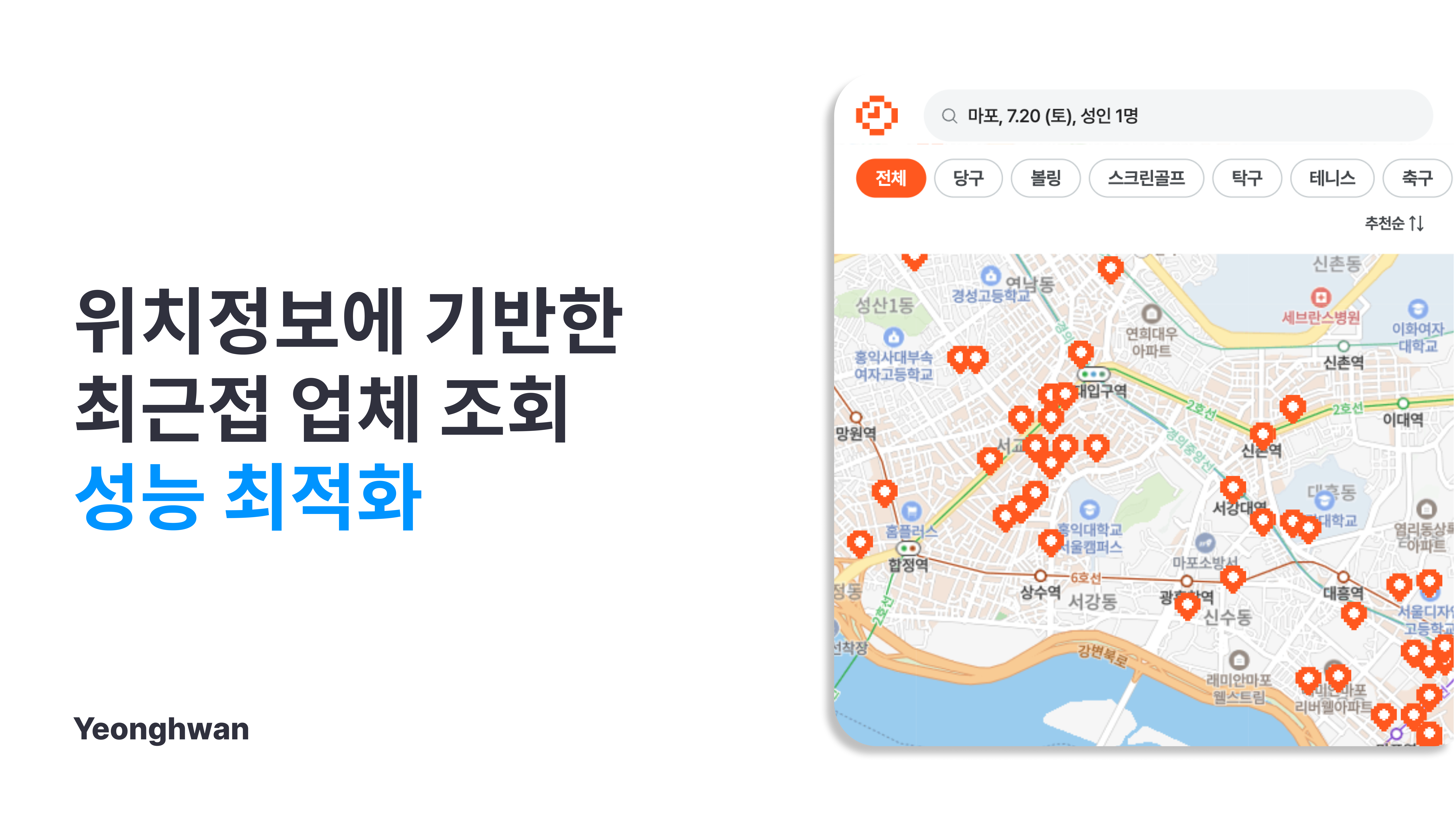
조회 최적화 배경
제가 서버 개발 중인 여가예약 플랫폼 서비스 TIG의 홈화면에서는, 아래와 같이 근처에서 즐길 수 있는 업체를 선별하여 보여주어야 하는데요.
 가까운 업체를 찾는 로직은 그래프 정보를 저장하지 않는 이상 전체 업체를 조회하고 일일이 비교해주어야 하기 때문에 성능 최적화가 필요하다고 판단했습니다.
가까운 업체를 찾는 로직은 그래프 정보를 저장하지 않는 이상 전체 업체를 조회하고 일일이 비교해주어야 하기 때문에 성능 최적화가 필요하다고 판단했습니다.
기존 성능
성능 측정 방법(AOP)
@Aspect
@Component
public class TimingAspect {
@Around("execution(* tig.server.club.service.ClubService.*(..))")
public Object timeMethodExecution(ProceedingJoinPoint joinPoint) throws Throwable {
long startTime = System.currentTimeMillis();
Object result = joinPoint.proceed();
long timeTaken = System.currentTimeMillis() - startTime;
String methodName = joinPoint.getSignature().getName();
String fullSignature = joinPoint.getSignature().toString();
String args = fullSignature.substring(fullSignature.indexOf("("), fullSignature.indexOf(")") + 1);
String requiredPart = methodName + args;
System.out.println(" Execution Time | " + requiredPart + " : " + timeTaken + " ms");
return result;
}
}Dummy Club
for (int i = 1; i <= 1000; i++) {
Club club = Club.builder()
.clubName("Club " + i)
.address("Address " + i)
.ratingSum(20.0f + i)
.ratingCount(10 + i)
.price(15000 + (i * 1000))
.phoneNumber("010-4569-9" + String.format("%03d", i))
.snsLink("snsLink " + i)
.businessHours("09:00 - 19:00")
.category(Category.FOOTBALL)
.type(Type.TIME)
.latitude(0f)
.longitude(0f)
.build();
clubRepository.save(club);
}AOP로 메소드 실행시간을 측정할 수 있게 했으며 1,000 건의 더미 업체(이하 club)을 넣어주었습니다.
0. 순회하여 정렬
Basic : findNearestClubs
public List<Club> findNearestClubs(double requestLatitude, double requestLongitude, Integer count) {
List<Club> allClubs = clubRepository.findAll();
return allClubs.stream()
.sorted(Comparator.comparingDouble(
club -> distance(requestLatitude, requestLongitude, club.getLatitude(), club.getLongitude()
)))
.limit(count)
.collect(Collectors.toList());
}
private double distance(double lat1, double lon1, double lat2, double lon2) {
// Haversine formula to calculate the distance between two points on the Earth
final int R = 6371; // Radius of the earth in km
double latDistance = Math.toRadians(lat2 - lat1);
double lonDistance = Math.toRadians(lon2 - lon1);
double a = Math.sin(latDistance / 2) * Math.sin(latDistance / 2)
+ Math.cos(Math.toRadians(lat1)) * Math.cos(Math.toRadians(lat2))
* Math.sin(lonDistance / 2) * Math.sin(lonDistance / 2);
double c = 2 * Math.atan2(Math.sqrt(a), Math.sqrt(1 - a));
double distance = R * c; // convert to kilometers
return distance;
}
}기존 로직은 보시다시피 현재 위도, 경도를 입력받아 count개의 가까운 club을 리턴하는 간단한 메소드입니다.
Time Complexity(N : num of clubs)
- retrieve clubs : O(N)
- sorting: O(N log N)
- collect: O(count) ~ O(1)
시간복잡도는 다음과 같이 N개 club 순회 이후 정렬이므로, 정렬에 필요한 O(N log N) 만큼 소요됩니다.
리턴받을 club 개수인 count는 많아야 5~10 개이니 상수로 취급할 수 있습니다.
findNearestClubs

1,000 건의 업체에 대해서는 40ms의 조회 성능을 보여주네요.
성능 최적화 과정
1. 우선순위 큐 도입 및 원시 자료형
개선 방안
- priority queue : Heap 기반의 우선순위 큐를 도입합니다.
- double → float : 8B의 double 대신 4B의 float 자료형을 이용합니다.
public List<Club> optimizedFindNearestClubsFour(float requestLatitude, float requestLongitude, int count) {
List<Club> allClubs = clubRepository.findAll();
// Create a priority queue to maintain the nearest clubs
PriorityQueue<ClubDistance> nearestClubs = new PriorityQueue<>(count, Comparator.comparingDouble(ClubDistance::getDistance));
allClubs.stream()
.map(club -> new ClubDistance(club, distance(requestLatitude, requestLongitude, club.getLatitude(), club.getLongitude())))
.forEach(clubDistance -> {
nearestClubs.offer(clubDistance);
if (nearestClubs.size() > count) {
nearestClubs.poll(); // Remove the club with the largest distance if the queue exceeds the count
}
});
return nearestClubs.stream()
.map(ClubDistance::getClub)
.collect(Collectors.toList());
}
private static class ClubDistance {
private final Club club;
private final double distance;
public ClubDistance(Club club, double distance) {
this.club = club;
this.distance = distance;
}
public Club getClub() {
return club;
}
public double getDistance() {
return distance;
}
}ClubDistance 객체를 생성하여 Priority Queue와 비교하며 항상 PQ가 가까운 업체들만 담을 수 있게 합니다.
Time Complexity(N : num of clubs)
- retrieve clubs : O(N)
- priority queue : O(log count) ~ O(1)
- collect: O(count) ~ O(1)
이번에는 club을 순회하며 PQ와 비교하기 때문에, O(log count)의 곱연산이 일어납니다.
역시 count를 상수로 취급할 수 있어, O(N log count) ~ O(N)의 성능을 기대할 수 있겠네요.
Improved 1 : optimizedFindNearestClubs

double -> float, PQ만 도입했을 때는 1,000 건의 업체에 대해서 8ms의 준수한 성능을 보여줍니다.
벌써 5배의 성능이 증가했네요.
조금 더 개선할 부분이 있을까요?
2. 연산 중복 최소화
개선 방안
- duplication elimination : stream 내부에서 중복되는 연산을 외부에서 한 번만 연산합니다.
Five라는 구린 변수명을 짓기는 했지만, 나름 이유가 있습니다.
먼저 앞서 사용한 distance 메소드를 볼까요
private float distance(float lat1, float lon1, float lat2, float lon2) {
// Haversine formula to calculate the distance between two points on the Earth
final float R = 6371; // Radius of the earth in km
float latDistance = (float) Math.toRadians(lat2 - lat1);
float lonDistance = (float) Math.toRadians(lon2 - lon1);
float a = (float) (Math.sin(latDistance / 2) * Math.sin(latDistance / 2)
+ Math.cos(Math.toRadians(lat1)) * Math.cos(Math.toRadians(lat2))
* Math.sin(lonDistance / 2) * Math.sin(lonDistance / 2));
float c = (float) (2 * Math.atan2(Math.sqrt(a), Math.sqrt(1 - a)));
return R * c; // convert to kilometers
}위의 첫번째 개선안은 매 순회마다 distance 메소드로 거리를 계산했습니다.
하지만 자세히 보면, Math.cos(Math.toRadians(lat1)) 은 현재 위치(lat1, lon1)을 사용하기 때문에 반복하여 연산해줄 필요가 없습니다.
// Precompute cosine of request latitude
float requestLatitudeRad = (float) Math.toRadians(requestLatitude);
float cosRequestLatitude = (float) Math.cos(requestLatitudeRad);때문에 cosRequestLatitude로 미리 계산 후, distance의 파라미터로 하나 추가해주었습니다.
파라미터가 4개에서 5개가 된 것이 optimizedFindNearestClubsFive라는 구린 변수명의 원인..!
사실 이 부분도 무작정 도입을 하기엔 고민되었던 게, method 파라미터가 늘어날수록 오류가 급속도로 늘었다는 Google 논문(Detecting Argument Selection Defects)이 있습니다.
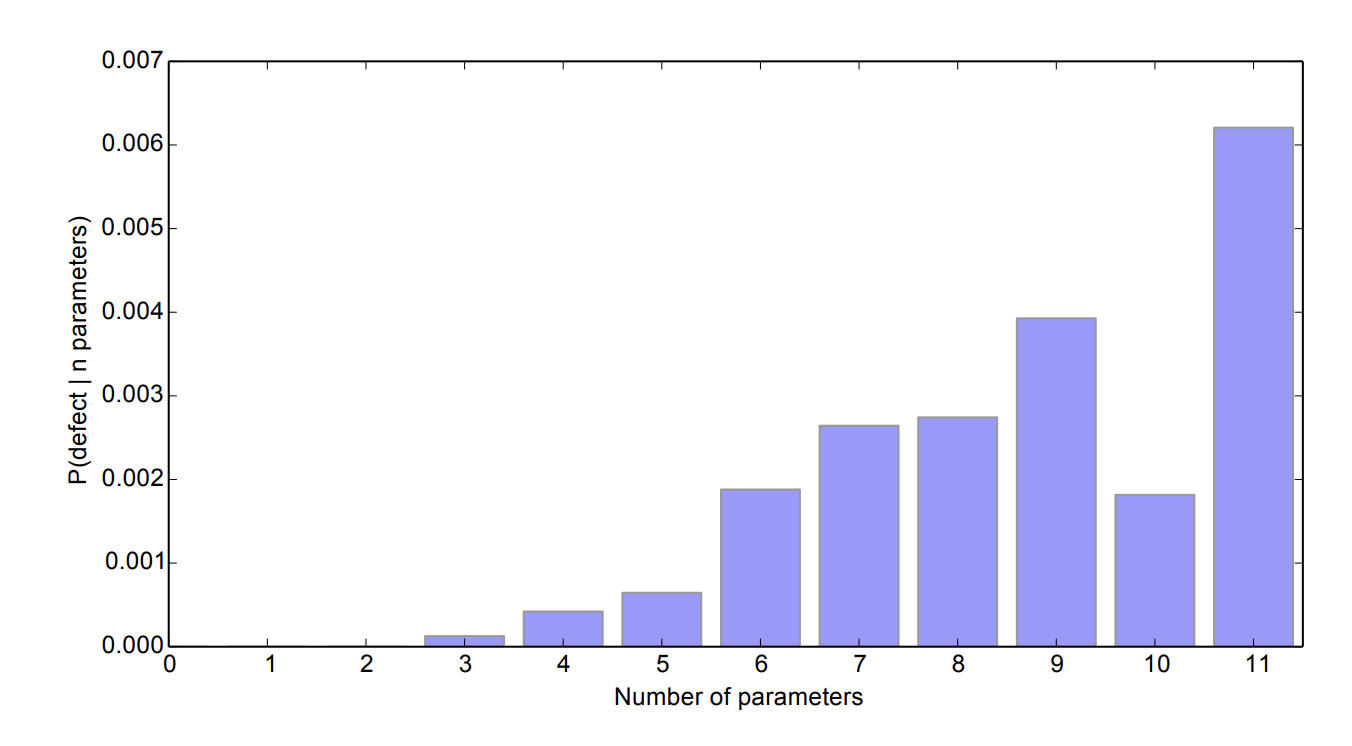
별개로 파라미터가 5개인 것도 클린하지 않아서 썩 마음에 들지는 않습니다. 2차원 거리구하기 로직의 특성상 파라미터 4개는 어쩔 수 없는 것 같습니다.
무튼 성능이 얼마나 개선되었나 확인해볼까요.
Improved 2 : optimizedFindNearestClubsFive

추가로 중복되는 코사인 연산을 미리 계산하여 파라미터로 넣어주니, 1ms를 더 줄일 수 있었습니다.
코드 레벨에서는 해볼 만큼 해본 것 같은데, 이젠 더 줄일 수 없을까요?
3. 병렬 stream 연산
개선 방안
- parallel stream : distance 연산을 병렬로 수행합니다.
- concurrent skip list set : thread safe하게 데이터에 접근 합니다.
allClubs.stream()
.map(club -> new ClubDistance(club, distance(requestLatitude, requestLongitude, club.getLatitude(), club.getLongitude())))
.forEach(clubDistance -> {
nearestClubs.offer(clubDistance);
if (nearestClubs.size() > count) {
nearestClubs.poll(); // Remove the club with the largest distance if the queue exceeds the count
}
});앞선 코드는 stream을 사용하여 모든 club을 순회하며 distance 연산을 수행하고 있었습니다. 하지만 이번에는 Java8부터 지원되는 병렬 stream을 사용해보고자 합니다.
단순히 stream을 parallelStream을 바꾸는 것으로 잘 돌아가면 좋았겠지요?
병렬 연산 특성상 thread-safe 이슈가 걱정됐고, 역시나 100건에서는 잘 동작하다가 1,000건에서는 NullPointerException이 발생했습니다.
PQ에 값을 넣고 빼는 모든 작업에 대해서 일일이 null handling하면 해결되겠지만, 우아하지 않은 방법이라고 판단했습니다.
이에 PQ의 O(log N) 접근 성능은 유지하면서, thread safe한 자료구조를 찾아보았고 ConcurrentSkipListSet이라는 훌륭한 대안을 발견했습니다.
// Use ConcurrentSkipListSet to maintain the nearest clubs in a thread-safe manner
ConcurrentSkipListSet<ClubDistance> nearestClubs = new ConcurrentSkipListSet<>(Comparator.comparingDouble(ClubDistance::getDistance));
allClubs.parallelStream()
.map(club -> new ClubDistance(club, distance(requestLatitude, requestLongitude, club.getLatitude(), club.getLongitude(), cosRequestLatitude)))
.forEach(clubDistance -> {
nearestClubs.add(clubDistance);
if (nearestClubs.size() > count) {
nearestClubs.pollLast(); // Remove the club with the largest distance if the set exceeds the count
}
});위와 같이 PQ를 thread-safe한 List Set으로 대체하여 병렬 순회해주었습니다.
Time Complexity(N : num of clubs)
- retrieve clubs : O(N)
- parallel list set : O(log count) ~ O(1)
역시 PQ를 사용한 것과 같이 O(N log count) ~ O(N)의 성능이지만, 병렬 연산을 적용했기 때문에 더욱 개선되기를 기대해볼 수 있겠네요.
Improved 3 : parallelFindNearestClubs

7ms보다 줄어들지는 않았습니다. 아무래도 1,000개의 데이터는 너무 적어서 당장의 수행시간은 cpu 등 하드웨어 의존성이 높을 것 같습니다.
이제 마지막으로 개선해볼까요?
4. 함수형 프로그래밍
개선 방안
- functional program paradigm : collect를 ConcurrentSkipListSet에 직접 사용하는 등, 불필요한 선언을 최소화합니다.
// Use ConcurrentSkipListSet to maintain the nearest clubs in a thread-safe manner
ConcurrentSkipListSet<ClubDistance> nearestClubs = allClubs.parallelStream()
.map(club -> new ClubDistance(club, distance(requestLatitude, requestLongitude, club.getLatitude(), club.getLongitude(), cosRequestLatitude)))
.collect(Collectors.toCollection(() -> new ConcurrentSkipListSet<>(Comparator.comparingDouble(ClubDistance::getDistance))));앞선 병렬 연산과 사실상 같은 코드이지만 함수형 프로그래밍 관점을 차용한 방식입니다. 차이점이 있다면 변수 할당을 줄여 가독성을 낮추고 조금이라도 더 성능을 취하는 코드입니다.
어차피 가까운 클럽을 찾는 함수로 capsulization된다면, 성능상 이점이 있을 때 코드가 복잡해지는 overhead는 감수할 만 하다고 생각됩니다.
Improved 4 : optimizedParallelFindNearestClubs

이번에도 1ms 줄었네요. 코드 레벨 최적화는 해볼만큼 한 것 같습니다.
Performance Comparison
코드 레벨 성능은 데이터가 많아야 제대로 측정했다고 할 수 있습니다.
기존 1,000건의 데이터를 100,000 건으로 늘려서 측정해보겠습니다.
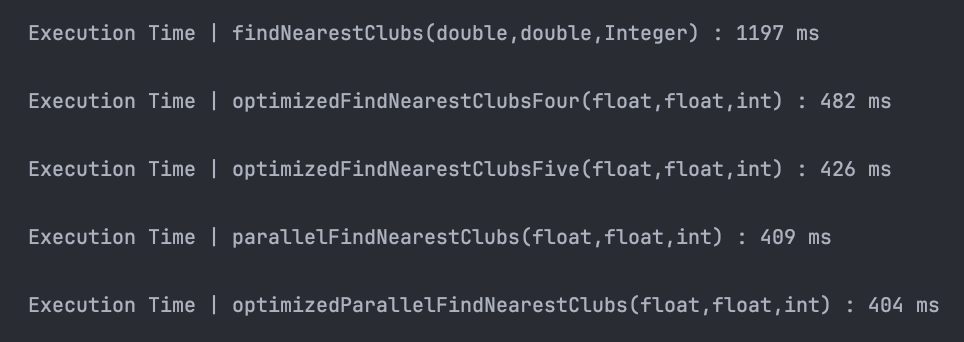
약 1,200 ms가 소요되었던 조회 작업이 최적화를 거칠수록 빨라져, 최종적으로는 약 400ms까지 3배 정도 성능이 증가했네요.
데이터를 1,000,000 건으로 늘려보겠습니다.
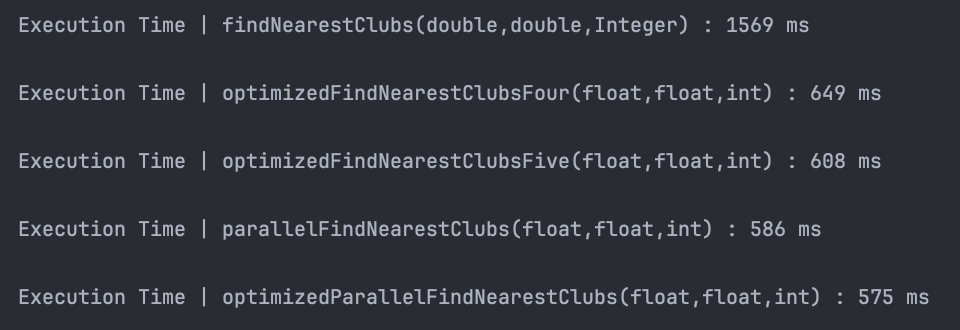
역시 성능이 좋아지기는 하나, 데이터가 10배 늘어난 것 치고는 놀라운 성능 차이가 있지는 않습니다.
쿼리 튜닝 및 KNN 등, 조회 성능을 개선하는 다양한 방법이 있을 것 같은데, 혹시 좋은 의견이 있다면 댓글 남겨주시면 감사하겠습니다.
References
